

Cerebras推出WSE-3 AI芯片,比NVIDIA H100大56倍
描述
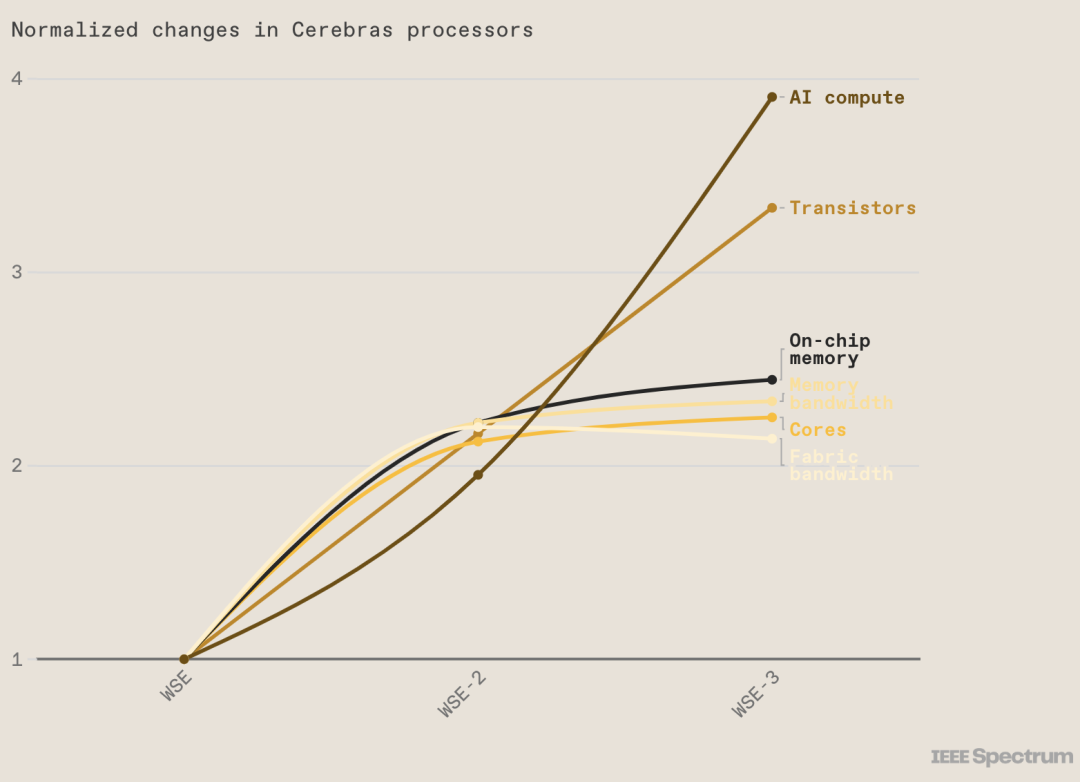
Cerebras 是一家位于美国加利福尼亚州的初创公司,2019 年进入硬件市场,其首款超大人工智能芯片名为 Wafer Scale Engine (WSE) ,尺寸为 8 英寸 x 8 英寸,比最大的 GPU 大 56 倍,拥有 1.2 万亿个晶体管和 40 万个计算核心,是当时最快、最大的 AI 芯片。随后在 2021 年,Cerebras 推出了 WSE-2,这是一款 7 纳米芯片,其性能是原来的两倍,拥有 2.6 万亿个晶体管和 85 万个核心。
近日,Cerebras 宣布推出了第三代WSE-3,性能再次提高了近一倍。
01
Cerebras 推出 WSE-3 AI 芯片,比 NVIDIA H100 大 56 倍 WSE-3采用台积电5nm工艺,拥有超过4万亿个晶体管和90 万个核心,可提供 125 petaflops 的性能。这款芯片是台积电可以制造的最大的方形芯片。WSE-3拥有44GB 片上 SRAM,而不是片外 HBM3E 或 DDR5。内存与核心一起分布,目的是使数据和计算尽可能接近。
自推出以来,Cerebras 就将自己定位为英伟达GPU 驱动的人工智能系统的替代品。这家初创公司的宣传是:他们可以使用更少的芯片在 Cerebras 硬件上进行 AI训练,而不是使用数千个 GPU。据称,一台Cerebras服务器可以完成与 10 个 GPU 机架相同的工作。
下图是Cerebras WSE-3和英伟达 H100的对比。 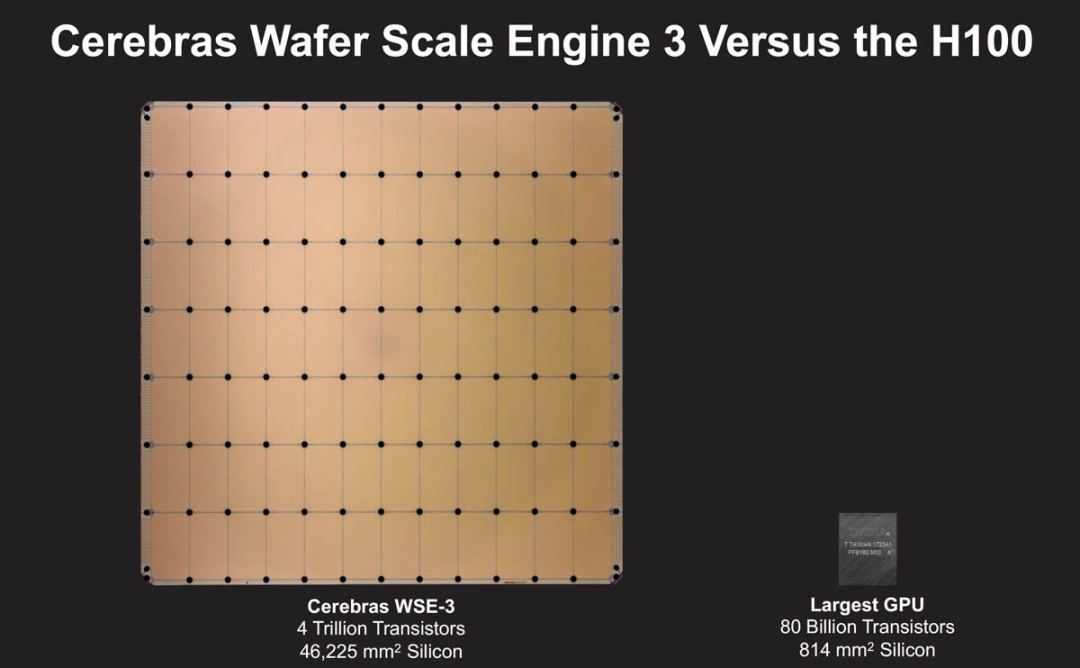
Cerebras 的独特优势是将整个硅片直接转化为单一巨大的处理器,从而大幅提升计算性能和效率。英伟达、AMD、英特尔等公司往往会把一块大晶圆切成多个小的部分来制造芯片,在充斥着 Infiniband、以太网、PCIe 和 NVLink 交换机的英伟达GPU 集群中,大量的功率和成本花费在重新链接芯片上,Cerebras的方法极大地减少了芯片之间的数据传输延迟,提高了能效比,并且在AI和ML任务中实现了前所未有的计算速度。
02
Cerebras CS-3 系统
Cerebras CS-3 是第三代 Wafer Scale 系统。其顶部具有 MTP/MPO 光纤连接,以及用于冷却的电源、风扇和冗余泵。该系统及其新芯片在相同的功耗和价格下实现了大约 2 倍的性能飞跃。 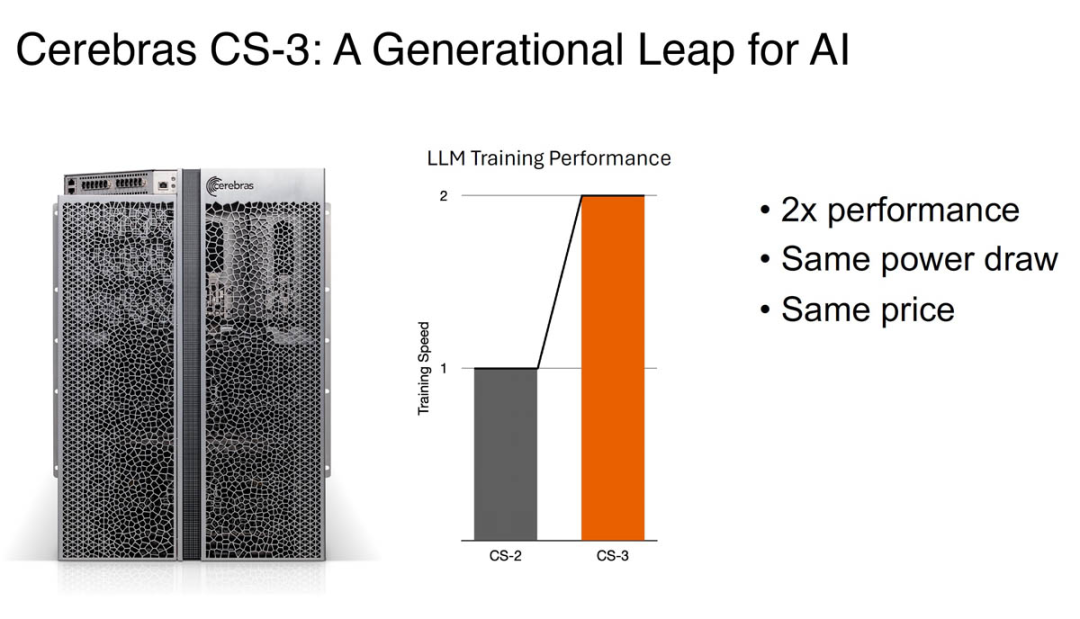
Cerebras WSE-3 的核心数量是英伟达的 H100 Tensor Core 的 52 倍。与 Nvidia DGX H100 系统相比,由 WSE-3 芯片驱动的 Cerebras CS-3 系统的训练速度提高了 8 倍,内存增加了 1,900 倍,并且可以训练多达 24 万亿个参数的 AI 模型,这是其 600 倍。Cerebras 高管表示,CS-3的能力比 DGX H100 的能力还要大。在 GPU 上训练需要 30 天的 Llama 700 亿参数模型,使用CS-3 集群进行训练只需要一天。 
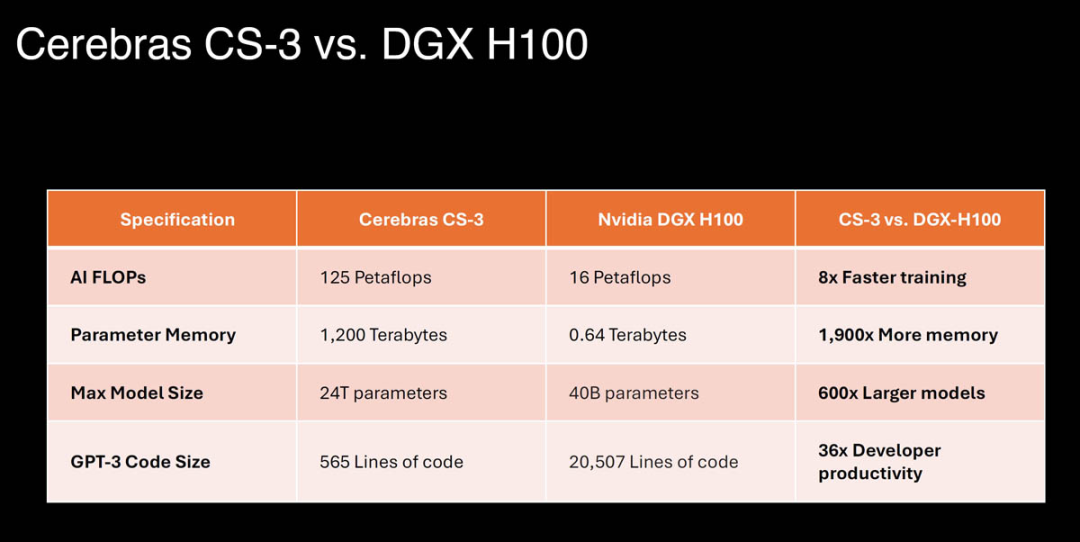
CS-3可以配置为多达2048个系统的集群,可实现高达 256 exaFLOPs 的 AI 计算,专为快速训练 GPT-5 规模的模型而设计。 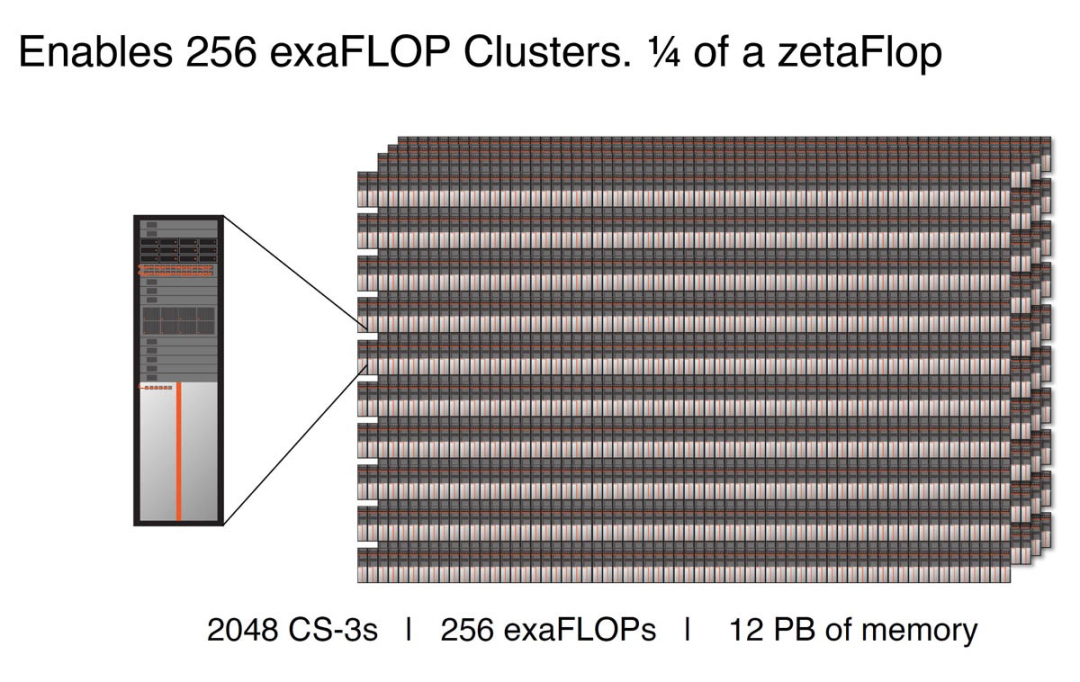
Cerebras CS-3 适用于 2048 节点 256EF 集群 
适用于 GPT 5 规模的 Cerebras CS-3 集群
03
Cerebras AI编程
Cerebras 声称其平台比英伟达的平台更易于使用,原因在于 Cerebras 存储权重和激活的方式,Cerebras 不必扩展到系统中的多个 GPU,然后扩展到集群中的多个 GPU 服务器。 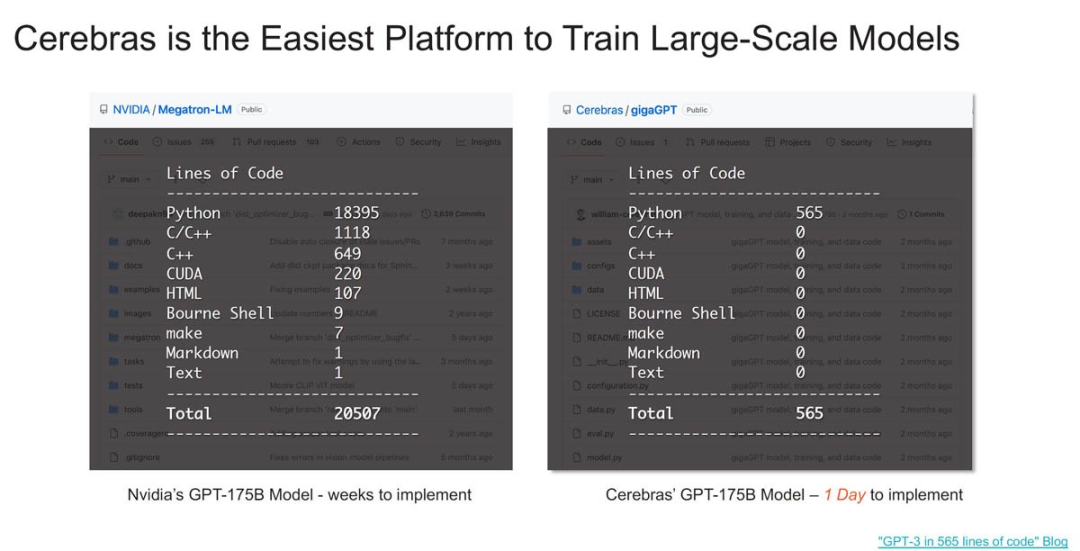
除了代码更改很容易之外,Cerebras 表示它的训练速度比 Meta GPU 集群更快。当然,这只是理论上数据,当前还没有任何 2048 个 CS-3 集群已经投入运行,而 Meta 已经有了 AI GPU 集群。 
Llama 70B Meta VS Cerebras CS-3 集群
04
Cerebras 与高通合作开发人工智能推理
Cerebras 和高通建立了合作伙伴关系,目标是将推理成本降低 10 倍。Cerebras 表示,他们的解决方案将涉及应用神经网络技术,例如权重数据压缩等。该公司表示,经过 Cerebras 训练的网络将在高通公司的新型推理芯片AI 100 Ultra上高效运行。
这项工作使用了四种主要技术来定制 Cerebras 训练的模型:
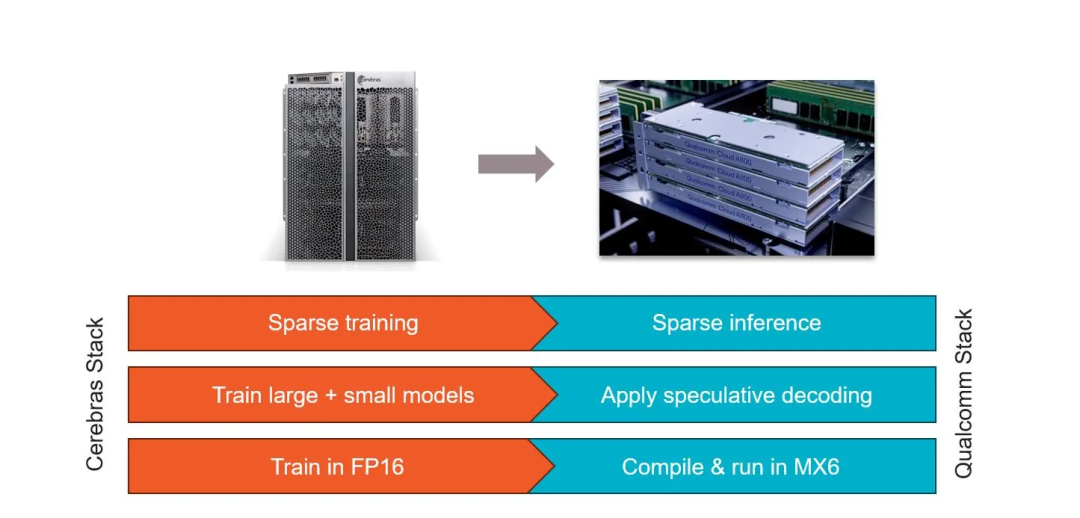
稀疏性是 Cerebras 的秘密武器之一,Cerebras 能够在训练过程中利用动态、非结构化的稀疏性。高通的 Cloud AI100 具有对非结构化稀疏性的硬件支持,这种稀疏协同可以使性能提高2.5倍。
推测解码是一种前景广阔但迄今为止难以有效实施的行业技术,也被用来加快速度。这种技术使用一个大型LLM和一个小型LLM的组合来完成一个大型LLM的工作。小模型不太精确,但效率较高。大模型用于检查小模型的合理性。总体而言,组合效率更高,由于该技术总体上使用的计算量较少,因此速度可以提高 1.8 倍。
权重压缩为 MxFP6,这是一种行业 6 位微指数格式,与 FP16 相比,可节省 39% 的 DRAM 空间。高通的编译器将权重从 FP32 或 FP16 压缩为 MxFP6,Cloud AI100 的矢量引擎在软件中执行即时解压缩到 FP16。该技术可以将推理速度提高 2.2 倍。
神经架构搜索(NAS)是一种推理优化技术。该技术在训练期间考虑了目标硬件(Qualcomm Cloud AI 100)的优点和缺点,以支持在该硬件上高效运行的层类型、操作和激活函数。Cerebras 和 Qualcomm 在 NAS 方面的工作使推理速度提高了一倍。
审核编辑:刘清
-
世界第一AI芯片发布!世界纪录直接翻倍 晶体管达4万亿个2024-03-21 1387
-
Cerebras推出性能翻倍的WSE-3 AI芯片2024-03-20 2091
-
最强AI芯片发布,Cerebras推出性能翻倍的WSE-3 AI芯片2024-03-19 2823
-
Cerebras发布WSE-3 AI芯片,性能翻倍达4万亿晶体,能耗不变2024-03-18 2096
-
AI芯片界掀起狂潮,WSE-3性能飙升刷新纪录!2024-03-15 1942
-
Cerebras推WSE-3芯片,性能翻倍,助力超大规模AI模型训练2024-03-14 1874
-
英伟达发布新一代H200,搭载HBM3e,推理速度是H100两倍!2023-11-15 6907
-
传英伟达新AI芯片H20综合算力比H100降80%2023-11-13 4287
-
英伟达h800和h100的区别2023-08-08 57866
-
关于NVIDIA H100 GPU的问题解答2022-07-18 3198
-
NVIDIA发布最新Hopper架构的H100系列GPU和Grace CPU超级芯片2022-03-26 4152
-
GTC2022大会亮点:NVIDIA发布全新AI计算系统—DGX H1002022-03-24 2693
-
NVIDIA发布新一代产品—NVIDIA H1002022-03-23 3762
-
Cerebras Systems展示了 AI 芯片 WSE2020-07-09 2464
全部0条评论

快来发表一下你的评论吧 !
