

深度解读Nvidia AI芯片路线图
人工智能
描述
在2023年投资者会议上,Nvidia展示了其全新的GPU发展蓝图 [1]。与以往两年一次的更新节奏不同,这次的路线图将演进周期缩短至一年。预计在2024年,Nvidia将推出H200和B100 GPU;到2025年,X100 GPU也将面世。其AI芯片规划的战略核心是“One Architecture”统一架构,支持在任何地方进行模型训练和部署,无论是数据中心还是边缘设备,无论是x86架构还是Arm架构。其解决方案适用于超大规模数据中心的训练任务,也可以满足企业级用户的边缘计算需求。
AI芯片从两年一次的更新周期转变为一年一次的更新周期,反映了其产品开发速度的加快和对市场变化的快速响应。其AI芯片布局涵盖了训练和推理两个人工智能关键应用,训练推理融合,并侧重推理。同时支持x86和Arm两种不同硬件生态。在市场定位方面,同时面向超大规模云计算和企业级用户,以满足不同需求。Nvidia旨在通过统一的架构、广泛的硬件支持、快速的产品更新周期以及面向不同市场提供全面的差异化的AI解决方案,从而在人工智能领域保持技术和市场的领先地位。Nvidia是一个同时拥有 GPU、CPU和DPU的计算芯片和系统公司。Nvidia通过NVLink、NVSwitch和NVLink C2C技术将CPU、GPU进行灵活连接组合形成统一的硬件架构,并于CUDA一起形成完整的软硬件生态。
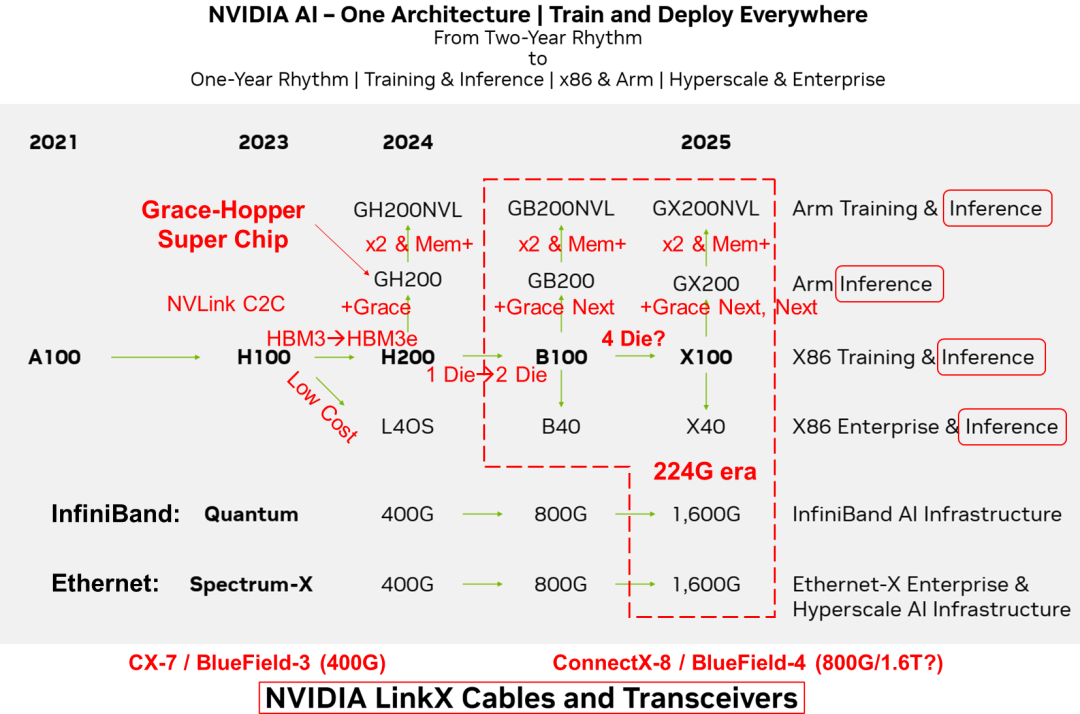
在AI计算芯片架构方面,注重训练和推理功能的整合,侧重推理。围绕GPU打造ARM和X86两条技术路线。在Nvidia的AI路线图中,并没有显示提及Grace CPU的技术路线,而是将其纳入Grace+GPU的SuperChip超级芯片路标中。
Nvidia Grace CPU会跟随GPU的演进节奏并与其组合成新一代超级芯片;而其自身也可能根据市场竞争的需求组合成CPU超级芯片,实现“二打一”的差异化竞争力。从需求角度来看,CPU的技术演进速度并不像GPU那样紧迫,并且CPU对于成本更加敏感。CPU只需按照“摩尔”或“系统摩尔”,以每两年性能翻倍的速度进行演进即可。而GPU算力需要不到一年就要实现性能翻倍,保持每年大约2.5倍的速率增长。这种差异催生了超级芯片和超节点的出现。
Nvidia将延用SuperChip超级芯片架构,NVLink-C2C和NVLink互联技术在Nvidia未来的AI芯片架构中将持续发挥关键作用。其利用NVLink-C2C互联技术构建GH200、GB200和GX200超级芯片。更进一步,通过NVLink互联技术,两颗GH200、GB200和GX200可以背靠背连接,形成GH200NVL、GB200NVL和GX200NVL模组。Nvidia可以通过NVLink网络组成超节点,通过InfiniBand或Ethernet网络组成更大规模的AI集群。
在交换芯片方面,仍然坚持InfiniBand和Ethernet两条开放路线,瞄准不同市场,前者瞄准AI Factory,后者瞄准AIGC Cloud。但其并未给出NVLink和NVSwitch自有生态的明确计划。224G代际的速度提升,可能率先NVLink和NVSwitch上落地。以InfiniBand为基础的Quantum系列和以Ethernet基础的Spectrum-X系列持续升级。预计到2024年,将商用基于100G SerDes的800G接口的交换芯片;而到2025年,将迎来基于200G SerDes的1.6T接口的交换芯片。其中800G对应51.2T交换容量的Spectrum-4芯片,而1.6T则对应下一代Spectrum-5,其交换容量可能高达102.4T。从演进速度上看,224G代际略有提速,但从长时间周期上看,其仍然遵循着SerDes速率大约3到4年翻倍、交换芯片容量大约2年翻倍的规律。虽然有提到2024年Quantum将会升级到800G,但目前我们只能看到2021年发布的基于7nm工艺,400G接口的25.6T Quantum-2交换芯片。路线图中并未包含NVSwitch 4.0和NVLink 5.0的相关计划。有预测指出Nvidia可能会首先在NVSwitch和NVLink中应用224G SerDes技术。NVLink和NVSwitch作为Nvidia自有生态,不会受到标准生态的掣肘,在推出时间和技术路线选择上更灵活,从而实现差异化竞争力。
SmartNIC智能网卡/DPU数据处理引擎的下一跳ConnectX-8/BlueField-4目标速率为 800G,与1.6T Quantum和Spectrum-X配套的SmartNIC和DPU的路标仍不明晰,NVLink5.0和NVSwitch4.0可能提前发力。Nvidia ConnectX系列SmartNIC智能网卡与InfiniBand技术相结合,可以在基于NVLink网络的超节点基础上构建更大规模的AI集群。而BlueField DPU则主要面向云数据中心场景,与Ethernet技术结合,提供更强大的网络基础设施能力。相较于NVLink总线域网络,InfiniBand和Ethernet属于传统网络技术,两种网络带宽比例大约为1比9。例如,H00 GPU用于连接SmartNIC和DPU的PCIE带宽为128GB/s,考虑到PCIE到Ethernet的转换,其最大可以支持400G InfiniBand或者Ethernet接口,而NVLink双向带宽为900GB/s或者3.6Tbps,因此传统网络和总线域网络的带宽比为1比9。虽然SmartNIC和DPU的速率增长需求没有总线域网络的增速快,但它们与大容量交换芯片需要保持同步的演进速度。它们也受到由IBTA (InfiniBand) 和IEEE802.3 (Ethernet) 定义互通标准的产业生态成熟度的制约。
互联技术在未来的计算系统的扩展中起到至关重要的作用。Nvidia同步布局的还有LinkX系列光电互联技术。包括传统带oDSP引擎的可插拔光互联 (Pluggable Optics),线性直驱光互联LPO (Linear Pluggable Optics),传统DAC电缆、重驱动电缆 (Redrived Active Copper Cable)、芯片出光 (Co-Packaged Optics) 等一系列光电互联技术。随着超节点和集群网络的规模不断扩大,互联技术将在未来的AI计算系统中发挥至关重要的作用,需要解决带宽、时延、功耗、可靠性、成本等一系列难题。
对Nvidia而言,来自Google、Meta、AMD、Microsoft和Amazon等公司的竞争压力正在加大。这些公司在软件和硬件方面都在积极发展,试图挑战Nvidia在该领域的主导地位,这或许是Nvidia提出相对激进技术路线图的原因。Nvidia为了保持其市场地位和利润率,采取了一种大胆且风险重重的多管齐下的策略。他们的目标是超越传统的竞争对手如Intel和AMD,成为科技巨头,与Google、Microsoft、Amazon、Meta和Apple等公司并驾齐驱。Nvidia的计划包括推出H200、B100和“X100”GPU,以及进行每年度更新的AI GPU。此外,他们还计划推出HBM3E高速存储器、PCIE 6.0和PCIE 7.0、以及NVLink、224G SerDes、1.6T接口等先进技术,如果计划成功,Nvidia将超越所有潜在的竞争对手 [2]。
尽管硬件和芯片领域的创新不断突破,但其发展仍然受到第一性原理的限制,存在天然物理边界的约束。通过深入了解工艺制程、先进封装、内存和互联等多个技术路线,可以推断出未来Nvidia可能采用的技术路径。尽管基于第一性原理的推演成功率高,但仍需考虑非技术因素的影响。例如,通过供应链控制,在一定时间内垄断核心部件或技术的产能,如HBM、TSMC CoWoS先进封装工艺等,可以影响技术演进的节奏。根据Nvidia 2023年Q4财报,该公司季度收入达到76.4亿美元,同比增长53%,创下历史新高。全年收入更是增长61%,达到269.1亿美元的纪录。数据中心业务在第四季度贡献了32.6亿美元的收入,同比增长71%,环比增长11%。财年全年数据中心收入增长58%,达到创纪录的106.1亿美元 [3]。因此Nvidia拥有足够大的现金流可以在短时间内对供应链,甚至产业链施加影响。另外,也存在一些黑天鹅事件也可能产生影响,比如以色列和哈马斯的战争就导致了Nvidia取消了原定于10月15日和16日举行的AI SUMMIT [4]。业界原本预期,Nvidia将于峰会中展示下一代B100 GPU芯片 [5]。值得注意的是,Nvidia的网络部门前身Mellanox正位于以色列。
为了避免陷入不可知论,本文的分析主要基于物理规律的第一性原理,而不考虑经济手段(例如控制供应链)和其他可能出现的黑天鹅事件(例如战争)等不确定性因素。当然,这些因素有可能在技术链条的某个环节产生重大影响,导致技术或者产品演进节奏的放缓,或者导致整个技术体系进行一定的微调,但不会对整个技术演进趋势产生颠覆式的影响。考虑到这些潜在的变化,本文的分析将尽量采取一种客观且全面的方式来评估这些可能的技术路径。我们将以“如果 A 那么 X;如果 B 那么 Y;…”的形式进行思考和分析,旨在涵盖所有可能影响技术发展的因素,以便提供更准确、更全面的分析结果。此外,本文分析是基于两到三年各个关键技术的路标假设,即2025年之前。当相应的前提条件变化,相应的结论也应该作适当的调整,但是整体的分析思路是普适的。
Nvidia的AI布局
Nvidia在人工智能领域的布局堪称全面,其以系统和网络、硬件和软件为三大支柱,构建起了深厚的技术护城河 [6]。有分析称Nvidia的H100显卡有高达90%的毛利率。Nvidia通过扶持像Coreweave这样的GPU云服务商,利用供货合同让他们从银行获取资金,然后购买更多的H100显卡,锁定未来的显卡需求量。这种模式已经超出传统硬件公司的商业模式,套用马克思在资本论中所述“金银天然不是货币,货币天然是金银。”,有人提出了“货币天然不是H100,但H100天然是货币”的说法 [7]。这一切的背后在于对于对未来奇点临近的预期 [8],在于旺盛的需求,同时更在于其深厚的技术护城河。
Nvidia 2019年3月发起对Mellanox的收购 [9],并且于2020年4月完成收购 [10],经过这次收购Nvidia获取了InfiniBand、Ethernet、SmartNIC、DPU及LinkX互联的能力。面向GPU互联,自研NVLink互联和NVLink网络来实现GPU算力Scale Up扩展,相比于基于InfiniBand网络和基于Ethernet的RoCE网络形成差异化竞争力。NVLink自2014年推出以来,已经历了四个代际的演进,从最初的2014年20G NVLink 1.0,2018年25G NVLink2.0,2020年50G NVLink 3.0 到2022年的100G NVLink 4.0,预计到2024年,NVLink将进一步发展至200G NVLink 5.0。在应用场景上,NVLink 1.0至3.0主要针对PCIE板内和机框内互联的需求,通过SerDes提速在与PCIE互联的竞争中获取显著的带宽优势。值得注意的是,除了NVLink1.0采用了20G特殊速率点以外,NVLink2.0~4.0皆采用了与Ethernet相同或者相近的频点,这样做的好处是可以复用成熟的Ethernet互联生态,也为未来实现连接盒子或机框组成超节点埋下伏笔。NVSwitch 1.0、2.0、3.0分别与NVLink2.0、3.0、4.0配合,形成了NVLink总线域网络的基础。NVLink4.0配合NVSwitch3.0组成了超节点网络的基础,这一变化的外部特征是NVSwitch脱离计算单板而单独成为网络设备,而NVLink则从板级互联技术升级成为设备间互联技术。
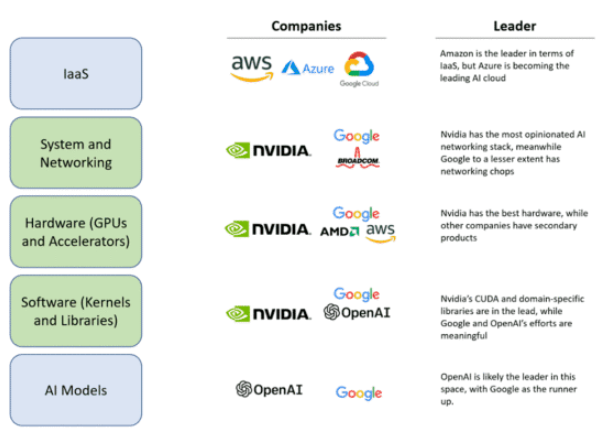
在计算芯片领域,Nvidia于2020年9月发起ARM收购,期望构建人工智能时代顶级的计算公司 [11],这一收购提案因为面临重大监管挑战阻碍了交易的进行,于2022年2月终止 [12]。但是,在同年3月其发布了基于ARM的Grace CPU Superchip超级芯片 [13]。成为同时拥有CPU、GPU和DPU的计算芯片和系统公司。
从业务视角看,Nvidia在系统和网络、硬件、软件三个方面占据了主导地位 [6]。系统和网络、硬件、软件这三个方面是人工智能价值链中许多大型参与者无法有效或快速复制的重要部分,这意味着Nvidia在整个生态系统中占据着主导地位。要击败Nvidia就像攻击一个多头蛇怪。必须同时切断所有三个头才有可能有机会,因为它的每个“头”都已经是各自领域的领导者,并且Nvidia正在努力改进和扩大其护城河。在一批人工智能硬件挑战者的失败中,可以看到,他们都提供了一种与Nvidia GPU相当或略好的硬件,但未能提供支持该硬件的软件生态和解决可扩展问题的方案。而Nvidia成功地做到了这一切,并成功抵挡住了一次冲击。这就是为什么Nvidia的战略像是一个三头水蛇怪,后来者必须同时击败他们在系统和网络、硬件以及软件方面的技术和生态护城河。目前,进入Nvidia平台似乎能够占据先机。OpenAI、微软和Nvidia显然处于领先地位。尽管Google和Amazon也在努力建立自己的生态系统,但Nvidia提供了更完整的硬件、软件和系统解决方案,使其成为最具吸引力的选择。要赢得先机,就必须进入其硬件、软件和系统级业务生态。然而,这也意味着进一步被锁定,未来更难撼动其地位。从Google和Amazon等公司的角度来看,如果不选择接入Nvidia的生态系统,可能会失去先机;而如果选择接入,则可能意味着失去未来。
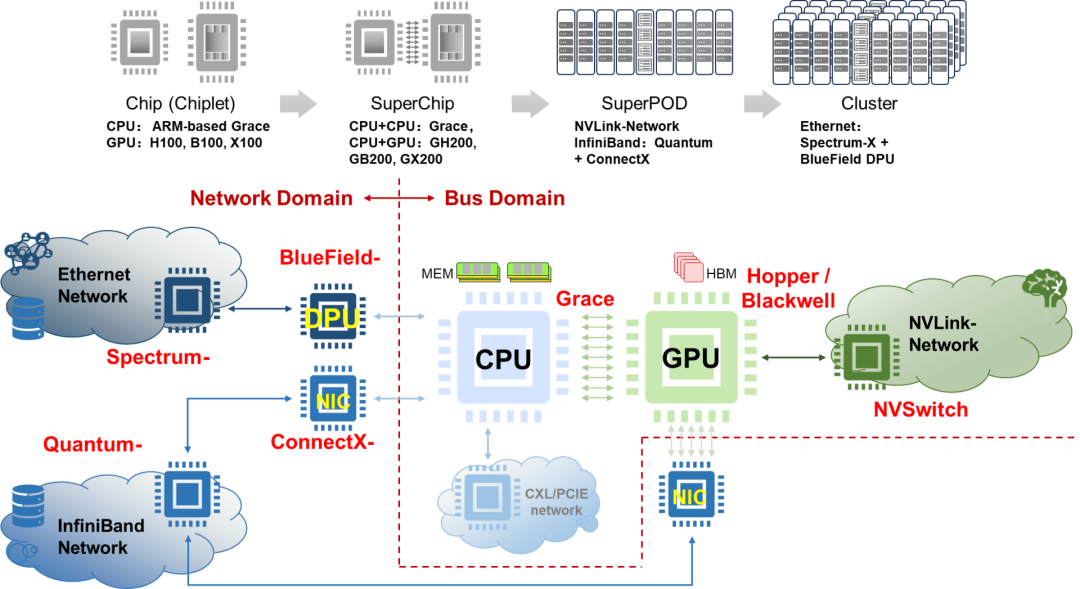
Nvidia布局了两种类型网络,一种是传统InfiniBand和Ethernet网络,另一种是NVLink总线域网络。在传统网络中,Ethernet面向AIGC Cloud多AI训练和推理等云服务,而InfiniBand面向AI Factory,满足大模型训练和推理的应用需求。在交换芯片布局方面,有基于开放Ethernet增强的Spectrum-X交换芯片和基于InfiniBand的封闭高性能的Quantum交换芯片。当前Ultra Ethernet Consortium (UEC) 正在尝试定义基于Ethernet的开放、互操作、高性能的全栈架构,以满足不断增长的AI和HPC网络需求 [14],旨在与Nvidia的网络技术相抗衡。UEC的目标是构建一个类似于InfiniBand的开放协议生态,从技术层面可以理解为将Ethernet进行增强以达到InfiniBand网络的性能,或者说是实现一种InfiniBand化的Ethernet。从某种意义上说UEC在重走InfiniBand道路。总线域网络NVLink的主要特征是要在超节点范围内实现内存语义级通信和总线域网络内部的内存共享,它本质上是一个Load-Store网络,是传统总线网络规模扩大以后的自然演进。从NVLink接口的演进历程可以看出,其1.0~3.0版本明显是对标PCIE的,而4.0版本实际上对标InfiniBand和Ethernet的应用场景,但其主要目标还是实现GPU的Scale Up扩展。
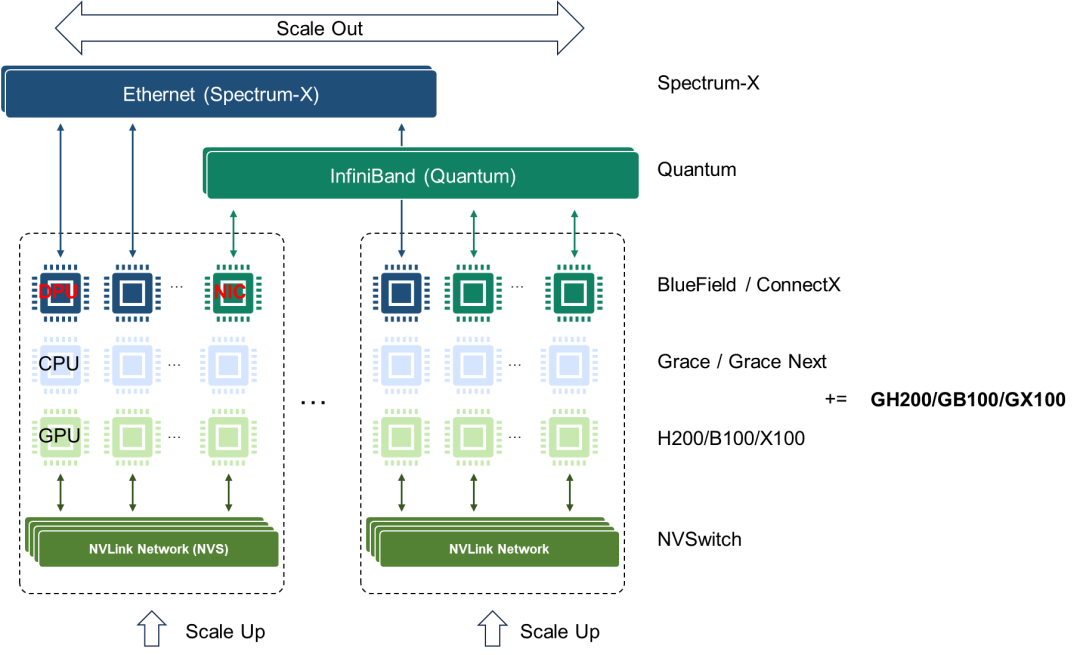
从原始需求的角度来看,NVLink网络在演进过程中需要引入传统网络的一些基本能力,例如编址寻址、路由、均衡、调度、拥塞控制、管理控制和测量等。同时,NVLink还需要保留总线网络基本特征,如低时延、高可靠性、内存统一编址共享以及内存语义通信。这些特征是当前InfiniBand或Ethernet网络所不具备的或者说欠缺的。与InfiniBand和Ethernet传统网络相比,NVLink总线域网络的功能定位和设计理念存在着本质上的区别。我们很难说NVLink网络和传统InfiniBand网络或者增强Ethernet网络最终会殊途同归。
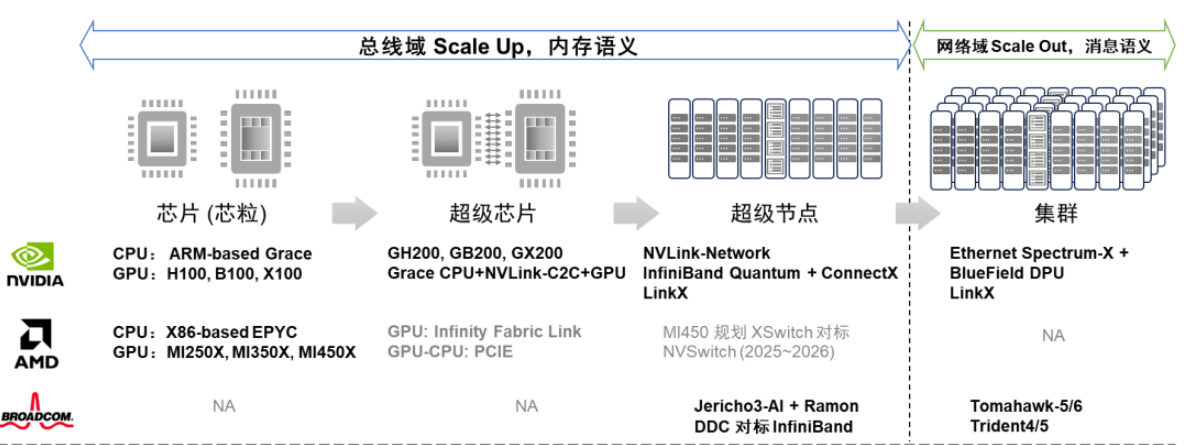
Nvidia在AI集群竞争态势中展现出了全面布局,涵盖了计算(芯片、超级芯片)和网络(超节点、集群)领域。在计算芯片方面,Nvidia拥有CPU、GPU、CPU-CPU/CPU-GPU SuperChip等全面的布局;在超节点网络层面,Nvidia提供了NVLink和InfiniBand两种定制化网络选项;在集群网络方面,Nvidia有基于Ethernet的交换芯片和DPU芯片布局。AMD紧随其后,更专注于CPU和GPU计算芯片,并采用基于先进封装的Chiplet芯粒技术。
与Nvidia不同的是,AMD当前没有超级芯片的概念,而是采用了先进封装将CPU和GPU Die合封在一起。AMD使用私有的Infinity Fabric Link内存一致接口进行GPU、CPU、GPU和CPU间的互联,而GPU和CPU之间的互联仍然保留传统的PCIE连接方式。此外,AMD计划推出XSwitch交换芯片,下一代MI450加速器将利用新的互连结构,其目的显然是与Nvidia的NVSwitch竞争 [15]。
BRCM则专注于网络领域,在超节点网络有对标InfiniBand的Jericho3-AI+Ramon的DDC方案;在集群网络领域有基于Ethernet的Tomahawk系列和Trident系列交换芯片。近期BRCM推出其新的软件可编程交换Trident 5-X12集成了NetGNT神经网络引擎实时识别网络流量信息,并调用拥塞控制技术来避免网络性能下降,提高网络效率和性能 [16]。Cerebras/Telsa Dojo则“剑走偏锋”,走依赖“晶圆级先进封装”的深度定制硬件路线。
作者:陆玉春
审核编辑:黄飞
-
《AI芯片:科技探索与AGI愿景》—— 勾勒计算未来的战略罗盘2025-09-17 3101
-
嵌入式Linux_Android的学习路线图2023-09-27 852
-
有关芯片光刻路线图的一些知识分享2022-07-10 4838
-
Rockchip处理器路线图及芯片选型2021-06-02 1703
-
嵌入式软件学习的路线图2021-02-04 2405
-
Intel公布2021年CPU架构路线图及封装技术2020-11-02 2590
-
物联网学习路线图2020-04-20 3910
-
嵌入式学习路线图分享2018-07-13 2949
-
韦东山嵌入式Linux+Android学习路线图 pdf 下载2017-09-18 79807
-
求STM32的成长路线图2015-05-12 2696
-
嵌入式学习指导路线图2013-08-15 21602
-
嵌入式学习路线图2012-08-16 40651
-
白炽灯淘汰路线图2011-11-06 4444
-
freescale汽车产品路线图2011-01-06 629
全部0条评论

快来发表一下你的评论吧 !
