

以太网自协商机制—双绞线自协商案例(四)
描述
10M/100M/1000M自协商基理
10M/100M/1000M自协商,主要协商的内容为“速度双工”、“流控”和“主从”三大类,下面先介绍10M/100M/1000M自协商的BasePage和NextPage的bits分配,然后就这三大类内容进行阐述。
10M/100M/1000M自协商交互方式
1000BASE-T PHY(无EEE能力时)按顺寻地不间断地交换一个自动协商基本页、一个1000BASE-T格式的下一页,和两个1000BASE-T未格式化的下一页;1000BASE-T PHY(有EEE能力时)按顺寻地不间断地交换一个自动协商基本页、一个1000BASE-T格式的下一页,两个1000BASE-T未格式化的下一页,一个1000BASE-T格式的下一页,和一个1000BASE-T未格式化的下一页;
1000BASE-T BasePage和NextPage编码格式分别如下图:

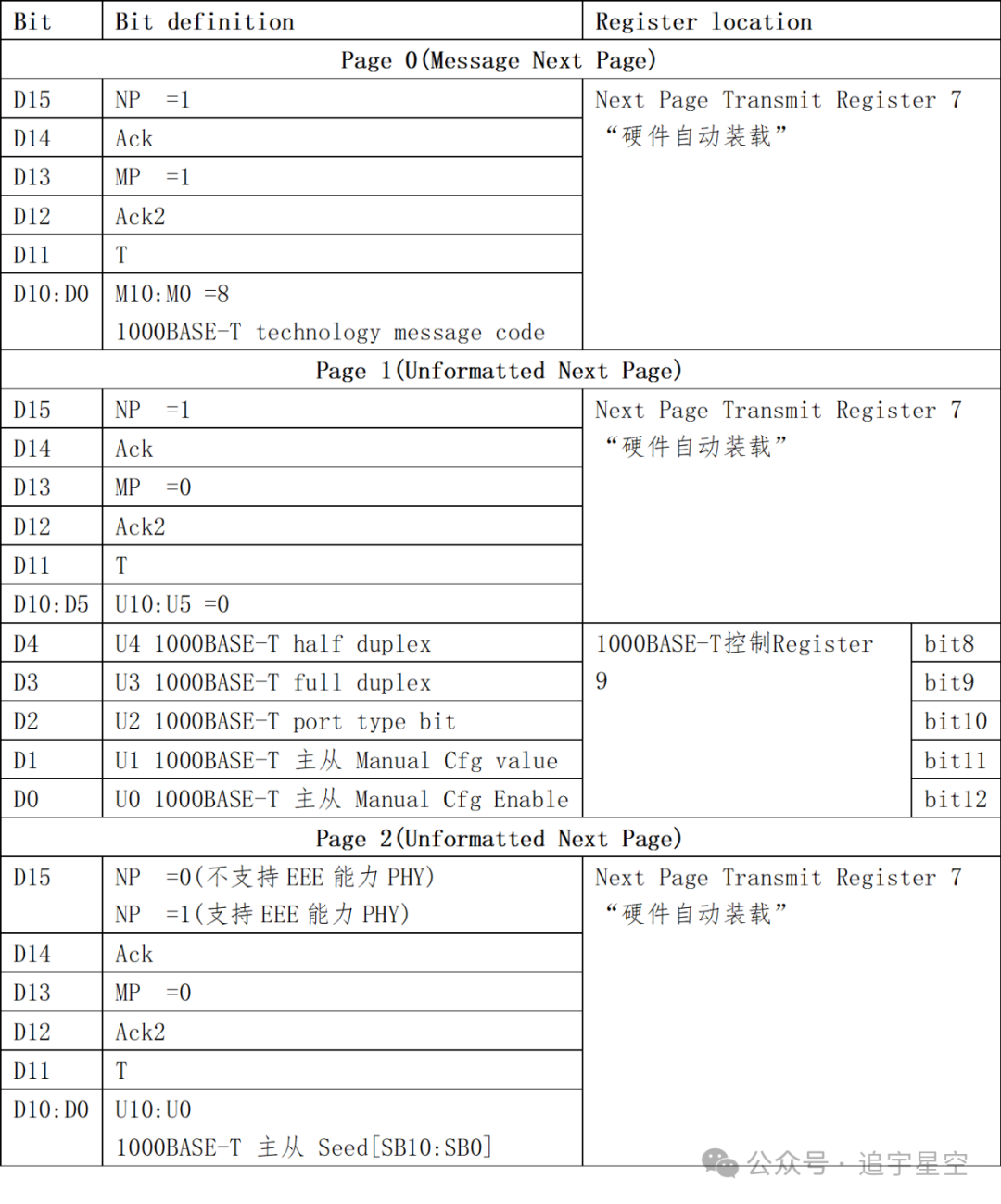
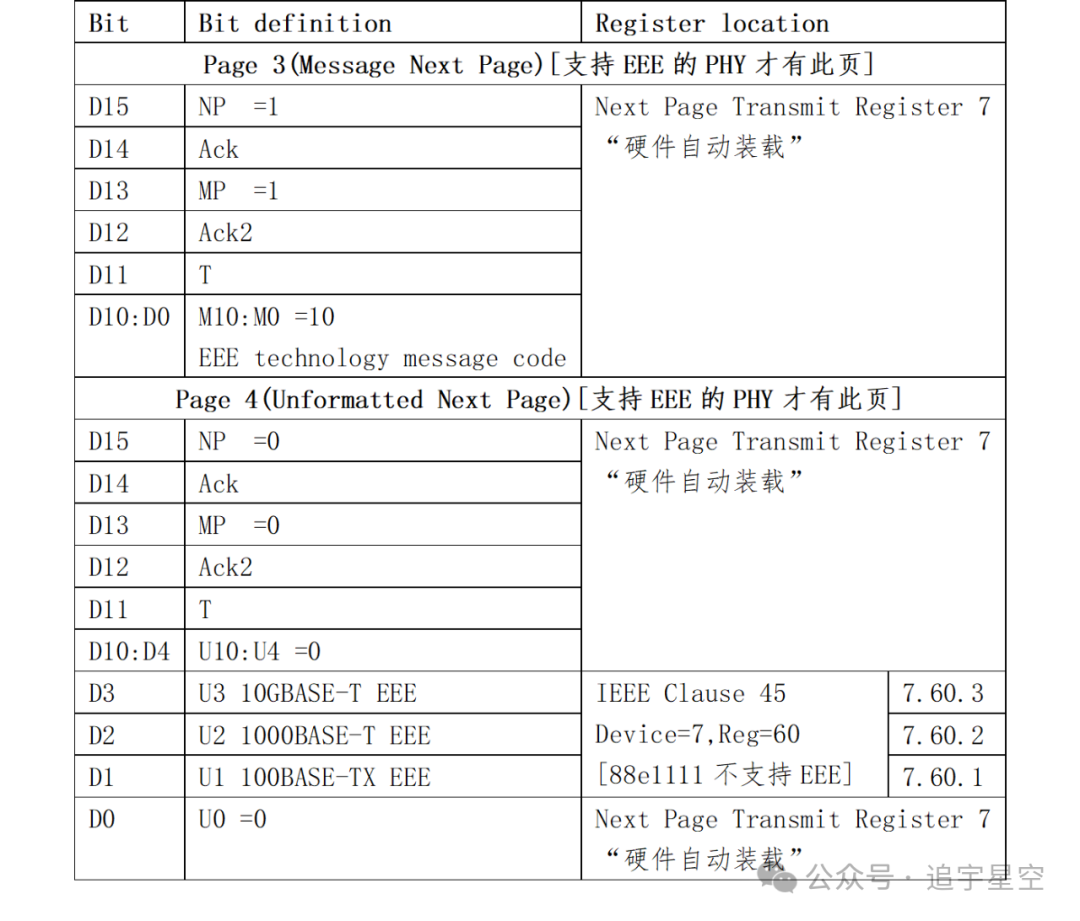
速度双工协商
速度双工协商主要靠设置“本地广告能力寄存器Auto-NegotiationAdvertisement Register Register 4”的bit9:5和“本地控制寄存器1000BASE-T Control Register Page 0, Register 9”的bit9:8实现的。下面为描述问题方便,把Reg 9.bit9:8+Reg 4.bit9:5合并为T[11:5].本端和远端选择彼此都有的能力(T[11:5]中的置1的相关bit)中优先级高的那种能力作为本端PHY和远端PHY的实际工作的速度双工状态。
PHY能力优先级由高到低排序如下:
1000BASE-Tfull duplex
1000BASE-T half duplex[没有芯片支持]
100BASE-T2 full duplex[已淘汰]
100BASE-TX full duplex
100BASE-T2[已淘汰]
100BASE-T4[已淘汰]
100BASE-TX half duplex
10BASE-T full duplex
10BASE-T half duplex
下面分为“本端远端均为千兆PHY”和“一端为千兆PHY,另一端均为百兆PHY”两种情况讨论。
“本端远端均为千兆PHY”:
例子1:本端PHY的T[11:5]=2b1001111;双绞线另一侧的远端PHY的T[11:5]=2b0000101。此时他俩的彼此能力的交集为PHY的T[11:5]=2b0000101,即双绞线链路双方都支持的PHY能力为T[5]=1(10BASE-T half duplex)和T[7]=1(100BASE-TX half duplex),并且因为优先级顺序为100BASE-TX half duplex>10BASE-T half duplex,故此时本端和远端速度双工自协商的结果为“100BASE-TX half duplex”;
例子2:本端PHY的T[11:5]=2b1001111;双绞线另一侧的远端PHY的T[11:5]=2b1001010。此时他俩的彼此能力的交集为PHY的T[11:5]=2b1001010,即双绞线链路双方都支持的PHY能力为T[6]=1(10BASE-T full duplex)、 T[8]=1(100BASE-TX full duplex)和T[11]=1(1000BASE-T full duplex),并且因为优先级顺序为1000BASE-Tfull duplex >100BASE-TX full duplex>10BASE-T full duplex,故此时本端和远端速度双工自协商的结果为“1000BASE-T full duplex”;
例子3:本端PHY的T[11:5]=2b1000000;双绞线另一侧的远端PHY的T[11:5]=2b0001111。此时他俩的彼此能力的交集为PHY的T[11:5]=2b0000000,即双绞线链路双方没有PHY能力交集,故此时本端和远端永远无法建立正确链接。
写到这里,可能有小伙伴感觉到疑惑,既然88e1111 PHY的“本地控制寄存器1000BASE-T Control Register Page 0, Register 9”的bit8(1000BASE-T half duplex)可设置为1,为什么说芯片均不支持1000BASE-T half duplex呢?笔者曾经实践多款不同厂家的PHY(broadcom,marvell,vitesse,realtek,micrel等),发现即使本端和远端的该能力bit均置1,但是实测效果是1000BASE-Thalf duplex模式实际并未生效,为避免产生不必要的混淆,建议驱动工程师将此bit永远初始化0。其实芯片厂家普遍选择不实现1000BASE-T half duplex是合乎情理的。我们知道以太网PHY半双工的技术需求主要是20年前,因为当年LAN主要是基于集线器组网(集线器基于总线广播模式而非地址表交换模式),并且当年的计算机的CPU能力普遍孱弱,硬件无环境无法支持全双工的应用。
而在进入1000BASE-T时代(大概是2007年)后,集线器已经被性能优越的交换机(基于SRAM地址表架构的交换机天生支持全双工能力)完全取代,同时计算机的CPU的处理性能极大飞跃,故此时此刻半双工的需求不复存在。所有厂家就没有花额外的成本去支持1000BASE-T half duplex必要。(还有另外一个原因,理论上如果支持基于CSMA/CD的1000BASE-T半双工200米的冲突域的需求,以太网的最小帧长要从64Byte提高到512Byte,这样的变动的历史代价太大)。
“一端为千兆PHY,另一端均为百兆PHY”:
千兆PHY通过“LinkPartner Ability Register - Base Page, Copper Page 0, Register 5”的bit15获知双绞线的另一端为百兆PHY(bit15 NextPage=0),故千兆PHY也只支持BasePage发送(此时NextPage永远不对外发送)。那当前的情况就完全等同于10M/100M自协商了,该部分在“10M/100M自协商基理”章节已阐述过,故这里就不再赘述了。
流控协商
流控主要靠设置“本地广告能力寄存器Auto-Negotiation Advertisement Register Register 4”的bit11:10实现的。软件通过本端和远端的bit11:10的各种组合进行对本端MAC的tx和rx方向的802.3流控进行设置,具体规则如下表:
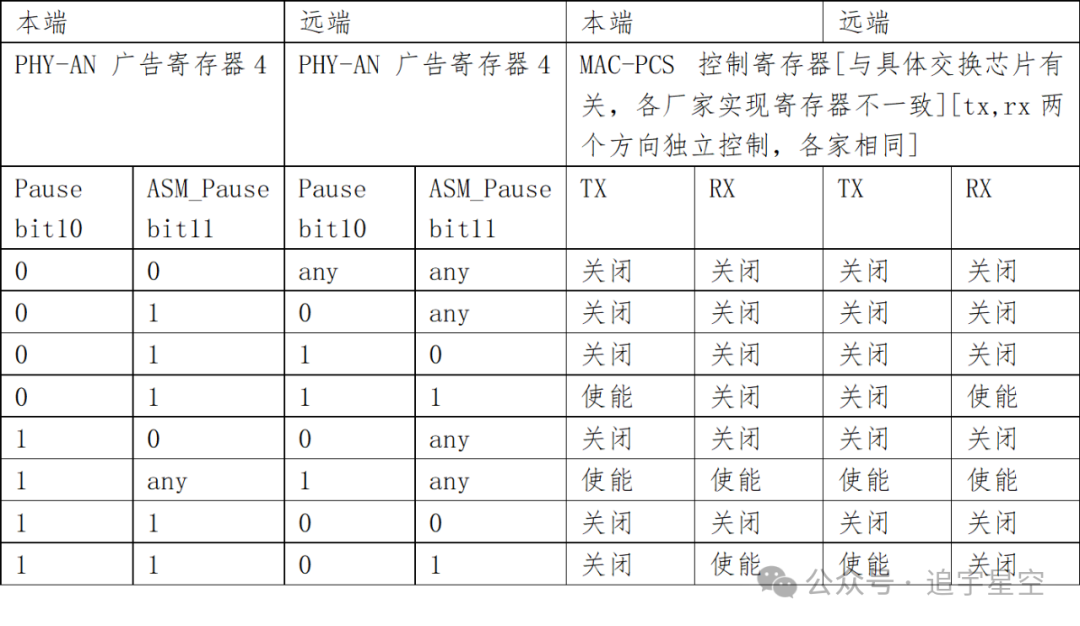
“MAC-PCS控制寄存器”需要软件根据“PHY-AN广告寄存器”和“PHY-AN LP广告状态寄存器”的内容进行动态更新配置,交换芯片硬件并不会自动联动。 流控设置之所以有上表的规则要求,是需要保证双绞线链路双方的流控状态匹配(双方都“tx 使能rx使能”,双方都“tx关闭rx关闭”和一方“tx关闭rx使能”另一方“tx使能rx关闭”)。如果出现双绞线链路双方流控失配,在链路拥塞时不但不能享受流控的优点,反而会引起链路中出现大量Pause流控帧使已经拥塞的链路更加拥塞。
主从协商
在1000BASE-T模式中,链路的两端执行环路定时(loop timing)。链接的一端协商配置为主设备,另一个协商配置为从设备。主设备发送和接收时钟锁定在本地晶振输入。从设备发送和接收时钟被锁定到传入的接收数据流。环路定时(loop timing)通过确保发射机和接收机在链路的每一端都以相同的频率工作。
主从协商主要靠设置 “本地控制寄存器1000BASE-T ControlRegister Page 0, Register 9”的bit12:10实现的。具体规则如下表:
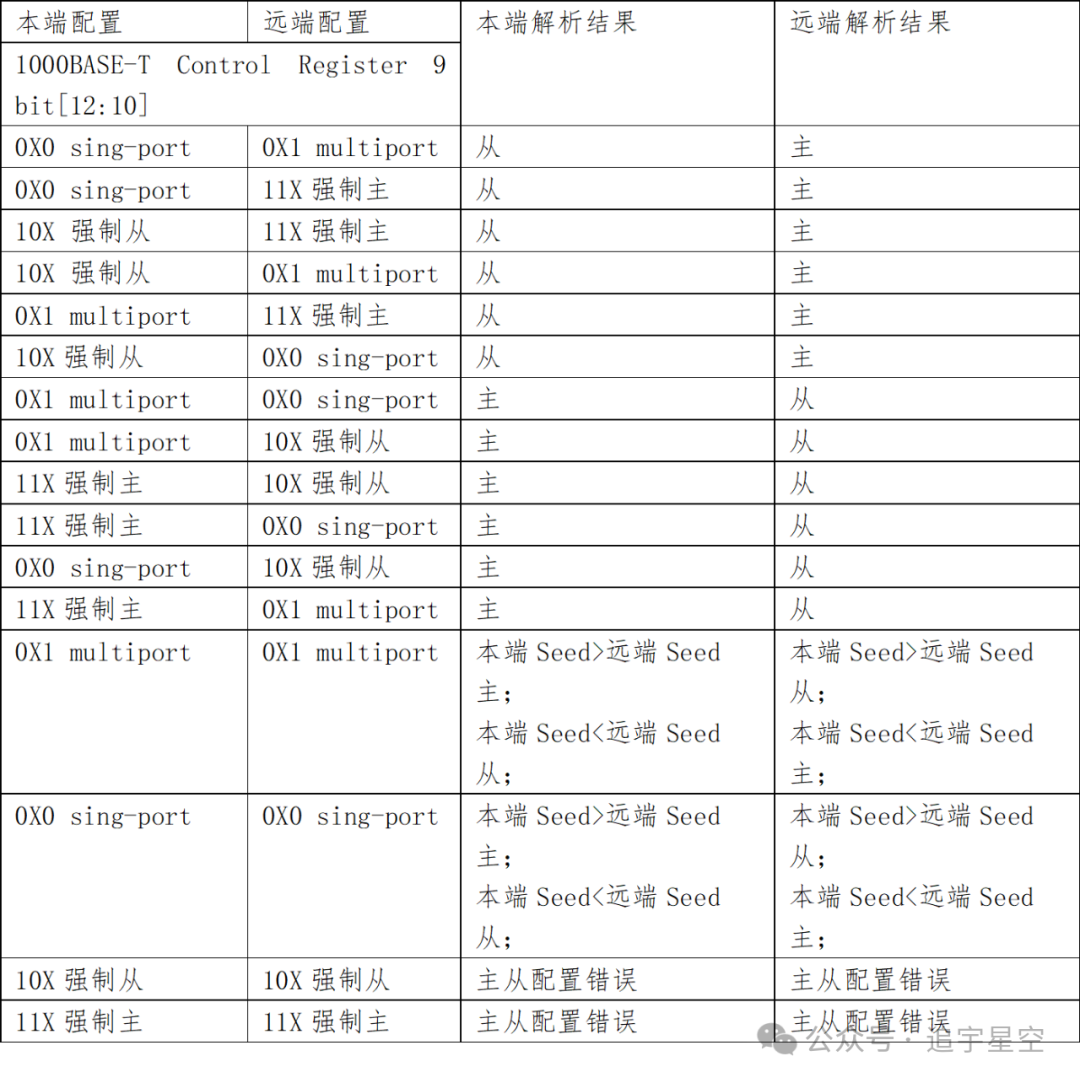
网络管理员因避免出现上述表格的最后两种情况,一旦出现此情况10M/100M/1000M自协商将永远无法完成,故此时本端和远端永远无法建立正确链接。 好的小伙伴们,这期10M/100M/1000M自协商就讲完啦,下一课会开始“10M/100M/1000M/2.5G/5G/10G/25G/40G自协商”相关内容。
审核编辑:刘清
-
以太网自协商机制-双绞线自协商案例设计(三)2024-03-18 3203
-
以太网自协商机制-双绞线自协商案例设计(二)2024-03-17 2919
-
基于IEEE Clause 28双绞线的以太网自协商机制2024-03-15 1669
-
一文解析以太网自动协商技术2024-02-22 7542
-
基于DP83822I工业以太网PHY自协商功能与其Strap电阻配置2022-11-11 775
-
以太网网口自协商功能现象2021-12-29 12732
-
10G/25G以太网IP自协商调试方案2020-11-03 7339
-
如何调试10G/25G以太网IP自协商/Link Training2020-09-03 11367
-
为什么以太网+柔性板与电脑无法协商为100M?2019-09-11 2355
-
DP83822I工业以太网PHY自协商功能与其Strap电阻配置2019-03-14 3250
-
基于语义网技术的SLA协商机制2018-01-02 942
-
FPGA光纤以太网自协商的设计2011-03-26 928
全部0条评论

快来发表一下你的评论吧 !
