

一种高效的KV缓存压缩框架--GEAR
人工智能
描述
摘要:键值(KV)缓存已成为加快大语言模型(LLM)推理生成速度的事实。然而,随着序列长度的增加,缓存需求也在不断增长,这使得 LLM 推理变成了一个内存约束问题,极大地限制了系统的吞吐量。现有的方法依赖于放弃不重要的标记或均匀量化所有条目。然而,这些方法在表示压缩矩阵时往往会产生较高的近似误差。自回归解码过程进一步加剧了每一步的误差,导致模型生成出现严重偏差,性能下降。为了应对这一挑战,我们提出了一种高效的 KV 缓存压缩框架--GEAR,它能实现近乎无损的高比率压缩。GEAR 首先对大部分大小相似的条目进行超低精度量化。然后,它采用低秩矩阵来近似量化误差,并采用稀疏矩阵来弥补离群条目的个别误差。通过巧妙地整合三种技术,GEAR 能够充分发挥它们的协同潜力。我们的实验证明,与其他技术相比,GEAR 实现了近乎无损的 4 位 KV 高速缓存压缩,吞吐量提高了 2.38 倍,同时内存峰值大小减少了 2.29 倍。
Q1: 这篇论文试图解决什么问题?
A:这篇论文提出了一个名为GEAR(GEnerative Inference with Approximation Error Reduction)的高效键值(KV)缓存压缩框架,旨在解决大型语言模型(LLM)推理过程中的内存瓶颈问题。随着模型大小和序列长度的增加,KV缓存的内存消耗迅速增长,这限制了系统吞吐量。现有的方法依赖于丢弃不重要的标记或对所有条目进行统一量化,但这些方法通常会引入较高的近似误差,导致压缩矩阵的表示不准确。特别是在自回归解码过程中,每一步的误差累积可能导致模型生成性能的关键偏差。
GEAR框架通过结合三种互补的技术来解决这一挑战:首先对大多数相似幅度的条目应用超低精度量化;然后使用低秩矩阵来近似量化误差;最后,引入稀疏矩阵来纠正异常值条目的个别误差。通过巧妙地整合这三种技术,GEAR能够在保持近乎无损的压缩比的同时,显著提高系统吞吐量和减少峰值内存使用。实验结果表明,与现有替代方案相比,GEAR在保持近乎无损性能的同时,实现了高达2.38倍的吞吐量提升和高达2.29倍的峰值内存减少。
Q2: 有哪些相关研究?
A:在这篇论文中,作者提到了以下几类相关研究:
LLM权重压缩:这类研究关注于如何有效地压缩大型语言模型的权重,以减少内存占用和数据传输成本。例如,GPTQ(Frantar et al., 2023) 和SqueezeLLM(Kim et al., 2023) 通过量化方法显著减少了模型权重的内存占用。
LLM激活和KV缓存压缩:与权重压缩相比,激活和KV缓存的压缩更具挑战性,因为它们与模型输入更相关且更敏感。SmoothQuant (Xiao et al., 2023) 和 Atom (Zhao et al., 2023) 等研究通过调整量化方案来减少异常值误差,实现了在简单生成任务上的近乎无损压缩。
KV缓存剪枝:基于注意力分数分析,一些研究提出了通过丢弃KV缓存中的标记来减少缓存大小的方法。例如,H2O (Zhang et al., 2023) 和 FastGen (Ge et al., 2023) 提出了基于注意力分数的KV剪枝方法。
KV缓存量化:除了剪枝方法,还有研究探索了KV缓存的量化方法。例如,SparQ (Ribar et al., 2023) 通过结合剪枝和量化来减少KV缓存的大小。
模型权重和激活的低精度量化:一些研究专注于将模型权重和激活转换为低精度表示,以提高推理效率。例如,Q8bert (Zafrir et al., 2019) 和 ZeroQuant (Yao et al., 2022) 提出了针对BERT等模型的8位和4位量化方案。
这些相关研究为GEAR框架提供了背景和动机,同时也展示了在大型语言模型压缩领域内的不同研究方向和技术进展。GEAR框架在这些研究的基础上,通过创新的方法实现了KV缓存的高效压缩,以提高LLM推理的性能和效率。
Q3: 论文如何解决这个问题?

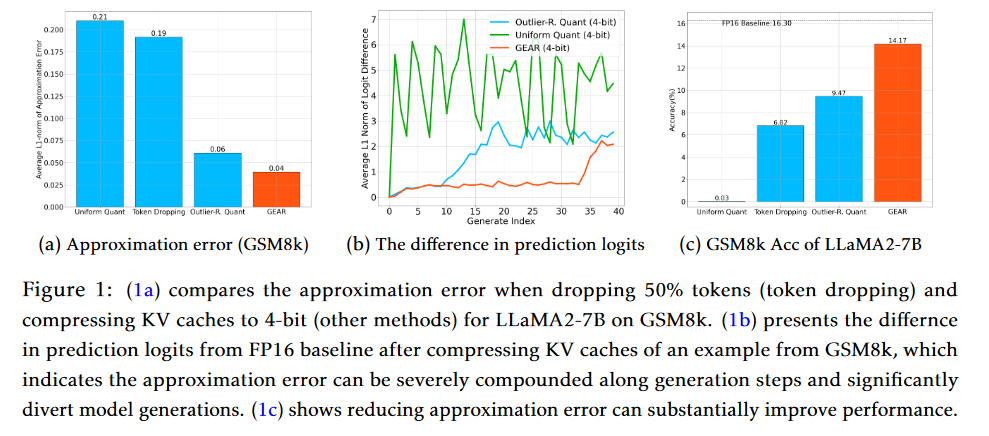
A:论文提出了GEAR框架来解决大型语言模型(LLM)推理中的KV缓存压缩问题。GEAR框架的核心思想是通过结合三种互补的技术来最小化压缩过程中的近似误差,从而实现高压缩比和近乎无损的性能。以下是GEAR框架的主要组成部分和解决方案:
量化(Quantization):GEAR首先对KV缓存中的大多数条目应用超低精度量化,例如4位量化。这种量化方法利用了KV缓存中条目的相似性,将它们压缩到极低的精度。
低秩近似(Low-Rank Approximation):为了更有效地减少量化误差,GEAR使用低秩矩阵来近似量化残差。这是通过奇异值分解(SVD)实现的,它能够捕捉到KV缓存中的共同信息,这些信息在不同的token之间是共享的。
稀疏矩阵(Sparse Matrix):GEAR引入稀疏矩阵来处理那些具有较大幅度的异常值条目。这些条目在量化过程中可能会产生较大的误差,通过将它们存储在稀疏矩阵中,可以单独处理这些异常值,从而减少整体的近似误差。
流式策略(Streaming Strategy):为了提高推理速度,GEAR采用了流式策略。在生成长序列时,GEAR会将新生成的token的KV向量存储到一个小缓冲区中。当缓冲区达到容量时,GEAR会进行KV缓存压缩。这种方法可以在几乎不增加额外内存消耗的情况下显著提高推理速度。
通过这些技术的集成,GEAR能够在保持近乎无损的性能的同时,实现高达2.38倍的吞吐量提升和高达2.29倍的峰值内存减少。这使得GEAR在处理复杂生成任务时,如包含推理的长序列生成,能够显著提高系统性能。
Q4: 论文做了哪些实验?
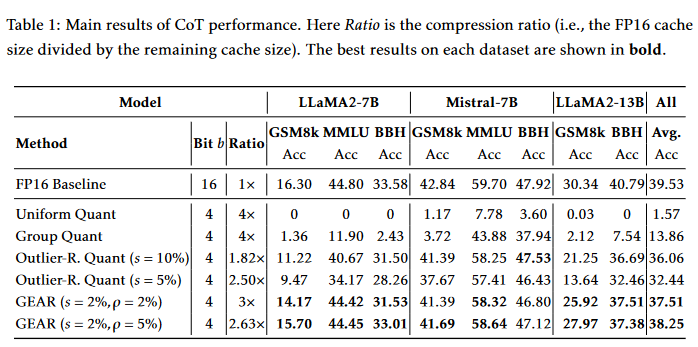
A:论文中进行了一系列实验来验证GEAR框架的有效性和性能。以下是主要的实验内容:
CoT(Chain-of-Thought)推理性能:使用LLaMA2-7B、LLaMA2-13B和Mistral-7B模型在多个具有挑战性的生成任务上评估GEAR的性能,包括数学推理(GSM8k)、多任务语言理解(MMLU)和符号推理(BigBench Hard)。实验结果表明,GEAR在保持高压缩比的同时,能够实现与FP16基线相近的准确性。
Zero-shot生成性能:在GSM8k和MMLU数据集上,对LLaMA2-7B、LLaMA2-7B-chat和Mistral-7B模型进行zero-shot评估。实验结果显示,GEAR在不同压缩比下均优于或至少与基线方法相当。
系统性能分析:分析了GEAR在实际推理系统中的内存占用和系统吞吐量。实验结果表明,GEAR能够显著降低峰值内存使用,允许更大的批量大小或更长的生成长度。此外,GEAR在有限GPU内存的系统中,通过减少内存带宽使用,提高了系统吞吐量。
不同压缩比的性能:展示了在不同压缩比下,GEAR在GSM8k和MMLU数据集上的性能。结果表明,即使在高压缩比下,GEAR仍然能够保持近乎无损的性能。
与token dropping方法的比较:评估了H2O方法在GSM8k数据集上的性能,结果表明H2O在保持性能的同时无法实现高压缩比。
在微调模型上的应用:在GSM8k数据集上,对微调后的LLaMA2-7B模型应用GEAR,并评估其性能。结果表明,GEAR在微调模型上仍然优于基线方法。
超参数敏感性分析:研究了GEAR对稀疏比率(s)和低秩比率(ρ)的敏感性。实验结果表明,GEAR不需要大量的稀疏或低秩成分,小比例的稀疏/低秩矩阵就足以实现近乎无损的准确性。
GEAR与不同KV量化方案的结合:展示了GEAR在不同KV量化方案(如均匀量化和分组量化)上的应用效果。实验结果表明,GEAR能够显著提高这些量化方案的性能。
权重量化模型上的GEAR应用:在模型权重已经量化为8位的情况下,评估GEAR在KV缓存上的性能。结果表明,GEAR在权重量化模型上也能显著提高性能。
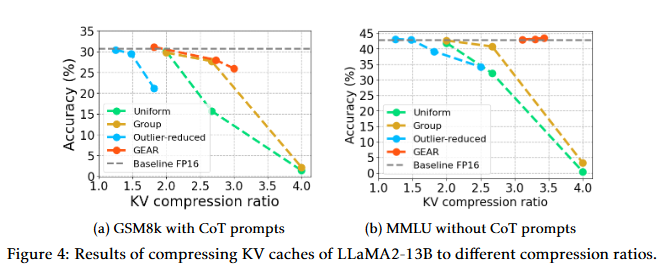
这些实验全面地展示了GEAR在不同场景下的性能,证明了其在压缩KV缓存时的有效性和实用性。
Q5: 有什么可以进一步探索的点?
A:尽管GEAR框架在LLM推理中的KV缓存压缩方面取得了显著的成果,但仍有一些潜在的研究方向可以进一步探索:
更精细的量化策略:研究更精细的量化策略,例如基于内容的量化,其中量化参数可以根据数据的统计特性动态调整,以进一步提高压缩效率和保持性能。
多任务和迁移学习:探索GEAR在多任务学习和迁移学习场景中的应用,特别是在不同领域和语言模型之间的迁移。
实时压缩和推理:研究如何将GEAR集成到实时推理系统中,以支持低延迟和高吞吐量的在线服务。
硬件加速:研究如何利用特定硬件(如FPGA、ASIC或定制加速器)来加速GEAR的压缩和解压缩过程,以进一步提高推理速度。
模型架构的适应性:研究GEAR在不同模型架构(如Transformer、CNN等)中的适应性和性能,以及如何针对特定架构优化压缩策略。
长期依赖和复杂推理任务:深入研究GEAR在处理具有长期依赖和复杂推理任务的模型中的性能,例如在科学问题解答、法律案例分析等场景。
压缩感知和稀疏表示:探索压缩感知技术在KV缓存压缩中的应用,以及如何结合稀疏表示来进一步减少内存占用。
跨模型和跨数据集的泛化能力:评估GEAR在不同模型大小、不同数据集和不同任务类型中的泛化能力,以及如何提高其泛化性。
安全性和隐私保护:研究在压缩过程中如何保护模型和数据的安全性和隐私,特别是在云计算和边缘计算环境中。
开源实现和社区贡献:将GEAR框架开源,并鼓励社区贡献,以促进技术的迭代发展和广泛应用。
这些研究方向可以帮助GEAR框架在实际应用中更加健壮和高效,同时也为大型语言模型的压缩和推理领域带来新的突破。
Q6: 总结一下论文的主要内容?
A:这篇论文介绍了GEAR(GEnerative Inference with Approximation Error Reduction),这是一个针对大型语言模型(LLM)推理过程中的键值(KV)缓存压缩问题的高效解决方案。以下是论文的主要内容总结:
问题背景:随着LLM模型规模的增长,KV缓存的内存需求迅速增加,成为限制系统吞吐量的主要瓶颈。现有的缓存压缩方法,如丢弃不重要的标记或统一量化,往往会引入显著的近似误差,影响模型的生成性能。
GEAR框架:为了解决这一问题,作者提出了GEAR框架,它结合了三种技术:量化、低秩近似和稀疏矩阵。这种方法旨在最小化压缩过程中的近似误差,实现高压缩比和近乎无损的性能。
量化策略:GEAR首先对大多数相似幅度的条目应用超低精度量化,然后使用低秩矩阵来近似量化误差,并引入稀疏矩阵来处理异常值条目。
流式策略:为了提高推理速度,GEAR采用了流式策略,通过在小缓冲区中存储新生成的token的KV向量,并在缓冲区满时进行压缩。
实验结果:在多个复杂生成任务上,GEAR在保持高压缩比的同时,实现了显著的性能提升。与现有方法相比,GEAR在吞吐量和峰值内存使用上都有显著改善。
系统性能分析:GEAR在实际推理系统中能够显著降低峰值内存使用,允许更大的批量大小或更长的生成长度。在有限GPU内存的系统中,GEAR还能提高系统吞吐量。
相关研究:论文讨论了与GEAR相关的研究领域,包括LLM权重压缩、KV缓存压缩、KV剪枝和量化等。
未来工作:论文提出了一些潜在的研究方向,如更精细的量化策略、多任务和迁移学习、硬件加速等,以进一步优化GEAR框架。
总的来说,GEAR框架为LLM的高效推理提供了一种新的内存压缩策略,通过减少KV缓存的内存占用,提高了模型的推理速度和系统吞吐量,同时保持了生成性能。
审核编辑:黄飞
-
如何去实现一种声呐图像压缩存储?2021-06-01 1971
-
怎样去实现一种基于DSP和ADC技术高速缓存和海量缓存?2021-06-26 1989
-
如何去实现一种ThreadX内核框架的设计呢2021-11-29 2108
-
一种较通用的界面切换框架分享,绝对实用2021-12-27 916
-
【ELT.ZIP】OpenHarmony啃论文俱乐部——点燃主缓存压缩技术火花2022-07-15 3319
-
基于AOP的智能Web缓存框架2009-04-11 807
-
一种新的Ad Hoc网络QoS框架2009-04-14 774
-
一种基于复用组件的WEB测控软件框架设计2009-06-06 592
-
高速数据压缩与缓存的FPGA实现2009-11-30 782
-
一种成分取证的理论分析模式的分类框架2017-03-20 694
-
DeepMind提出一种全新的“深度压缩感知”框架2019-05-25 4644
-
一种基于差分编码的RDF分组压缩算法2021-03-17 1301
-
一种基于框架特征的共指消解方法2021-03-19 1468
-
一种基于缓存块重用信息的动态旁路策略2021-04-29 1026
-
mybatis一级缓存和二级缓存的原理2023-12-03 2195
全部0条评论

快来发表一下你的评论吧 !
