

RDMA技术在Apache Spark中的应用
电子说
描述
背景介绍
在当今数据驱动的时代,Apache Spark已经成为了处理大规模数据集的首选框架。作为一个开源的分布式计算系统,Spark因其高效的大数据处理能力而在各行各业中广受欢迎。无论是金融服务、电信、零售、医疗保健还是物联网,Spark的应用几乎遍及所有需要处理海量数据和复杂计算的领域。它的快速、易用和通用性,使得数据科学家和工程师能够轻松实现数据挖掘、数据分析、实时处理等任务。
然而,在Spark的灿烂光环背后,一个核心的技术挑战一直困扰着用户和开发者 -- Shuffle过程中的网络瓶颈。
在大规模数据处理时,Shuffle是Spark中不可或缺的一环,它涉及大量数据在不同节点间的交换,是整个数据处理过程中最耗时的部分之一。随着数据量的不断增长,网络传输成为了显著的性能瓶颈,这不仅影响了处理速度,还影响了整体的资源利用效率和系统的可扩展性。
Apache Spark Shuffle
在Spark中,Shuffle是数据处理过程的一个关键阶段,发生在数据需要redistribute的情况。

图一: shuffle中的数据流向
每个左上角的彩色条带代表Spark在Shuffle前计算得到的一个数据块。假设这些数据块分别存放在集群的不同的节点上。此刻,假设我们希望“根据颜色将这些数据块进行分组”,那么Shuffle过程就会启动:
首先,每台机器上的数据块会按颜色进行本地第一次聚合(从左上角的彩色条带变为中上部的彩色条带)。这些经过聚合的数据就成了Shuffle的中间数据。接下来,Spark会将中间数据以文件的形式暂存到各自节点的硬盘上(从中上部的条带变为"File")。这一部分称为Shuffle的Map阶段。
在这之后,所有相同颜色的数据块会通过网络第二次聚合到一个指定的节点上(从中上部的彩色条带移动至中下部)。这一阶段称为Shuffle的Reduce阶段。
至此,Spark完成了“根据颜色将数据块进行分组”这个要求,Shuffle过程结束。
在实际的操作中,Shuffle是一个非常耗时的过程,因为它涉及到大量的数据在网络中的传输。如果Shuffle管理得不好,它会成为Spark作业性能瓶颈的主要原因。
解决Spark Shuffle网络传输性能瓶颈的关键
为了克服这一挑战,近年来,远程直接内存访问(RDMA)技术逐渐进入了专家们的视野。RDMA允许内存数据直接从一个系统传输到另一个系统,而无需通过操作系统的干预,这显著减少了数据传输过程中的延迟和CPU的使用率。在高性能计算和大规模数据中心环境中,RDMA已经显示出了其强大的网络加速能力。
将RDMA技术应用于Apache Spark,尤其是在Shuffle过程中,可以大幅度减轻网络瓶颈带来的影响。通过利用RDMA的高带宽和低延迟特性,Spark的数据处理性能有望得到显著的提升。
RDMA相比传统网络技术的优势
Kernel Bypass:
传统的网络通信需要操作系统内核参与数据的发送和接收,这会增加额外的延迟。每个数据包在传输过程中都需要经过操作系统的网络协议栈,这个过程中涉及多次上下文切换和数据拷贝。如下图所示。
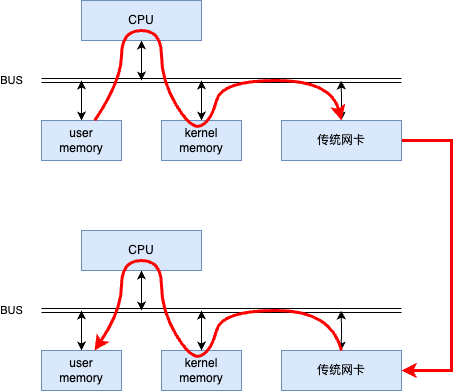
图二: 传统网络通信中数据的发送和接收
RDMA技术允许网络设备直接访问应用程序内存空间,实现了内核旁路(kernel bypass)。这意味着数据可以直接从发送方的内存传输到接收方的内存,无需CPU介入,减少了传输过程中的延迟。如下图所示。
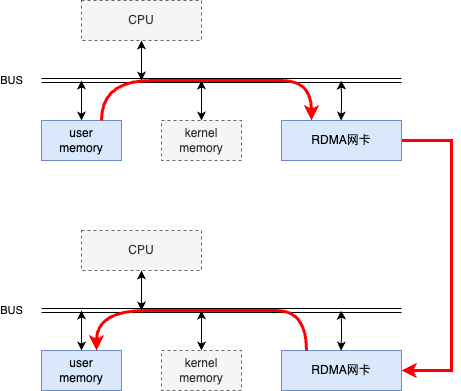
图三: RDMA网络通信中数据的发送和接收
对于Spark的Shuffle过程,这意味着数据块可以更快地在节点间传输,因为它们不再需要在用户空间和内核空间之间进行多次拷贝。
CPU Offloading:
在传统的网络通信中,CPU需要处理包括TCP协议栈在内的大量网络协议处理任务,这不仅消耗了大量的计算资源,而且还增加了通信的延迟。
RDMA通过其协议和硬件的设计,允许网络设备处理大部分数据传输的细节,从而释放CPU资源。这意味着CPU可以专注于执行计算任务,而不是网络数据的传输,从而提高了整体的计算效率。
在Spark中,这样可以确保CPU更多地用于执行Map和Reduce阶段之外的实际计算工作,而不是在网络通信上。
RDMA技术在Apache Spark中的应用
在Spark中集成RDMA
Spark允许将外部实现的ShuffleManager插入到其架构中。下图中通过实现Spark的接口,可以创建专有的ShuffleManager从而将RDMA技术引入到Shuffle过程中。
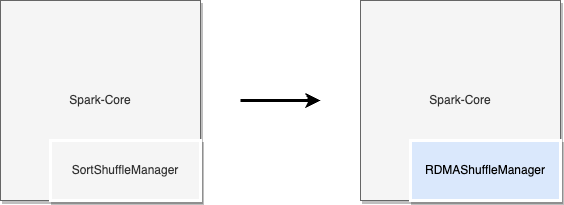
图四: 通过Spark接口将RDMA集成到Apache Spark
RDMA加速的实现
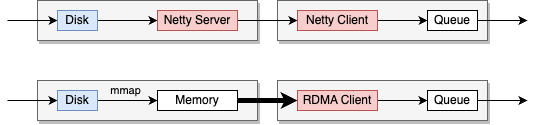
图五: RDMA在Spark Shuffle过程中的位置
上图中展示了RDMA引入Apache Spark前后的Shuffle过程中的数据传输方式。
在上半部分,展示了Apache Spark使用Netty作为网络传输层的传统方法。数据从磁盘读取,通过Netty服务器传输,然后由Netty客户端接收,并放入队列中供进一步处理。
在下半部分,展示了使用RDMA作为网络传输层的方法。在这种方式中, Netty客户端被RDMA客户端替换,而由于RDMA单边操作的特性,不再需要服务器端,Disk上的数据通过MMAP加载进入用户空间的内存,之后Client使用RDMA直接在网络上进行内存访问操作,避免了数据在操作系统内存和网络接口之间的多次复制,从而提高了数据传输速度,并减少了延迟和CPU负载。
性能数据和比较分析
为了验证我们的实现,我们在多种数据集和查询负载下进行了性能测试。测试结果如下图所示
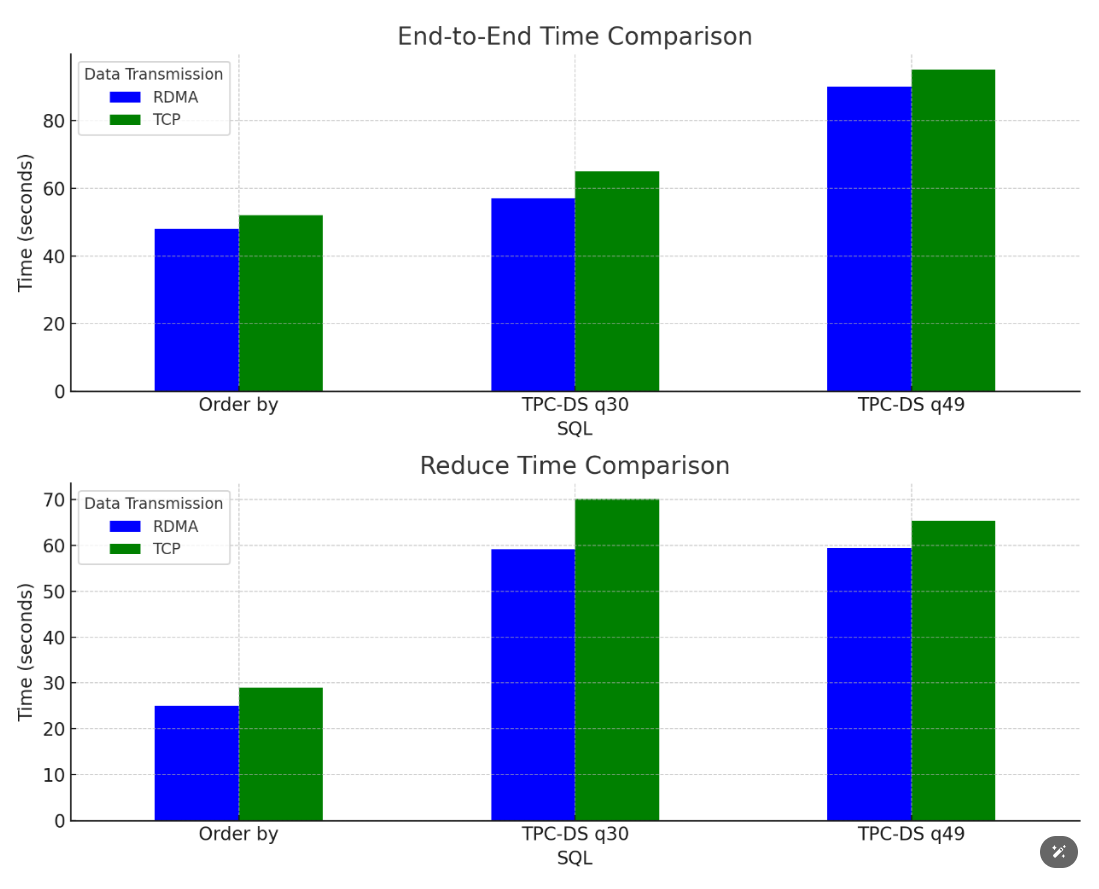
图六:SQL的性能提升效果
这些测试结果表明,在多种场景下使用RDMA均能实现大约10%左右的性能提升。然而,值得注意的是,具体的加速效果会受到业务逻辑和数据处理工作负载的影响,因此我们推荐在实施RDMA解决方案前,对特定的应用场景进行详细评估。
应用场景建议
通过RDMA和Spark的特性分析,结合测试,可得到针对RDMA技术在Spark中适用和不适用的场景的优化建议:
适合RDMA的场景
大数据量的复杂SQL操作:在处理包含复杂操作(如Order by)的大数据量SQL查询时,RDMA技术可显著提升效率。
大量小数据分区:当分区数量较多,且每个分区处理的数据量较小,传送的数据包较多时,RDMA的加速效果尤为显著。
不适合RDMA的场景
数据量大幅减少的操作:如SQL中的Group by聚合操作等,这些减少数据量的计算可能不会从RDMA中获得显著加速。
基于HDD的磁盘集群:在使用HDD磁盘的集群中,由于读写速度较慢,磁盘I/O所占的时间较长,这可能限制RDMA技术的加速潜力。
数据高度本地化: 如果数据本地化良好,则意味着网络传输占比较少,这种计算难以通过RDMA获得加速。
总结
尽管面临一些挑战,RDMA技术在Apache Spark中的应用仍然有着显著的优势,体现在以下几个方面:
提高数据传输效率:RDMA通过提供低延迟和高带宽的数据传输,显著加快了Spark中的数据处理速度。这是因为RDMA直接在网络设备和应用程序内存之间传输数据,减少了CPU的干预,从而降低了数据传输过程中的延迟。
减少CPU占用:RDMA的Kernel Bypass特性允许数据绕过内核直接从内存传输,减少了CPU在数据传输过程中的工作量。这不仅提高了CPU的有效利用率,还留出了更多资源用于Spark的计算任务。
改善端到端处理时间:在对比测试中,使用RDMA相比传统的TCP传输方式,在端到端的数据处理时间上有显著的降低。这意味着整体的数据处理流程更加高效,能够在更短的时间内完成相同的计算任务。
优化Shuffle阶段的性能:在Spark中,Shuffle阶段是一个关键的、对性能影响较大的阶段。RDMA通过减少数据传输和处理时间,有效地优化了Shuffle阶段的性能,从而提升了整个数据处理流程的效率。
增强大规模数据处理能力:对于处理大规模数据集的场景,RDMA提供的高效数据传输和低延迟特性尤为重要。它使得Spark能够更加高效地处理大数据量,提高了大规模数据处理的可扩展性和效率。
总而言之,RDMA技术在Apache Spark中的应用显著提升了数据处理的效率和性能。在未来,相信随着数据量的持续增长和计算需求的日益复杂化,RDMA技术在Apache Spark以及更广泛的大数据处理和高性能计算领域的应用将越来越广。
审核编辑 黄宇
-
Spark入门及安装与配置2018-07-31 3041
-
基于Spark 2.1版本的Apache Spark内存管理2019-04-26 1994
-
基于RDMA技术的Spark Shuffle性能提升2019-10-28 2483
-
基于Apache Spark 的下一波智能应用2016-12-28 1051
-
如何使用Apache Spark 2.02017-09-28 812
-
Apache Spark 1.6预览版新特性展示2017-10-13 711
-
Apache Spark的分布式深度学习框架BigDL的概述2018-10-30 4333
-
Apache Spark上的分布式机器学习的介绍2018-11-05 3865
-
Apache Spark 3.2有哪些新特性2021-11-17 2772
-
一文详细了解APACHE SPARK开源框架2022-04-19 3283
-
利用Apache Spark和RAPIDS Apache加速Spark实践2022-04-26 2849
-
Apache Spark 靠什么帮助获得市场头把交椅?2022-08-01 797
-
NVIDIA ConnectX智能网卡驱动RDMA通讯技术在分布式存储的应用2022-11-03 2215
-
NVIDIA加速的Apache Spark助力企业节省大量成本2025-03-25 1435
-
使用NVIDIA GPU加速Apache Spark中Parquet数据扫描2025-07-23 1373
全部0条评论

快来发表一下你的评论吧 !
