

如何解决FPGA布局布线的拥塞问题呢?有哪些方法?
描述
解决布线拥塞问题
1.问题①的解决方法
14.2节提到的问题①,即设计中有很大的扇出,对于如何获知该扇出信号有多种途径。常见的途径是通过FPGAEditor(Xilinx)或者Fitter里Resource Section中的Control Signals 或者 Non Global Hign Fan-out Signal(Altera)查看扇出信号的大小排序。以Altera为例(下面的例子只是一个示范,并非说该例子是扇出过大导致布线问题),编译完成后,查看Fitter报告即可查看扇出,如图14-2所示。
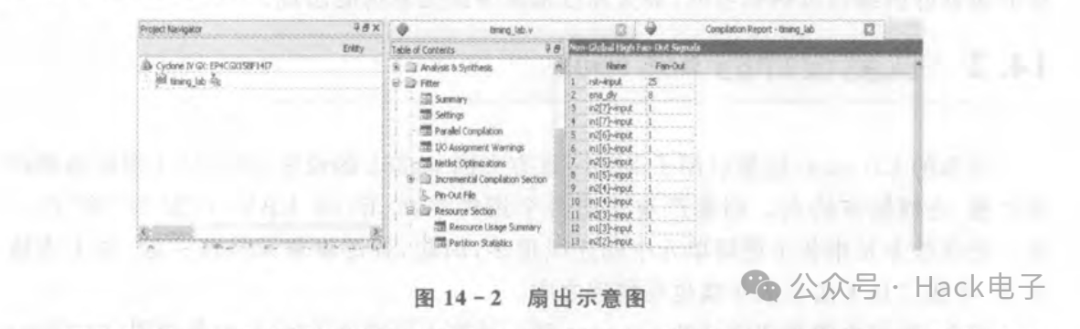
可以看到,rst这个复位信号的扇出有33个,ena_dly有8个。该设计对应的RTL代码如下:


从代码中可以看到,控制信号enadly有效时才对输入信号inl和in2的寄存信号进行或操作,因此该控制信号直接控制着输出寄存器ut[7:0]的翻转,该控制信号的扇出量为8个寄存器。所以,通过对编译结果的查询可以知道扇出信号较大的为哪些,结合代码对其进行修改即可。注意,本段RTL代码只是举例说明如何查找和定位扇出信号,并不表明扇出信号为8就会导致时序问题。实际上非全局信号的扇出多少才是合理的要看具体的布线情况,且要视FPGA器件而定。在编写代码阶段要养成时刻警惕扇出过大的问题,一般而言,如果一个信号扇出到几百个寄存器或者逻辑单元,则
最好对该信号做逻辑复制。知道如何定位控制信号的扇出后,我们就要着手于如何修改。对于此类修改,一般有两种方法:第一种是让工具自己做扇出复制;第二种是设计者在代码中手动修改,让工具自己做扇出复制。以Altera为例,在settings中,单击Fitter Settings,然后单击More Settings,弹出如图 14-3的界面。
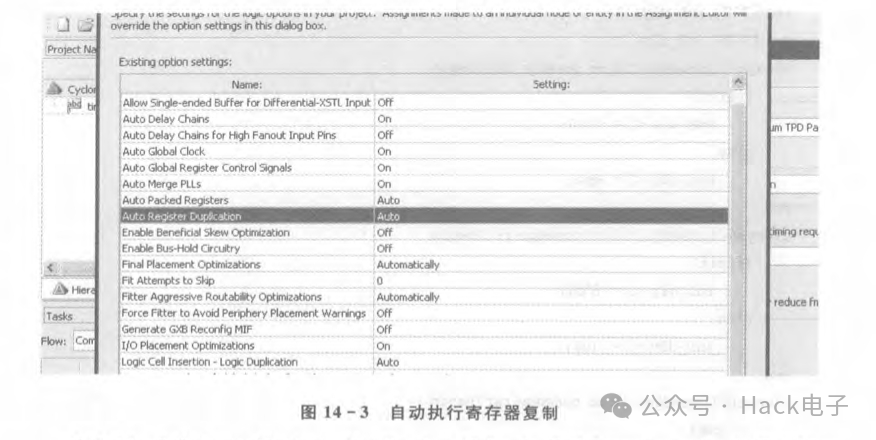
对图14-3 中 Auto Register Duplication 和 Logic Cell Insertion -Logic Duplication中的Auto全部改为On,则工具会对由扇出引起的布线时序问题做逻辑复制。而在手动做扇出寄存器/信号复制的情况下,则对该信号做复制。以上面的RTL为例子,假设要把enable信号的扇出控制到4,那么只须做如下调整:



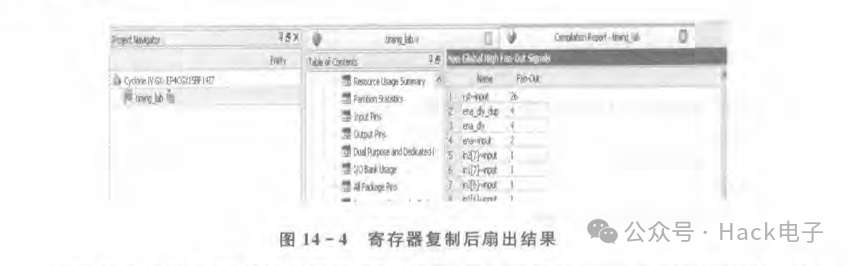
可以看到,对ena_dly做了寄存器复制,多了一个ena_dly_dup,这样ena_dly的信号扇出就减少了一半,另外一半由ena_dly_dup代替。注意,声明该寄存器时有“/*synthesispreserve*/;"语句,这是为了告诉编译器不要对该信号做优化,因为在通常情况下,编译器会对多余或者等效的寄存器做优化,只保留一个。从图14-4可以看出,ena_dly的扇出减少了一半。
2.问题②的解决方法
关于第二个问题,即复位信号造成的布局布线问题,一般有如下解决方法:
对于复位信号,如果是异步复位、同步释放,那么将会对removal路径做时序分析,该路径要求所有的复位信号在同一个节拍内撤离且满足removal的时序要求。对于这种情况,如果能够确定设计里所有的寄存器在复位不在同一个节拍内无效的情况下也能正常工作,那么可以对该路径做falsepath处理,即在时序约束里对复位信号到所有相关寄存器的路径做不分析处理。
另外一个方式是降低复位信号的扇出,没有必要对所有的寄存器都加上复位信号,作者推荐数据路径上的流水线寄存器可以不加复位信号,只对控制路径上的寄存器(如计数器、数据使能信号)等加上复位信号,从而大幅度降低复位信号的扇出。另外,在Xilinx器件中,不推荐对BIockRAM、DSP48中的流水线寄存器等加入复位信号。
3.问题③解决方法
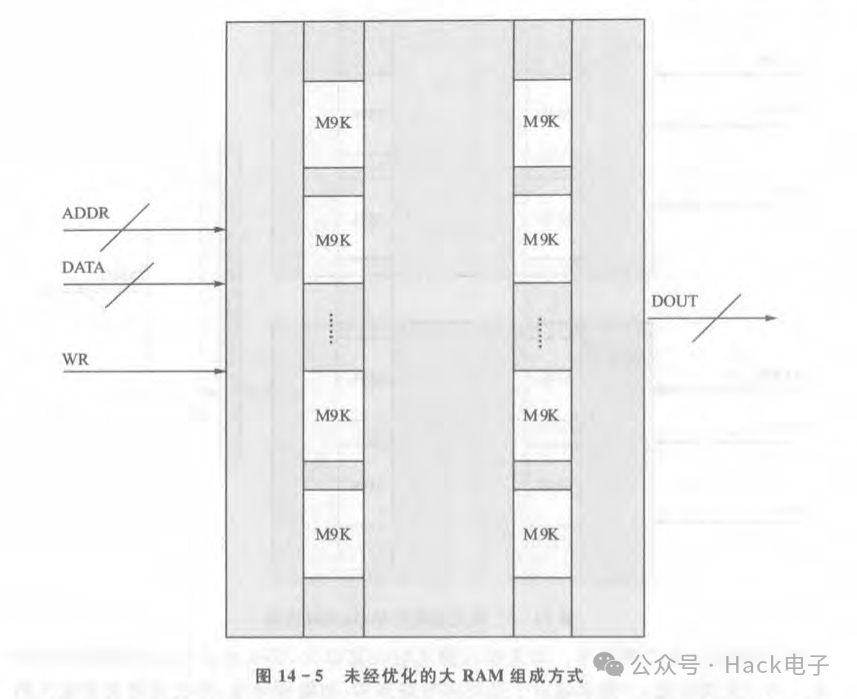
关于第三个问题的解决思路,一般来说设计者应该极力避免使用FPGA的BlockRAM IP来生成大容量的BlockRAM。比如说,用Block Memory Generator生成一个位宽为16,深度为1M的BIockRAM。因为在这种情况下,IP生成工具是把很多Block RAM单元(以AlteraCycloneIV为例,其BlockRAM基本单元为 M9K,即一个BlockRAM的存储容量为9kbit,其最大读写位宽和深度是确定的)拼接在一起形成-个大的BIocKRAM。这种情况下,IP生成工具生成的BlockRAM由于多片拼接在起,有可能造成各个BlockRAM基本单元间的距离过大,进而造成走线过长,从而产生拥塞和布线困难问题,如图14-5所示。
如图14-5所示,FPGA中每个BlockRAM单元(以M9K为例)在基底中都是列状分布,如果生成的BIocKRAM容量太大,那么将会使用一列甚至是两列M9K来拼接。而对于外部信号来说,就只有ADDR总线、DATA总线、WR信号等对其操作,这就要求ADDR、DATA、WR等信号的输出寄存器到各个M9K的时序路径都要满足而如果M9K过多,那么基本上这是不可能达到的,如此即会造成布线拥塞。
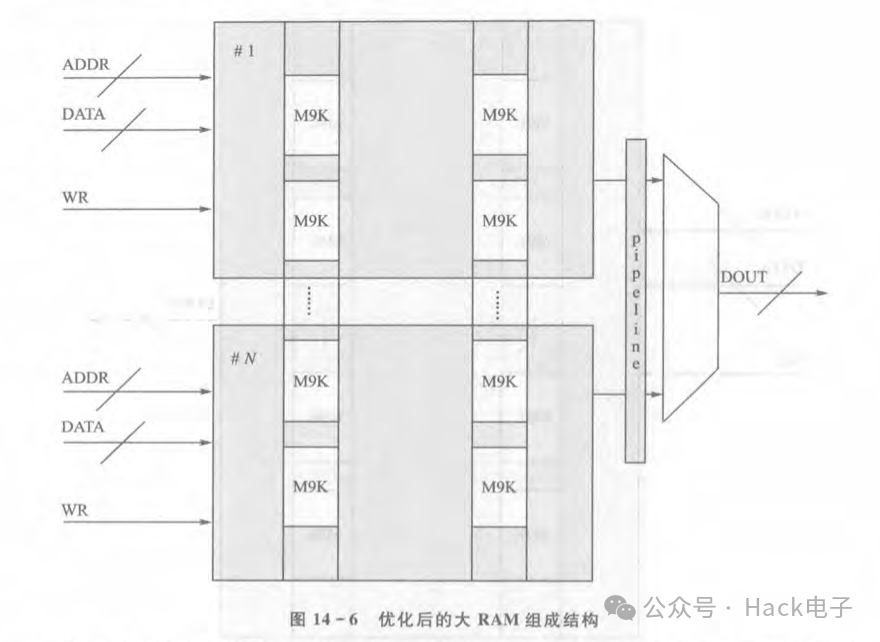
正确的解决方法是把一个大的BlockRAM手动拼接,假设要生成一个位宽为16bit、深度为1M的Block RAM,那么可以把其拆分成10个位宽为16bit、深度为100K的Block RAM,然后再由这些较小的BlockRAM来组成一个大的BIockRAM。读者可能会问,这跟上面的有何区别?区别就是设计者可以对ADDR、DATA、WR等信号进行逻辑复制,即一共有10个相同的ADDR,DATA,WR分别操作这10个BlockRAM,然后根据操
作结果进行选择输出,从而降低了ADDR、DATA、WR等信号到达各个M9K的扇出提高布线成功率,如图14-6所示。如图14-6所示,原来一个大的BIockRAM被拆分成了N个,每个都由一套等效的ADDR、DATA和WR进行控制,从而降低了ADDR、DATA和WR在操作大的BlockRAM时的扇出,增加了可布线和时序收敛性。另外,在各个BIockRAM的输出MUX里要多打几级pipeline,有助于时序收敛。同理,对于DSP硬CORE使用过多造成的布线时序问题,作者推荐对DSP硬CORE的输入输出进行多级pipeline。
4.问题④的解决方法
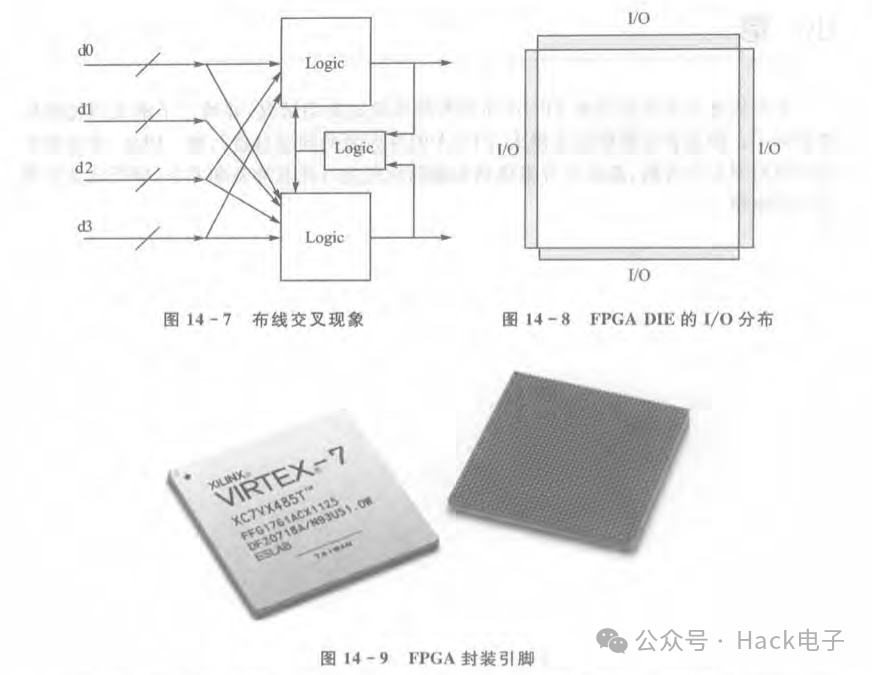
对于设计中的电路交叉线过多引起的布局布线问题的解决,有可能需要对电路/逻辑结构进行优化或者再设计。这跟PCB布局布线是一个道理,如果一个设计在PCB布线时发现,原理图设计者对IC之间引脚的连线比较随意,造成交叉线过多,比如说MCU的通用I/O跟外部芯片的连接,那么这时候可以选择调换MCU通用I/O引脚来降低连线之间的交叉,进而降低布局布线难度。比如说,一个逻辑设计的结构如图14-7所示。
这种结构的数据流很容易造成布线拥塞或者布线困难,因为输入数据流之间是交
叉的,而输出又有反馈环节。如果输入输出的位宽很大,那么将会导致布线困难的问题。对于此类问题,一般来说由于是逻辑电路架构/功能所导致,修改需要花费很大的力气。一般来说,在不修改整体架构的情况下,在数据的输入输出之间最好做多级流水线寄存器,目的并不是减少组合逻辑的层数,而是减少寄存器到寄存器之间的走线。图14-7的硬件结构存在大量交叉,因此很多内部互连需要绕很远,从而大大增加了走线延时。这样就只能增加寄存器的流水级数,降低寄存器到寄存器之间的走线延时。
5.问题⑤的解决方法
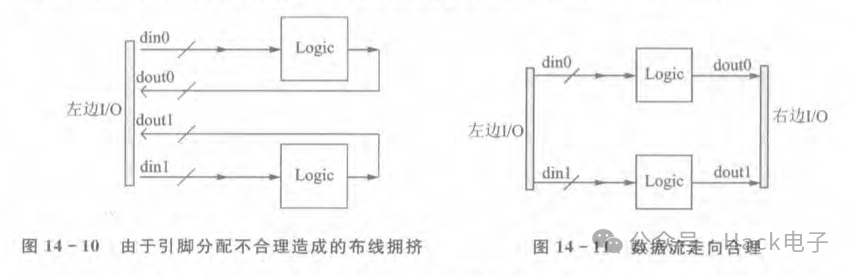
还有一种情况是FPGA引脚分配不合理导致数据流出现大量交叉进而导致时序收敛困难或者布线失败。在FPGA的基底里面,引脚的排布跟外面封装的引脚排布是不一样的,FPGA基底里面的引脚排布大部分位于芯片的左边、右边、上边和下边,如图14-8所示。
对于很多BGA封装的FPGA,尽管从其封装图上看,引脚分布在芯片内部,如图14-9所示,但是实际上在芯片内部,引脚的排布却是跟图14-8类似。因此,当引脚分配不合理时,在FPGA内部的数据流有可能造成交叉,或者输入输出混在一起,如图14-10所示。
如果引脚分配不合理,输入和输出的I/O在FPGA的基底引脚中的距离都放得很近的话,那么当数据很多且内部逻辑处理占用资源较多时,将会带来很大的布线问题因此可酌情对引脚进行调整,力争做到数据流是顺着的,如图14-11所示。
其实这一步应该在FPGA原理图设计阶段的FPGAPinLocation时就要考虑到宁可在前期的方案设计方面多花一点功夫,也不要匆匆上马,欠缺考虑,只有在前期做足准备,到后面才会事半功倍。
小 结
本章讲述了常见的导致FPGA布局布线失败的典型情况,并给出了解决问题的思路和例子。随着设计规模越来越大,FPGA时序收敛的问题日益凸现。因此,在遇到此类问题时要心中有数,最好在方案规划和编码阶段就对此有准备和考虑,降低此类问题发生的概率。
审核编辑:刘清
-
PADS Layout布局布线有什么技巧呢2014-12-31 15854
-
FPGA去耦电容如何布局布线2017-08-22 10440
-
如何判断PCB布局布线合理呢?谢谢2017-11-21 3037
-
如何应对FPGA的拥塞问题2018-06-26 4141
-
PCB布局和布线的设计技巧有哪些?2021-04-25 2509
-
如何解决高速信号的手工布线和自动布线之间的矛盾2009-03-20 1137
-
FPGA设计的塑封式布局和布线介绍2019-05-17 3968
-
FPGA的布局布线2020-10-25 9492
-
MCM布局布线的软件实现2020-11-20 4296
-
FPGA布线为什么会拥塞呢?如何解决呢2022-08-25 2466
-
FPGA布线拥塞主要原因及解决方法2022-12-07 2362
-
PCB布局布线技巧104问2023-05-05 1647
-
如何解决高速信号的手工布线和自动布线之间的矛盾?2023-11-24 1711
-
fpga布局布线算法加速2023-12-20 2246
-
FPGA布局布线的可行性 FPGA布局布线失败怎么办2024-03-18 2091
全部0条评论

快来发表一下你的评论吧 !
