

FPGA实现算法硬件加速的方法与步骤
可编程逻辑
描述
当设计者试图从算法中获得最佳性能但软件方法已无计可施时,可以尝试通过硬件/软件重新划分来进行加速。FPGA易于实现软件模块和硬件模块的相互交换,且不必改变处理器或进行板级变动。本文阐述如何用FPGA来实现算法的硬件加速。
如果想从代码中获得最佳性能,方法包括优化算法、使用查找表而不是算法、将一切都转换为本地字长尺寸、使用注册变量、解开循环甚至可能采用 汇编代码。如果所有这些都不奏效,可以转向更快的处理器、采用一个不同的处理器架构,或将代码一分为二通过两个处理器并行处理。不过,如果有一种方法可将 那些对时间有严格要求的代码段转换为能够以5-100倍速度运行的函数调用,而且如果这一方法是一种可供软件开发之用的标准工具,这可信吗?现在,利用可编程逻辑作为硬件加速的基础可使这一切都变成现实。
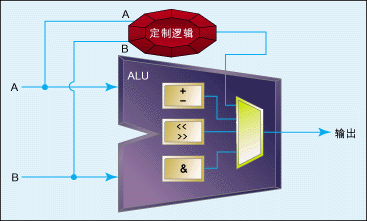
图1:带定制指令的可配置处理器架构。
低成本可编程逻辑在嵌入式系统中应用得越来越普遍,这为系统设计者提供了一个无需对处理器或架构进行大的改动即可获得更高性能的可选方案。可编程逻辑可将计算密集型功能转换为硬件加速功能。从软件的角度看,这只是简单地将一个函数调用做进一个定制的硬件模块中,但运行速度要比通过汇编语言优 化的相同代码或将算法转换为查找表要快得多。
1. 硬件加速
首先探讨一下什么是硬件加速,以及将算法作为定制指令来实现与采用硬件外围电路的区别。硬件加速是指利用硬件模块来替代软件算法以充分利用 硬件所固有的快速特性。从软件的角度看,与硬件加速模块接口就跟调用一个函数一样。唯一的区别在于此函数驻留在硬件中,对调用函数是透明的。
取决于算法的不同,执行时间最高可加快100倍。硬件在执行各种操作时要快得多,如执行复杂的数学功能、将数据从一个地方转移到另一个地方,以及多次执行同样的操纵。本文后面将讨论一些通常用软件完成的操作,经过硬件加速后这些操作可获得极大的性能提高。
如果在系统设计中采用FPGA,那么在设计周期的任何时候都可以添加定制的硬件。设计者可以立刻编写软件代码,并可在最终定稿之前在硬件部 分上运行。此外,还可以采取增量法来决定哪部分代码用硬件而不是软件来实现。FPGA供应商所提供的开发工具可实现硬件和软件之间的无缝切换。这些工具可 以为总线逻辑和中断逻辑生成HDL代码,并可根据系统配置定制软件库及include文件。
2. 带一些CISC的RISC
精简指令集计算(RISC)架构的目标之一即是保持指令简单化,以便让指令运行得足够快。这与复杂指令集计算(CISC)架构正好相反,后者一般不会同样快地执行指令,但每个指令可完成更多处理任务。这两种架构应用得都很普遍,而且各有所长。
如果能根据特定的应用将RISC的简单和快速特性与CISC强大的处理能力结合起来,岂不两全其美?其实这正是硬件加速所要做的。加入为某 种应用而定制的硬件加速模块可以提高处理能力,并减少代码复杂性和密度,因为硬件模块取代了软件模块。可以这么说,是用硬件来换取速度和简单性。
定制指令和硬件外围电路方式
有两种硬件加速模块实现方式。其一是定制指令,它几乎可在每一个可配置处理器中实现,这是采用可配置处理器的主要优点。如图1所示,定制指 令是作为算术逻辑单元(ALU)的扩展而添加的。处理器只知道定制指令就像其它指令一样,包括拥有自己的操作代码。至于C代码,宏可自动生成,从而使得使 用该定制指令跟调用函数一样。
如果定制指令需要几个时钟周期才能完成,而且要连续调用它,则可以流水线式定制指令来实现。这样可在每个时钟周期产生一个结果,不过开始时有些延迟。
硬件加速模块的另一种实现方式是硬件外围电路。在这一方式下,数据不是传递给软件函数,而是写入存储器映射的硬件外围电路中。计算是在 CPU之外完成的,因此在外围电路工作的同时CPU可以继续运行代码。其实代替软件算法的只是一个普通的硬件外围电路。与定制指令的另一个不同之处是硬件 外围电路可以访问系统中的其它外围电路或存储器,而无须CPU介入。
根据硬件需要做什么、怎么工作以及需要多长时间可以决定采用是定制指令还是硬件外围电路更合适。对于那些在几个周期内就可完成的操作,定制 指令一般更好些,因为它产生的开销要更少。对于外围电路,一般需要执行几个指令来写入控制寄存器、状态寄存器和数据寄存器,而且需要一个指令来读取结果。如果计算需要几个周期,实施外围电路比较好,因为它不会影响CPU流水线。或者,也可以实施前面所述的流水线式定制指令。
另一个区别是定制指令需要有限数目的操作数,并返回一个结果。根据处理器指令集架构的不同,操作数也各异。对某些操纵,这样可能显得很麻烦。此外,如果需要硬件从存储器或存储器中的其它外围电路读出和写入,则必须采用硬件外围电路,因为定制指令无法访问总线。
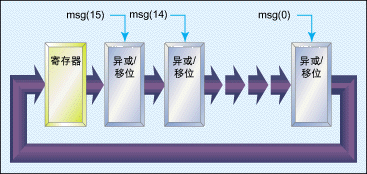
图2:16位CRC算法的硬件实现。(Optional)
3. 选择代码
当需要优化C语言代码以满足某些速度要求时,可能要运行一个代码仿制工具,或亲自检查该代码以便了解代码的哪个部分导致系统停滞。当然,这需要熟悉代码以便知道瓶颈在哪儿。
即便找出瓶颈所在,如何优化也是个挑战。有些方案采用本地字大小的变量、带预先计算值的查找表,以及通用软件算法优化。这些技巧可产生快几 倍的执行速度效果。另一种优化C算法的方法是用汇编语言编写。过去这种方法可获得很好的提高,但现今的编译器在优化C算法上已做得很好,因此这种性能的提 高是有限的。如果需要显著的性能提高,传统的软件算法优化技巧恐怕是不够的。
然而,利用硬件实施的算法比软件实施要强100倍,这不足为奇。那么,如何确定将哪些代码转为硬件实施呢?大可不必将整个软件模块转换为硬 件,而应选择那些在硬件中运行得特别快的操作,比如将数据从一处复制到另一处、大量的数学运算以及任何运行多次的循环。如果一个任务由几个数学运算组成, 还可以考虑在硬件中加速整个任务。有些时候,仅加速任务中的一个操作就可满足性能要求。
4. 实例:CRC算法的硬件加速
由于大量且重复的计算,循环冗余校验(CRC)算法或任何“校验和”算法都是硬件加速的不错选择。下面通过一个CRC算法的优化过程来探讨如何实现硬件加速。
首先,利用传统的软件技巧来优化算法,然后将其转向定制指令以加速算法。我们将讨论不同实现方法的性能比较和折衷。
CRC算法可用来校验数据在传输过程中是否被破坏。这些算法很流行,因为它们具有很高的检错率,而且不会对数据吞吐量造成太大影响,因为 CRC校验位被添加进数据信息中。但是,CRC算法比一些简单的校验和算法有更大的计算量要求。尽管如此,检错率的提高使得这种算法值得去实施。
一般说来,发送端对要被发送的消息执行CRC算法,并将CRC结果添加进该消息中。消息的接收端对包括CRC结果在内的消息执行同样的CRC操作。如果接收端的结果与发送端的不同,这说明数据被破坏了。
CRC算法是一种密集的数学运算,涉及到二元模数除法(modulo-2 division),即数据消息被16或32位多项式(取决于所用CRC标准)除所得的余数。这种操作一般通过异或和移位的迭代过程来实现,当采用16位 多项式时,这相当于每数据字节要执行数百条指令。如果发送数百个字节,计算量就会高达数万条指令。因此,任何优化都会大幅提高吞吐量。
代码列表1中的CRC函数有两个自变量(消息指针和消息中的字节数),它可返回所计算的CRC值(余数)。尽管该函数的自变量是一些字节,但计算要逐位来执行。该算法并不高效,因为所有操作(与、移位、异或和循环控制)都必须逐位地执行。
列表1:逐位执行的CRC算法C代码。
/*
* The width of the CRC calculation and result.
* Modify the typedef for a 16 or 32-bit CRC standard.
*/
typedef unsigned char crc;
#define WIDTH (8 * sizeof(crc))
#define TOPBIT (1 << (WIDTH - 1))
crc crcSlow(unsigned char const message[], int nBytes)
{
crc remainder = 0;
/*
* Perform modulo-2 division, a byte at a time.
*/
for (int byte = 0; byte < nBytes; ++byte)
{
/*
* Bring the next byte into the remainder.
*/
remainder ^= (message[byte] << (WIDTH - 8));
/*
* Perform modulo-2 division, a bit at a time.
*/
for (unsigned char bit = 8; bit > 0; bit--)
{
/*
* Try to divide the current data bit.
*/
if (remainder & TOPBIT)
{
remainder = (remainder << 1) ^ POLYNOMIAL;
}
else
{
remainder = (remainder << 1);
}
}
}
/*
* The final remainder is the CRC result.
*/
return (remainder);
}
4.1 传统的软件优化
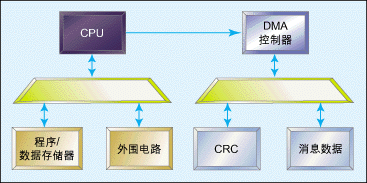
图3:带CRC外围电路和DMA的系统模块示意图。
让我们看一下如何利用传统的软件技巧来优化CRC算法。因为CRC操作中的一个操作数,即多项式(除数)是常数,字节宽CRC操作的所有可能结果都可以预先计算并存储在一个查找表中。这样,通过一个读查找表动作就可让操作按逐个字节执行下去。
采用这一算法时,需要将这些预先计算好的值存储在存储器中。选择ROM或RAM都可以,只要在启动CRC计算之前将存储器初始化就行。查找表有256个字节,表中每个字节位置包含一个CRC结果,共有256种可能的8位消息(与多项式大小无关)。
列表2示出了采用查找表方法的C代码,包括生成查找表crcInit()中数值的代码。
crc crcTable[256];
void crcInit(void)
{
crc remainder;
/*
* Compute the remainder of each possible dividend.
*/
for (int dividend = 0; dividend < 256; ++dividend)
{
/*
* Start with the dividend followed by zeros.
*/
remainder = dividend << (WIDTH - 8);
/*
* Perform modulo-2 division, a bit at a time.
*/
for (unsigned char bit = 8; bit > 0; bit--)
{
/*
* Try to divide the current data bit.
*/
if (remainder & TOPBIT)
{
remainder = (remainder << 1) ^ POLYNOMIAL;
}
else
{
remainder = (remainder << 1);
}
}
/*
* Store the result into the table.
*/
crcTable[dividend] = remainder;
}
} /* crcInit() */
crc crcFast(unsigned char const message[], int nBytes)
{
unsigned char data;
crc remainder = 0;
/*
* Divide the message by the polynomial, a byte at a time.
*/
for (int byte = 0; byte < nBytes; ++byte)
{
data = message[byte] ^ (remainder >> (WIDTH - 8));
remainder = crcTable[data] ^ (remainder << 8);
}
/*
* The final remainder is the CRC.
*/
return (remainder);
} /* crcFast() */
整个计算减少为一个循环,每字节(不是每位)有两个异或、两个移位操作和两个装载指令。基本上,这里是用查找表的存储空间来换取速度。该方 法比逐位计算的方法要快9.9倍,这一提高对某些应用已经足够。如果需要更高的性能,可以尝试编写汇编代码或增加查找表容量以挤出更多性能来。但是,如果 需要20、50甚至500倍的性能提高,就要考虑采用硬件加速来实现该算法了。
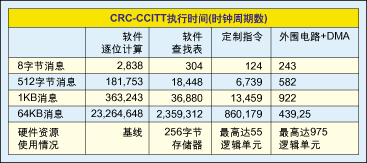
表1:各种规模的数据模块下CRC算法测试比较结果。
4.2 采用定制指令方法
CRC算法由连续的异或和移位操作构成,用很少的逻辑即可在硬件中简单实现。由于这一硬件模块仅需几个周期来计算CRC,采用定制指令来实 现CRC计算要比采用外围电路更好。此外,无须涉及系统中任何其它外围电路或存储器。仅需要一个微处理器来支持定制指令即可,一般是指可配置微处理器。
当在硬件中实现时,算法应该每次执行16或32位计算,这取决于所采用的CRC标准。如果采用CRC-CCITT标准(16位多项式),最 好每次执行16位计算。如果使用8位微处理器,效率可能不太高,因为装载操作数值及返回CRC值需要额外的周期。图2示出了用硬件实现16位CRC算法的 内核。
信号msg(15..0)每次被移入异或/移位硬件一位。列表3示出了在64KB数据模块上计算CRC的一些C代码例子。该实例是针对Nios嵌入式处理器。
列表3:采用定制指令的CRC计算C代码。
unsigned short crcCompute(unsigned short *data_block, unsigned int nWords)
{
unsigned short* pointer;
unsigned short word;
/*
* initialize crc reg to 0xFFFF
*/
word = nm_crc (0xFFFF, 1); /* nm_crc() is the CRC custom instruction */
/*
* calculate CRC on block of data
* nm_crc() is the CRC custom instruction
*
*/
for (pointer = data_block; pointer < (data_block + nWords); pointer ++)
word = nm_crc(*pointer, 0) return (word);
}
int main(void)
{
#define data_block_begin (na_onchip_memory)
#define data_block_end (na_onchip_memory + 0xffff)
unsigned short crc_result;
unsigned int data_block_length = (unsigned short *)data_block_end -
(unsigned short *)data_block_begin + 1;
crc_result = crcCompute((unsigned short *)data_block_begin, data_block_length);
}
采用定制指令时,用于计算CRC值的代码是一个函数调用,或宏。当针对Nios处理器实现定制指令时,系统构建工具会生成一个宏。在本例中为nm_crc(),可用它来调用定制指令。
在启动CRC计算之前,定制指令内的CRC寄存器需要先初始化。装载初始值是CRC标准的一部分,而且每种CRC标准都不一样。接着,循环将为数据模块中的每16位数据调用一次CRC定制指令。这种定制指令实现方式要比逐位实现的方法快27倍。
4.3 CRC外围电路方法
如果将CRC算法作为硬件外围电路来实现,并利用DMA将数据从存储器转移到外围电路,这样还可以进一步提高速度。这种方法将省去处理器为 每次计算而装载数据所需要的额外周期。DMA可在此外围电路完成前一次CRC计算的时钟周期内提供新的数据。图3示出了利用DMA、CRC外围电路来实现 加速的系统模块示意图。
在64KB数据模块上,利用带DMA的定制外围电路可获得比逐位计算的纯软件算法快500倍的性能。要知道,随着数据模块规模的增加,使用 DMA所获得的性能也随之提高。这是因为设置DMA仅需很少的开销,设置之后DMA运行得特别快,因为每个周期它都可以传递数据。因此,若只有少数字节的 数据,用DMA并不划算。
这里所讨论的所有采用CRC-CCITT标准(16位多项式)的算法都是在Altera Stratix FPGA的Nios处理器上实现的。表1示出了各种数据长度的测试比较结果,以及大致的硬件使用情况(FPGA中的存储器或逻辑单元)。
可以看出,算法所用的硬件越多,算法速度越快。这是用硬件资源来换取速度。
5. FPGA的优点
当采用基于FPGA的嵌入式系统时,在设计周期之初不必为每个模块做出用硬件还是软件的选择。如果在设计中间阶段需要一些额外的性能,则可 以利用FPGA中现有的硬件资源来加速软件代码中的瓶颈部分。由于FPGA中的逻辑单元是可编程的,可针对特定的应用而定制硬件。因此,仅使用所需要的硬 件即可,而不必做出任何板级变动(前提是FPGA中的逻辑单元足够用)。设计者不必转换到另一个新的处理器或者编写汇编代码,就可做到这一点。
使用带可配置处理器的FPGA可获得设计灵活性。设计者可以选择如何实现软件代码中的每个模块,如用定制指令,或硬件外围电路。此外,还可以通过添加定制的硬件而获取比现成微处理器更好的性能。
另一点要知道的是,FPGA有充裕的资源,可配置处理器系统可以充分利用这一资源。
算法可以用软件,也可用硬件实现。出于简便和成本考虑,一般利用软件来实现大部分操作,除非需要更高的速度以满足性能指标。软件可以优化,但有时是不够的。如果需要更高的速度,利用硬件来加速算法是一个不错的选择。
FPGA使软件模块和硬件模块的相互交换更加简便,不必改变处理器或进行板级变动。设计者可以在速度、硬件逻辑、存储器、代码大小和成本之间做出折衷。利用FPGA可以设计定制的嵌入式系统,以增加新的功能特性及优化性能。
审核编辑:黄飞
-
针对LSTM实现硬件加速的稀疏化案例分析2020-11-29 4587
-
硬件加速模块的时钟设计2025-10-23 297
-
常用硬件加速的方法2025-10-29 295
-
【PYNQ-Z2申请】图像目标识别FPGA硬件加速2019-01-09 5325
-
为什么FPGA协处理器可以实现算法加速?2021-04-13 2733
-
GNN(图神经网络)硬件加速的FPGA实战解决方案2021-07-07 4781
-
基于FPGA Nios-Ⅱ的矩阵运算硬件加速器设计2011-12-06 1687
-
Bitfusion支持通过云访问基于赛灵思All Programmable器件的FPGA硬件加速功能2017-02-08 556
-
硬件加速边缘检测优化处理方案2017-11-15 2830
-
MD5算法硬件加速模型2018-01-12 1104
-
基于Xilinx FPGA的Memcached硬件加速器的介绍2018-11-27 4767
-
LSTM的硬件加速方式2019-08-24 3669
-
如何确定一个硬件加速应用2022-08-02 1348
-
基于FPGA的Poseidon哈希算法硬件加速方案2022-08-19 3830
-
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片2026-02-12 825
全部0条评论

快来发表一下你的评论吧 !
