

如何应对工业缺陷检测数据短缺问题?
工业控制
描述
作者:Mingyu Lee,Jongwon Choi等
作者机构:Dept. of Advanced Imaging, GSAIM, Chung-Ang University, Seoul, Korea等
这篇文章提出了一种文本引导的变分图像生成方法,旨在解决工业制造中异常检测数据清洁的挑战。该方法利用文本信息生成类似输入图像的非缺陷数据图像,确保生成图像与预期分布相一致。实验证明,即使有限的非缺陷数据,该方法也比先前的方法更有效。通过在多个模型和数据集上进行验证,证实了该方法的通用性和稳定性。另外,利用生成的图像还可以增强异常检测模型的有效性。
读者理解:
这篇文章提出了一种解决大规模工业制造中异常检测任务中数据短缺问题的新框架。该框架包括方差感知图像生成器、关键词到提示生成器和文本引导知识整合器。作者通过实验验证了该框架在不同场景下的有效性,特别是在只有单个非缺陷图像的情况下。实验结果显示,该框架可以有效地进行异常检测和分割,即使在缺乏数据的工业环境中也能取得令人印象深刻的性能。文章指出,通过保持非缺陷图像的特征来提高性能,并且即使在非缺陷图像数量有限的情况下,也能避免与缺陷图像混合的问题。
1 引言
这篇论文介绍了一种文本引导的变分图像生成方法,旨在解决工业制造中的异常检测和分割问题。传统方法通过训练非缺陷数据的分布来进行异常检测,但这需要大量且多样化的非缺陷数据。该方法利用文本信息生成类似输入图像的非缺陷数据图像,并确保生成的图像与预期分布相一致。实验证明,即使只有少量非缺陷数据,该方法也优于先前方法。
文章提出了四点贡献:
开发了一种基于变分的图像生成器,用于预测和保留非缺陷图像的方差;
开发了关键词到提示生成器,解决了好产品数据缺乏多样性的问题;
开发了基于文本引导的知识整合器方法,弥合了不同模态之间的语义鸿沟;
将方法应用于几种最先进的算法,并在各种真实工业数据集上进行了测试,结果表明,即使只有少量非缺陷图像,该方法也表现出色。
2 初步分析
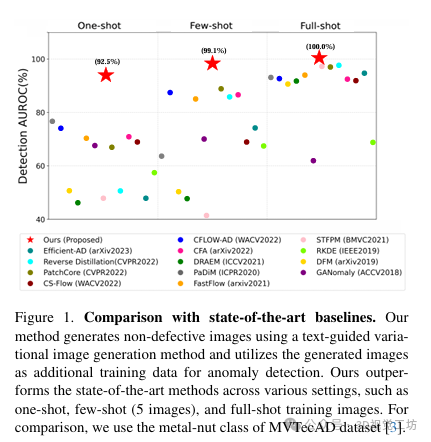
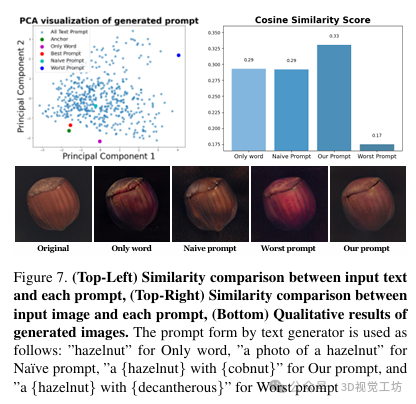
本节介绍了针对异常检测任务的新生成图像方法的初步实验。实验比较了基准异常检测模型和使用额外训练图像的相同模型的性能。实验使用了来自MVTecAD数据集的单个榛子图像,并利用了各种生成图像方法。实验结果表明,性能受生成图像的影响。有趣的是,良好的图像质量并不一定有助于提高性能。在保留原始图像的关键元素的情况下,可以提高性能。因此,为了有效地训练生成图像的非缺陷分布,需要考虑几个因素:生成的图像应该与提供的非缺陷图像的外观类似,同时保留其视觉变化;找到生成视觉结构良好的图像的最佳提示非常重要;基于上述两种信息内容,即使给出了不足数量的非缺陷图像,也应该创建具有小语义差距的图像。
3 方法
本节介绍了本文的方法,包括关键词到提示生成器、方差感知图像生成器和文本引导知识整合器。关键词到提示生成器根据输入文本中的关键词生成一组提示,然后选择最佳提示,其中包含与输入图像相似的信息。方差感知图像生成器将非缺陷图像的视觉特征编码到正态分布中,以保持它们的方差,并通过生成器更新迭代生成图像。文本引导知识整合器通过评估生成的文本提示与图像集之间的潜在分布相似性,确定最佳的生成图像集合。最后,生成的图像集合被用作基准异常检测模型的额外训练集。
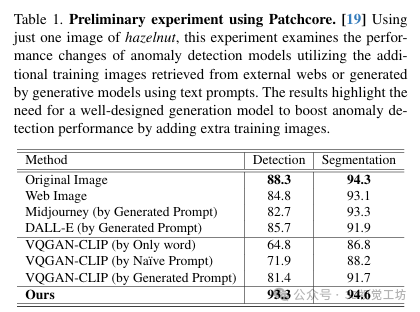
3.1 生成模块
这部分介绍了生成模块,包括关键词到提示生成器和方差感知图像生成器。关键词到提示生成器通过将目标对象名称与一组预定义状态词结合起来,生成多个候选提示,并选择与原始图像潜在特征最相似的最佳提示。然后,将输入图像转换为多个增强图像,并馈送到方差感知图像生成器中。方差感知图像生成器将图像编码到相应的潜在分布中,以保持它们的方差。最后,通过采样解码生成一组新的图像。关键词到提示生成器利用 WordNet 构建了一组不同的词,通过计算候选提示与原始图像之间的距离来选择最佳提示。方差感知图像生成器基于 VQGAN 模型,扩展了其架构以预测潜在变量的方差,从而有效地表示图像的外观多样性。
3.2 文本引导的知识集成器
在这个过程中,作者使用文本引导知识集成器生成与最佳提示相匹配的非缺陷图像,并将它们添加到用于异常检测模型的非缺陷数据池中。首先,从关键词到提示生成器中选择最佳提示,并通过 Clip 文本编码器提取文本剪辑特征。同时,通过方差感知图像生成器生成一组图像,并通过对图像特征求平均来估计视觉剪辑特征。接着,文本引导知识集成器通过余弦相似度评分选择最佳生成图像集合,用于训练异常检测模型。在生成新图像集合的每次迭代中,同时更新方差感知图像生成器,以便生成与输入非缺陷图像相似的图像,并增强生成图像集合的多样性。最后,通过利用均方误差损失和传统 VQGAN 损失来训练模型,并使用 Adam 优化器更新方差感知图像生成器的参数。
4 实验
在这项研究中,提出了一种新颖的框架,通过结合文本引导和图像生成来增强异常检测性能。以下是实验的详细总结:
基线和数据集:选择了几种基线模型,包括Patchcore、Cflow、EfficientAD和Reverse Distillation,并在MVTecAD、MVTecADloco和BTAD数据集上进行了比较分析。这些数据集包含了各种对象和纹理的图像,以及实际工业产品的缺陷图像。
实现细节:使用了每个基线模型的原始设置,并使用预训练的ResNet-18模型作为默认骨干网络。还初始化了方差感知图像生成器,并使用了预训练的CLIP模型。每次迭代生成20张图像,训练时间平均为182.6秒。
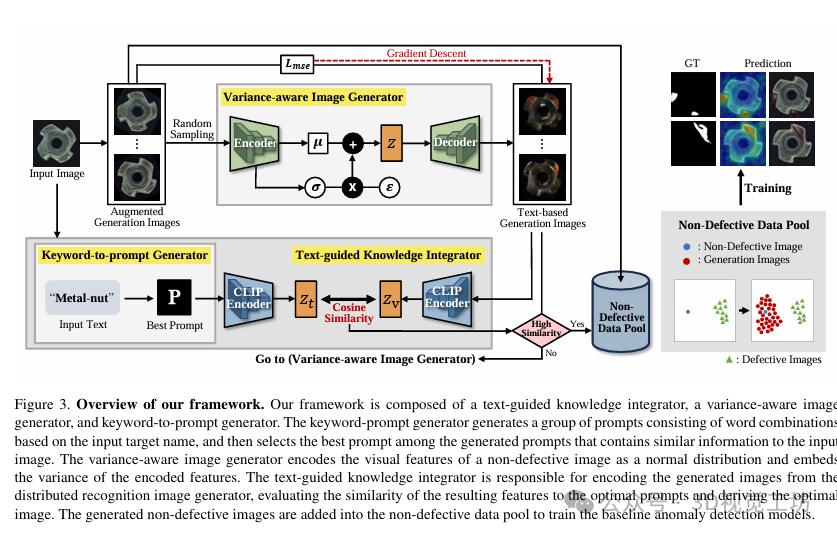
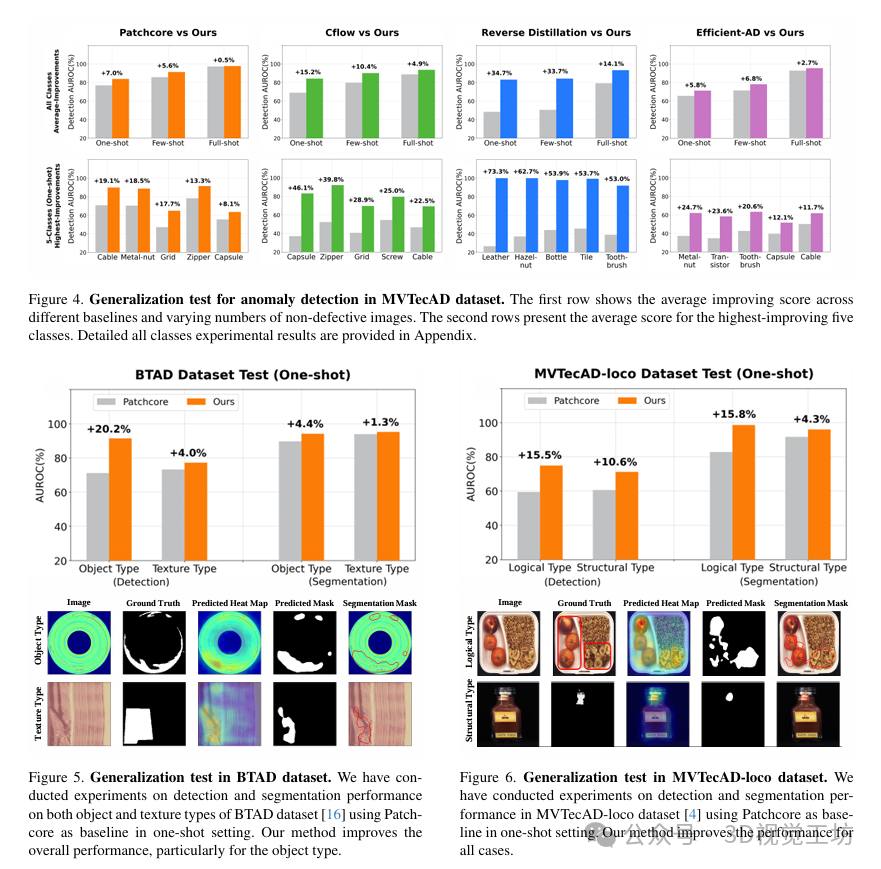
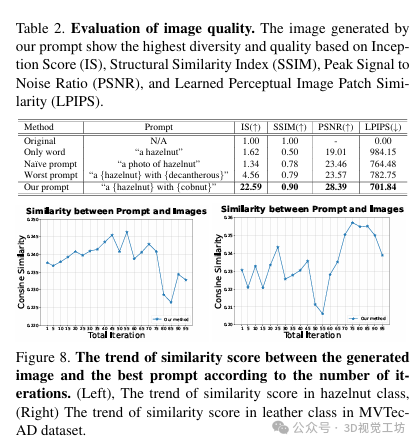
定量结果:通过将最新的基线模型应用于MVTecAD数据集,对本文设计的框架进行了性能比较。结果显示,本文的框架在一次、少量和完整训练任务中都取得了显著的性能提升,验证了其泛化能力。此外,作者还分析了在一次训练任务中性能提升最高的五个类别。
实验分析:作者进行了实验分析,验证了本文提出的模块的有效性,并发现了添加生成图像的额外启示。作者还对文本生成图像的数量对文本生成器性能的影响进行了分析,并发现过多的非缺陷数据可能会成为数据表达中的重要噪声。
优化结果:本文可视化了关键词到提示生成器成功找到最佳提示以及方差感知图像生成器和文本引导知识整合器基于最佳提示生成的图像结果。结果表明,作者的提示具有接近非缺陷图像的特征,并且可以提高基于文本的知识整合模块的性能。
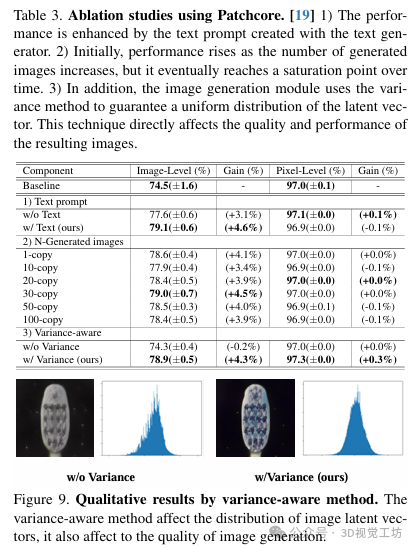
消融研究:进行了消融研究,评估了作者方法各组件的影响。结果显示,本文的方法相比基线提高了4.6%。还分析了文本生成图像的数量对文本生成器性能的影响,并发现随着生成图像数量的增加,模型性能不断提高,但最终趋于饱和。
5 总结
这个实验主要是为了解决大规模工业制造中异常检测任务中数据短缺的问题。研究提出了一个新的框架,包括方差感知图像生成器、关键词到提示生成器和文本引导知识整合器。通过广泛的实验,使用四种基线模型和三个数据集进行比较分析。实验结果表明,该框架在所有假设场景下表现出色,尤其是在单个非缺陷图像的情况下。研究发现,潜变量的均匀分布有助于通过在再生过程中保持非缺陷图像的特征来提高性能。通过基于文本的多模态模型,该框架在工业环境中有效执行异常检测和分割的潜力得到展示。此外,即使在有限数量的非缺陷图像下,该方法也表现出色,这使本文能够在有效收集大规模非缺陷图像集的同时避免与缺陷图像交织的问题。
审核编辑:黄飞
-
缺陷检测在工业生产中的应用2015-11-18 3913
-
如何应对硬件缺陷?2019-10-10 1775
-
[转]产品表面缺陷检测2020-08-07 2397
-
机器视觉检测系统在薄膜表面缺陷检测的应用2020-10-30 2344
-
有需要图像识别处理,工业视觉检测,缺陷检测,故障检测的可以咨询联系2021-03-02 1310
-
表面检测市场案例,SMT缺陷检测2022-11-08 1534
-
工业相机:表面缺陷检测系统的优势2020-11-17 3658
-
基于深度学习的工业缺陷检测方法2022-07-30 3898
-
工业缺陷检测场景简介2023-02-17 3509
-
蔡司工业CT检测铸件缺陷2023-06-07 1522
-
工业CT内部缺陷扫描检测设备2023-08-10 2125
-
工业产品表面缺陷检测方法研究2023-08-17 2563
-
深度学习在工业缺陷检测中的应用2023-10-24 4651
-
工业视觉缺陷检测的算法总结2023-11-14 2150
-
描绘未知:数据缺乏场景的缺陷检测方案2024-01-25 1405
全部0条评论

快来发表一下你的评论吧 !
