

基于L31 RISC-V核心的嵌入式人工智能设计方案
嵌入式技术
描述
1. 产业趋势
近年来,物联网和工业物联网的快速发展促发了从云端到设备端AI处理的重要转变。越来越多设备需要能够在端侧运行人工智能任务,从而最大限度地减少安全问题、数据传输成本和延迟。在为物联网和工业物联网应用程序选择SoC或MCU时,运行AI/ML任务的能力逐步成为必备条件。
嵌入式设备通常面临资源限制,在嵌入式平台上如何高效运行人工智能算法成为新挑战。Codasip工程团队从软件和硬件的角度研究了如何让它变得更容易。我们使用Codasip L31 RISC-V内核和Codasip Studio,探索并定制了与CPU流水线紧密耦合的高效紧凑的人工智能加速器的设计。
2. 项目概述
Codasip工程团队使用TensorFlow Lite for Microcontrollers(TFLite Micro)作为专用人工智能框架,对Codasip L31 RISC-V核进行了定制,并对使用标准指令集(ISA)的L31性能和包含了AI加速器指令的自定义扩展后的L31性能进行了比较。该AI加速器使用不到200行CodAL代码即可实现,性能提高了5倍以上,功耗降低了3倍以上。该项目凸显了Codasip Studio工具所提供的定制设计灵活性和CodAL易用性的优势。这些工作大幅提高了神经网络(NN)在嵌入式RISC-V核上的性能。
3. 应用开发
我们使用了基于Codasip L31 RISC-V核的TensorFlow Lite Micro运行卷积神经网络进行图像分类。神经网络(NN)架构包含两个卷积和池化层、至少一个完全连接层、矢量化非线性函数、数据大小调整和归一化操作(图1)。
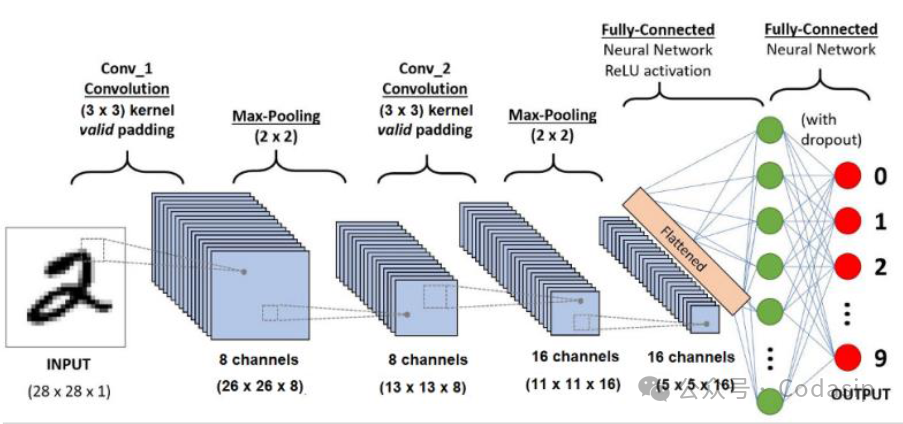
图1 卷积神经网络架构
我们采用了著名的“MNIST手写数字分类”作为基准来评测,使用Codasip Studio分析器(图2)来分析图像分类任务。通过Codasip Studio软件可以很容易地看出哪些代码部分是最为关键的,占用了最多的处理器时间,这些部分将是优化的主要目标。
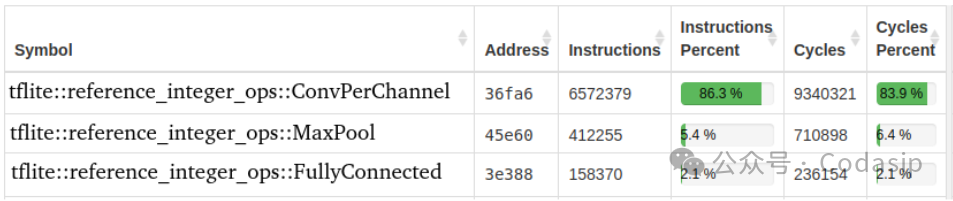
图2 Codasip Studio分析器 报告
通过基准评测显示,约84%的周期用于图像卷积函数,该函数是由深度嵌套的for循环实现。为了进行简单的3x3卷积,通用RISC-V处理器必须运行9条加载指令、9次乘法运算和8次加法运算,并且存在一些流水线停滞的开销。因此,卷积似乎是优化的主要目标。
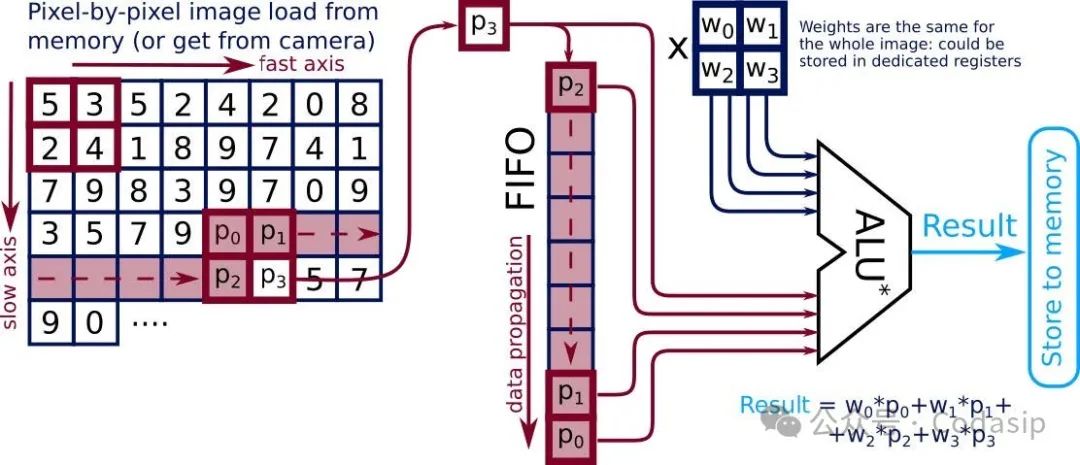
图3 卷积加速器原理
所提出的卷积加速器方案如图3所示。它与核心流水线紧密耦合,并基于可以存储多个图像行的FIFO寄存器链。通过将图像像素推送到FIFO,并读取某些FIFO元素,从而可以在单个处理器时钟周期内访问单个卷积所需的所有图像数据,避免来自存储器的多次加载。修改后的ALU* 通过图像像素与卷积权重的并行乘法,并将结果相加。该加速器由几条自定义指令控制,可以在单个时钟周期内完成卷积结果,从而显著减少了整个图像卷积所需的时间。
所描述的加速器也可以用行业标准的常用硬件描述语言来实现,然而CodAL提供了一种更简单、更紧凑的方法来实现。
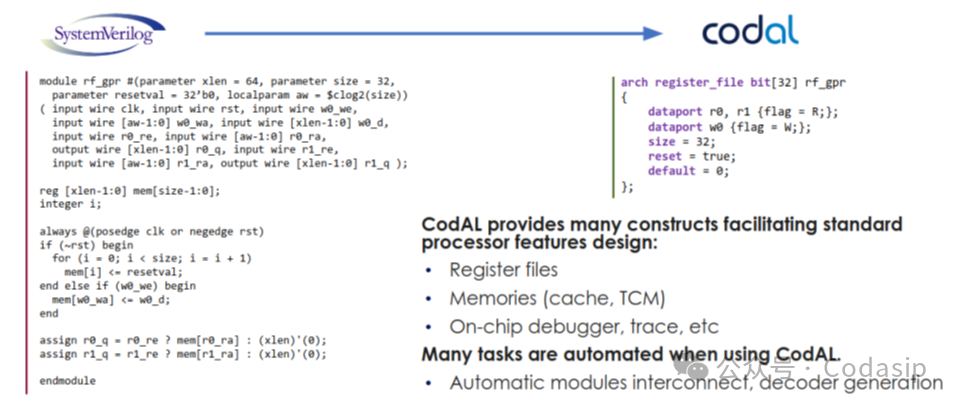
图4 CodAL与HDL(Veriflog)比较
CodAL是一种专门为处理器描述而设计的高级语言。它有助于简化某些标准处理器功能的定义,例如寄存器文件、缓存、紧密耦合存储器和片上调试器。生成的CodAL描述比其他HDL所提供的要紧凑得多(图4)。
由于这种紧凑性,上述卷积加速器可以仅用200行代码在CodAL中实现。它包括了硬件资源覆盖率和自定义控制指令实现。由此产生的加速器设计可以处理多达64 x 64个图像,并构成多达5 x 5个卷积。同时自动生成编译器和分析器,进一步简化了对加速器性能的评估。
4. 实施结论
通过添加卷积加速器和自定义指令,从而获得了比标准L31 RISC-V核具有更好性能和更低功耗的定制L31核。
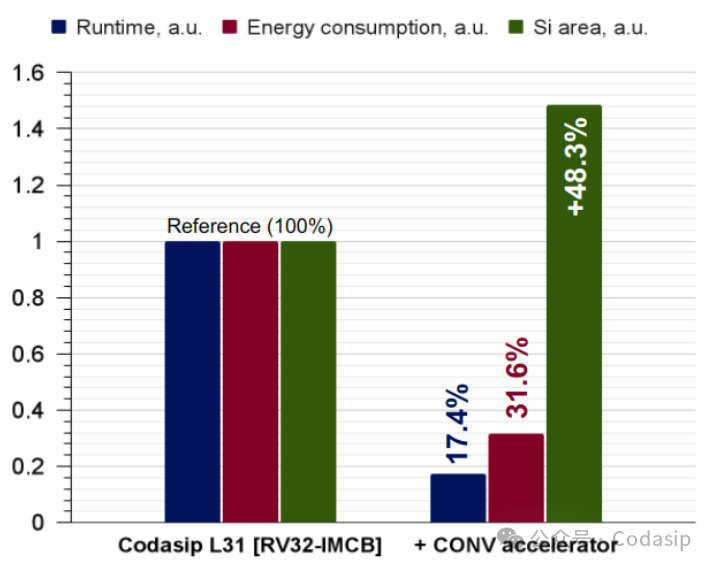
图5 L31 RISC-V核 嵌入AI定制前后比较
图像分类所需的时钟周期数减少了5倍以上,功耗减少了3倍以上。后者与电池寿命直接相关,这意味着在一个充电周期之间,可以完成原来3倍的图像分类。性能和功耗的大幅改善伴随着硬件成本的提高,RISC-V核的硅面积增加了48%。这是由于增加了卷积加速器模块内部的并行乘法器,对于显著的性能和功耗收益来说,这可以被认为是合理的成本。
(注:AI和ML应用程序的计算要求各不相同。上面提供的定制设计示例仅供参考,并不代表是一个完整和最优的解决方案。通过其他自定义指令和/或加速器设计可能会进一步改进PPA。)
审核编辑:黄飞
-
重磅合作!Quintauris 联手 SiFive,加速 RISC-V 在嵌入式与 AI 领域落地2025-12-18 1030
-
为什么RISC-V是嵌入式应用的最佳选择2025-11-07 2036
-
risc-v在人工智能图像处理应用前景分析2024-09-28 1173
-
基于嵌入式RISC-V处理器核轻松实现DSP扩展设计2024-02-28 2188
-
嵌入式人工智能的就业方向有哪些?2024-02-26 12463
-
嵌入式人工智能学习路线2022-09-16 4548
-
嵌入式人工智能实践课程改革研讨会在南京顺利召开2022-08-31 4428
-
Codasip的可定制L31 RISC-V内核荣获Embedded World展会最佳产品大奖2022-06-28 1060
-
如何入门RISC-V嵌入式2022-01-07 1306
-
嵌入式与人工智能关系是什么?2021-12-27 4781
-
RISC-V嵌入式开发的特点有哪些2021-11-08 2455
-
RISC-V嵌入式开发2021-11-03 1901
-
什么叫嵌入式人工智能2021-10-28 2077
-
嵌入式与人工智能关系是什么2021-10-27 3447
全部0条评论

快来发表一下你的评论吧 !
