

超算网络中的主流拓扑架构
通信网络
描述
高性能计算场景的流量关注静态时延的同时需要支持超大规模组网。然而传统的 CLOS 架构作为主流网络架构,主要关注通用性,牺牲了时延和性价比。业界针对该问题开展了多样的架构研究和新拓扑的设计,Fat-Tree、Dragonfly、Torus是几种常见的网络拓扑,Fat-Tree架构实现无阻塞转发,Dragonfly架构网络直径小,Torus 具有较高的扩展性和性价比。
Fat-Tree胖树架构
传统的树形网络拓扑中,带宽是逐层收敛的,树根处的网络带宽要远小于各个叶子处所有带宽的总和。而Fat-Tree则更像是真实的树,越到树根,枝干越粗,即:从叶子到树根,网络带宽不收敛,这是Fat-Tree能够支撑无阻塞网络的基础。Fat-Tree是使用最广泛的拓扑之一,它是各种应用程序的一个很好的选择,因为它提供低延迟并支持各种吞吐量选项——从非阻塞连接到超额订阅,这种拓扑类型最大限度地提高了各种流量模式的数据吞吐量。
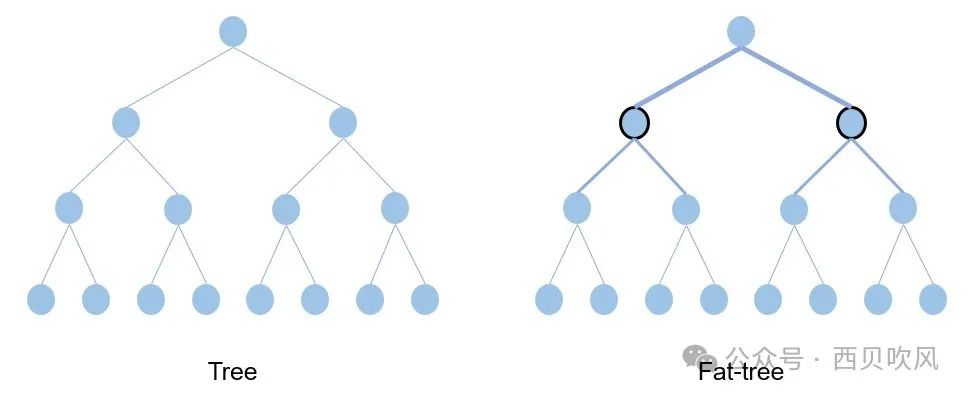
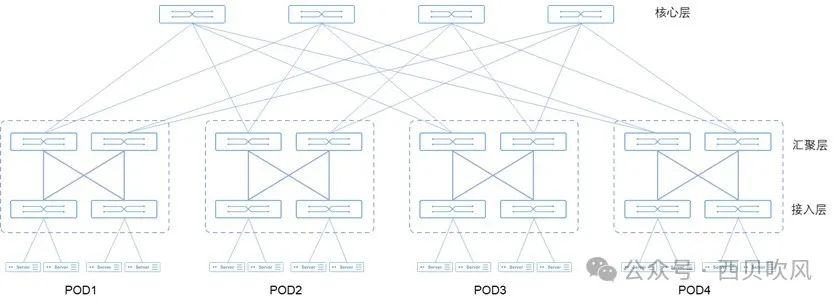
Fat-Tree架构采用1:1无收敛设计,Fat-Tree架构中交换机上联端口与下联端口带宽、数量保持一致,同时交换机要采用无阻塞转发的数据中心级交换机。Fat-Tree架构可以通过扩展网络层次提升接入的GPU节点数量。
Fat-Tree架构的本质是无带宽收敛,因此,云数据中心的Spine-leaf组网在无收敛的情况下,也可以认为是遵从了Fat-Tree架构理念。
如果交换机的端口数量为n,则:两层Fat-Tree架构能够接入n²/2张GPU卡,以40端口的InfiniBand交换机为例,能够接入的GPU数量最多可达800个。三层Fat-Tree架构能够接入n(n/2)*(n/2)张GPU卡,以40端口的InfiniBand交换机为例,能够接入的GPU数量最多可达16000个。
但是,Fat-Tree架构也存在明显的缺陷:
网络中交换机与服务器的比值较大,需要大量的交换机和链路,因此,在大规模情况下成本相对较高。构建Fat-Tree需要的交换机数量为5M/n(其中,M是服务器的数量,n是交换机的端口数量),当交换机的端口数量n较小时,连接Fat-Tree需要的交换机数量庞大,从而增加了布线和配置的复杂性;
拓扑结构的特点决定了网络不能很好的支持One-to-All及All-to-All网络通信模式,不利于部署 MapReduce、Dryad等高性能分布式应用;
扩展规模在理论上受限于核心层交换机的端口数目。
Fat-Tree架构的本质是CLOS架构网络,主要关注通用性和无收敛,牺牲了时延和性价比。在构建大规模集群网络时需要增加网络层数,需要更多的互联光纤和交换机,带来成本的增加,同时随着集群规模增大,网络跳数增加,导致通信时延增加,也可能会无法满足业务低时延需求。
Dragonfly架构
Dragonfly是当前应用最广泛的直连拓扑网络架构,它由John Kim等人在2008年的论文Technology-Driven, Highly-Scalable Dragonfly Topology中提出,它的特点是网络直径小、成本较低,已经在高性能计算网络中被广泛应用,也适用于多元化算力的数据中心网络。
Dragonfly网络如下图所示:
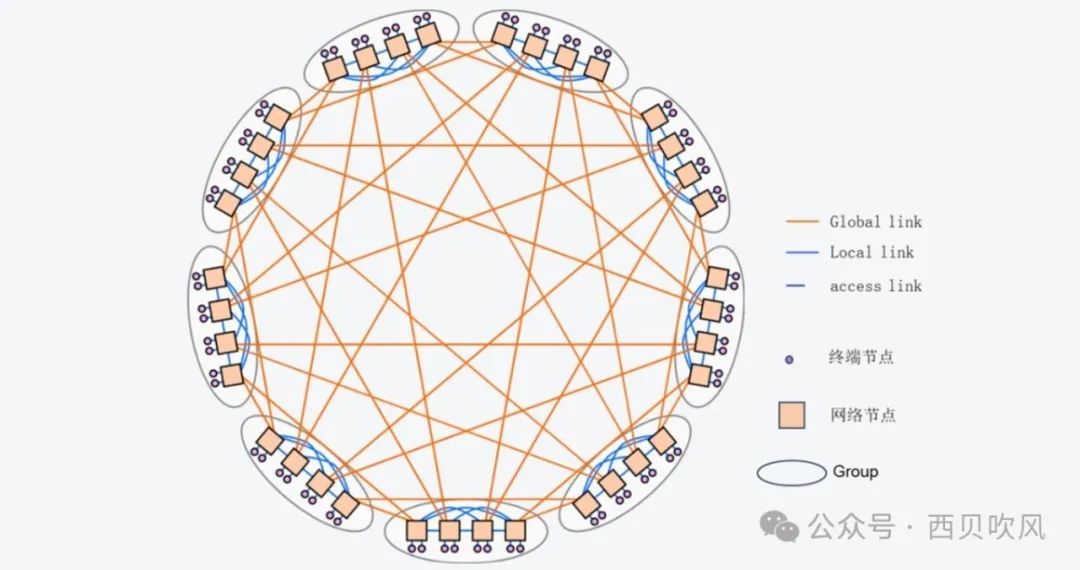
Dragonfly的拓扑结构分为三层:Switch层、Group层、System层。
Switch层:包括一个交换机及其相连的P个计算节点;
Group层:包含a个Switch层,这a个Switch层的a个交换机是全连接(All-to-all)的,换言之,每个交换机都有a-1条链路连接分别连接到其他的a-1台交换机;
System层:包含g个Group层,这g个Group层也是全连接的。
对于单个Switch交换机,它有p个端口连接到了计算节点,a-1个端口连接到Group内其他交换机,h个端口连接到其他Group的交换机。因此,我们可以计算得到网络中的如下属性:
每个交换机的端口数为k=p+(a-1)+h
Group的数量为g=ah+1
网络中一共有N=ap(ah+1) 个计算节点
如果我们把一个Group内的交换机都合成一个,将它们视为一个交换机,那么这个交换机的端口数为k‘=a(p+h)。
不难发现,在确定了 p、a、h、g四个参数之后,我们就可以确定一个Dragonfly的拓扑,因此,一个Dragonfly的拓扑可以用dfly(p,a,h,g) 来表示,一种推荐的较为平衡的配置是方法是:a=2p=2h。
Dragonfly的路由算法主要有以下几种:
最小路由算法(Minimal Routing):由于拓扑的性质,Minimal Routing中最多只会有1条Global Link和2条Local Link,也就是说最多3跳即可到达。在任由两个Group之间只有一条直连连接时(即g=ah+1时),最短路径只有一条。
非最短路径的路由算法(Non-Minimal Routing):有的地方叫Valiant algorithm,简写为VAL,还有的地方叫Valiant Load-balanced routing,简写为VLB。随机选择一个Group,先发到这个Group然后再发到目的地。由于拓扑的性质,VAL最多会经过2条Global Link和3条Local Link,最多5跳即可到达。
自适应路由(Adaptive Routing):当一个数据包到达交换机时,交换机根据网络负载信息在最短路径路由和非最短路径路由路径之间进行动态选路,优先采用最短路径转发,当最短路径拥塞时,通过非最短路径转发。因为要获取到全局网络状态信息比较困难,除了UGAL(全局自适应负载均衡路由),还提出了一系列变种自适应路由算法,如UGAL-L,UGAL-G等。
上述几种路由,由于自适应路由能够根据网络链路状态动态调整流量转发路径,因此会有更好的性能表现。
Dragonfly为各种应用程序(或通信模式)提供了良好的性能,与其他拓扑相比,它通过直连模式,缩短网络路径,减少中间节点数量。64端口交换机支持组网规模27万节点,端到端交换机转发跳数减至3跳。
Dragonfly拓扑在性能和性价比方面有显著的优势。然而,这种优势的实现需要依赖于有效的拥塞控制和自适应路由策略。Dragonfly网络在扩展性方面存在问题,每次需要增加网络容量时,都必须对Dragonfly网络进行重新布线,这增加了网络的复杂性和管理难度。
Torus架构
随着模型参数的增加和训练数据的增加,单台机器算力无法满足,存储无法满足,所以要分布式机器学习,集合通信则是分布式机器学习的底层支撑,集合通信的难点在于需要在一定的网络互联结构的约束下进行高效的通信,需要在效率与成本、带宽与时延、客户要求与质量、创新与产品化等之间进行合理取舍。
Torus网络架构是一种完全对称的拓扑结构,具有很多优良特性,如网络直径小、结构简单、路径多以及可扩展性好等特点,非常适合集合通信使用。索尼公司提出2D-Torus算法,其主要思想就是组内satter-reduce->组间all-reduce->组内all-gather。 IBM提出了3D-Torus算法。
我们用k-ary n-cube来表示。k是排列的边的长度,n是排列的维度。
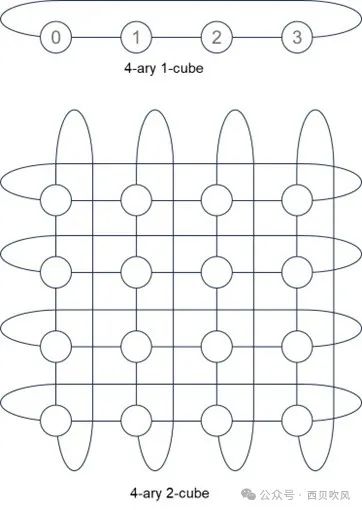
3-ary 3-cube拓扑如下:
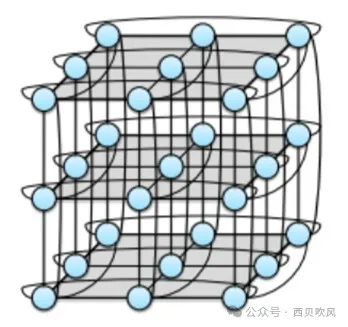
以2D-Torus拓扑为例,可以将网络结构表达成如下的Torus结构。
横向:每台服务器X个GPU节点,每GPU节点通过私有协议网络互联(如NVLINK);
纵向:每台服务器通过至少2张RDMA网卡NIC 0 /NIC 1通过交换机互联。
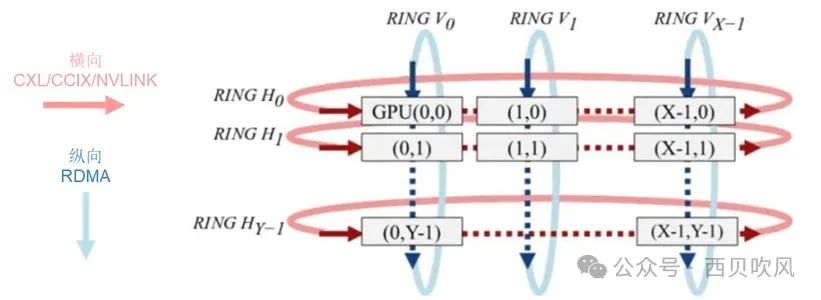
第1步,横向,先进行主机内Ring Scatter Reduce,将主机内8张卡上的梯度进行拆分与规约,这样经过迭代,到最后每个GPU将有一个完整的同维梯度,该块梯度包含所有GPU中该块所对应的所有梯度的总和;
第2步,纵向,进行主机间X个纵向的 Ring All Reduce,将每台服务器的X个GPU上的数据进行集群内纵向全局规约;
第3步,横向,进行主机内All Gather,将GPUi[i=0~(X-1)]上的梯度复制到服务器内的其他GPU上;
Torus网络架构具有如下优势:
更低的延迟:环面拓扑可以提供更低的延迟,因为它在相邻节点之间有短而直接的链接;
更好的局部性:在环面网络中,物理上彼此靠近的节点在逻辑上也很接近,这可以带来更好的数据局部性并减少通信开销,从而降低时延和功耗。
较低的网络直径:对于相同数量的节点,环面拓扑的网络直径低于CLOS网络,需要更少的交换机,从而节省大量成本。
Torus网络架构也存在一些不足:
可预测方面,环面网络中是无法保证的;
易扩展方面:缩放环面网络可能涉及重新配置整个拓扑,可能更加复杂和耗时;
负载平衡方面:环面网络提供多条路径,但相对Fat-tree备选路径数量要少;
故障排查:对于突发故障的排查复杂性略高,不过动态可重配路由的灵活性可以大幅避免事故。
Torus网络拓扑除了2D/3D结构外,也在向更高维度发展,Torus高维度网络中的一个单元称之为硅元,一个硅元内部采用3D-Torus拓扑结构,多个硅元可以构建更高维的4D/5D/6D-Torus直接网络。
审核编辑:黄飞
-
智算中心网络架构选型原则2023-08-07 4264
-
请问mesh网络中拓扑结构是如何管理的?2024-07-12 524
-
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览2024-10-15 2377
-
《算力芯片 高性能 CPUGPUNPU 微架构分析》第二篇阅读心得:芯片拓扑学:并行扩展与CPU设计的巨头对决2024-10-29 1569
-
发现网络拓扑的方法(中)2012-08-11 2276
-
什么是超融合技术,为什么超融合架构比传统架构好2020-07-20 11124
-
三维片上网络高维超立方裂变拓扑结构2021-05-11 1338
-
CPU+GPU架构超算的未来发展趋势分析2022-03-01 4815
-
算力网络的架构2022-08-17 7205
-
CPU 拓扑中的SMP架构2022-08-29 6124
-
算力网络的概念及整体架构2023-05-25 1327
-
什么是走线的拓扑架构?怎样调整走线的拓扑架构来提高信号的完整性?2023-11-24 1783
全部0条评论

快来发表一下你的评论吧 !
