

TI新一代高性能SoC最小系统的构建
嵌入式操作系统
描述
DM816x,C6A816x,AM389x是TI新一代高性能SOC,系统集成度高,系统控制模块化,架构与以往TI SOC平台有所不同,本文针对最小系统的时钟配置,电源管理,内存映射,内存配置的区别做深入解释。
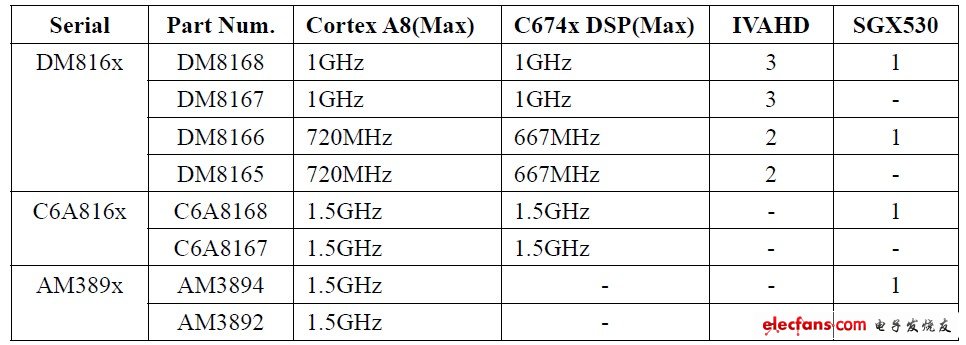
DM816x,C6A816x,AM389x引脚兼容(为方便讨论,下面统称DM816x),资源配置主要区别如下表所示,这种兼容系列产品便于用户基于同一平台,根据不同的产品需求选择合适的型号,可以节省大量的硬件、系统软件开发时间。
表1. DM816x, C6A816x, AM389x比较表
1.时钟配置
DM816x内部有4个FAPLL(Flying Adder PLL,结构见图1.1),分别负责不同模块的时钟配置,系统时钟框图见图1.2。
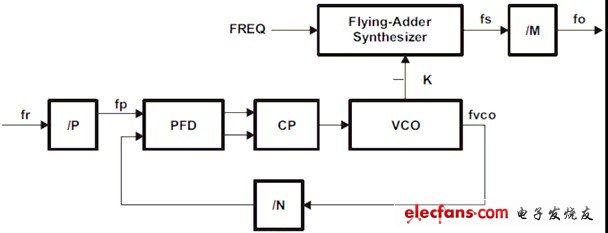
图1.1 Flying-Adder PLL框图
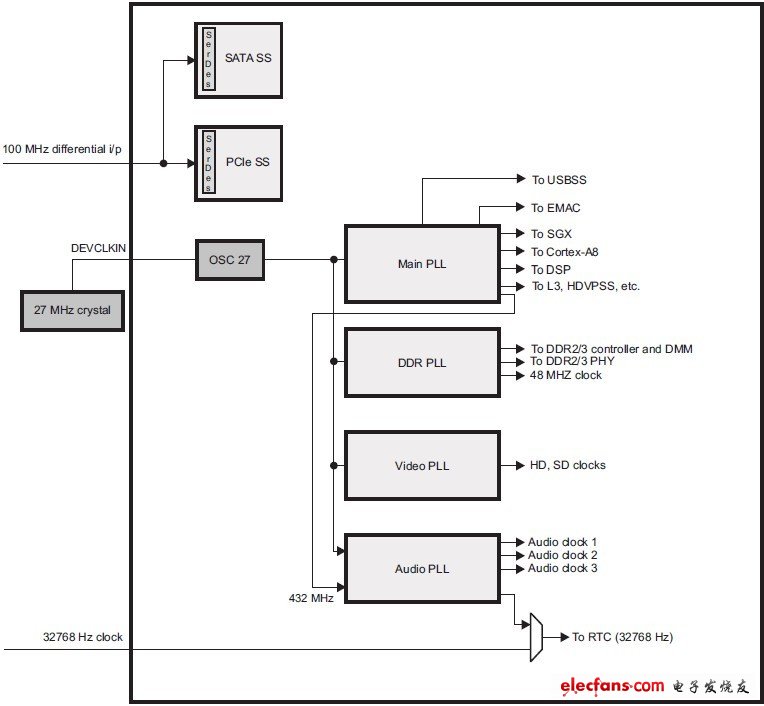
图1.2 DM816x系统时钟结构图
FAPLL相对于传统的PLL具有精度高,响应快,减少模拟电路复杂度等优点,更适合于音视频应用。从使用者的角度在DM816x上最直接的体现是它支持小数分频系数,方便于产生需要的频率。
每个FAPLL结构由两部分组成:
1. Multiphase PLL。
2. Flying Adder Synthesizer.(可能有多个为不同模块提供不同频率的时钟)
FAPLL的配置属于Control Module的PLL部分。
Multiphase PLL的配置寄存器为相应的FAPLL控制寄存器,对应四个FAPLL分别为:MAINPLL_CTRL,DDRPLL_CTRL,VIDEOPLL_CTRL,AUDIOPLL_CTRL.Multiphase PLL的输出时钟频率为:

Flying Adder Synthesizer的配置寄存器为相应FAPLL的PLL_FREQ和PLL_DIV寄存器,可能有多组对应多个Synthesizer.对应图1.1中Fs和Fo的输出频率计算公式为:

FAPLL的配置参数不能任意选择,在根据上述公式计算频率的基础上需要满足下面公式的条件:

● A = 169 (如果AUDIOPLL的输入源是从MAINPLL输出的,则AUDIOPLL的A=218)。
● H = 10 (如果M*FREQ是8的倍数,否则H=0)。
●800MHz≤PLL_CLKIN*N/P≤1600MHz?? 10MHz≤PLL_CLKIN/P≤60MHz
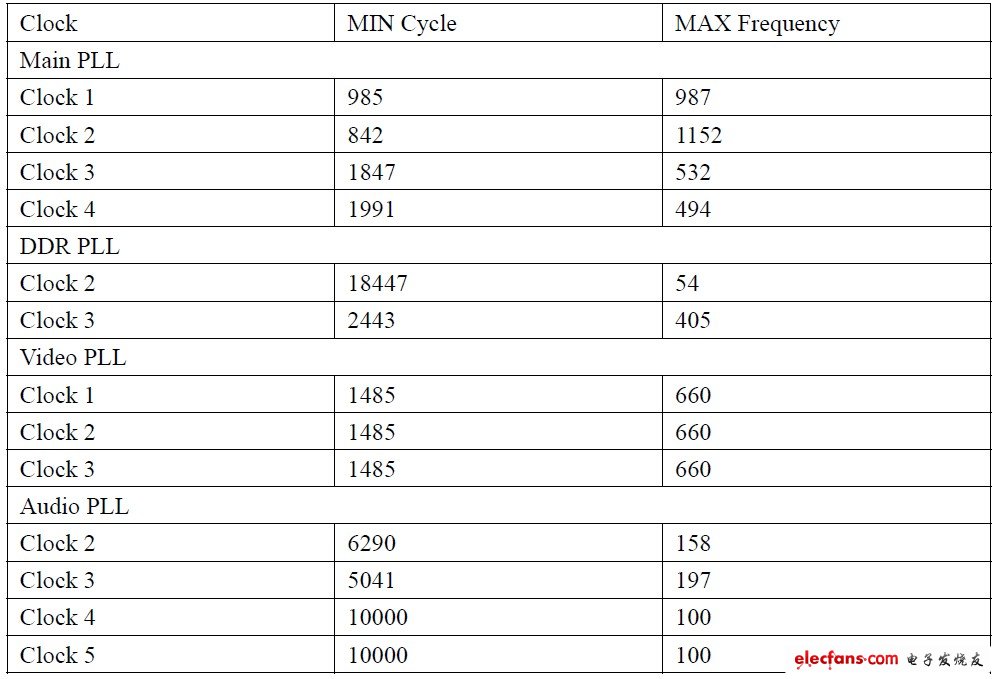
● MIN CYCLE见表2
表2 PLL时钟频率
针对视频应用,系统输入时钟CLKIN=27MHz,在EVM板提供的gel文件,UBOOT代码里有提供合适的FAPLL配置参数。对于其它的输入时钟频率,需要根据上面的条件计算合适的配置值。
CLKIN时钟经过FAPLL后,送到PRCM进行选择控制,给各模块提供时钟。以图2.3Main PLL为例,框内部分由PRCM(Power Reset Control Module)控制,参考后面的PRCM部分。
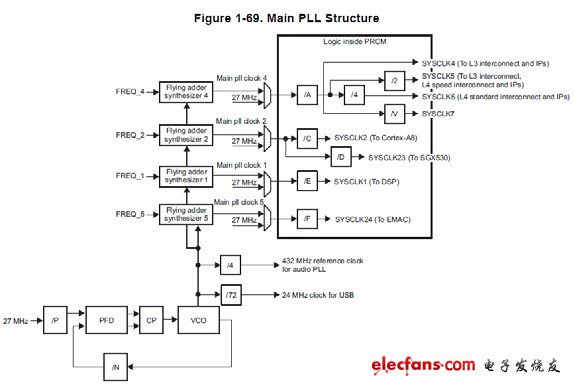
图2.3 MAIN PLL框图
下面以MainPLL的Main PLL clock 1输出为例说明时钟的配置方法,MAINPLL_FREQ1寄存器定义见表3,MAINPLL_DIV1寄存器定义见表4.
表3 MAINPLL_FREQ1寄存器

表4 MAINPLL_DIV1寄存器

Main PLL clock 1输出频率计算公式如下:

PLL_FREQ寄存器小数分频系数MAIN_FRACFREQ1部分的计算方法是:
DecToHex(Fraction * 2 24),如0.5的16进制小数=(0.5*224)= 0x800000。
同时需要注意的是PLL_FREQ的整数系数INTFREQ必须大于或等于8。
SYSCLK1的时钟输出为:
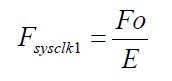
E为PRCM的CM_SYSCLK1_CLKSEL[CLKSEL]分频系数选择。
2.电源,复位,控制模块配置
PRCM(Power Reset Control Module)是系统控制的枢纽。一方面控制系统模块的正常供电,一方面可以将不用的模块关闭达到省电的目的。
2.1 电源管理
电源管理模块控制电源域的使能与关闭,共有的四个电源域为: Always On,Default, Active,SGX,视频协处理器电源域IVAHD0,IVAHD1,IVAHD2是DM816x特有的。Always On电源域不能关闭,其它电源域由相应的PRCM.PM__PWRSTCTRL[POWERSTAT]寄存器控制电源的开关:
● PM_ACTIVE_PWRSTCTRL控制GEM,HDMI,HDD_SS.
● PM_DEFAULT_PWRSTCTRL控制TPDMA,DMM,DDR0/1,USB0/1,SATA,PCI,TPPSS,M3.
● PM_SGX_PWRSTCTRL控制3D图形模块。
● 三个视频协处理分别由PM_IVAHD0_PWRSTCTRL,PM_IVAHD1_PWRSTCTRL,PM_IVAHD2_PWRSTCTRL控制。
通常一个电源域下包含多个模块,如果同一电源域的某模块需要继续使用,则只能关闭其它不用的模块的时钟来达到省电的目的,而不能关闭整个电源域。
为了进一步达到省电的目的,对于使能的模块,可以通过_SYSCONFIG. MIDLEMODE 或者 >Module>_SYSCONFIG寄存器的STANDBYMODE设置将其配置为smart-standby模式,在其没有操作的时候,模块自动关闭时钟进入省电状态,在有操作的时候,自动打开时钟。不是每个模块都可配置STANDYMODE,需要检查相应的模块是否有上述两个寄存器之一。
2.2复位管理
芯片的复位分为两大类:系统级复位和模块级Local Reset。
2.2.1 系统级复位
表5列出了系统级复位的不同复位信号源分类,以及对芯片的不同影响。
表5 系统级复位分类
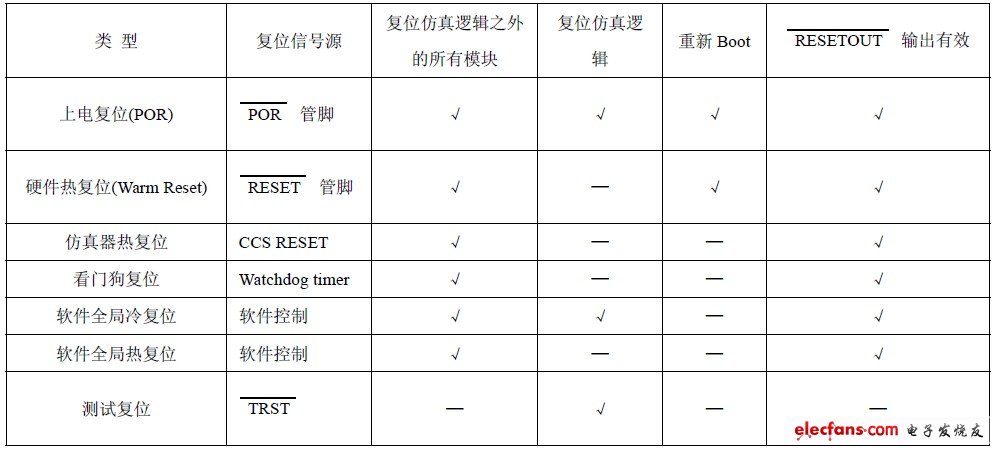
芯片的硬件复位分为上电复位(POR)和热复位(WARM Reset),区别是Warm Reset不会复位仿真器的状态,如果仿真器处于连接状态则不会断连。这两种硬件复位都会让芯片重新Boot.
PRCM的PRM_RSTCTRL寄存器控制用来设置以下两种软件全局复位:
● 软件全局冷复位(Software Cold Global Reset)。
●软件全局热复位(Software Warm Global Reset) .
这两种复位都不会使芯片重新Boot,区别同样是软件全局热复位不会复位仿真逻辑。
仿真器复位,看门狗复位与PRCM的Software Warm Global Reset的作用是一样的。
TRST复位是通过仿真器对芯片JTAG电路的复位控制,不会复位芯片的状态。
2.2.2 局部复位Local Reset
局部子系统可以通过软件控制复位状态,一共有六个RM__RSTCTRL寄存器分别控制Always On之外的六个电源域下的局部子系统的复位:
● RM_ACTIVE_RSTCTRL控制DSP的复位;
●RM_DEFAULT_RSTCTRL控制PCIe,MMU和两个M3的复位。
● RM_SGX_RSTCTRL控制SGX的复位。
● RM_IVAHD0_RSTCTRL,RM_IVAHD1_RSTCTRL,RM_IVAHD2_RSTCTRL控制视频协处理的复位。
2.3 时钟管理
时钟经FAPLL(Flying Adder PLL)倍频后输入PRCM,PRCM对时钟的控制管理分为三个方面:
● 模块时钟频率的配置由CM__CLKSEL[CLKSEL]控制;
●时钟域的开关由CM___CLKSTCTRL控制;
● 模块时钟开关由CM___CLKCTRL控制;
由上可以看出系统架构的划分,首先是按电源域,然后按时钟域,最后才是对模块独立的时钟控制。为达到省电的目的,在不能对整个电源域关闭的情况下,要看时钟域是否有模块被使用,如果没有,则可将时钟域关闭,否则,就只能将相应的模块时钟关闭。
以系统中用到EMIF0,但不用EMIF1为例说明如何配置PRCM控制电源域,时钟域,以及模块时钟。
● EMIF属于Default电源域,PM_DEFAULT_PWRSTCTRL寄存器只有一个控制位控制整个default电源域的开关,因为EMIF0要使能,所以这个寄存器必需使能,也就是不能关闭整个default电源域。
WR_MEM_32(PM_DEFAULT_PWRSTCTR, 0x2);
while((RD_MEM_32(PM_DEFAULT_PWRSTCTR) & 0x3000)!=0x3000);
● 配置EMIF的时钟域,EMIF时钟属于L3_FAST_DEFAULT_GCLK时钟域,由寄存器CM_DEFAULT_L3_FAST_CLKSTCTRL 控制,DMM,EMIF_FW也属于这个时钟域,所以这个时钟域需要使能。
WR_MEM_32(CM_DEFAULT_L3_FAST_CLKSTCTRL, 0x2);
while((RD_MEM_32(CM_DEFAULT_L3_FAST_CLKSTCTRL) & 0x300)!=0x300);
● 配置EMIF模块时钟,EMIF0,EMIF1的模块时钟分别由CM_DEFAULT_EMIF_0_CLKCTRL和CM_DEFAULT_EMIF_1_CLKCTRL单独控制。
WR_MEM_32(CM_DEFAULT_EMIF_0_CLKCTRL, 0x2); // Enable EMIF0 Clock
while(RD_MEM_32(CM_DEFAULT_EMIF_0_CLKCTRL)!=0x2);
WR_MEM_32(CM_DEFAULT_EMIF_1_CLKCTRL, 0x0); // Disable EMIF1 Clock
while((RD_MEM_32(CM_DEFAULT_EMIF_1_CLKCTRL) & 0x3000)!=0x3000);
3.DSP MMU配置
DM816x DSP上首次使用了MMU,MMU(Memory Management Unit)的作用是:
● 提供硬件机制的虚拟地址与物理地址转换;
● 提供硬件机制的内存访问权限授权。
对于支持多进程的HLOS(High Level Operation System),OS利用MMU的地址转换功能可以为每个进程提供独立的地址空间。但对于DSP来说,通常不运行HLOS, 这种功能得不到体现。
在ARM+DSP的双核SOC架构上,所有外设包括内存空间都是共享的,平等访问,这样的架构有很多好处,比如在两个核间共享数据很高效,只需要传递数据的指针,不需要做数据的拷贝;但是带来的问题是需要用户程序保证不会非法改写另一个核的程序数据空间,否则会导致系统崩溃,而且这种问题导致的现象不确定,通常难以精确定位。
ARM上的HLOS如Linux的内存管理,可以保证不会非法访问系统管理之外的空间。在以往的DaVinci系列芯片上DSP没有MMU,需要用户保证DSP程序不会非法访问ARM的程序和数据空间。DM8168的DSP上使用MMU以硬件方式提供了内存访问授权,使内存访问越界问题的定位变得格外容易, MMU的错误状态寄存器会记录越界访问,并且MMU_FAULT_AD会记录最近通过MMU的访问地址。
MMU可以工作在旁通模式,即不对地址做映射,但是在DM816x上GPMC的系统地址空间于0x0地址开始,与DSP的片内地址空间重叠,如果DSP需要访问GPMC,必需要通过MMU将GPMC的空间映射到虚拟空间。
MMU的TLB(Translation Look-aside Buffer)配置分为两种:TWL(Table Walking Logic)模式,和静态TLB模式;TWL模式功能灵活,静态TLB模式转换效率高[5].
通常DSP上不运行HLOS,建议采用静态TLB模式。一张超级映射表可以映射16MByte空间,TLB共可容纳32张表,最多可以映射512MByte空间。由于外设通常由ARM控制,DSP访问部分GPMC和部分DDR空间,以及部分外设,所以512MByte空间能满足绝大多数应用的DSP访问空间需求。目前UBoot中没有DSP MMU的配置,用户在DSP访问片外空间之前完成MMU的配置即可。
4 DDR配置
DM816x的DDR控制器兼容支持DDR2和DDR3;有两个独立的控制器,各有两个片选;每个DDR控制器的地址空间为1GByte;与TI以往处理器不同的是在DM816x上片选与地址空间的映射是可配置的,每个片选上的地址空间大小也是可配置的。所以在DM816x上的DDR配置分为三部分:
●DDR时钟配置
●DDR地址空间映射,
●DDR时序配置
4.1 DDR时钟配置
DDR时钟FAPLL配置计算方法参见前面时钟配置部分。DDR时钟包括两部分:接口时钟,模块功能时钟。
接口时钟即FDDR_CLK由DDR FAPLL的Fvco经DDRPLL_DIV1分频输出。
DDR模块功能时钟FSYSCLK8固定为400MHz以与内部总线L3时钟同步, 无论DDR接口时钟多少,都将SYSCLK8配置为400MHz.
DDR时钟计算公式:

4.2 DDR地址空间映射
DDR空间寻址范围共2GB,最多可分为4段,通过DMM的DMM_LISA_MAP0~3分别配置EMIF0的CS0,CS1和EMIF1的CS0和CS1的首地址映射,及两个DDR控制器之间的寻址方式。两个DDR控制器之间的寻址方式有两种模式:非交织访问,交织访问。
非交织访问,即两个控制器的寻址在各自的映射范围内线性递增。如果希望将ARM与DSP的内存空间在物理上分开,可以选择这种模式。当只使用一个控制器时,只能使用非交织的线性寻址模式。
交织访问,即双通道内存技术,当访问在控制器A上进行时,控制器B为下一次访问做准备,数据访问在两个控制器上交替进行,从而提高DDR吞吐率。支持128byte,256byte,512byte的交织模式。如果要使用交织模式,要保证两个控制器上有对称的物理内存:即两块内存大小一致;在各自的控制器上的地址映射一致。
以两个控制器上的CS0,CS1各接512MByte内存,共2GByte内存为例,非交织线性访问模式的配置为:
/*Program the DMM to Access EMIF0*/
WR_MEM_32(DMM_LISA_MAP__0, 0x80500100);
WR_MEM_32(DMM_LISA_MAP__1, 0xA0500120);
/*Program the DMM to Access EMIF1*/
WR_MEM_32(DMM_LISA_MAP__2, 0xC0500200);
WR_MEM_32(DMM_LISA_MAP__3, 0xE0500220);
示意图见4.1.

图4.1 线性访问模式
在线性访问模式下,系统送出的物理地址在控制器上线性递增寻址,图4.2为线性模式的物理寻址示意图。

图4.2 线性访问物理地址寻址。
128-byte交织访问模式的配置为:
/*Program the DMM to Access EMIF0 and 1*/
// Interleaved 1GB section from 0x80000000 on EMIF0 CS0 and EMIF1 CS0
WR_MEM_32(DMM_LISA_MAP__0, 0x80640300);
// Interleaved 1GB section from 0xC0000000 on EMIF0 CS1 and EMIF1 CS1
WR_MEM_32(DMM_LISA_MAP__1, 0xC0640320);
WR_MEM_32(DMM_LISA_MAP__2, 0x80640300);
WR_MEM_32(DMM_LISA_MAP__3, 0xC0640320);
图4.3为交织访问模式下系统地址在控制器寻址访问的示意图。

图4.3 交织访问模式
在交织访问模式下,系统送出的物理地址在两个控制器上交替访问,图4.4为128Byte交织模式的物理寻址示意图。

图4.4 交织访问物理地址寻址
4.3 DDR时序配置
DM816x 目前版本的DDR3控制器不支持硬件自动 Leveling,支持软件leveling,运用参考文献[3]的工具,根据DDR布线计算出leveling种子,将计算结果更新到UBoot的ddr_def.h文件中。每次重新布板后,都需要重新计算leveling.工具中提供的配置基于4*8bit的,如果是用2x16bit的配置,那么在RatioSeed.xls中DQS0=DQS1,DQS2=DQS3;CK0=CK1,CK2=CK3.
结束语
阅读本文请结合EVM板的gel文件,DM8168 EZSDK[7] UBoot源码的board\ti\ti8168\evm.c文件的s_init()函数。
-
芯华章推出新一代高性能FPGA原型验证系统2024-12-10 884
-
TI 新一代明星CPU2023-12-15 1579
-
一文简述MCU最小系统2023-09-01 6763
-
什么叫最小系统2021-11-25 2190
-
Altium Designer绘制stm32最小系统2021-11-17 2132
-
51单片机最小系统是什么?51单片机最小系统的电路介绍2019-08-12 10097
-
基于DM816x,C6A816x和AM389x系列SOC的最小系统配置的详细资料概述2018-07-18 1044
-
stm32最小系统2017-03-19 1303
-
at89s52最小系统图 单片机最小系统介绍与设计2016-09-22 34455
-
51最小系统2016-03-22 720
-
ST针对DTV市场发布新一代高性能FHD系统单芯片2010-01-26 823
-
新一代小区网关:灵活性与高性能至关重要2009-10-05 3596
全部0条评论

快来发表一下你的评论吧 !
