

人工智能、机器学习、深度学习之间有何关系?
描述
说到近些年的火热名词,“人工智能”必须榜上有名。随着去年ChatGPT爆火出圈,“AI(Artificial Intelligence,人工智能)”屡次霸屏热搜榜,并被英国词典出版商柯林斯评为2023年的年度词。
除了“人工智能”,我们还经常听到“机器学习”、“深度学习”…… 这些术语都是啥意思?它们之间有什么关系呢?
人工智能——Artificial Intelligence
说到人工智能,大家的第一反应可能是科幻电影里那些拥有人类智慧的机器人,但实际上,人工智能可不仅仅是机器人哦。
人工智能是由约翰·麦卡锡(John McCarthy)于1956年提出来的,当时的定义是“制造智能机器的科学与工程”。 现在的人工智能是指“研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学”。 总结一下:人工智能就是让机器能够模拟人类的思维能力,让机器能像人一样去感知、思考甚至决策。 时至今日,人工智能已经不再是一门单纯的学科,而是涉及了计算机、心理学、语言学、逻辑学、哲学等多个学科的交叉领域。
人工智能看起来是高深的科技,实际上是一个覆盖范围很广的概念。我们的身边,早就有了各种人工智能,例如:自动驾驶、人脸识别、智能机器人、机器翻译等等。
面对多种多样的人工智能,我们按照人工智能的实力,可将其分成三类:
弱人工智能(Artificial Narrow Intelligence,ANI)
擅长于某个方面的人工智能,只能执行特定的任务。 例如,人脸识别系统就只能识别图像,你要是问它明天天气怎么样,它可不知道怎么回答。
强人工智能(Artificial General Intelligence,AGI)
类似于人类级别的人工智能,能够在多个领域表现出类似于人的智慧,能理解、学习和执行各种任务。 强人工智能也叫通用人工智能(Artificial General Intelligence,AGI)。 ChatGPT之所以是划时代的进展,就是因为它能写诗能做数学题还能编代码,已经基本可以被称作强人工智能了。
超人工智能(Artificial Superintelligence,ASI)
超越人类智慧的人工智能,在各个领域都比人类聪明,可以执行任何智力任务并且在许多方面超越人类。 尽管超人工智能在科幻作品中经常出现,但在实际中只是一个理论概念,目前还没有实现的可能。
说到这里,问大家一个问题,打败围棋世界冠军的AlphaGo属于什么人工智能呢?
机器学习——Machine Learning
前面提到,人工智能的目的是让机器能够像人一样思考并决策,到底如何实现呢?
回想一下,我们刚出生时基本上什么都不会,经过了几十年的学习,我们学会了各种知识、技能。 机器也是一样的,要让它会思考,就要让它先学习,从经验中总结规律,进而拥有一定的决策和辨别能力,这就是人工智能的核心——机器学习。
机器学习专门研究计算机怎样模拟或实现人类的学习行为,通过学习获取新的知识、技能,从而重新组织已有的知识结构,不断改善自身性能。
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、算法复杂度理论等多门学科。
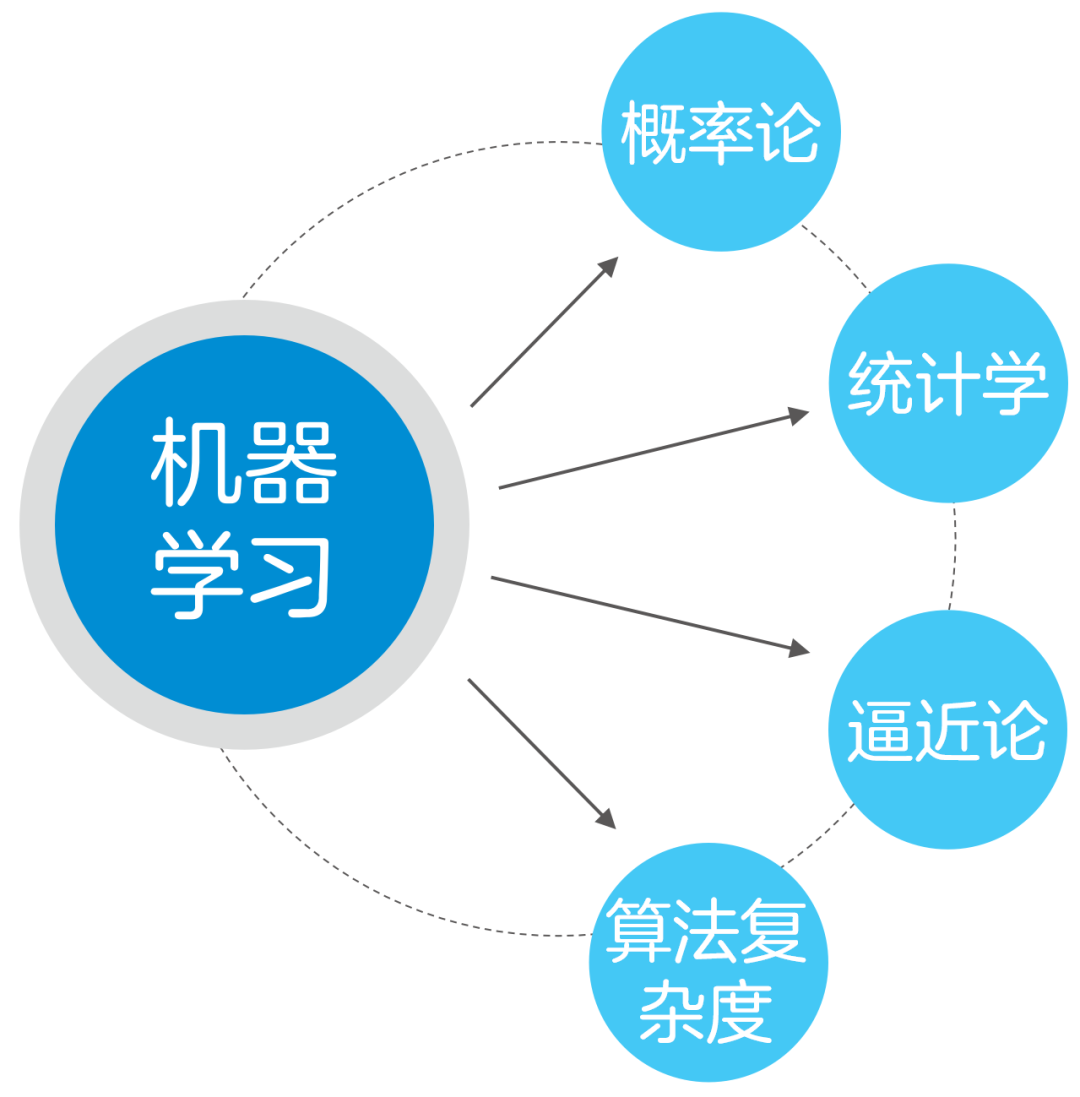
机器是怎样学习的呢?我们先来看一下人的学习过程:
上课:学习理论知识,进行知识输入
总结复习:通过复习,强化理解
梳理知识框架:整理知识,形成体系
课后作业:通过练习,进一步加深理解
每周测验:检查掌握情况
查漏补缺:改善学习方法
期末考试:检查最终学习成果
机器的学习过程也是类似的,包括以下7个步骤:
数据获取:收集相关的数据
数据处理:对数据进行转换,统一数据格式
模型选择:选择适合的算法
模型训练:使用数据训练模型,优化算法
模型评估:根据预测结果评估模型性能
模型调整:调整模型参数,优化模型性能
模型预测:对未知结果数据进行预测
简而言之,机器学习就是从数据中通过算法自动归纳逻辑或规则,并根据归纳的结果与新数据来进行预测。
举个例子,如果我们想让计算机看到狗时能判断出是狗,就需要给计算机展示大量狗的图片,同时告诉它这就是狗。 经过大量的训练,计算机会总结出一定的规律,当下次看到狗时,捕捉到对应的特征,得出“这是狗”的结论。 如果算法不够完善,可能会把猫误认为狗,这就需要计算机通过经验数据自动改进算法,从而增强预测能力。
按照学习方式,机器学习可分为以下四类:
监督学习
从有标记的数据中学习,即数据中包含自变量和因变量,通过学习已知的输入和输出数据来进行预测,如分类任务和回归任务。
分类任务:预测数据所属的类别,如垃圾邮件检测 、识别动植物类别等。
回归任务:根据先前观察到的数据预测数据,如房价预测,身高体重预测等。
无监督学习
分析没有标签的数据,即数据中只有自变量没有因变量,发现数据的规律,如聚类、降维等。
聚类:把相似的东西聚在一起,并不关注这类东西是什么,如客户分组。
降维:通过提取特征,将高维数据压缩用低维表示,如将汽车的里程数和使用年限合并为磨损值。
半监督学习
训练数据只有部分有标记,先使用无监督学习对数据进行处理,再用监督学习对模型进行训练和预测。 例如手机可以识别同一个人的照片(无监督学习),当把同一个人的照片打上标签后,之后新增的这个人的照片也会自动加上对应的标签(监督学习)。
强化学习
通过与环境进行交互,根据奖励或惩罚来优化算法,直到获得最大奖励,产生最优策略。例如扫地机器人撞到障碍物后,会优化清扫路径。
深度学习——Deep Learning
通过上面的了解,相信大家对机器学习已经不陌生了。那么深度学习又是个啥?跟机器学习有什么关系?
深度学习是机器学习领域的一个新的研究方向,是一种通过多层神经网络来学习和理解复杂数据的算法。 机器通过学习样本数据的深层表示来学习复杂任务,最终能够像人一样具有分析学习能力,能够识别文字、图像和声音等。
深度学习使用了神经网络结构,神经网络的长度称为模型的“深度”,因此基于神经网络的学习被称为“深度学习”。 神经网络模拟了人类大脑的神经元网络,神经元节点可以对数据进行处理和转换。通过多层神经网络,数据的特征可以被不断地提取和抽象,从而使机器能更好地解决各种问题。
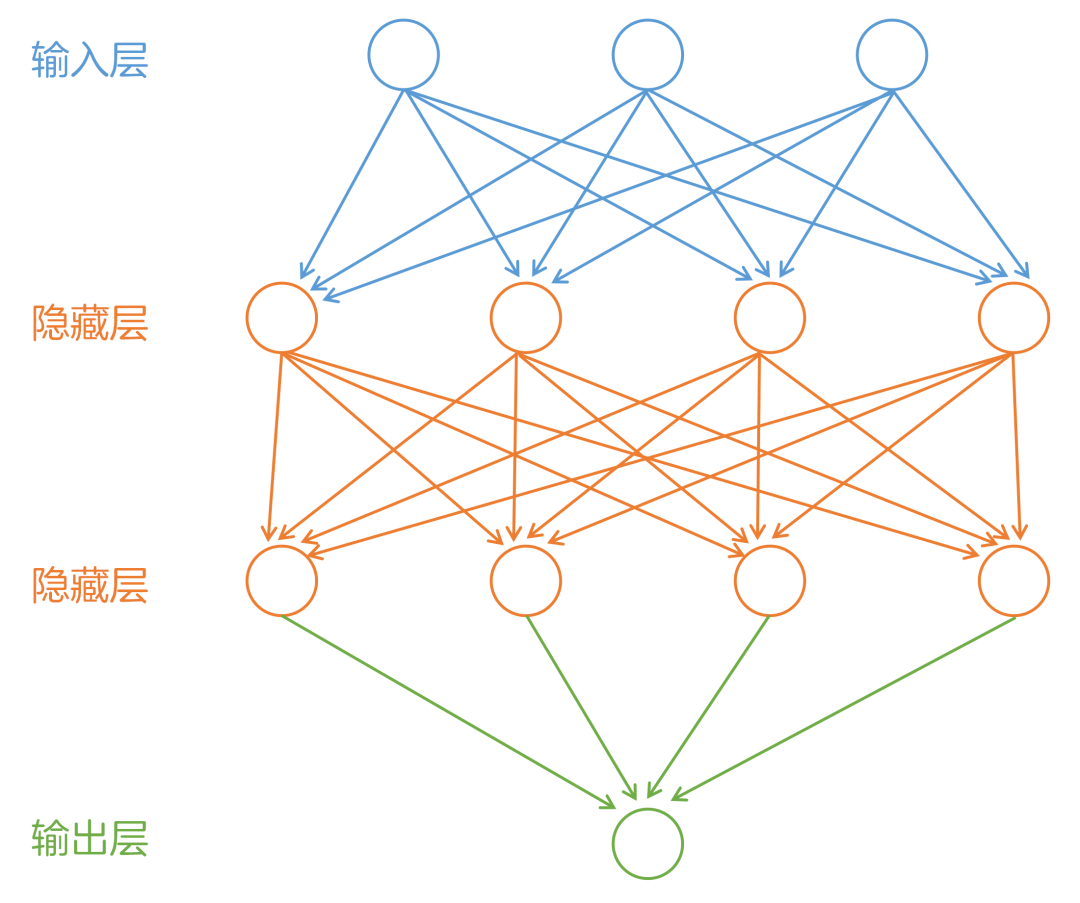
典型的深度学习算法有以下四种类型:
卷积神经网络(Convolutional Neural Network,CNN):常用于图像识别和分类任务。
递归神经网络(Recurrent Neural Network,RNN):适用于处理序列数据,如自然语言处理。
长短期记忆网络(Long Short-Term Memory,LSTM):一种特殊的RNN结构,能够更好地处理长序列数据。
生成对抗网络(Generative Adversarial Network,GAN):用于生成新的数据,如图像、音频或文本。
在深度学习的加持下,人工智能得以快速发展,相信在不久的将来,我们将拥有一个全新的AI时代。
结束语
总结一下:
“人工智能”是一个广泛的概念,目的是让机器像人一样思考和执行任务。
“机器学习”是实现人工智能的一种方法,目的是从数据中学习规律,传统的机器学习需要人工确定数据特征。
“深度学习”是机器学习的一个特定分支,基于神经网络,能够自动学习数据特征。
审核编辑:刘清
-
人工智能和机器学习的前世今生2018-08-27 3620
-
人工智能、数据挖掘、机器学习和深度学习的关系2020-03-16 2884
-
python人工智能/机器学习基础是什么2020-04-28 3261
-
人工智能基本概念机器学习算法2021-09-06 2808
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 4732
-
人工智能深度学习和机器学习的基础知识及其关系2017-11-15 17124
-
人工智能、机器学习、深度学习三者关系分析2018-01-04 7909
-
浅谈人工智能,机器学习,深度学习三者关系2018-07-01 2501
-
人工智能、机器学习、深度学习有什么关系?2018-06-08 13531
-
从概念和特点上阐述机器学习和深度学习的关系2019-01-24 9456
-
机器学习与深度学习之间比较2019-05-11 4729
-
人工智能/机器学习/深度学习的关系2021-01-03 9351
-
机器学习与人工智能和深度学习有什么关系?2021-01-12 4997
-
人工智能与机器学习、深度学习的区别2023-03-29 2720
-
机器学习和深度学习的区别2023-08-17 5979
全部0条评论

快来发表一下你的评论吧 !
