

探索推理时KV Cache的动态内存压缩方法
人工智能
描述
摘要:Transformers已成为大型语言模型(LLM)的支柱。然而,由于需要在内存中存储过去标记的键值表示缓存,其大小与输入序列长度和批量大小成线性比例,因此生成效率仍然很低。作为解决方案,我们提出了动态内存压缩(DMC),这是一种在推理时在线压缩键值缓存的方法。最重要的是,该模型可以学习在不同的头和层中应用不同的压缩率。我们将预训练的 LLM(如 Llama 2(7B、13B 和 70B))改装成 DMC Transformers,在英伟达 H100 GPU 上实现了高达 ~3.7 倍的自动回归推理吞吐量提升。DMC 通过持续预训练应用于可忽略不计的原始数据百分比,而不添加任何额外参数。我们发现,DMC 保持了原有的下游性能,缓存压缩率高达 4 倍,优于向上训练的分组查询注意(GQA)。GQA 和 DMC 甚至可以结合使用,以获得复合增益。因此,在任何给定的内存预算内,DMC 都能适应更长的上下文和更大的批次。
Q1: 这篇论文试图解决什么问题?
A:这篇论文提出了一种名为动态内存压缩(Dynamic Memory Compression,简称DMC)的方法,旨在解决大型语言模型(Large Language Models,简称LLMs)在推理(inference)阶段的内存效率和生成效率问题。具体来说,论文关注的问题包括:
内存消耗:在自回归生成过程中,Transformer模型需要在内存中存储过去token的键值(key-value)表示,这些表示的内存消耗与输入序列长度和批量大小线性相关,导致内存负载随序列长度增加而迅速增长。
生成效率:由于上述的内存消耗问题,使用Transformer模型进行长序列生成(如对话和故事生成)或同时服务大量用户查询时,会变得非常低效,因为内存限制了批量大小和序列长度。
现有解决方案的局限性:虽然已有一些方法(如Grouped Query Attention,GQA)通过减少内存中的token数量来提高Transformer模型的内存效率,但这些方法往往会牺牲下游任务的性能。
为了解决这些问题,论文提出了DMC方法,它允许模型在推理时动态地压缩键值缓存,并且能够学习在不同头(heads)和层(layers)中应用不同的压缩率。这种方法旨在在不增加额外参数的前提下,通过少量的继续预训练(continued pre-training)来实现,从而在保持原有下游性能的同时,显著提高模型的内存效率和生成速度。
Q2: 有哪些相关研究?
A:这篇论文提到了与动态内存压缩(DMC)相关的几个研究领域和具体工作,包括:
Transformer模型和大型语言模型(LLMs):Transformer作为LLMs的骨干网络结构,是当前生成式和对话式AI的最新进展。例如,Touvron et al. (2023) 和 Jiang et al. (2023) 等人的工作展示了LLMs在各种任务上的应用。
内存效率的Transformer变体:为了提高Transformer在推理阶段的内存效率,研究者们提出了多种方法,如Grouped Query Attention (GQA),它通过参数共享减少键值头的数量。其他方法包括token合并和token剪枝,但这些方法往往会牺牲性能。
硬件/IO感知和子二次方算法:Dao et al. (2022) 和 Kwon et al. (2023) 等人的研究关注于如何使注意力机制更加高效,但这些方法并没有直接减轻键值缓存的内存负担。
动态压缩方法:Anagnostidis et al. (2023) 和 Kim & Cho (2020) 等人提出了动态压缩方法,这些方法在推理时决定哪些token应该从键值缓存中丢弃。与DMC不同,这些方法通过丢弃token来减少内存消耗,而不是合并它们。
非学习型缓存驱逐策略:Zhang et al. (2023) 和 Sheng et al. (2023) 等人研究了基于启发式的缓存驱逐策略,这些策略不依赖于额外的训练,但缺乏学习压缩机制的能力。
动态令牌池:Nawrot et al. (2022) 提出了动态令牌池(Dynamic Token Pooling),这是一种在中间层对token表示进行合并的方法,DMC在这一基础上进行了改进,将其应用于KV缓存,并在训练期间引入了池化决策的连续放松。
这些相关研究为DMC的提出提供了背景和对比,DMC通过在保持原有模型性能的同时减少内存消耗,为提高大型语言模型的推理效率提供了一种新的解决方案。
Q3: 论文如何解决这个问题?

 A:论文提出了一种名为动态内存压缩(Dynamic Memory Compression,DMC)的方法来解决大型语言模型(LLMs)在推理阶段的内存效率和生成效率问题。具体解决方案包括以下几个关键步骤:
A:论文提出了一种名为动态内存压缩(Dynamic Memory Compression,DMC)的方法来解决大型语言模型(LLMs)在推理阶段的内存效率和生成效率问题。具体解决方案包括以下几个关键步骤:
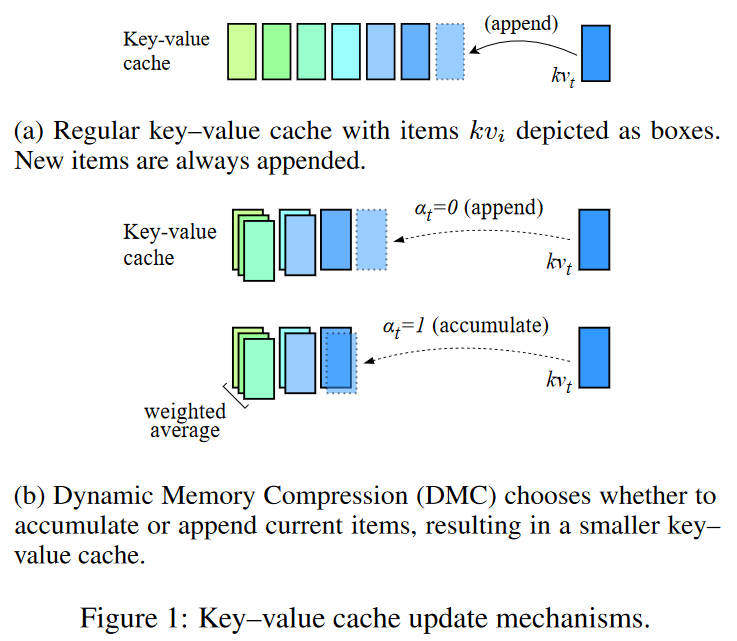
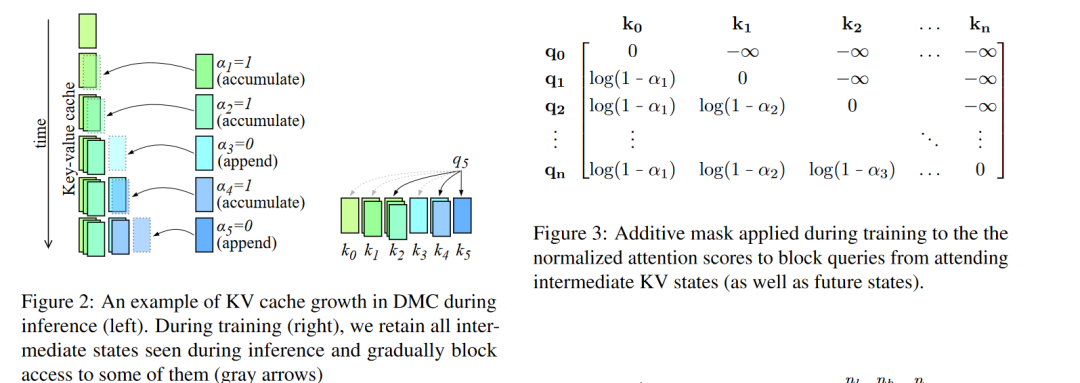
在线键值缓存压缩:DMC在自回归推理过程中动态地决定是否将当前的键(key)和值(value)表示追加到缓存中,或者与缓存中的顶部元素进行加权平均。这种机制允许模型根据输入序列的当前部分来调整缓存的大小。
端到端学习:DMC通过在继续预训练(continued pre-training)过程中逐渐增加全局压缩率(global Compression Ratio,CR),让模型学习如何应用不同的压缩策略。这个过程不需要引入额外的参数。
分段机制:DMC通过一个决策变量(α)来有效地对输入序列进行分段,每个段落可以独立地决定是继续追加还是进行累积。这允许模型在不同段落之间动态调整内存使用。
重要性评分:DMC还引入了一个重要性变量(ω),用于在累积操作中计算当前token与缓存顶部元素的加权平均,这样模型可以学习保留更重要的信息。
训练策略:为了训练DMC模型,论文提出了一种随机重参数化(stochastic reparametrization)的方法来处理离散的决策变量,以及一种中间压缩步骤(intermediate compression steps)来处理连续的α值。此外,还设计了一个全局一边损失(global one-sided loss)来激励模型达到目标压缩率。
实际考虑:为了在不使用填充张量(padded tensors)的情况下实现变长缓存,论文提供了一个基于PyTorch的自定义注意力机制实现,该实现允许不同的头学习不同的压缩率,同时避免了填充的需要。
通过这些方法,DMC能够在保持原有LLMs性能的同时显著提高内存效率和推理速度,使得模型能够适应更长的上下文和更大的批量大小,同时减少内存消耗。论文通过在不同规模的Llama 2模型上进行实验,证明了DMC的有效性。
Q4: 论文做了哪些实验?
A:论文中进行了一系列实验来验证动态内存压缩(DMC)方法的有效性和效率。以下是实验的主要内容:
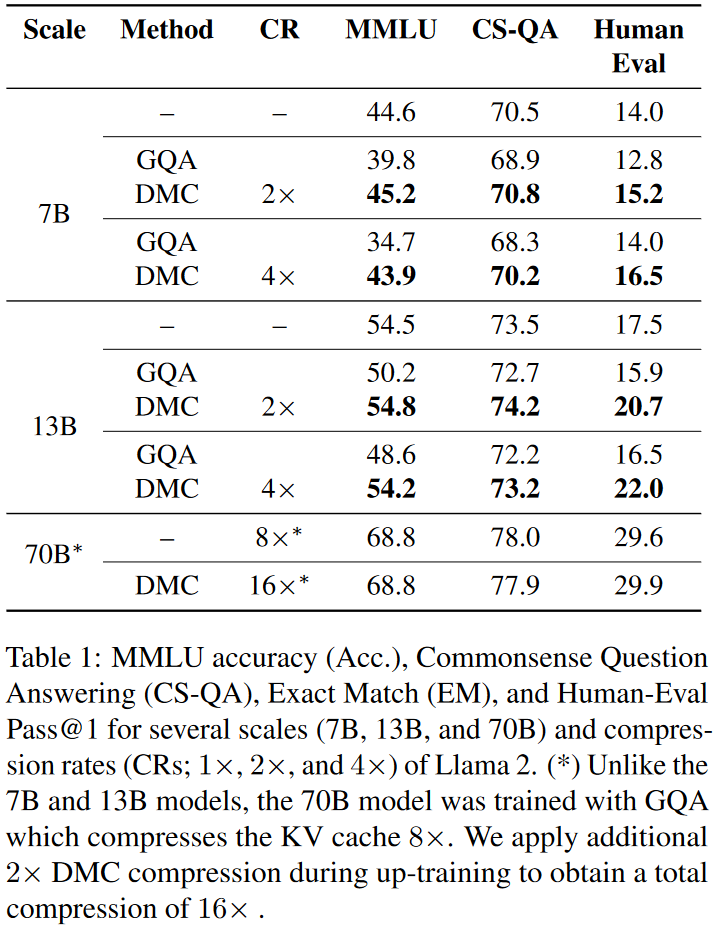
基线模型:选择了不同规模的Llama 2模型(7B、13B和70B)作为基线模型,并与原始模型进行了比较。
压缩率(CR)目标:针对不同的压缩率(2×、3×和4×)训练DMC模型,并通过继续预训练(continued pre-training)逐步增加压缩率。
性能评估:在多个下游任务上评估DMC模型的性能,包括MMLU(用于事实性)、QA数据集(用于常识推理)和HumanEval(用于代码生成)。
与GQA的比较:将DMC与Grouped Query Attention(GQA)进行比较,GQA是一种广泛使用的减少KV缓存大小的方法。
样本效率:比较DMC和GQA在不同压缩率下的样本效率,即在达到相同性能时所需的训练步骤数量。
吞吐量和延迟测量:使用NVIDIA Megatron-LM框架在NVIDIA A100和H100 GPU上测量DMC模型的推理吞吐量和延迟,以评估其在实际硬件上的性能提升。
每层和每头的压缩率分析:分析DMC模型在不同层和头中学习到的压缩率分布,以了解模型如何动态调整压缩策略。
训练策略的消融研究:研究不同的训练策略(如不同的目标CR调度和训练步骤数)对DMC模型性能的影响。
DMC变体的评估:评估DMC的一个变体(DMC-C),它强制在同一层中的头保持相似的压缩率,以减少填充并比较其与标准DMC的性能差异。
这些实验结果表明,DMC模型能够在保持或甚至提高原始模型下游任务性能的同时,显著提高推理效率,减少内存消耗,并允许更大的批量大小和更长的序列处理。此外,DMC模型还能够与GQA结合使用,以获得更高的压缩率和进一步的性能提升。
Q5: 有什么可以进一步探索的点?
A:尽管论文提出了一种有效的动态内存压缩(DMC)方法并进行了广泛的实验验证,但仍有一些潜在的研究方向和可以进一步探索的点:
不同模型架构的适用性:研究DMC方法在不同类型的Transformer模型或其他序列处理模型中的应用,例如BERT、GPT、T5等。
从头开始训练的模型:探索在模型预训练阶段直接集成DMC机制的可能性,而不是仅在预训练模型上进行改造。
更深层次的解释性分析:对DMC模型学习到的压缩模式进行更深入的分析,以理解模型如何根据输入序列的不同特征进行压缩。
压缩策略的优化:研究是否可以进一步优化压缩策略,以提高内存效率和推理速度,同时保持或提高模型性能。
长序列和复杂任务的性能:在更长的序列和更复杂的任务上评估DMC模型的性能,以测试其在实际应用中的有效性。
不同硬件配置下的性能:在不同的硬件配置上测试DMC模型,包括CPU、不同的GPU型号以及其他加速器,以评估其通用性和可扩展性。
实时或在线生成场景:研究DMC在实时或在线生成场景中的应用,例如聊天机器人、语音识别和翻译系统。
环境影响和能效:评估DMC在减少计算资源消耗和降低环境影响方面的潜力,特别是在大规模AI模型训练和部署中。
与其他技术的结合:探索将DMC与其他模型压缩和效率提升技术(如量化、剪枝、知识蒸馏等)结合使用的可能性。
开源实现和社区贡献:鼓励开源DMC的实现,并与研究社区合作,以促进方法的改进和应用。
这些潜在的研究方向可以帮助进一步提升DMC方法的性能和实用性,同时为大型语言模型的高效推理提供新的思路。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
背景: 大型语言模型(LLMs)如Transformer在生成任务中表现出色,但在推理阶段存在内存消耗大和生成效率低的问题,因为需要存储过去token的键值(key-value)表示。
问题: 随着输入序列长度的增加,键值缓存的大小线性增长,导致内存消耗和生成延迟增加,限制了模型在长序列生成和高并发查询场景中的应用。
方法: 提出了动态内存压缩(DMC),一种在推理时在线压缩键值缓存的方法。DMC允许模型根据输入序列动态决定是追加新的键值表示到缓存中,还是与缓存中的顶部元素进行加权平均。
实现: 通过在原有预训练模型上进行少量的继续预训练,DMC能够在不增加额外参数的情况下学习不同的压缩策略,实现高达4倍的缓存压缩。
实验: 在不同规模的Llama 2模型上进行实验,包括7B、13B和70B版本,评估了DMC在多个下游任务上的性能,如MMLU、QA数据集和HumanEval。
结果: DMC在保持或提高原始模型性能的同时,显著提高了推理速度和内存效率。与Grouped Query Attention(GQA)相比,DMC展现了更高的性能和样本效率。
结论: DMC是一种有效的技术,可以加速大型语言模型的推理过程,减少内存消耗,并允许模型处理更长的上下文和更大的批量大小。此外,DMC的压缩策略可以与GQA结合,实现进一步的性能提升。
未来工作: 论文提出了一些潜在的研究方向,包括将DMC应用于不同的模型架构、在预训练阶段集成DMC、以及在不同硬件配置下测试DMC的性能。
审核编辑:黄飞
-
忆联自研芯片以压缩技术重塑KV Cache存储效率2026-04-10 582
-
如何使用LAX_CODEGEN启用动态内存分配?2025-04-10 1621
-
C语言知识总结:动态内存分配2022-10-24 1375
-
动态内存分配是什么意思2021-12-17 1340
-
请问使用动态内存分配安全吗?2021-12-15 1451
-
内存的动态内存分配实现2021-08-03 1948
-
动态内存管理模块的设计原理与实现2020-06-30 3220
-
嵌入式中是否使用动态内存?2020-02-28 2868
-
嵌入式C语言中的动态内存管理和动态内存分配2019-08-15 2786
-
静、动态内存的优劣比较2019-08-06 8089
-
嵌入式中需要用到动态内存吗2019-07-27 3750
-
arduino 动态内存不足怎么处理2019-06-18 6182
-
51单片机如何使用动态内存2019-06-14 945
-
动态内存错误的静态检测2011-06-10 1192
全部0条评论

快来发表一下你的评论吧 !
