

英伟达AI服务器NVLink版与PCIe版有何区别?又如何选择呢?
描述
在人工智能领域,英伟达作为行业领军者,推出了两种主要的GPU版本供AI服务器选择——NVLink版(实为SXM版)与PCIe版。这两者有何本质区别?又该如何根据应用场景做出最佳选择呢?让我们深入探讨一下。
** NVLink版的服务器**
SXM架构,全称Socketed Multi-Chip Module,是英伟达专为实现GPU间超高速互连而研发的一种高带宽插座式解决方案。这一独特的设计使得GPU能够无缝对接于英伟达自家的DGX和HGX系统。这些系统针对每一代英伟达GPU(包括最新款的H800、H100、A800、A100以及之前的P100、V100等型号)配备了特定的SXM插座,确保GPU与系统之间实现最高效率的连接。举例来说,一张展示8块A100 SXM卡在浪潮NF5488A5 HGX系统上并行工作的图片,直观展示了这种强大的整合能力。
在HGX系统主板上,8个GPU通过NVLink技术进行了紧密耦合,构建出前所未有的高带宽互联网络。具体来说,每一个H100 GPU会连接至4个NVLink交换芯片,从而实现GPU之间的惊人传输速度——高达900 GB/s的NVLink带宽。此外,每个H100 SXM GPU还通过PCIe接口与CPU相连,确保任意GPU产生的数据都能快速传送到CPU进行处理。
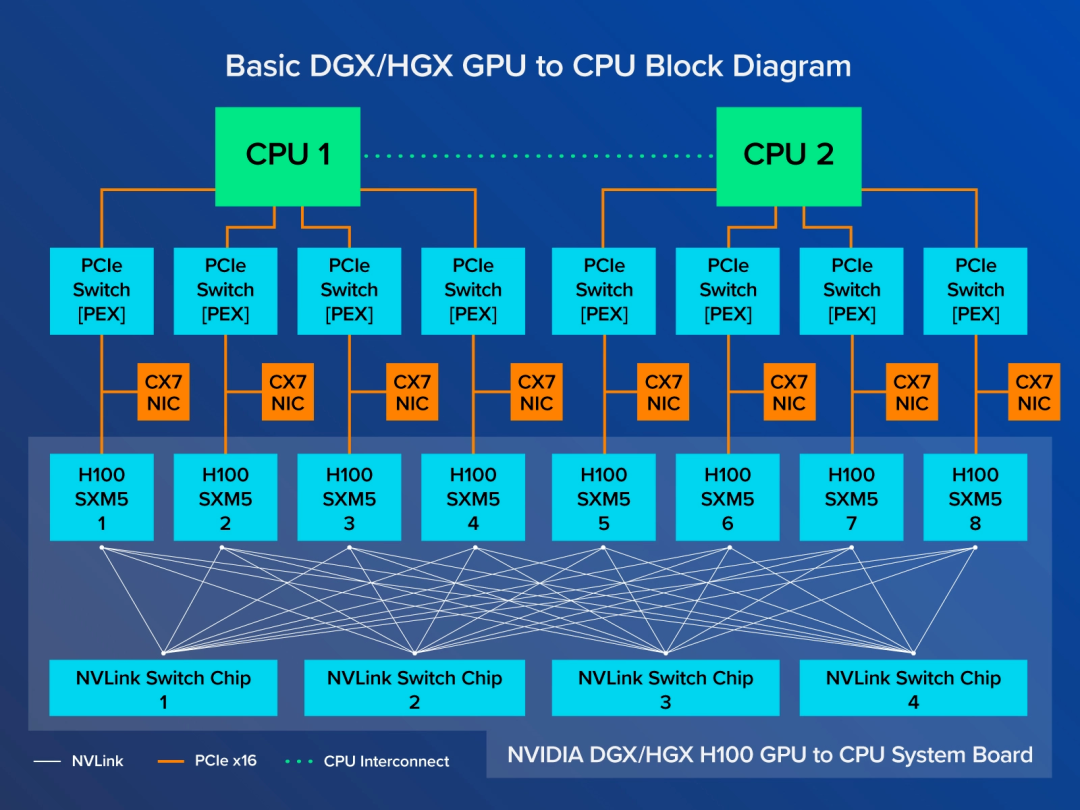
进一步强化这种高性能互联的是NVSwitch芯片,它把DGX和HGX系统板上的所有SXM版GPU串联在一起,形成了一个高效的GPU数据交换网络。未削减功能的A100 GPU可达到600GB/s的NVLink带宽,而H100更是提升至900GB/s,即便是针对特定市场优化过的A800、H800也能保持400GB/s的高速互连性能。

谈及DGX和HGX的不同之处,NVIDIA DGX可视为出厂预装且高度可扩展的完整服务器解决方案,其在同等体积内的性能表现堪称业界翘楚。多台NVIDIA DGX H800可通过NVSwitch系统轻松组合,形成包含32个乃至64个节点的超级集群SuperPod,足以应对超大规模模型训练的严苛需求。而HGX则属于原始设备制造商(OEM)定制整机方案。
** PCIe版的服务器**
相比于SXM版GPU的全域互联,PCIe版GPU的互联方式更为传统和受限。在这种架构下,GPU仅仅通过NVLink Bridge与相邻的GPU实现直接连接,如图所示,GPU 1仅能直接连接至GPU 2,而非直接相连的GPU(如GPU 1与GPU 8)间的通信则必须通过较慢的PCIe通道来实现,这过程中还需要借助CPU的协助。目前最先进的PCIe标准提供的最大带宽仅为128GB/s,远不及NVLink的超高带宽。
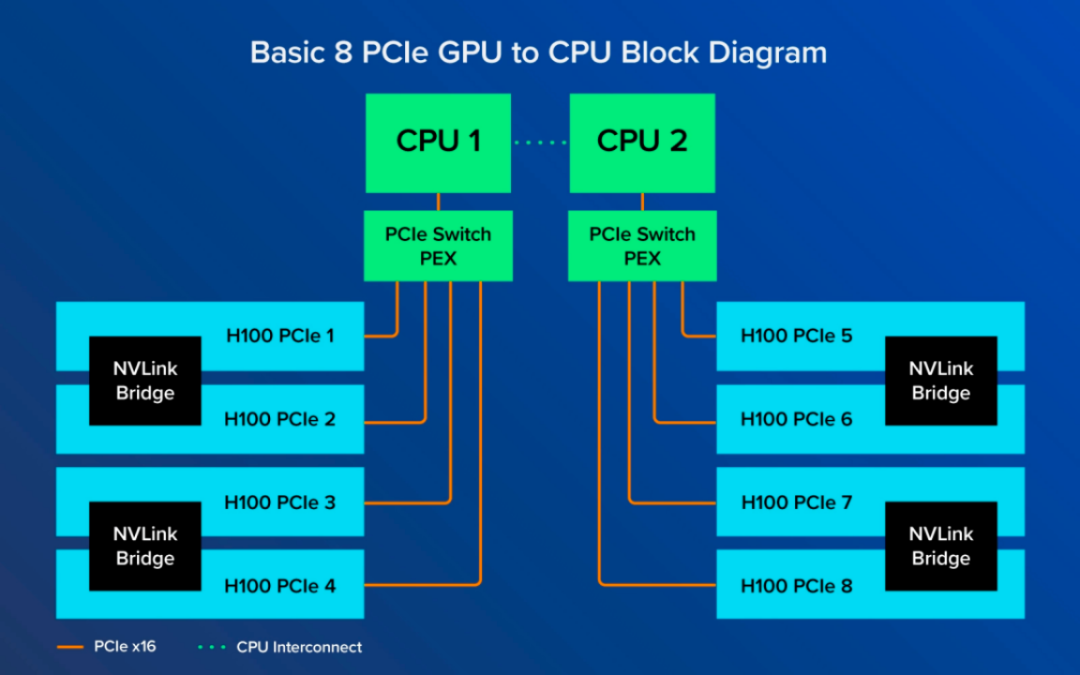
然而,尽管在GPU间互联带宽上PCIe版稍逊一筹,但单就GPU卡本身的计算性能而言,PCIe版与SXM版并无显著差异。对于那些并不极端依赖于GPU间高速互连的应用场景,如中小型模型训练、推理应用部署等,GPU间互联带宽的高低并不会显著影响整体性能。
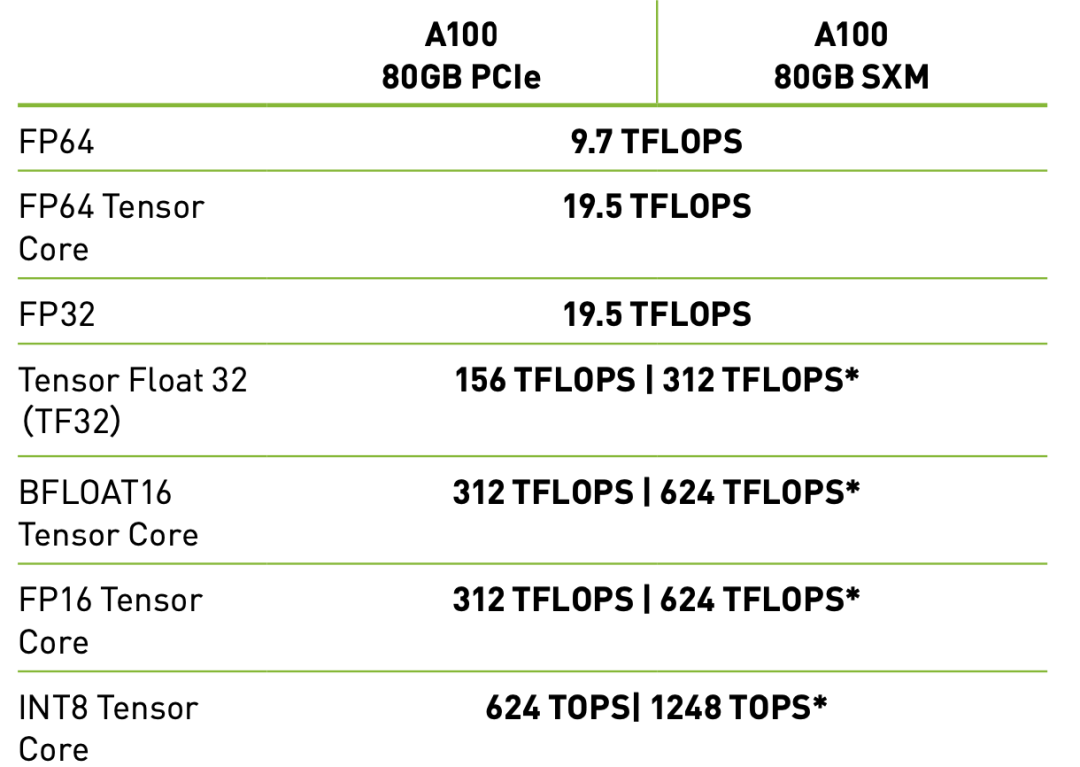
对比A100 PCIe与A100 SXM各项参数的图表显示两者的计算核心性能并无太大差别。
** 该如何选择?**
PCIe版GPU的优势主要体现在其出色的灵活性和适应性。对于工作负载较小、追求GPU数量配置灵活性的用户,PCIe版GPU无疑是个绝佳选择。例如,某些GPU服务器仅需配备4张或者更少的GPU卡,此时采用PCIe版即可方便地实现服务器的小型化,可轻松嵌入1U或2U服务器机箱,同时降低了对数据中心机架空间的要求。
此外,在推理应用部署环境中,我们经常通过虚拟化技术将资源拆分和细粒度分配,实现CPU与GPU的一对一匹配。在这个场景下,PCIe版GPU因其较低的能耗(约300W/GPU)和普遍兼容性而受到青睐。而相比之下,SXM版GPU在HGX架构中的功率消耗可能达到500W/GPU,虽然牺牲了一些能效比,却换取了顶级的互联性能优势。
综上所述,NVLink版(SXM版)GPU与PCIe版GPU各自服务于不同的市场需求。对于对GPU间互连带宽有着极高需求的大规模AI模型训练任务,SXM版GPU凭借其无可匹敌的NVLink带宽和极致性能,成为了理想的计算平台。而对于那些重视灵活性、节约成本、注重适度性能和广泛兼容性的用户,则可以选择PCIe版GPU,它尤其适合轻量级工作负载、有限GPU资源分配以及各类推理应用部署场景。
企业在选购英伟达AI服务器时,务必充分考虑当前业务需求、未来发展规划以及成本效益,合理评估两种GPU 服务器版本的优劣,以便找到最适合自身需求的解决方案。最终的目标是在保证计算效能的同时,最大化投资回报率,并为未来的拓展留足空间。
审核编辑:刘清
-
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片2024-05-13 6747
-
英伟达GPU卡多卡互联NVLink,系统累积的公差,是怎么解决的?是连接器吸收的?2022-03-05 25888
-
英伟达DPU的过“芯”之处2022-03-29 5958
-
IBM联合英伟达发布NVLink 将与PCIe抢市场2014-03-26 1019
-
浅析AI服务器与普通服务器的区别2020-01-23 5381
-
服务器应该是选择物理服务器还是云服务器2020-02-17 5916
-
恒讯科技分析:apache服务器和tomcat服务器有何区别?2023-05-17 1803
-
英伟达AI服务器需求助推生益科技CCL供应2023-12-13 4326
-
独立服务器和云服务器的区别2024-01-17 4757
-
全面解读英伟达NVLink技术2024-04-22 3662
-
英伟达首次向OpenAI供应AI服务器,鸿海出货预期将增长2024-04-26 1949
-
鸿海再获AI领域大单,独家供货英伟达GB200 NVLink交换器2024-06-19 2050
-
英伟达新业务动向:AI服务器市场的新变局2024-06-21 2196
-
英伟达AI服务器将革新采用插槽式设计2024-09-27 1388
-
微软Azure首获英伟达GB200 AI服务器2024-10-10 1870
全部0条评论

快来发表一下你的评论吧 !
