

如何利用chiplet技术构建大芯片?
描述
大芯片的架构设计对性能有重大影响,与存储器访问模式密切相关。在内存访问模式方面,与传统的多核处理器设计考虑将多核集成在单个裸片上访问内存不同,大芯片设计侧重于多个多核裸片访问内存系统。根据内存访问模式,大芯片可以分为对称chiplet架构、NUMA(非均匀内存访问)chiplet架构、集群chiplet架构和异构chiplet架构。在接下来的章节中,我们将以利用chiplet技术构建大芯片为例,从性能、可扩展性、可靠性、通信等方面讨论这些大芯片架构的特点。
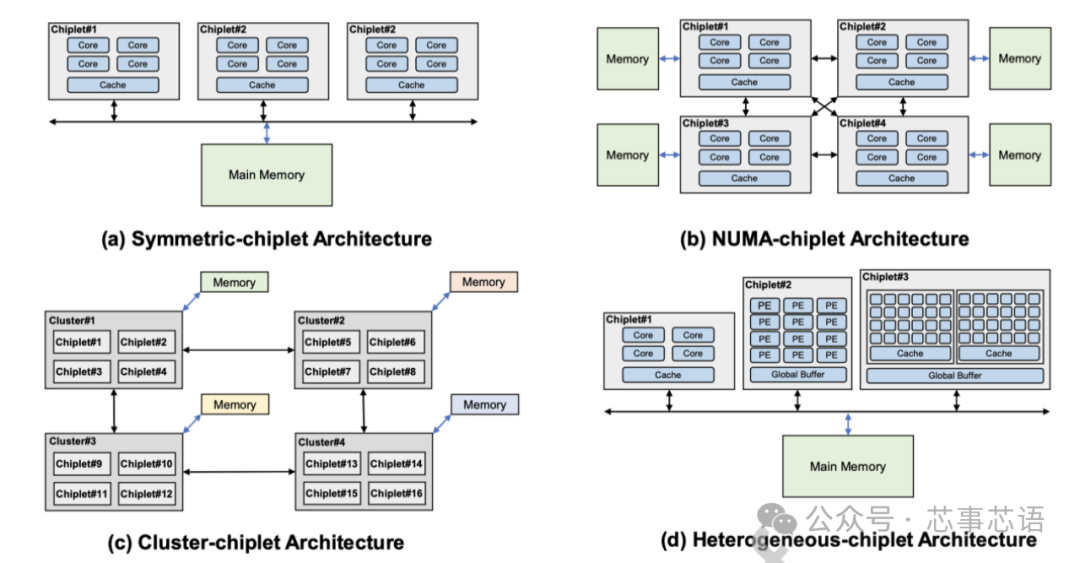
Symmetric-chiplet architecture
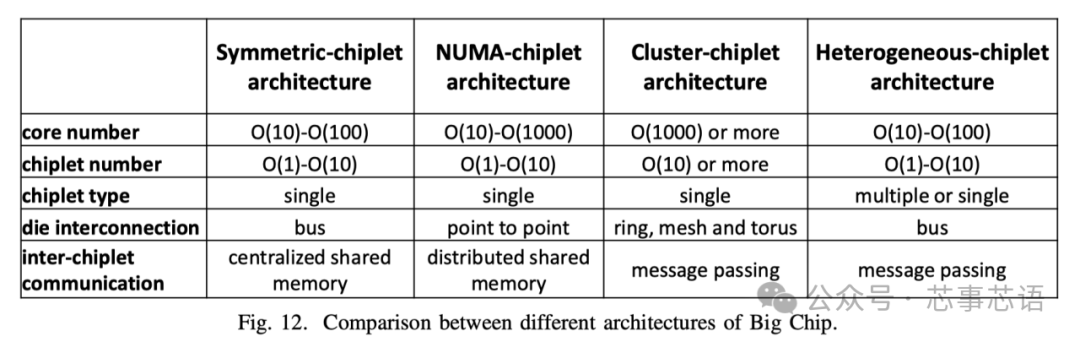
对称小芯片架构(Symmetric-chiplet architecture)。如图11(a)所示,对称chiplet架构由许多相同的计算chiplet组成,通过路由器网络或chiplet间资源(例如中介层)访问共享的统一存储器或IO。Chiplet可以设计为具有本地缓存的多核结构,或者具有多个处理元件的NoC结构。统一内存可以被所有chiplet平等地访问,这体现了UMA(统一内存访问)的效果。我们现在讨论对称小芯片架构的三个主要优点。
首先,对称chiplet架构允许多个chiplet执行指令以提供高计算能力。工作负载可以分成小块,然后分配给不同的 Chiplet,以加快应用程序的执行速度,同时保持不同 Chiplet 之间的工作负载平衡。
其次,这种对称的chiplet架构提供了从不同chiplet到内存的统一延迟,无需考虑NUMA等分布式共享内存系统中的远程访问或内存复制,从而节省了由于不必要的数据移动而导致的延迟和能耗。
第三,对称chiplet处理器还提供冗余设计,其他chiplet可以接管故障chiplet的工作,从而提高系统可靠性。由于共享内存,对称小芯片处理器可以在不增加额外私有内存的情况下增加小芯片的数量。然而,当对称chiplet架构继续扩大chiplet数量时,互连设计将受到物理布线的严重限制。解决高带宽小芯片间通信和内存请求冲突也具有挑战性。请注意,增加 Chiplet 的数量可能会增加不同 Chiplet 对内存的请求冲突,这会损害系统性能。平均而言,内存带宽由小芯片划分。增加小芯片的数量会减少每个小芯片的分区内存带宽。工业界和学术界的一些设计采用了对称芯片架构。Apple M1 Ultra 处理器 [43] 采用小芯片集成设计,具有两个相同的 M1 Max 芯片,具有统一的内存架构设计。芯片上的内核可以访问高达 128GB 的统一内存。Fotouhi [44]提出了一种基于小芯片集成的统一内存架构,以克服距离相关的功耗和延迟问题。Sharma [45] 提出了一种通过板载光学互连共享统一存储器的多芯片系统。
NUMA-chiplet architecture
NUMA-chiplet架构(NUMA-chiplet architecture)。NUMA小芯片架构包含通过点对点网络或中央路由器互连的多个小芯片,并且NUMA小芯片架构的存储器系统由所有小芯片共享但分布在架构中,如图11(b)所示。Chiplet可以采用共享缓存的多核设计,或者通过NoC互连的PE的设计。而且,每个chiplet可以占用自己的本地存储器,例如DRAM、HBM等,这是其区别于对称chiplet架构的最明显特征。尽管这些连接到不同chiplet的存储器分布在系统中,但存储器地址空间是全局共享的。共享内存的这种分布式放置会导致 NUMA 效应,即访问远程内存比访问本地内存慢[46]。NUMA-chiplet 架构考虑了一些优点。从单个chiplet的角度来看,每个chiplet都拥有自己的内存,具有相对私有的内存带宽和容量,减少了与其他chiplet的内存请求的冲突。此外,芯片与内存的紧密放置提供了数据移动的低延迟和低功耗。
此外,在NUMA-chiplet架构中,通过高带宽点对点网络或路由器互连的多个chiplet可以并行执行任务,从而提高系统性能和兼容性。这种 NUMA 小芯片架构具有很高的可扩展性,因为每个小芯片都有自己的内存。然而,随着 NUMA-chiplet 架构扩展到更多的chiplet,设计chiplet 到chiplet 互连网络变得具有挑战性。
此外,随着chiplet数量的增加,编程模型的成本和难度也随之增加。有一些设计采用 NUMAchiplet 架构。AMD 的第一代 EPYC 处理器将四个相同的小芯片与本地内存连接起来 [39]。对内存的本地访问和远程访问之间的延迟差异可达 51ns [46]。
在 AMD 第二代 EPYC 处理器中,计算 Chiplet 通过 IO Chiplet 连接到内存,这显示了 NUMA-chiplet 架构 [34]。另一种典型的 NUMAchiplet 架构设计是 Intel Sapphire Rapids [47]。它由四个小芯片组成,通过 MDFIO(多芯片结构 IO)连接。四个小芯片组织为 2x2 阵列,每个芯片充当 NUMA 节点。Zaruba [48] 架构了 4 个基于 RISC-V 处理器的小芯片,每个小芯片都有三个分别与其他三个小芯片的链接,以提供非统一的内存访问。
Cluster-chiplet architecture
集群小芯片架构(Cluster-chiplet architecture)。如图11(c)所示,集群chiplet架构包含许多chiplet集群,总共有数千个核心。采用环形、网状、一维/二维环面等高速或高吞吐量网络拓扑来连接集群,以满足此类超大规模系统的高带宽和低延迟通信需求。每个集群由许多互连的小芯片和单独的内存组成,并且每个集群都可以运行单独的操作系统。集群可以通过消息传递的方式与其他集群进行通信。通过高性能互连实现强大集群互连的集群-chiplet架构显示出高可扩展性并提供巨大的计算能力。
作为一种可扩展性很强的架构,clusterchiplet 架构是许多设计的基础。IntAct [30]集成了 96 个内核,这些内核在有源中介层上分为 6 个小芯片。6 个小芯片通过 NoC 连接。Tesla [49]发布了用于亿级计算的Dojo系统微架构。在 Dojo 中,一个训练图块由 25 个 D1 小芯片组成,这些小芯片排列为 5x5 矩阵样式。通过 2D 网格网络互连的许多训练块可以形成更大的系统。Simba [1] 通过 MCM 集成,利用网状互连构建了 6x6 小芯片系统。Chiplet 内的 PE 使用 NoC 连接。
Heterogeneous-chiplet architecture
异构小芯片架构(Heterogeneous-chiplet architecture)。异构chiplet架构集成了异构chiplet,由不同种类的chiplet组成,如图11(d)所示。同一中介层上的不同种类的chiplet可以与其他种类的chiplet互补,协同执行计算任务。华为鲲鹏920系列SoC[25]是基于计算chiplet、IO chiplet、AI chiplet等的异构系统。Intel Lakefield[50]提出了将计算chiplet堆叠在基础chiplet上的设计。计算chiplet集成了许多处理核心,包括CPU、GPU、IPU(基础设施处理单元)等,基础chiplet包含丰富的IO接口,包括PCIe Gen3、USB type-C等。在Ponte Vecchio [51]中,两个基础块使用EMIB(嵌入式多芯片互连桥)互连。计算瓦片和 RAMBO 瓦片堆叠在每个基础瓦片上。Intel Meteor Lake处理器[52]集成了GPU tile、CPU tile、IO tile和SoC tile。
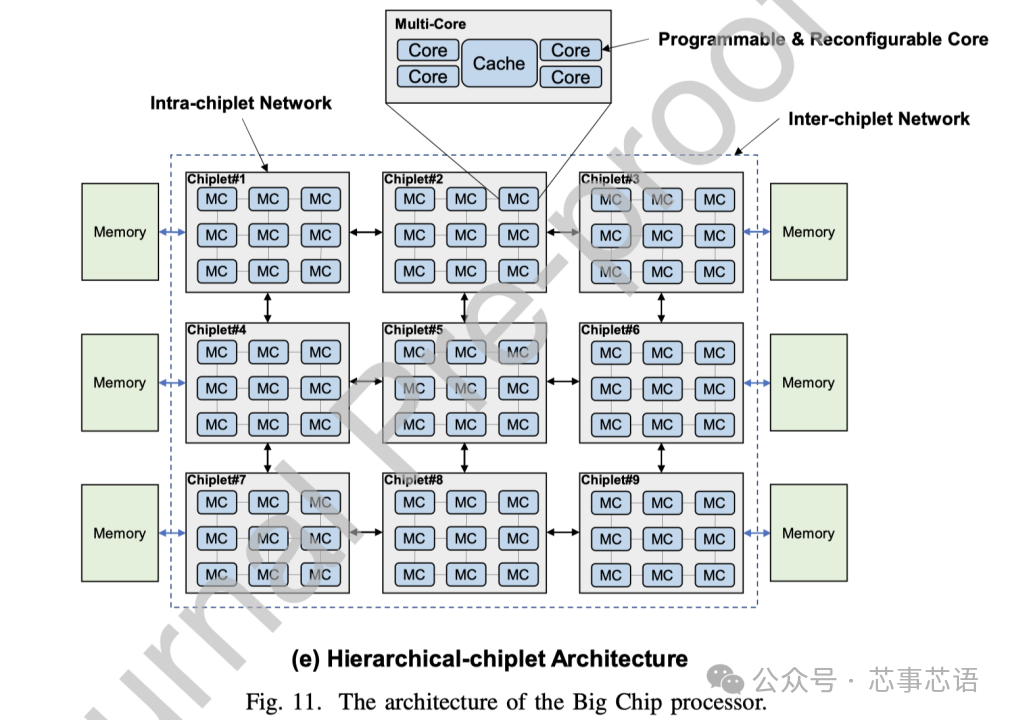
hierarchical-chiplet architecture
对于当前和未来的亿亿级计算,我们预测分层chiplet架构(hierarchical-chiplet architecture)将是一种强大而灵活的解决方案。如图11(e)所示,分层chiplet架构被设计为具有分层互连的许多内核和许多chiplet。在chiplet内部,内核使用超低延迟互连进行通信,而chiplet之间则通过先进封装技术的低延迟互连,从而可以在这种高可扩展性系统中降低片上(let)延迟和NUMA效应最小化。存储器层次结构包含核心存储器、片内存储器和片外存储器。这三个级别的内存在内存带宽、延迟、功耗和成本方面有所不同。
在分层chiplet架构的概述中,多个核心通过交叉交换机连接并共享缓存。这就形成了一个pod结构,并且pod通过chiplet内网络互连。多个pod形成一个chiplet,chiplet通过chiplet间网络互连,然后连接到片外存储器。需要仔细设计才能充分利用这种层次结构。合理利用内存带宽来平衡不同计算层次的工作负载可以显着提高chiplet系统的效率。正确设计通信网络资源可以确保chiplet协同执行共享内存任务。
VI. 构建大芯片:我们的实现
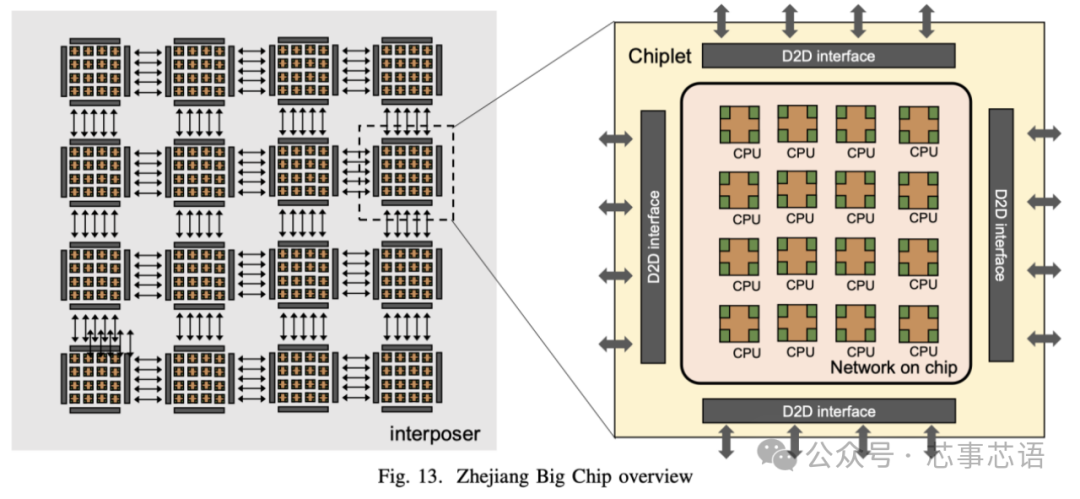
为了探索大芯片的设计和实现技术,我们构建并设计了一个基于16 个小芯片的 256 核处理器系统,名为浙江大芯片。在这里,我们介绍了拟议的 Big Chip 处理器。
浙江大芯片采用可扩展的基于tile的架构,如图13所示。该处理器由16个chiplet组成,并且有可能扩展到100个chiplet。每个chiplet中都有16 个CPU 处理器,通过片上网络(NOC) 连接,每个tile 完全对称互连,以实现多个chiplet 之间的通信。CPU处理器是基于RISC-V指令集设计的。此外,该处理器采用统一内存系统,这意味着任何区块上的任何核心都可以直接访问整个处理器的内存。
为了连接多个小芯片,采用了芯片间(D2D) 接口。该接口采用基于时分复用机制的通道共享技术进行设计。这种方法减少了芯片间信号的数量,从而最大限度地减少了 I/O bumps和内插器布线(interposer wiring)资源的面积开销,从而显着降低了基板设计的复杂性。小芯片终止于构建微型 I/O pads的顶部金属层。浙江大芯处理器采用22 nm CMOS工艺设计和制造。
审核编辑:刘清
-
什么是Chiplet技术?chiplet芯片封装为啥突然热起来2022-10-20 8970
-
北极雄芯开发的首款基于Chiplet异构集成的智能处理芯片“启明930”2023-02-21 1538
-
chiplet是什么意思?chiplet和SoC区别在哪里?一文读懂chiplet2021-01-04 61345
-
国产封测厂商竞速Chiplet,能否突破芯片技术封锁?2023-01-16 1871
-
Chiplet技术给EDA带来了哪些挑战?2023-04-03 1003
-
半导体Chiplet技术及与SOC技术的区别2023-05-16 3153
-
Chiplet关键技术与挑战2023-07-17 2588
-
Chiplet究竟是什么?中国如何利用Chiplet技术实现突围2023-07-27 1365
-
chiplet和cowos的关系2023-08-25 5037
-
Chiplet主流封装技术都有哪些?2023-09-28 3418
-
先进封装 Chiplet 技术与 AI 芯片发展2023-12-08 2671
-
什么是Chiplet技术?Chiplet技术有哪些优缺点?2024-01-08 7520
-
什么是Chiplet技术?2024-01-25 4593
-
解锁Chiplet潜力:封装技术是关键2025-01-05 2692
-
Chiplet,正在改变芯片制造2026-05-15 174
全部0条评论

快来发表一下你的评论吧 !
