

SHARC并行系统软件设计方法
处理器/DSP
描述
随着数字信号处理(Digital Signal ProcESSor,DSP)技术的发展,DSP已被广泛应用于雷达、通信等领域。虽然DSP经历了几代的发展,运算速度和能力都有了很大的提高,但在很多情况下,单片DSP已经不能满足实时处理的要求,必须寻求多片DSP并行处理的方案。
从系统结构出发可以将并行系统分为共享存储器并行系统和分布存储器并行系统。AD公司推出的SHARC系列DSP芯片同时支持这二种并行处理器结构。通常,将AD公司的一系列双位高性能浮点DSP称为SHARC(Super Harvard Architecture)。对于共享存储器系统,通过SHARC间的外部共享总线实现。对于分布存储器系统,通过2个SHARC间的链路口直接连接,实现DSP间点对点的通信。
然而,不能认为将多个SHARC互相进行硬件连接就实现了并行处理。真正的并行处理应该是使互连的各个DSP能够协调工作,缩短系统处理的时间。这需要并行系统中SHARC间能完成数据流的传递。并行系统中各个SHARC间数据流的传递同数据处理同等重要。本文针对这二种并行方式,分别给出了软件的设计方法和设计技巧,并且给出了针对ADSP2116X的程序实现。
1 共享存储器并行系统的设计
SHARC为多处理器系统提供了强大的支持,用户可以在不附加任何外围电路的情况下构成共享存储器并行系统。SHARC具有一套巧妙的分布式总线仲裁机制。使用2~6片SHARC把各SHARC的相应引脚相连就可以共享外部总线。每片SHARC都可以访问其他SHARC的片内存储器,还可以通过设置IOP寄存器启动其他SHARC的DMA操作。
组成共享存储器并行系统时,每一个SHARC都有一个惟一的标识:ID2~0,取值范围为000~110。ID=001表示该SHARC为1号DSP,ID=010表示该SHARC为2号DSP,依此类推。ID=000表示是单DSP系统。在多DSP系统中,ID=001号的DSP是必须存在的,这是DSP加载成功以后的主处理器。
在共享存储器系统中,任何时刻都只有一片SHARC可以驱动外部总线,该SHARC就被称为主处理器。其余的从SHARC如果需要访问总线,则必须先申请总线。主处理器如果此时没有数据传递或者总线占用时间到,就会释放总线控制权,把自己的外部总线驱动为三态,完成总线控制权的转移。
主处理器对从SHARC的内存访问和对自己的内存访问一样简单,既可以通过内核直接读写完成,也可以通过外部口DMA实现。在共享存储器并行系统中,每一片SHARC根据自己的ID号都有一个映射的多处理器存储空间。例如对于ADSP2116X,ID=001的SHARC对应的多处理器存储空间为0x100000~0x1F FFFF,ID=010的SHARC对应的多处理器存储器空间为0x20 0000~0x2F FFFF等。共享存储系统的LDF文件与单DSP系统有些不同。下面给出它的一个示例(以2个SHARC为例)。
例1:共享存储器系统LDF文件。
ARCHITECTURE(ADSP-21160)
SEARCH_DIR($ADI_DSP211xxlib)
MPMEMORY{
DSP1{START(0X100000)} //第一片DSP在多处理
//器空间的映射地址
DSP2{START(0X200000)} } //第二片DSP在多处理
//器空间的映射地址
MEMORY
{pm_rsTI { TYPE(PM RAM)START(0x00040004)END
(0x0004000f)WIDTH(48) }
pm_code { TYPE(PM RAM)START(0x00040100)END
(0x00049fff)WIDTH(48) }
dm_data { TYPE(DM RAM)START(0x00050000)END
(0x00059fff)WIDTH(32) } }
PROCESSOR DSP1
{LINK_AGAINST(DSP2.DXE) //需要重新连接的
//DSP2的目标文件
OUTPUT(DSP1.DXE) //DSP1输出的目标文件
…… //和单DSP系统相同,故略去,下同
}
PROCESSOR DSP2
{LINK_AGAINST(DSP1.DXE) //需要重新连接的
//DSP1的目标文件
OUTPUT(DSP2.DXE) //DSP2输出的目标文件
……
}
这样,这二片DSP便可以通过外部总线访问对方的内部资源。当DSP1需要直接访问DSP2中的某一变量时,只需要DSP2将该变量设置为global类型,DSP1就可以在多处理器空间中通过外部总线直接访问该变量,当然,也可以根据变量的内存地址直接访问。
在共享存储器并行系统中,当二个SHARC之间通过总线进行数据传递时,如果此时其他的DSP需要访问外部总线,则只有挂起等待。这样,在多个DSP间数据交换比较频繁时,系统的效率就会大大降低。另外,在共享存储器并行系统中,最多只能有6个DSP互相连接。如果需要更多的DSP并行工作,共享存储器并行系统便无能为力。采用以下介绍的分布存储器并行系统,可以有效地解决这个问题。
2 分布存储器并行系统的设计
ADSP2116X提供了独立的6个链路口,每个链路口可以实现与其他ADSP2116X或者外围设备点对点的通信。每个链路口包括8位双向数据线(LxDAT7~0),1个双向时钟信号(LxCLK),1个双向确认信号(LxACK)。但是,链路口没有为发送和接收提供2套管脚,所以在任何时刻链路口只能工作在单工状态。依靠链路口进行双DSP间的数据传递时,只需要把2个DSP的10个管脚对应连接即可,不需要任何外部附加逻辑。
在ADSP2116X内部有6个链路缓冲器。用户通过定义LAR寄存器,可以为每个链路口选择一个或几个缓存器。链路缓冲器一端与内部总线相连,另一端通过LAR寄存器与不同的链路口相连。需要注意的是,链路口与链路缓存器是完全不同的概念。链路缓冲器可以理解为一个双向的FIFO,而链路口仅仅代表其对外的10个管脚。链路口的特性很大程度上是由其正在使用的缓冲器的特性决定的。
ADSP2116X的链路口发送时钟频率可以通过LCTLx寄存器的LxCLKD位设置(1,1/2,1/3,1/4核时钟频率),链路口数据线根据需要可以选择为8位或4位。发送方在时钟LxCLK的上升沿送出8/4位码,接收方利用时钟下降沿锁存8/4位码,并且接收方使LxACK有效,表示已准备好接收下一个字。在每个字开始发送时,发送方如果看到LxACK无效,则将LxCLK保持为高,并等待LxACK有效后才开始发送新字。当发送缓冲为空时,LxCLK将保持为低电平。
链路口数据传输可以通过DMA方式和内核直接访问二种方式。DMA方式传输时不需要内核干预,在传输数据量比较大时效率很高,但是需要首先进行DMA参数设置。当仅有个别数据需要通过链路口传递的情况下,往往不使用DMA方式,而是通过ADSP2116X的内核直接访问。用户可以通过LCOM寄存器中缓冲器的状态来控制内核对链路口缓冲进行读写操作,也可以通过相应的中断从链路口缓冲器中读写数据,如“DM(LBUF0)=R0;”或者“R0=DM(LBUF0);”等。值得注意的是,无论是试图从一个空的链路缓冲中读,还是试图向满的缓冲中写,内核的指令都会挂起,直到操作成功为止。因此,内核指令直接读写链路缓存时,需要首先判断链路缓冲状态。
ADSP2116X为每个链路口提供了一个专用的DMA通道,它们分别占用DMA中的4~9通道。链路口的DMA使用非常方便,只需将对应的DMA参数寄存器(IIx,IMx,Cx)设置完毕,使能LCTLx中对应通道的LxDEN即可。在当前DMA结束(或者链式DMA全部结束)后,会触发一个可屏蔽中断通知用户。启动链路口DMA的顺序如下:
(1)由LAR寄存器的AxLB为链路口分配一个LBUFx;
(2)由LCTL寄存器的LxEN使能这个LBUFx,并设置好LCTL控制寄存器;
(3)设置DMA参数(IIy,IMy,Cy);
(4)置位LCTL寄存器的LxDEN,就启动了DMA。
其中:x=0~5,y=4~9。
下面给出一个利用链路口DMA发送数据的示例。
例2:利用链路口0进行数据发送。
.SECTION/dm dm_data;
.VAR trans_data[size];
.SECTION/pm pm_code:
……
r0=0x0002c688;
dm(LAR)=r0;
r9=0x00000229; /*LBUF0使能、发送、8位字宽、核时钟速率*/
dm(LCTL0)=r9;
r0=trans_data;
dm(II4)=r0; /*需要发送数据的起始地址*/
r0=1;
dm(IM4)=r0;
r0=size;
dm(C4)=r0;
ustat1=dm(LCTL0);
bit set ustat1 L0DEN; /*启动发送DMA*/
dm(LCTL0)=ustat1;
如果传输的数据不在一段连续的内存区,而是在多段数据块中,可以利用链式DMA。链式DMA可以在当前DMA操作结束后自动重新配置当前通道并开始新的DMA,所有这些操作都不需要内核的干预。在链式DMA过程中,用户只要对DMA参数配置一次,就可以方便地完成多块数据的DMA传输。
链式DMA是通过CPx寄存器实现的。对于ADSP2116X来说,CPx是一个19位的寄存器。寄存器中低18位表示相对于基地址0x40000的偏移量,用户在这个地址的内部存储器中存放下一次DMA的参数,这些参数叫做TCB(Transfer Control Blocks)。CPx中的第19位是控制当前链式DMA完成后是否产生中断的PCI位。如果把全局地址赋给CPx,则PCI位一定为1,表明一定会产生中断。
用户只需要在内存区填写多个TCB的表格,用其中的CPx字段将每个表格串起来并将第一个表格的结束地址放入CPx寄存器,就可以启动链式DMA。要终止一个链式DMA,只需要把最后一个TCB中的CPx字段填0即可。TCB结构如图1所示。
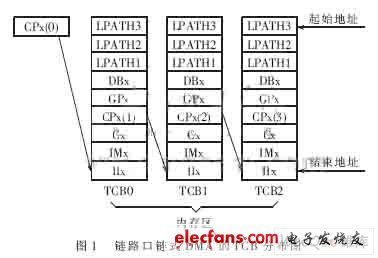
下面是建立一个链式DMA的顺序:
(1)在片内存储器中建立需要的TCB数据块;
(2)设置DMA参数寄存器,使能相应的LxDEN和LxCHEN;
(3)将第一个TCB的最后一个地址的偏移量写入CPx寄存器中,即启动了链式DMA。
链路口的数据传递可以依靠中断。链路口中断的产生有以下3种情况:
(1)DMA使能时,DMA完成后将产生一个可屏蔽中断。
(2)DMA禁止时,发送时LxBUF非满,接收时LxBUF非空。
(3)外部设备访问一个未指定的链路口,或者访问一个已指定但LBUF被禁止的链路口时,将产生一个链路服务请求(LSRQ)中断,且所有的链路口公用一个中断矢量。
前2种情况比较简单,只需要注意:ADSP2116X链路口的中断屏蔽、锁存与ADSP2106X不同,它从IRPTL/IMASK中分离出来,单独存在于寄存器LIRPTL中,并且在IMASK中加了一个链路口中断总开关LPISUMI。如果要使能某个链路口中断,则需要设置3个控制位。例如使能L0BUF中断,需要以下指令:“bit set imask LPISUMI;bit set lirptl LP0MSK;bit set mode1 IRPTEN;”。
对于上面的链路服务请求中断(LSRQ),在多SHARC通信时比较有效。通过该中断可以实现使用同一个链路口完成接收和发送数据的功能,并且在2个SHARC一个主动、另一个被动的情况下不依靠外部逻辑实现2个链路口的数据传递同步。例如SHARC-1需要通过链路口向SHARC-2传送数据,由于SHARC-1主动发送,因此只需配置好DMA参数,启动DMA即可。但是对于SHARC-2,由于被动接收,事先并不知道SHARC-1何时向自己发送数据,因此很难在适当的时候启动DMA接收。通过LSRQ中断,就可以很容易地解决这个问题。
首先将双方的链路口设置为无效。当SHARC-1需要向SHARC-2通信时(发送或接收)将自己的链路口设为有效,并根据需要从自己的链路缓冲中读写数据。由于链路通信协议规定:当发送数据时,如果对方没有响应,则将LxCLK置为高电平,数据线保持不变;当需要接收数据时,如果对方没有响应,则LxACK保持为高电平。这样,SHARC-2就会触发LSRQ中断。由于LSRQ中断的所有链路口公用一个中断矢量,因此在中断服务子程序中,首先需要判断哪个链路口有服务请求,且要区分是发送还是接收请求,然后配置相应的DMA参数,使能该链路口,从而在双方之间建立一个单向的数据通路。双方传递数据完成,会产生一个如上文中链路口中断情况(1)所示的中断。在中断服务程序中,仍然将各自的链路口设置为无效,等待下一次通信请求。下面给出一个利用LSRQ中断实现数据传递的示例。
例3:配置L0BUF,利用LSRQ中断实现数据传递。
r0=0x0002c688;
dm(LAR)=r0;
ustat1=dm(LCTL0);
bit clr ustat1 L0EN; /*禁止链路缓冲0*/
dm(LCTL0)=ustat1;
ustat1=dm(LSRQ);
bit set ustat1 L0TM; /*链路0发送屏蔽*/
bit set ustat1 L0RM; /*链路0接收屏蔽*/
dm(LSRQ)=ustat1;
bit set imask LSRQI; /*使能LSRQ中断*/
bit set mode1 IRPTEN;
……
上面的程序段可以放在主程序的开始。经过以上的配置,就可以通过LSRQ中断方便地实现与另一片SHARC的链路口通信(发送、接收)。另外需要注意的是,当修改链路缓冲器的使能位LxEN时,必须将该中断屏蔽(bit clr imask LSRQI),否则有可能产生不可预料的LSRQ中断。
3 结束语
采用共享存储器并行系统和分布存储器并行系统各有特色,结合这二种系统设计的思想更易于构建并行处理系统。设计时,可以采用子模块结构把这二者结合起来。子模块内部,采用共享存储器和分布存储器并存,各个SHARC间根据需要既可以通过总线传送数据,又可以通过链路口传送数据。子模块之间采用分布式存储器系统,通过链路口进行数据传递。采用以上设计,可以实现有效的并行处理,使系统整体性能有很大的提高。
-
基于Qt和ARM的无线点菜系统软件设计2023-10-13 598
-
嵌入式系统软件设计教材资料2022-04-12 944
-
嵌入式系统软件设计的原则是什么2021-12-24 1075
-
掌握嵌入式系统软件设计方法2021-11-09 1871
-
基于RTOS的嵌入式系统软件设计2021-04-19 1311
-
SHARC并行系统软件设计方法及其程序实现2017-11-30 788
-
ARM的嵌入式系统软件设计2017-10-27 1052
-
变电站综合自动化系统软件设计2017-03-26 1538
-
基于ARM的嵌入式系统软件设计部分2017-01-14 888
-
基于MCU的高可靠性数据采集系统软件设计分析2016-01-04 817
-
基于LabView的图像跟踪系统软件设计2015-04-20 3299
-
微波自动测量系统软件设计2009-12-29 994
-
采用WinCE的液位遥测系统软件设计2009-03-29 1028
-
配套新型布袋除尘控制系统软件设计2009-03-16 771
全部0条评论

快来发表一下你的评论吧 !
