

基于NVIDIA Megatron Core的MOE LLM实现和训练优化
描述
本文将分享阿里云人工智能平台 PAI 团队与 NVIDIA Megatron-Core 团队在 MoE (Mixture of Experts) 大语言模型(LLM)实现与训练优化上的创新工作。分享内容将按以下脉络展开:
首先简短回顾 MoE 技术的发展历程,提炼核心概念及其在实践应用中亟待解决的关键挑战。
接着详述双方合作研发的 MoE 框架所具有的独特能力和卓越性能,展示其在提升模型训练效率、资源利用以及模型表现等方面取得的验证结果。
最后,扼要介绍阿里云基于此合作成果所搭建的平台工具及推荐的最佳实践方案,赋能开发者高效运用 MoE 技术,促进大规模模型训练的深入探索与广泛应用。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIA Megatron-Core 的 MoE LLM 实现和训练优化》
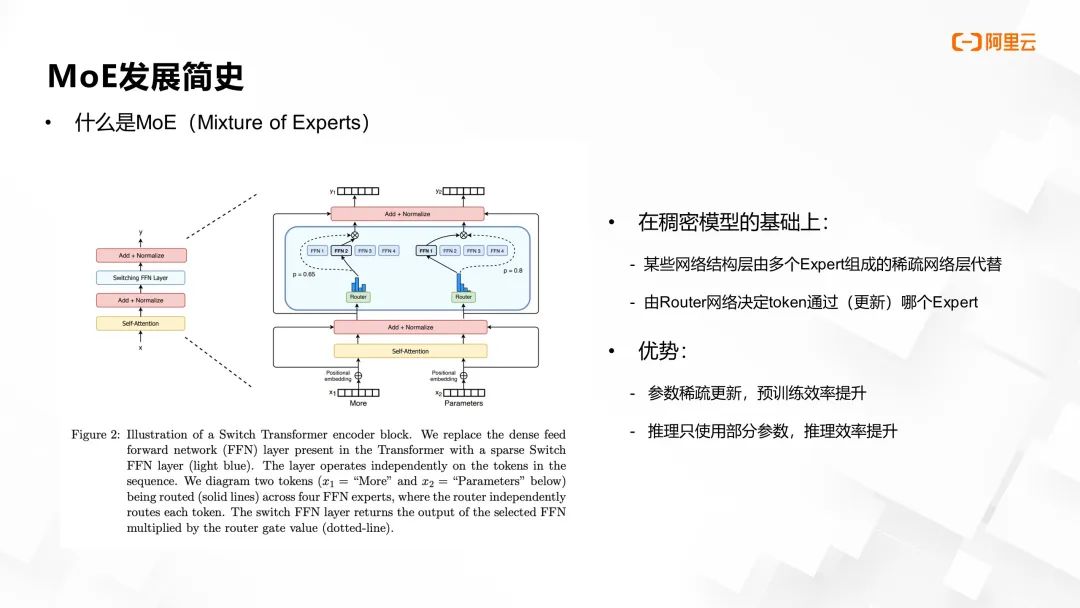
MoE 是一种模型结构,它将稠密模型结构拆分为多个子结构,每个子结构成为一个专家,通过在训练和推理过程中动态选择一组专家进行计算,实现了模型参数的稀疏更新。
简而言之,MoE 模型将整体模型拆分为多个专业子模块(专家),每次仅激活和更新少数与输入相关的专家子结构,而选择哪些专家参与计算则是通过一个路由机制决定。在 GPT 等超大规模语言模型中,采用 MoE 技术能够显著减少训练和推理时的计算负担,因为不是所有参数都需要在每次操作时都更新,这极大提高了训练效率,并且在推理阶段仅使用部分活跃的网络参数,极大地削减了计算资源需求。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
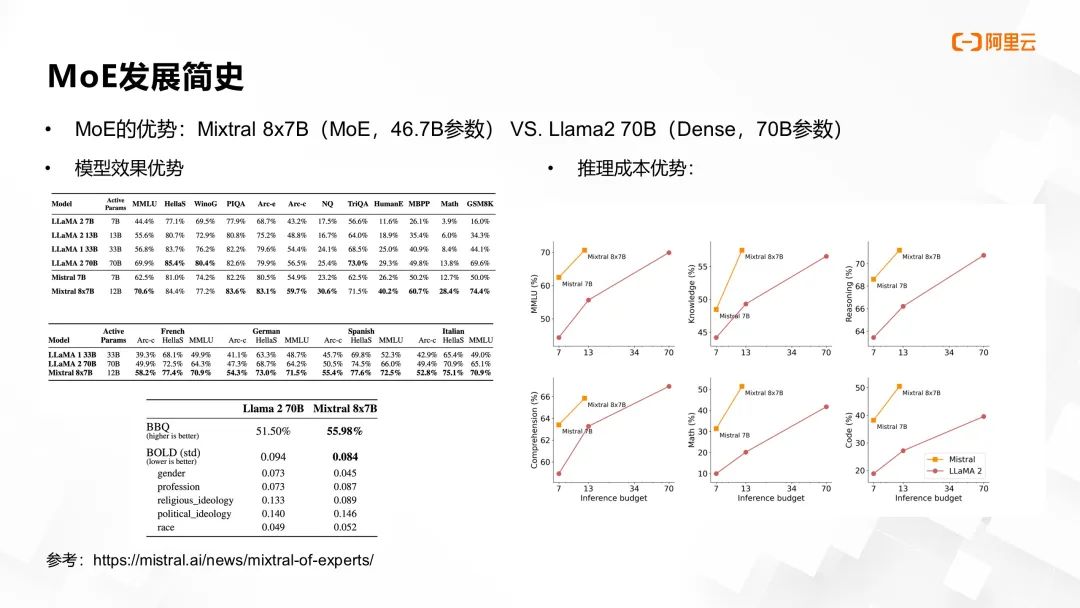
2023 年末,Mistral AI 推出开源 MoE 架构大语言模型 Mixtral 8x7B,凭借 46.7B 参数量,在多项下游任务榜单的效果胜过当时的最佳开源稠密模型 Llama-2 70B。右侧图表揭示,在同等推理资源条件下,MoE 模型性能显著优于稠密模型。这一成就引发业界对 MoE 模型的强烈关注,进而推动阿里云与 NVIDIA Megatron-Core 团队,共同深化在大模型领域的 MoE 技术合作与应用。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
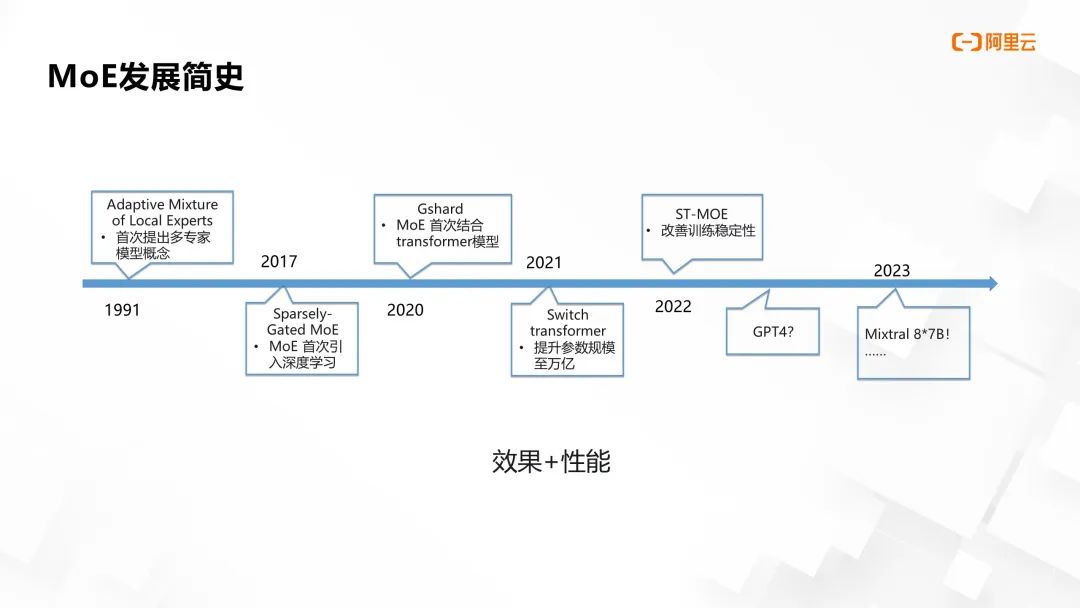
为了描述使用 MoE 结构来实现工业级应用需要解决的问题,本文首先回顾 MoE 的发展历史。90 年代初提出的多专家模型概念为 MoE 打下了理论基础,即通过集合多个专家模型协同解决任务,并采用门控路由进行专家选择。
随着 2017 年深度学习突飞猛进,参数量对模型性能的重要性日益显现,传统稠密结构深度学习框架面临容量瓶颈。谷歌率先将 MoE 与深度学习结合,首次在 RNN 中验证了 MoE 的可行性。至 2020 年,Transformer 结构在语言模型领域展现出卓越效果和优秀的可扩展性。此后,Google Gshard 项目将 MoE 融入 Transformer,通过深度设计与实验显著提升效果和性能,并在 Switch Transformers 中将参数总量推向万亿级别,奠定了 MoE 架构在大模型领域的基础。
后续研究如 ST-MoE、Tutel MoE、FasterMOE 和 MegaBlocks 等,针对速度和稳定性进行深入探索。2023 年,GPT-4 的惊艳表现引发了业内对其是否采用 MoE 结构的热议。同年,Mixtral 的实现似乎验证了这一猜想,表明 MoE 在大模型架构中的应用正逐步走向成熟和广泛认可。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
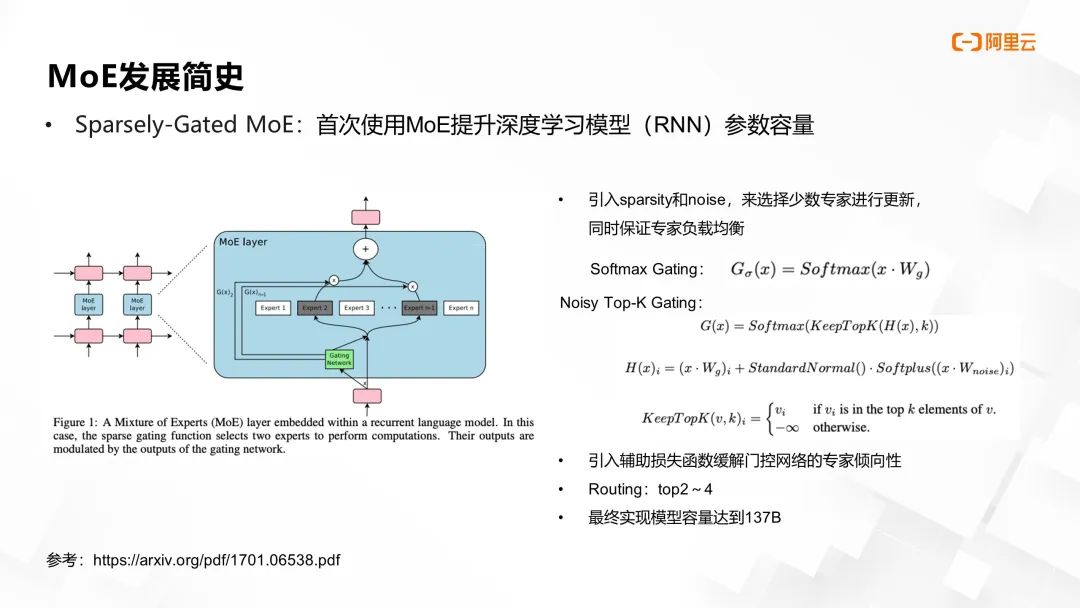
后续我们将简要剖析几个标志性工作,首先是将 MoE 与深度学习融为一体的 Sparsely-Gated MoE。该研究将 RNN 网络划分为多个专家子网络,并采用 Softmax Gating 机制来控制 token 的路由分配。然而,原始 Softmax Gating 逻辑可能导致负载不均衡,随着训练推进,部分专家网络可能过于活跃,而其他专家的参数训练不足。
为解决此问题,研究者在计算 Softmax 之前,对门控矩阵参数和输入特征进行噪声 (noise) 注入,以实现更为均衡的专家选择。此外,在门控网络损失函数 (loss function) 中增设辅助损失,引导模型实现更佳的负载分配。同时,路由策略上尝试每次挑选 top-2 至 top-4 的专家,这些优化举措最终助力模型参数容量首次突破千亿门槛。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
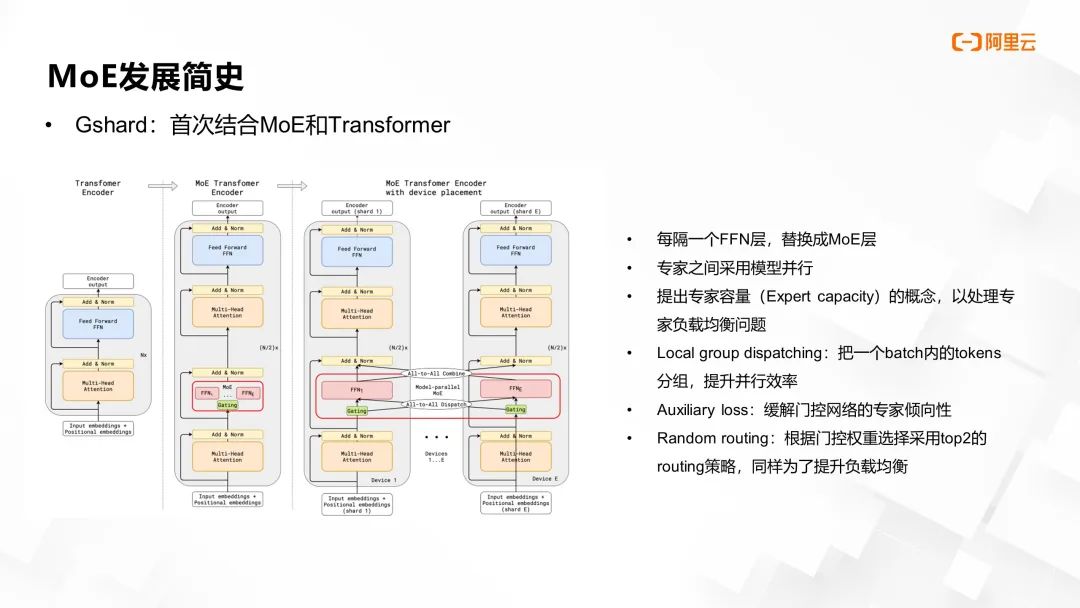
而谷歌的 Gshard 项目进一步将 MoE 应用于 Transformer 架构中,其主要创新包括:
设计了 MoE Transformer 的基本结构和并行模式,每间隔一层前向层采用 MoE 层替代,专家分布在不同设备上独立计算,其他层的参数共享。
针对专家负载均衡问题,提出了“专家容量(expert capacity)”概念,限制每个专家处理的 token 数量,并采用残差连接策略绕过已满负荷的专家。
引入辅助损失与随机 top-k 路由策略,以优化专家选择过程。
在通信效率上,创新提出“local group dispatching”方案,通过门控网络预筛选后再按专家 ID 分组传输数据,有效提升通信效率。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
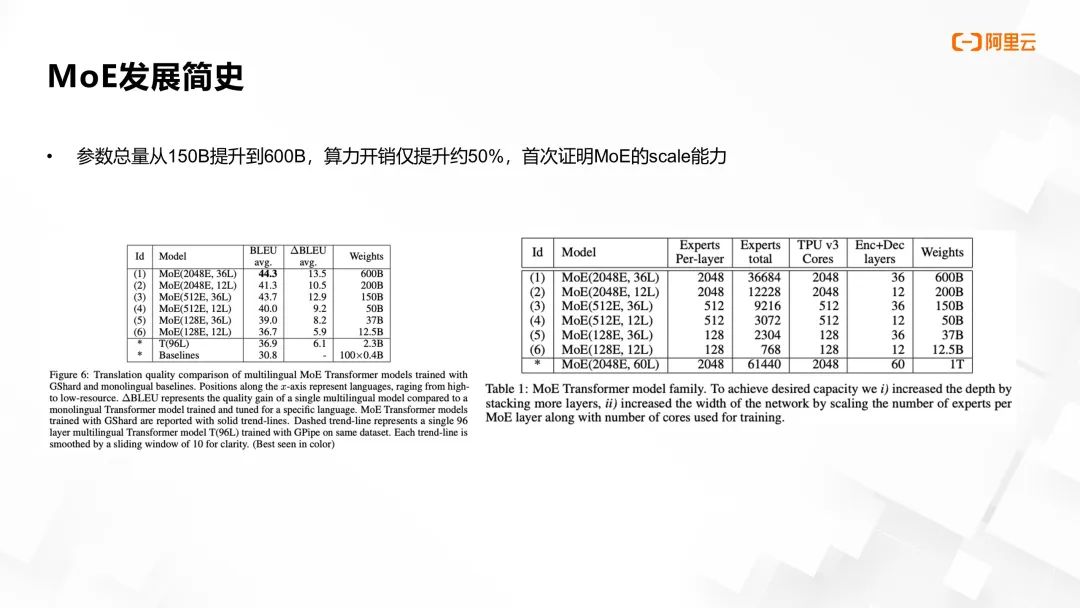
实验结果显示,Gshard 成功将 Transformer 参数量从 150B 提升至 600B,而计算开销仅增加 50%,首次验证了 MoE 在模型扩展性上的显著优势。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
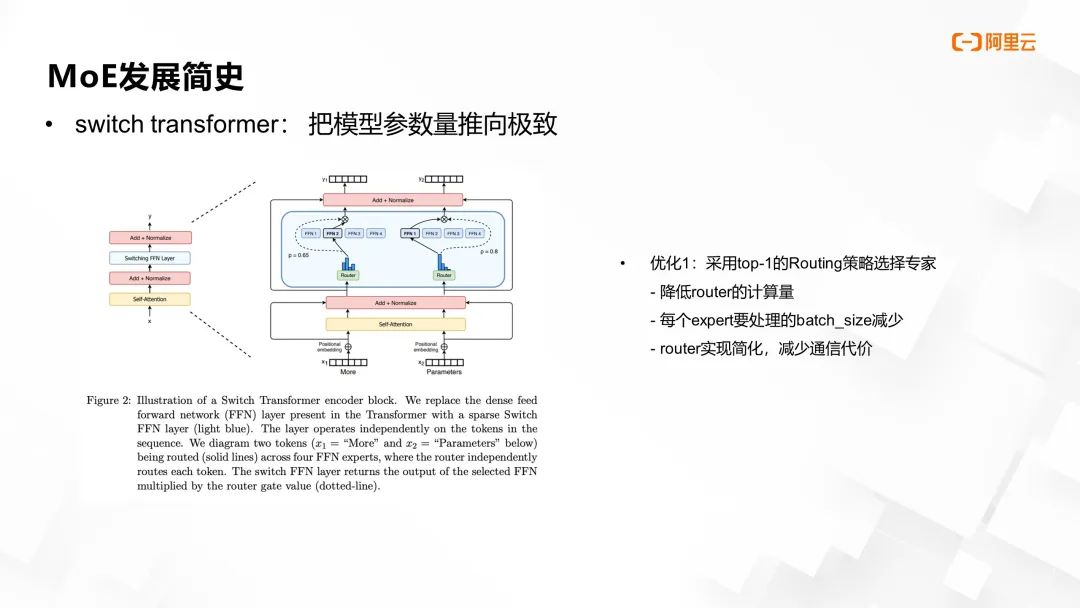
之后的 Switch Transformer 工作对 MoE Transformer 的训练流程进行了深度优化,以实现模型参数规模的极限拓展。首先,路由策略选择了更为激进的 top-1 方案,即每次仅选择一个专家进行参数更新。此举不仅能显著降低路由的计算负担,与 top-2 策略相比计算量近乎减半,同时每个专家处理的 batch size 也因此减少,进一步减轻了通信成本。

图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
其次,针对先前存在的专家负载均衡问题,工作引入了辅助损失函数。该函数中,N 代表专家总数,f 表示第 i 个专家分配到的 token 比例,P 代表路由器分配给第i个专家的概率。优化目标旨在促使 token 均匀分配至每个专家。通过最小化损失函数,使得 f 和 P 趋向于 N 分之一,此时损失函数中的调节参数 α 通常取值 0.01 左右,能够实现较好的负载均衡效果。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
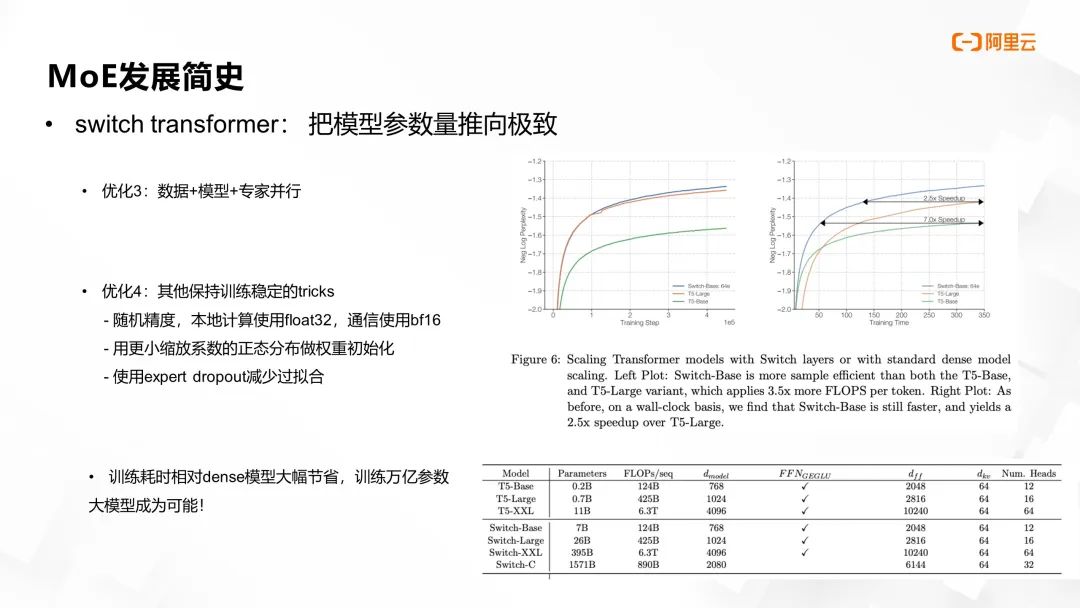
在分布式训练方面,除了先前提及的数据并行和专家并行外,该工作对非专家结构部分实施了模型并行策略,来进一步降低单卡显存需求,使得模型参数量得以显著提升。
针对路由负载均衡引起的模型训练随机性与不稳定问题,该工作提出了一系列稳定训练的策略。其中包括在本地计算时采用较高的 FP32 精度,而在通信阶段使用较低的 BF16 精度的随机精度策略;采用具有较小缩放系数的正态分布初始化权重;引入专家 dropout 即专家内部的 dropout 技术以减少过拟合现象。
通过这些优化措施,MoE transformer 的训练收敛速度相较于稠密模型在迭代次数和时间上均有数倍提升。其中,最大的 Switch-C 模型参数量高达 1.5 万亿。后续的 ST-MoE 工作则更深入地探究了如何进一步改善 MoE 模型的训练稳定性和提升模型性能。

图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
在预训练稳定性方面,为解决专家路由随机性和数值精度造成的 roundoff 误差,即路由网络计算 logits 值过大导致的训练不收敛问题,工作提出了 z-loss 函数。该函数中,B 表示一个 batch 的 token 数量,N 代表专家数量,X 则对应输入路由网络的 logits 的维度。通过引入 z-loss 有效抑制了由精度等因素导致的 logits 值过高现象,从而增强了模型训练的稳定性,z-loss 同样适用于稠密 LLM 训练的稳定性提升。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
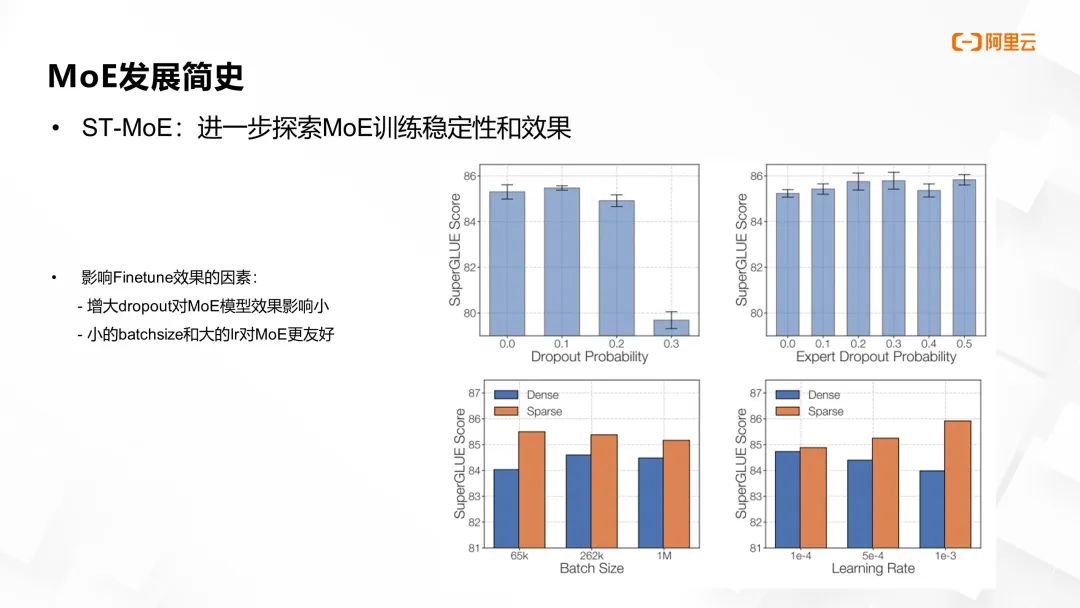
此外,该工作还深入探究了影响 MoE 训练稳定性和效果均衡的多种因素,并通过细致实验归纳出一系列最佳实践。
譬如,向路由网络引入适量噪声 (noise),例如 dropout 操作,能够增强训练稳定性,但可能模型效果受损。在调优 (Fine-tuning) 阶段,ST-MoE 的研究进一步发现,增大 dropout 参数对稠密 MoE 模型和非稠密 MoE 模型的影响存在显著差异,对于稠密模型影响更大。同时,与稠密模型不同,小型 batch size 和较大学习率 (learning rate) 对 MoE 模型训练效果的提升更为有利。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
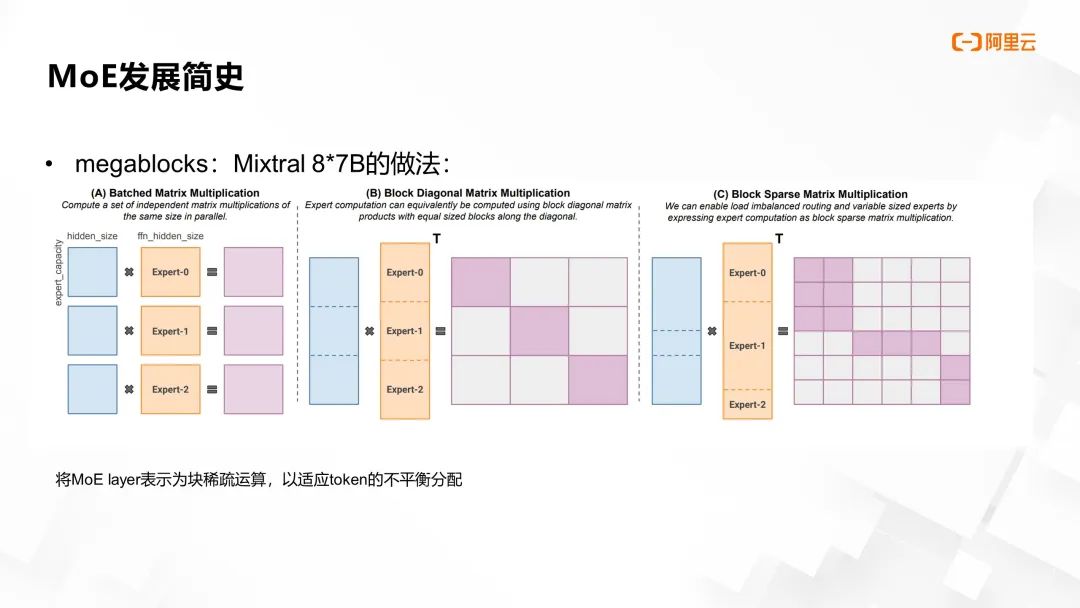
Mixtral 模型在实现上借鉴了 Megablocks 框架的独特思路,该框架的主要特点是将 MoE 层的计算表述为块稀疏运算。面对前面提及的动态路由问题,即不同专家处理的 token 数量各异,导致用户在计算过程中需抉择使用 drop token 或 padding,前者关乎模型性能,后者则会增加训练成本。
Megablocks 创新性地将多个矩阵乘的操作统一定义为一个大型块稀疏矩阵,即将多位专家的计算视作一个固定尺寸的大矩阵,其中的计算任务则细分为多个小矩阵块的 GEMM(General Matrix Multiply)操作。
为优化这种块稀疏矩阵的处理,Megablocks 框架利用了 Block Compressed Sparse Row (BCSR) 数据结构,对矩阵的行和列访问速度以及转换操作进行了优化。通过这种方法实现了路由矩阵的高效操作。

图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
上述 MoE 发展史详细说明了其开发需要解决的问题,下文将简介阿里云为解决这些问题,与 NVIDIA Megatron-Core 团队的技术合作及产出。Megatron-Core 是一个成熟且轻量化的大规模 LLM 训练框架,集成了训练大规模 LLM 的核心技术,比如多元化的模型并行支持、算子优化、通信优化、显存优化,以及低精度训练(如 FP8)等先进技术。
Megatron-Core 沿袭了 Megatron-LM 的优秀能力,并在代码质量、稳定性、功能完备度及测试覆盖范围等维度全面提升。尤为关键的是,该框架设计上更注重解耦和模块化,开发者在做二次开发或探索新模型架构时享有高度灵活性。因此我们选择了与 Megatron-Core 团队开展合作。

图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
接下来探讨 Megatron-Core 对 MoE 架构的主要支持特性。在并行化方面,Megatron-Core MoE 不仅支持专家并行,还支持 3D 并行,包括数据并行、张量并行、流水并行以及序列并行等。对于超大规模 MoE 模型,它能够灵活地将专家并行与其他并行策略有机结合。
在 token 分发机制上,Megatron-Core MoE 采用了 dropless MoE 操作,即不丢弃任何 token。在路由和负载均衡优化层面,它支持多种路由策略,如通用的 top-k,并在负载均衡算法上支持 Sinkhorn 算法、z-loss 以及 load balancing loss 等多种方案。
此外,为解决多个专家接收变长输入问题,Megatron-Core MoE 引入了 GroupedGMM 技术,并优化效率较低的操作,将其替换为优化的 CUDA kernel。
同时,在模型迁移与适配上,Megatron-Core MoE 提供了丰富的模型 checkpoint 转换功能,允许用户导入 HuggingFace 模型,并自由调整 TP(tensor parallelism)、PP(pipeline parallelism)和 EP(expert parallelism)等结构,随后利用 Megatron-Core 高效启动模型训练任务。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
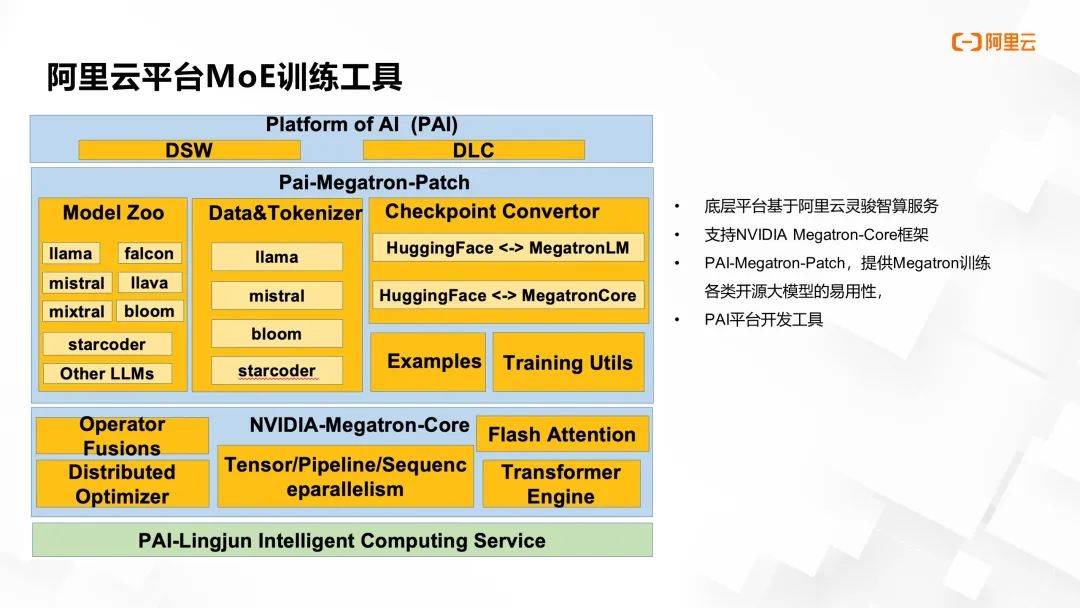
阿里云人工智能平台 PAI 团队基于 Megatron-Core,开发了一套简易、高效的大模型训练工具。依托阿里云灵骏计算服务,团队推出了 PAI-Megatron-Patch 工具库,可实现从十余种主流开源大模型的模型格式到 Megatron-LM 和 Megatron-Core 的无缝转换。用户通过 PAI DSW 和 DLC 等产品,能轻松启动 Megatron-LM 及 Megatron-Core 进行大规模稠密模型和 MoE 模型训练。

图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
针对开源大模型多采用 HuggingFace 格式,与 Megatron 训练框架存在一定差异的问题,PAI-Megatron-patch 的主要功能在于提供从 HuggingFace 模型到 Megatron 框架的权重转换服务。该转换实质上是对模型命名空间进行映射,涵盖了 layernorm 层、attention 层以及 MLP 层等核心组件的定义转换。PAI-Megatron-patch 内置简洁的权重转换脚本,使得用户能够便捷地执行模型格式转换操作,极大地简化了迁移流程。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
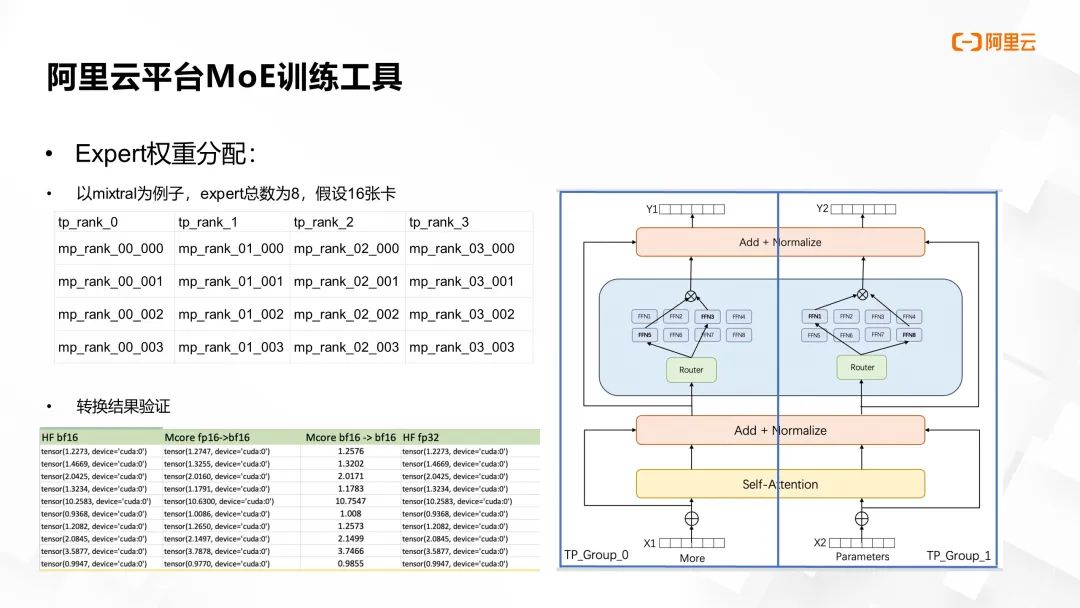
在进行 MoE 模型转换时,需确保转换后的文件能直接用于分布式训练,为此我们也做了大量验证工作。以 Mixtral 模型为例,在拥有 8 个专家和 16 张卡的场景下,采取 TP=4 和 EP=4 的切分策略。每个 TP 分区内的文件夹中包含四个文件,存储全部八个专家的 FFN 权重,即每个文件承载两位专家的 FFN 权重信息。
经过转换,模型在零样本(Zero-shot)损失精度方面的表现如途中下表所示,数据显示转换前后模型的精度差异非常微小,确保了模型转换的有效性和准确性。
我们的工作不仅关注模型的转换环节,同样严谨地验证了整个训练流程的稳健性。仍以 Mixtral 8x7B 模型为例,我们在三个训练阶段——从头预训练、基于 checkpoint 的续训及指令微调 (Finetune),均进行了细致测试。
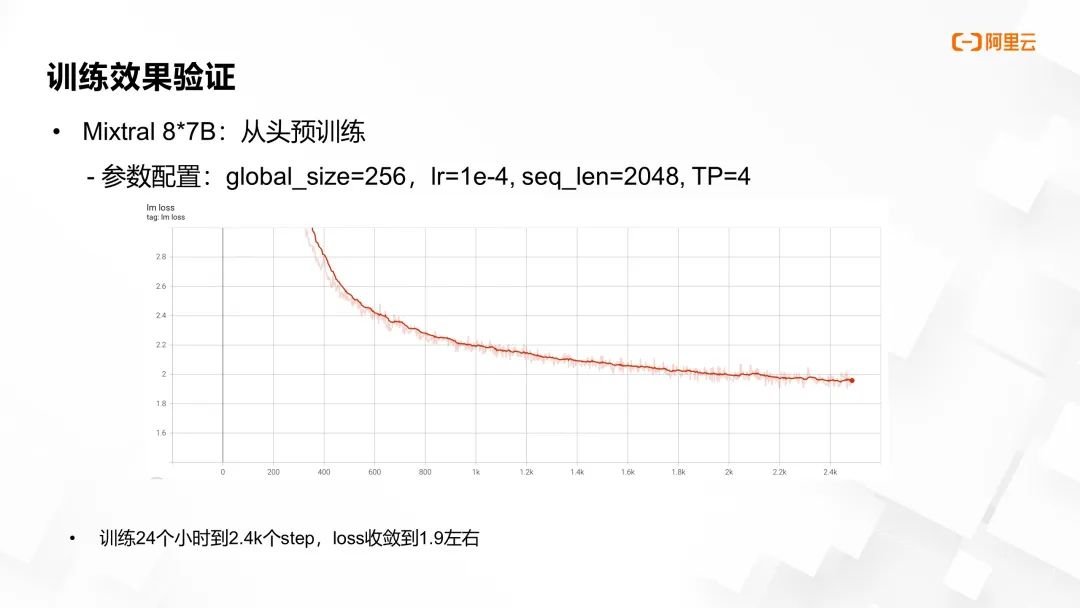
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
在从头预训练阶段,我们设定的参数包括:global_size=256,LR (learning rate) =1e-4,seq_len=2048,TP=4。经过 24 小时至 2.4K 个训练步骤后,损失 loss 成功收敛至约 1.9。
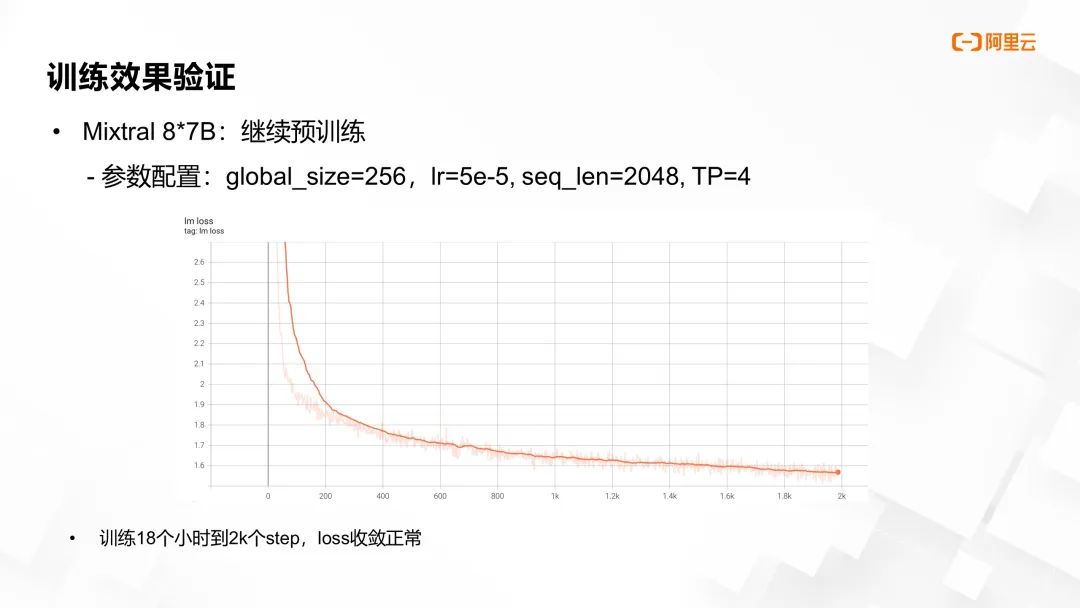
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
在继续预训练阶段,设定 global_size = 256,LR=5e-5,seq_len=2048,TP=4。在 18 小时达到 2,000 个训练步骤后,loss 亦表现出正常的收敛行为。
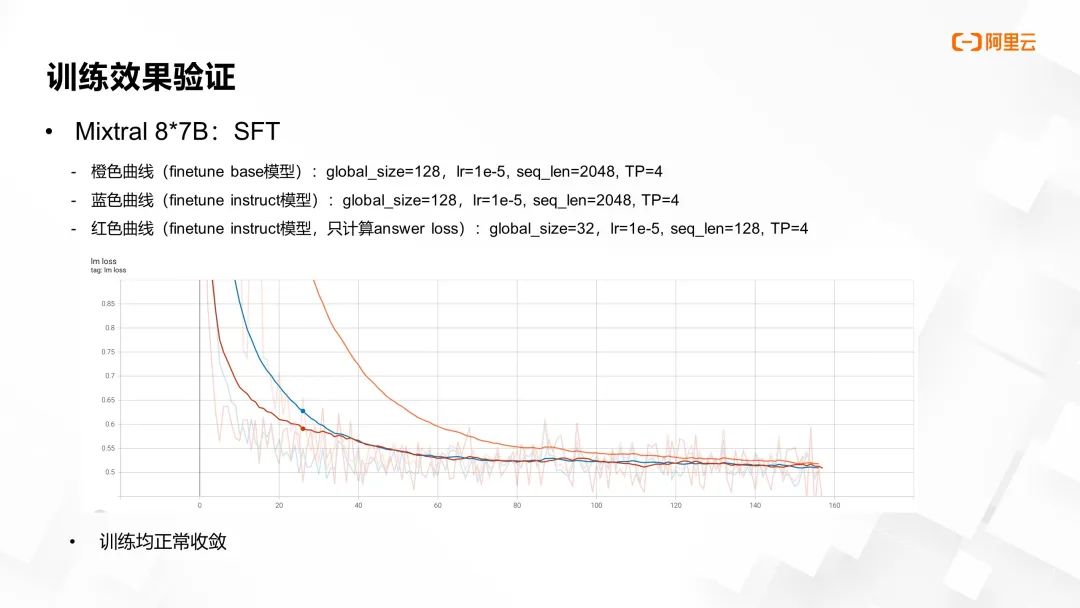
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
针对 Finetune 阶段,我们做了三组测试:
橙色曲线代表 finetune base 模型,设定 global_size=128,LR=1e-5,seq_len=2048,TP=4。
蓝色曲线代表 finetune instruct 模型,其参数配置与橙色曲线一致。
红色曲线代表仅计算 answer loss 的 finetune instruct 模型,其 global_size=32,LR 依旧为1e-5,seq_len 调整为 128,TP 依旧为 4。
所有模型在训练过程中均呈现出正常收敛态势,其中 finetune base 模型导致 loss 下降幅度较大,这一现象符合预期。

图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
为了进一步验证 Finetune 的效果,我们选取了一个代码生成任务作为评估基准。我们利用大约 80K 条公开的代码训练样本,测试集在 HumanEvol 平台上进行评估,此处的参数配置沿袭了上述 SFT 设定。经过 2,500 步训练后,模型在 HumanEvol 上的性能指标从最初的 45.73% 显著提升至 53.05%,有力证明了训练流程的合理性和有效性。此外,在速度对比方面,该方法优于同等资源条件下运行的 Megablocks。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
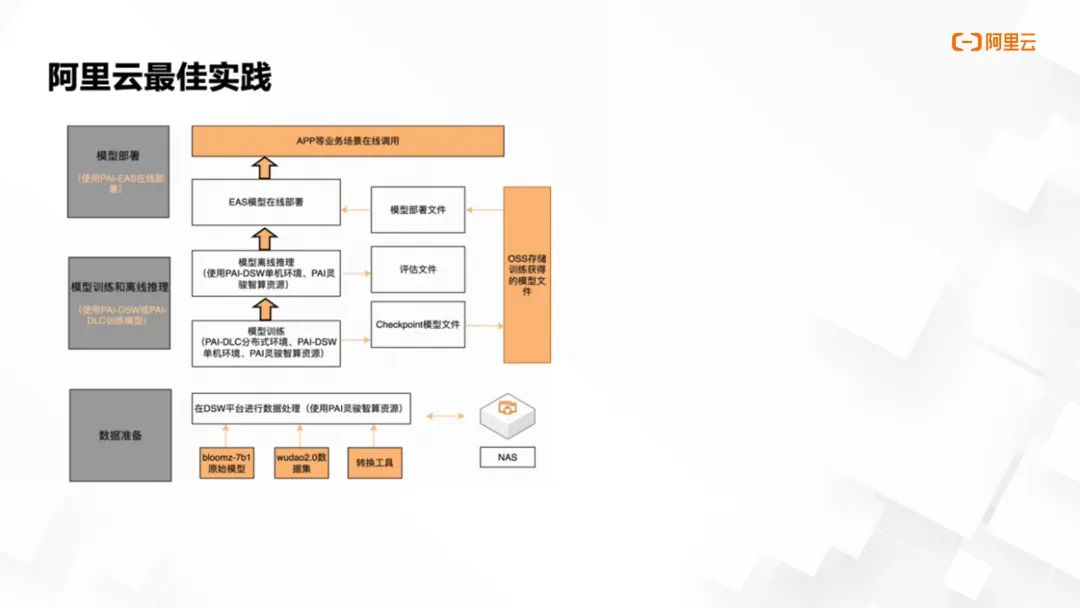
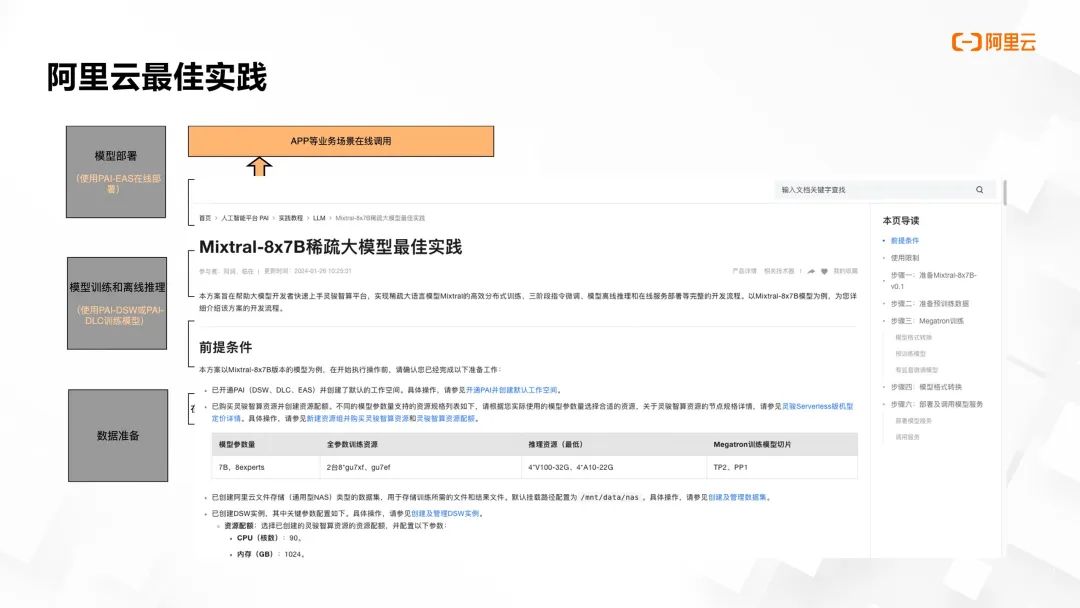
我们通过阿里云人工智能平台 PAI 提供了一套官方最佳实践指南,指南是对我们从数据处理、训练、推理、评估、直至在线服务部署的完整 AI 开发流程的测试成果总结:
https://mp.weixin.qq.com/s?__biz=Mzg4MzgxNDk2OA==&mid=2247492431&idx=1&sn=1e135a9e61ac65e88a156969d66ab5be&chksm=cf430418f8348d0e1ed97db178536e73d3ae7093e428c6e3e25bc0dc84a5754f49e3c20ce98e&cur_album_id=2918365856378880004&scene=189#wechat_redirect
该指南涵盖了从数据准备阶段起,指导用户如何从 OSS (对象存储服务)和 NAS (网络附加存储)读取原始数据,并在 PAI DSW 环境中执行高效的数据预处理操作。预处理后的数据能够方便地回存至 NAS 或 OSS,以为后续的模型训练做好准备。
这种方式的模型训练支持在 PAI DLC 进行大规模分布式训练,同时也兼容 DSW 提供的单机训练环境,确保用户可根据实际需求灵活选择训练方式。训练完成后,模型的 checkpoint 可以直接导出至 OSS 或 NAS 存储系统。
完成训练的 checkpoint 可先进行离线推理和模型性能评估。一旦推理和评估验证无误,开发者只需一键即可部署至 EAS 提供的模型在线服务。依托此服务的接口,开发者可以轻松构建各类 APP 和业务场景。
图片来源于 GTC 2024 大会 China AI Day 线上专场的演讲
《基于 NVIDIAMegatron-Core 的 MoE LLM 实现和训练优化》
这份最佳实践指南提供了详细的步骤说明,确保用户能清晰掌握每一步骤的操作方法。
未来,阿里云人工智能平台 PAI 团队将继续深化与 NVIDIA Megatron-Core 团队的合作,致力于在密集型和稀疏型模型的训练表现和效率上取得更大突破,为推进 AGI(通用人工智能)技术的发展贡献力量。我们热忱欢迎全球开发者共同参与到开源社区项目以及阿里云的建设之中,携手共进,共创智能未来。
审核编辑:刘清
-
在Ubuntu上使用Nvidia GPU训练模型2022-01-03 2552
-
探究超大Transformer语言模型的分布式训练框架2021-10-20 4227
-
用Riva和NeMo Megatron构建语音AI2022-03-31 2353
-
NVIDIA发布Riva语音AI和大型LLM软件2022-04-01 12110
-
NVIDIA对 NeMo Megatron 框架进行更新 将训练速度提高 30%2022-07-30 3546
-
KT利用NVIDIA AI平台训练大型语言模型2022-09-27 2510
-
NVIDIA AI平台为大型语言模型带来巨大收益2022-10-10 1799
-
DeepSpeed结合Megatron-LM训练GPT2模型笔记2023-06-19 5178
-
基于PyTorch的模型并行分布式训练Megatron解析2023-10-23 6052
-
NVIDIA Nemotron-4 340B模型帮助开发者生成合成训练数据2024-09-06 1715
-
如何训练自己的LLM模型2024-11-08 2387
-
解锁NVIDIA TensorRT-LLM的卓越性能2024-12-17 2257
-
Votee AI借助NVIDIA技术加速方言小语种LLM开发2025-08-20 1207
-
DeepSeek R1 MTP在TensorRT-LLM中的实现与优化2025-08-30 5018
-
借助NVIDIA Megatron-Core大模型训练框架提高显存使用效率2025-10-21 1659
全部0条评论

快来发表一下你的评论吧 !
