

 单日获客成本超20万,国产大模型开卷200万字以上的长文本处理
单日获客成本超20万,国产大模型开卷200万字以上的长文本处理
描述
电子发烧友网报道(文/周凯扬)随着AGI生态的蓬勃发展,各种支持多模态的大模型推陈出新,比如最近比较火的音乐大模型Suno和文生视频大模型Sora等等。然而在传统基于文本的大语言模型上,除了追求更快更精准的推理和高并发流量以外,似乎已经没有太多值得厂商大肆宣传的特性了,直到最近超长文本处理的爆火。
国产大模型的新卷法,长文本处理
当下将大模型长文本处理炒热的,无疑是来自月之暗面的Kimi。作为去年发布的大模型,Kimi的主要卖点就是长文本,当时发布的初版Kimi,就已经支持到最多20万汉字的输入处理。
然而仅仅20万字的文本处理,还不至于给用户带来质变的交互体验,毕竟GPT-4 Turbo-128k已经支持到约合10万汉字的长文本处理,谷歌的Gemini pro也支持到最多70万个单词的上下文,但不少长篇小说、专业书籍的字数要远超这一数字。

Kimi支持200万字上下文 / 月之暗面
Kimi在最近爆火源于一项重大迭代升级,月之暗面将长文本处理的字数限制扩展到200万字,远超Claude3、GPT-4 Turbo和Gemini Pro模型。在新功能推出和有效推广下,Kimi很快涌入了一大批用户,其app甚至短暂地冲进了苹果App Store前五的位置。然而这样也对Kimi的运营造成了不小的压力,Kimi在上周经历了多次宕机,这还是在月之暗面对服务器连续扩容的前提下。
面对竞争对手Kimi的用户量激增,阿里巴巴和360很快就坐不住了。3月22日,阿里巴巴宣布通义千问将向所有用户免费开放1000万字的长文档处理功能;3月23日,360智脑宣布正式内测500万字长文本处理功能,且该功能即将入驻360 AI浏览器。
除了阿里巴巴和360外,目前国内访问量第一的百度文心一言据传也会在下月开放长文本处理功能,并计划把字数上限提高至200万甚至500万字。
超长文本实现的技术难点和商业桎梏
尽管在用户看来,阿里巴巴、360等厂商宣布支持超长文本处理好像是一件无需多少时间的易事,但实际上超长文本处理的实现存在不少技术痛点和商业成本问题。要知道在2022年,绝大多数的LLM上下文长度最多也只有2K,比如GPT-3。
直到GPT-4和Claude 2等,这些大模型才从架构上对文本长度进行了优化,可即便如此,主流的文本输入长度依然不会超过100K。这也是因为对部分大模型而言,长文本不一定代表着更好的使用体验,尤其是在查全率和准确率上。
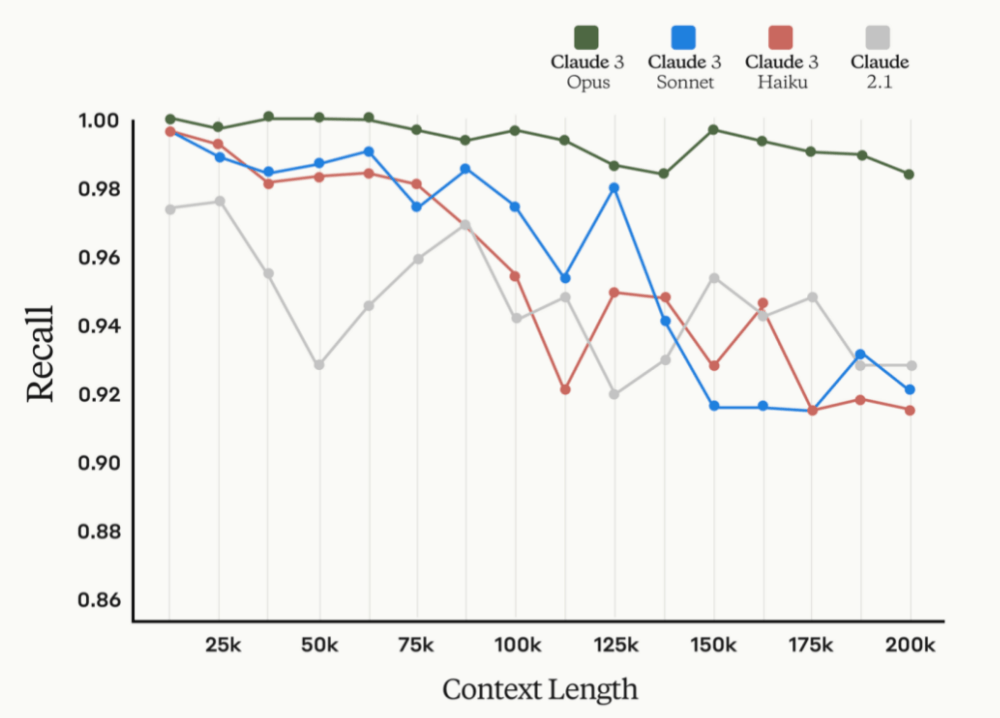
Claude的上下文长度和召回率关联图 / Anthropic
以Anthropic给出的数据为例,从上图可以看出,随着文本长度的增加,召回率是在逐步降低的,即便是最新的Claude3也是如此,而召回率代表了检索出相关信息量占总量的比率。至于精确度,则与上下文中的事实位置存在很大的关系,如果用户问题的事实存在于文本开头或后半部分的位置,那么更容易得到精确的结果,而位于10%到50%之间位置的文本,则精确度急剧下降。
除此之外,长文本对于GPU和内存的资源消耗太大了,即便是小规模地扩展文本长度,动辄也要消耗100块以上的GPU或TPU,这里指代的GPU还是A100这种单卡显存容量高达40GB或80GB的设备。
这也是Kimi在经历大量用户访问后,需要紧急扩容的原因。而阿里巴巴之所以能这么快开放长文本能力,也是凭借着手握庞大的服务器资源。至于Anthropic,我们从Claude3 Opus高昂的Tokens价格,也可以猜到其硬件成本绝对不低。
另外,在持续火爆一年之后,目前的大模型应用也难以单纯靠技术立足市场吸引用户了,商业推广也已经成了必行之路。就以Kimi为例,在社交媒体上有关该应用的推广可谓铺天盖地,很明显对于新兴的大模型应用而言,收获第一批用户才是至关重要的。
据传Kimi在广告投放上,吸引每位新用户的花费在10元左右,而新用户参与到使用中带来的额外算力开销在12元至13元左右。如果单单只是根据手机平台app的下载量计算,那么Kimi的每日获客成本至少为20万人民币,而这还未计算来自网页端和小程序端的用户。
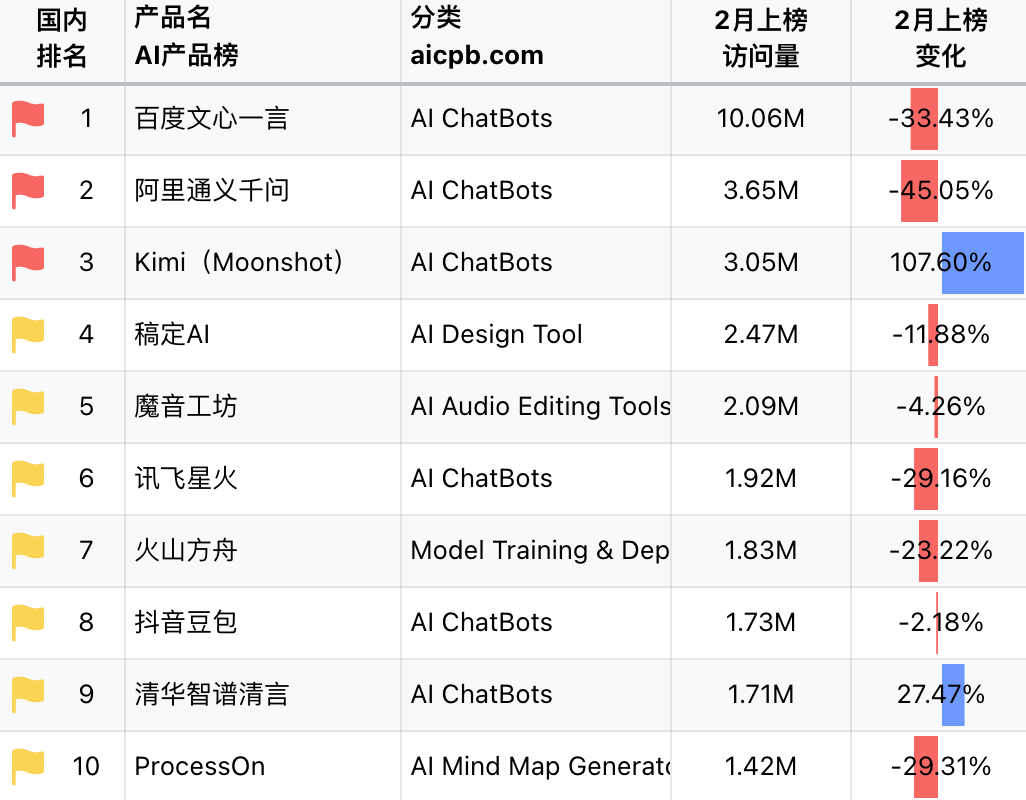
AI产品国内总榜 / AI产品榜
而且Kimi的推广也不是从200万长文本功能的推出才开始的,早在二月份Kimi就开始以长文本这一特性加强商业推广了。从AI产品榜中可以看出,Kimi在2月的访问量飙升,在国内总榜中仅次于百度文心一言和阿里通义千问,足见其在商业推广和产品运营上都下了血本。但相对ChatGPT和New Bing之类的应用而言,其访问量还是存在很大的差距。
这也充分说明了为何国外的大模型应用没有去卷200K以上文本长度的原因,目前算力、准确度和长文本之间的冲突限制了他们去发展长文本。但这对于中国的大模型应用来说,反而是一个弯道超车的机会,因为大模型上的长文本能力确实带来了用户体验上的改变。
长文本对于用户体验的改变
国产大模型为什么要去卷长文本,这是一个与大模型应用落地息息相关的问题。在过去,正是由于长文本能力不足,绝大多数大模型应用才会给人不堪大用的感觉,比如虚拟助手由于长文本能力不足,会遗忘重要信息;基于大模型来设计剧本杀等游戏规则时,上下文长度不够只能在规则和设定上缩水,从而简化游戏难度;在论文分析和法律法规解读这样的关键领域,更是因为缺乏长文本的支持,无法给到用户精准的答案。
这与大模型卷参数规模不同,因为用户已经发现了即便是70B这个量级的大模型,在面对用户的问题时,也会出现胡编乱造的问题。反倒是长文本提供了更多的上下文信息,大模型在对语义进行分析判断后,会提供更加精确的答案,所以不少用户才会借助Kimi来分解长篇小说、总结论文等。
不过在享受长文本处理带来便利的同时,我们也应该注意下长文本处理背后潜在的信息安全和版权问题。对于过去短文本的处理,就已经存在一些可能暴露用户真实身份和隐私信息的问题,随着长文本支持对于更大文件和更长文本的处理,有的人可能会选择将合同、条例或标准等包含敏感信息的专业文件上传到大模型上,又或是引入一些盗版文档资源。
所以国家层面也开始出台各种管理办法,对于大模型语言模型在内的生成式人工智能进行规范,不能侵犯知识产权并保护个人隐私。如此一来,对于大模型应用本身的信息脱敏也提出了更高的要求。
写在最后
相信经过一年的大模型应用轰炸后,不少用户对于基本的AGI玩法已经玩腻了,所以长文本、文生视频这种新的交互方式才会让人趋之若鹜。但我们也很少看到成功的长文本大模型商业化落地项目,毕竟在高额的获客成本下,RAG这种外挂知识库的方式可能更适合手中资金有限的初创AGI应用开发商。
-
光伏户用如何做到低成本获客?2024-02-27 34308
-
[原创]诚招兼职打字录入员,中文80元/万字,英文110元/万词2010-07-05 2946
-
使用 Linux/Unix 进行文本处理2015-11-24 4352
-
shell文本的处理方法是什么2020-05-27 1245
-
易语言-文本处理2016-06-06 604
-
Python网页爬虫,文本处理,科学计算,机器学习和数据挖掘工具集2018-09-07 1505
-
如何优雅地使用bert处理长文本2020-12-26 9765
-
详解Linux Shell文本处理工具2022-10-27 925
-
近万字长文盘点!2022十大AR工业典型案例,不可不看!2023-01-17 4063
-
达观曹植大模型正式对外公测!专注于长文本、多语言、垂直化发展2023-07-12 2236
-
如何用AI聊天机器人写出万字长文2023-12-26 2613
-
阿里通义千问重磅升级,免费开放1000万字长文档处理功能2024-03-26 1942
-
360开源70亿参数模型,助力360k长文本输入2024-03-29 1236
-
MiniMax推出“海螺AI”,支持超长文本处理2024-05-17 2115
-
Linux Shell文本处理神器合集:15个工具+实战例子,效率直接翻倍2026-02-03 3399
全部0条评论

快来发表一下你的评论吧 !
