

基于高光谱成像技术的山楂产地判别建模分析
电子说
描述
山楂(Crataegus Pinnatifida)是蔷薇科山楂属植物,是典型的“药食同源”植物,在我国广泛分布于吉林、辽宁、河北、河南、山东、山西等地区。我国山楂年产量超过 150万吨,市场前景广阔,但由于不同产地的山楂中各类营养成分含量存在差异,因此其在价格上也有所区分,而当今山楂市场上产地混用、以次充好等现象屡见不鲜,使许多消费者上当受骗,这些现象严重破坏了市场秩序。因此,目前市场亟需一种能够快速准确对山楂进行产地溯源的方法。
为满足市场需求,本文旨在探究高光谱成像技术在山楂产地识别中的应用及不同采样方向对于模型分类性能的影响,利用高光谱成像系统(410~2500 nm),分别采集山楂样本果梗面、侧面及底面的光谱数据,结合多种机器学习算法分别建立产地识别模型,最终实现基于高光谱成像技术对山楂进行产地溯源的目的。
续
二、结果与分析
2.3 基于全波段的建模分析
2.3.1预处理及分类建模方法
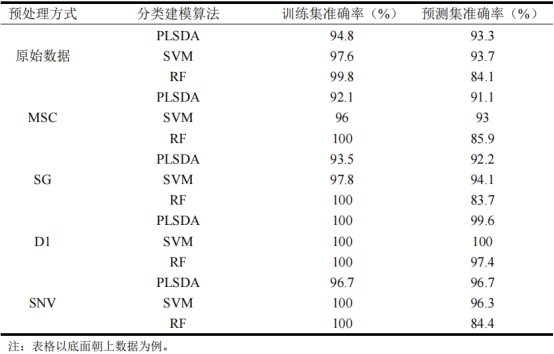
筛选为筛选出最佳预处理和分类建模方法,分别采用4种预处理方法和3种分类建模方法建立模型,以样本底面数据为代表,各模型分类准确率见表1。对比四种预处理数据分类模型准确率可以发现,引入预处理方法之后,大部分模型的分类精度得到了提高,而D1对于三种分类模型(PLSDA、SVM和RF)均为最优预处理方式。对比三种不同模型(PLSDA、SVM和RF)分类准确率,发现无论采用哪种预处理方式,采用RF建立的分类模型虽然有较高的训练集准确率,但是预测集准确率一般;采用PLSDA和SVM建立的分类模型训练集和预测集准确率良好,其中以SVM模型分类准确率最高。综上所述,对于底面数据,D1为最佳预处理方式,采用SVM建立的分类模型分类准确率高,且具有优秀的稳定性和泛化能力。为进一步验证结论,分别使用C和G数据集进行建模对比,均呈现相同的规律,故判断D1为最优预处理方式,SVM为最佳分类建模算法,后续均采用D1-SVM(经D1预处理后建立的SVM模型)方式进行分类建模。
表1不同预处理分类模型准确率
2.3.2不同采样方式分类建模分析
本研究为探究不同采样方向对模型分类结果的影响,分别收集了样本侧面朝上(C)、果梗面朝上(G)和底面朝上(D)的高光谱图像。同时为模拟实际应用时随机拍摄到的高光谱数据,将三个数据集进行等比混合建立一个新数据集(R),使用四个数据集分别进行分类建模,建模方法均采用D1-SVM,综合对比各项指标筛选出最优模型。各模型分类准确率结果见表2。
对于使用R数据集建立的分类模型,其准确率较高(100%,96.7%),根据图4d并由公式(3)和公式(4)计算得出,不同产区的精确率和召回率均超过90%。对比四个数据集模型的准确率可以发现,三种单面数据集(C、D和G)模型准确率均高于使用R数据集建立的模型,这说明对于山楂样本,在高光谱数据采集时保持样品方向一致可以有效提高分类模型准确率,这一规律与研究人员在玉米真菌感染检测中的发现一致。横向对比C、G和D三个模型,其中使用D数据集建立的分类模型准确率最高,训练集和预测集准确率均达到100%,各产区样本全部预测正确。为避免过拟合现象,对D-D1-SVM模型进行十折交叉验证,其平均准确率为98.8%。综上所述,D-D1-SVM模型对于不同产区山楂的分类效果最优。
表2不同方向数据分类模型准确率
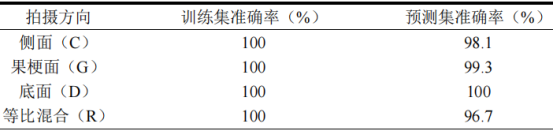
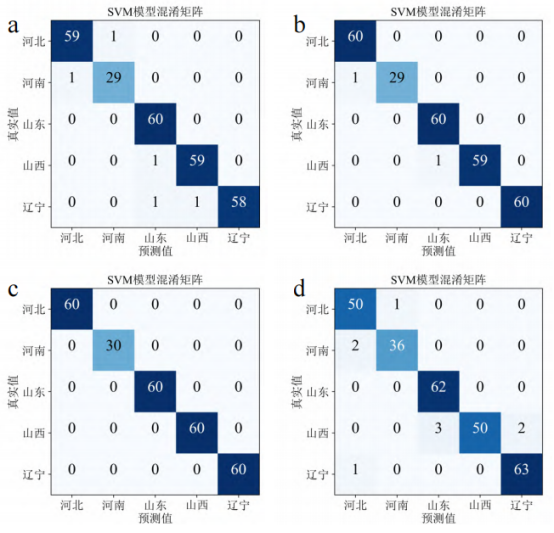
图4全波段模型混淆矩阵
注:a、b、c、d分别为对应C-D1-SVM、
G-D1-SVM、D-D1-SVM、R-D1-SVM四个模型
2.4 基于特征波长的建模分析
2.4.1特征波长的选择
为筛选出最佳特征提取方法,分别使用2种提取方式提取4个数据集的特征波长,最终得到的波长见表3及图5。对比两种方法提取得到的特征波长数量发现,使用SPA提取出的特征波长数量明显少于CARS,进一步观察特征波长分布(图5),发现使用SPA提取出的特征波长分布均匀,各个波段均有涉及;而CARS提取的特征波长分布较为集中,主要分布于750nm、2000nm及2250nm处的三个特征峰。观察各组特征波长重合的部分,发现750nm、1700nm和2200nm附近的重合波长较多,说明这三处吸收峰可能包含不同产区样本的差异信息。对这些特征峰进行深入分析,700~800nm处的吸收峰来自于样品内部的叶绿素,也受样品的外部颜色特征影响;1700nm附近的吸收峰可归因于酰胺基团;2200nm处的吸收峰为C—H和C—O的联合吸收峰。
表3不同方法提取特征波长数量


图5不同数据集特征波长
注:a、c、e、g分别为G、C、D和R数据集经SPA提取得到的特征波长;b、d、f、h分别为G、C、D和R数据集经CARS提取得到的特征波长
2.4.2特征波长建模分析
使用4个数据集的特征波长分别建立SVM模型,其准确率见表4。观察发现使用SPA筛选特征波长建立的模型分类准确率优于CARS,这一现象在G和D数据集上尤为明显。综合考虑波长数量和模型准确率,SPA筛选的波长数量更少,模型复杂度较低,且准确率更高。与本研究得到的结果不同,有研究人员在基于特征波段建立红景天分类模型时,发现CARS为最佳特征波段提取方法,这说明对于不同的检测对象,应当选用不同的特征提取方法,而对于山楂样本,SPA相比于CARS特征波长提取效果更好。
采用SPA提取特征波长的分类模型预测集混淆矩阵见图6,对比四个数据集的准确率(表4)看出,R-SPA模型预测集准确率为87.8%,根据其混淆矩阵(图6d)并由公式(3)和公式(4)计算得出,模型对于河北产区的精确率和召回率仅为79.2%和82.4%,分类能力一般。而C-SPA、G-SPA和D-SPA三个模型准确率均超过90%(分别为90.3%、91.5%和93%),这一现象再次证明在高光谱数据采集时,保持样品方向一致可以有效提高分类模型准确率。综合对比所有模型,D-SPA模型拥有最高的分类准确率,训练集和预测集准确率分别为95.2%和93%,根据其混淆矩阵(图6c)并由公式(3)和公式(4)计算得出,模型对于各产区的精确率和召回率均超过90%(其中山东产区精确率和召回率最低,分别为91.6%和90%);且这一模型涉及的特征波长数量最少,在保证分类准确率的情况下拥有较低的模型复杂度。
综上所述,采集高光谱数据时保持样品摆放方式一致有助于提高模型分类准确率。采用SPA提取特征波长建立的产地分类模型复杂度较低且准确率良好。可以在波长数量有限的情况下对山楂产地进行判别,为后续山楂专属小型化高光谱设备的开发提供了方法参考。
表4特征波长建模准确率
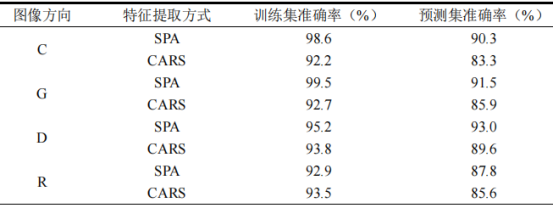
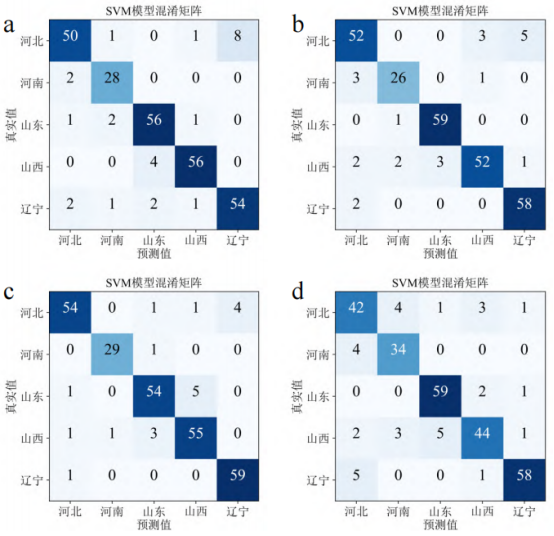
图6特征波长模型混淆矩阵
注:a、b、c、d分别对应C-SPA-SVM、G-SPA-SVM、D-SPA-SVM、R-SPA-SVM四个模型。
综合考虑全波段模型和特征波长模型的分类结果,发现采集样本光谱数据时,样本的摆放方式会影响后续分类建模准确率。无论全波段还是特征波长模型,使用D数据集建模分类效果都明显优于R数据集(提高了约5%),相对于C和G数据集也有所提高。观察山楂样品的外部特征,发现样品底面存在萼片部位,结合宁素云等的研究报道:山楂不同部位的化学成分含量存在差异,推测不同产地山楂其萼片部位各成分含量的差异相比于其他部位更大,进而导致分类特征更加明显。
三、结论
本研究基于高光谱成像技术建立了山楂产地识别模型。为探究样本拍摄方向对分类结果的影响,采集了山楂样本三个不同方向(C、G和D)的光谱数据,分别使用偏最小二乘判别分析(PLSDA)、支持向量机(SVM)和随机森林(RF)三种方法建立模型,通过对比模型分类准确率得到最优建模方法,最终成功区分了5个不同省级产区的山楂,为山楂无损检测设备的开发提供了参考。经过对比筛选发现,一阶导数(D1)为最优预处理方式,SVM为最优建模算法;使用连续投影算法(SPA)提取特征波长数量少且分类模型准确率高。全波段最优建模方法为D-D1-SVM,训练集和预测集准确率均达到100%;特征波长最优建模方法为D-SPA-SVM,训练集和预测集准确率分别为95.2%和93%。本研究证明基于高光谱成像技术对山楂产地进行溯源是可行的,为维护山楂市场秩序提供一种新的识别方式;同时验证高光谱图像采集方向会对检测结果产生影响,为后续开发山楂专属高光谱检测设备提供理论依据和参考。
推荐:
便携式高光谱成像系统 iSpecHyper-VS1000
专门用于公安刑侦、物证鉴定、医学医疗、精准农业、矿物地质勘探等领域的最新产品,主要优势具有体积小、帧率高、高光谱分辨率高、高像质等性价比特点采用了透射光栅内推扫原理高光谱成像,系统集成高性能数据采集与分析处理系统,高速USB3.0接口传输,全靶面高成像质量光学设计,物镜接口为标准C-Mount,可根据用户需求更换物镜。
审核编辑 黄宇
-
高光谱、多光谱、超光谱成像技术的区别2021-07-03 6747
-
高光谱成像技术在农业中能实现哪些应用2021-12-22 2719
-
高光谱成像技术如何分析金属锈化分级2022-02-14 528
-
高光谱成像技术在族谱印记中的应用2022-02-23 1225
-
高光谱成像技术有哪些显著的优势?2022-07-28 4418
-
光谱成像技术的分类2023-04-18 944
-
什么是高光谱成像技术?高光谱成像技术的原理与应用2023-08-18 4878
-
高光谱成像技术在茶叶中的应用与展望2023-09-07 580
-
基于高光谱成像技术的枸杞产地鉴别2023-10-23 464
-
光谱成像技术分类及应用2024-01-15 527
-
避免高光谱成像数据中的光谱混叠问题2024-02-27 868
-
基于高光谱成像技术的山楂产地判别方法2024-03-14 359
-
高光谱成像技术原理及其优势2024-03-27 838
-
高光谱成像技术:从原理到应用的全面指南2024-04-15 1998
-
高光谱成像仪的数据怎么看2024-05-17 532
全部0条评论

快来发表一下你的评论吧 !
