

网络布局与光模块配置需求深度解析
通信网络
描述
本文来自“A100/H100/GH200集群:网络架构及光模块需求”。传统数据中心经历了从三层架构到叶脊架构的改变,主要是为了适配数据中心东西向流量的增长。随着数据上云的进程持续加速,云计算数据中心规模持续扩大,而其中所采用的的虚拟化、超融合系统等应用推动数据中心东西向流量大幅增长——根据思科此前的数据,2021年数据中心相关的流量中,数据中心内部的流量占比超过70%。
以传统三层架构到叶脊架构的转变为例,叶脊网络架构下,光模块数量提升最高可达到数十倍。

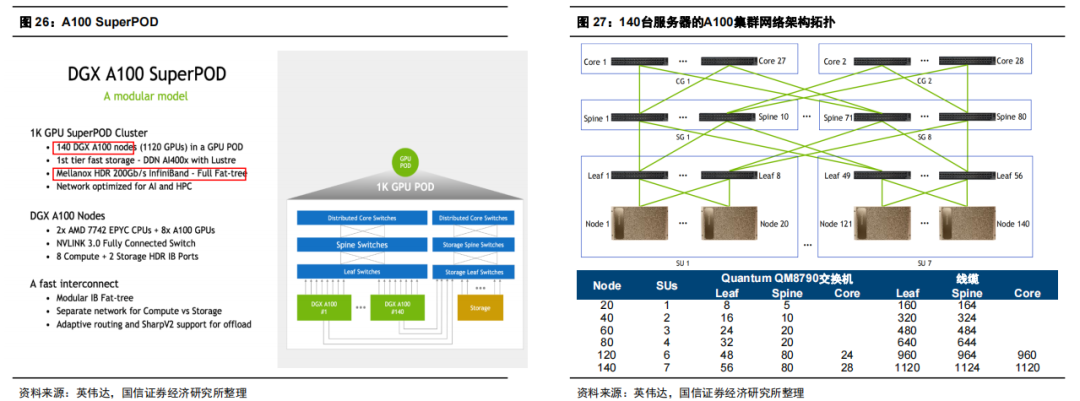
基于缩小网络瓶颈考虑,大规模AI集群的网络架构需要满足大带宽、低时延、无损的需求。智算中心网络架构一般采用Fat-Tree(胖树)网络架构,具有无阻塞网络的特点。 同时为避免节点内互联瓶颈,英伟达采用NVLink实现卡间高效互联。对比PCIe,NVLink具有更高带宽优势,成为英伟达显存共享架构的基础,创造了新的GPU到GPU的光连接需求。 A100:网络结构及光模块需求测算 每个DGX A100 SuperPOD基本部署结构信息为:140台服务器(每台服务器8张GPU)+交换机(每台交换机40个端口,单端口200G);网络拓扑结构为IB fat-tree(胖树)。 关于网络结构的层数:针对140台服务器,会进行三层网络结构部署(服务器-Leaf层交换机-Spine层交换机-Core层交换机),每层交换机对应的线缆数分别为1120根-1124根-1120根。 假设服务器和交换机之间采用铜缆,基于一条线缆对应2个200G光模块计算,GPU:交换机:光模块=14;若采用全光网络,GPU:交换机:光模块=16。
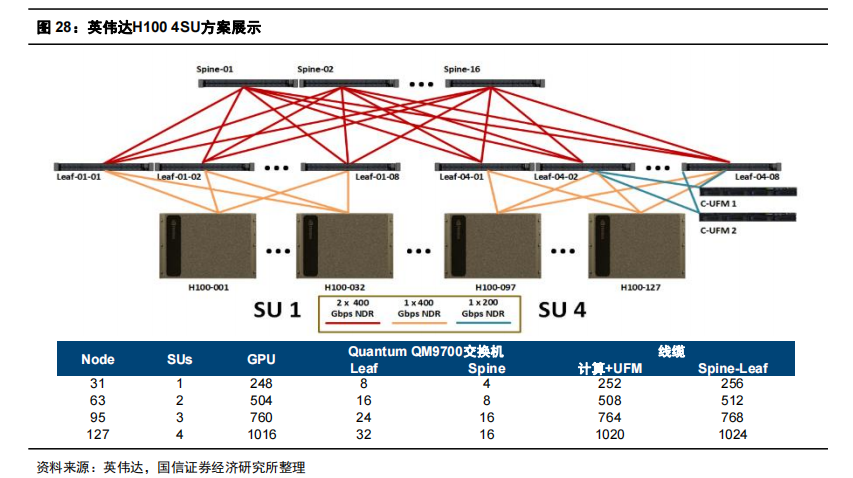
H100:网络结构及光模块需求测算 每个DGX H100 SuperPOD基本部署结构信息为:32台服务器(每台服务器8张GPU)+12台交换机;网络拓扑结构为IB fat-tree(胖树),交换机单端口400G速率,可合并形成800G端口。 针对4SU集群,假设为全光网络、三层Fat-Tree架构下,服务器和Leaf层交换机使用400G光模块,Leaf-Spine和Spine-Core使用800G光模块,则400G光模块数量为32*8*4=256只,使用800G的数量为32*8*2.5=640只。 即GPU:交换机:400G光模块:800G光模块=11:2.5。
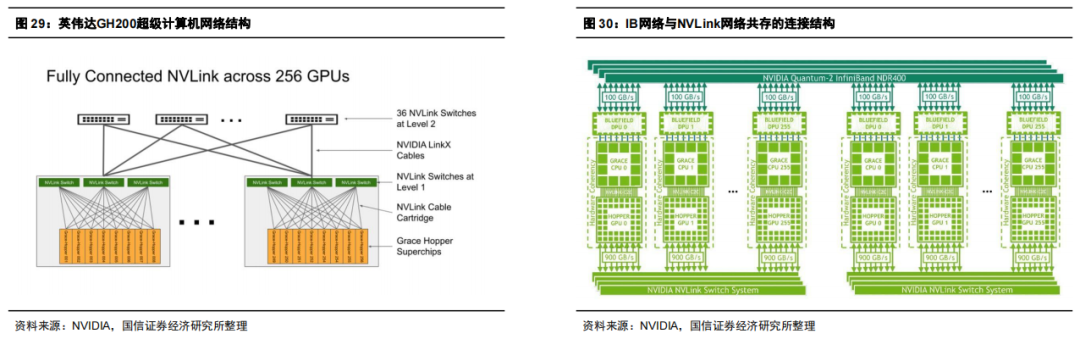
GH200:网络结构及光模块需求测算 针对单个GH200集群:256张超级芯片GPU互联,采用2层fat-tree网络结构,其中两层网络均采用NVLink switch来完成搭建,第一层(服务器和Level 1交换机)之间使用了96台交换机,Level 2使用了36个交换机。NVLink switch的配置参数为:每台交换机拥有32个端口,每个端口速率为800G。由于NVLink 4.0对应互联带宽双向聚合是900GB/s,单向为450GB/s,则256卡的集群中,接入层总上行带宽为115200GB/s,考虑胖树架构以及800G光模块传输速率(100GB/s),800G光模块总需求为2304块。因此,GH200集群内,GPU:光模块=1:9。 若考虑多个GH200互联,参考H100架构,3层网络架构下,GPU:800G光模块需求=1:2.5;2层网络架构下,GPU:800G光模块=1:1.5。即多个GH200互联情况下,GPU:800G光模块上限=1:(9+2.5)=1:11.5。
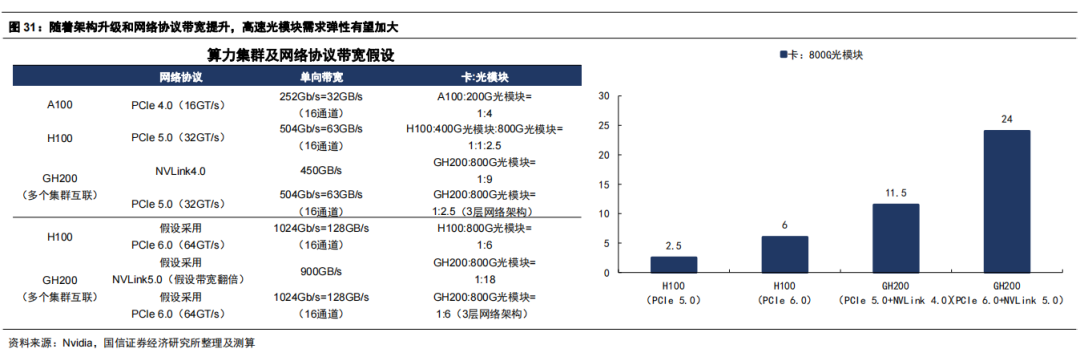
总结: 随着算力集群不断提升网络性能,高速光模块需求弹性加大。以英伟达集群为例,加速卡所适配的网卡接口速率和其网络协议带宽密切相关,A100 GPU支持PCIe 4.0,最大支持单向带宽为252Gb/s,即PCIe网卡速率需小于252Gb/s,因此搭配搭配Mellanox HDR 200Gb/sInfiniband 网卡;H100 GPU支持PCIe 5.0,最大支持单向带宽为504Gb/s,因此搭配Mellanox NDR 400Gb/s Infiniband 网卡。 所以,A100向H100升级,其对应的光模块需求从200G提升到800G(2个400G端口合成1个800G);而GH200采用NVLink实现卡间互联,单向带宽提升到450GB/s,对应800G需求弹性进一步提升。 若H100集群从PCIe 5.0提升到PCIe 6.0,最大支持单向带宽提升到1024Gb/s,则接入层网卡速率可提升到800G,即接入层可使用800G光模块,集群中单卡对应800G光模块需求弹性对应翻倍。
Meta算力集群架构及应用 Meta此前发布“Research SuperCluster”项目用于训练LLaMA模型。RSC项目第二阶段,Meta总计部署2000台A100服务器,包含16000张A100 GPU,集群共包含2000台交换机、48000条链路,对应三层CLOS网络架构,若采用全光网络,对应9.6万个200G光模块,即A100:光模块=1:6,与前文测算的A100架构相同。
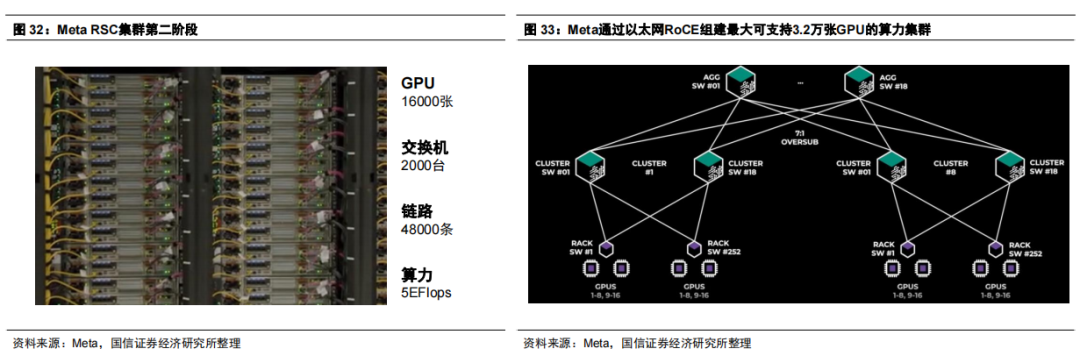
针对LLaMA3的训练,Meta使用了H100 GPU,包含IB和以太网集群,最大均可支持3.2万张GPU。针对以太网方案,根据Meta披露的信息,其算力集群仍采用了有收敛的叶脊网络架构——每个机架2台服务器,接入1个TOR交换机(采用Wedge 400),一个集群中有252台服务器;Cluster交换机采用Minipack2 OCP机架交换机,一个集群中共使用18个Cluster交换机,推算收敛比为3.5:1;汇聚层交换机共18台(采用Arista 7800R3),收敛比为7:1。集群主要采用400G光模块,从集群架构来看,以太网方案仍有待在协议层面进一步突破,推动无阻塞网络的构建,关注超以太网联盟等进展。 AWS算力集群架构及应用 AWS推出了第二代 EC2 Ultra Clusters集群,包括H100 GPU和自研Trainium ASIC方案。AWS EC2 Ultra Clusters P5实例(即H100方案)提供3200 Gbps的聚合网络带宽并支持 GPUDirect RDMA,最大可支持2万张GPU组网;Trn1n实例(自研Trainium方案)单集群16卡,提供1600 Gbps的聚合网络带宽,最大支持3万张ASIC组网,对应6 EFlops算力。
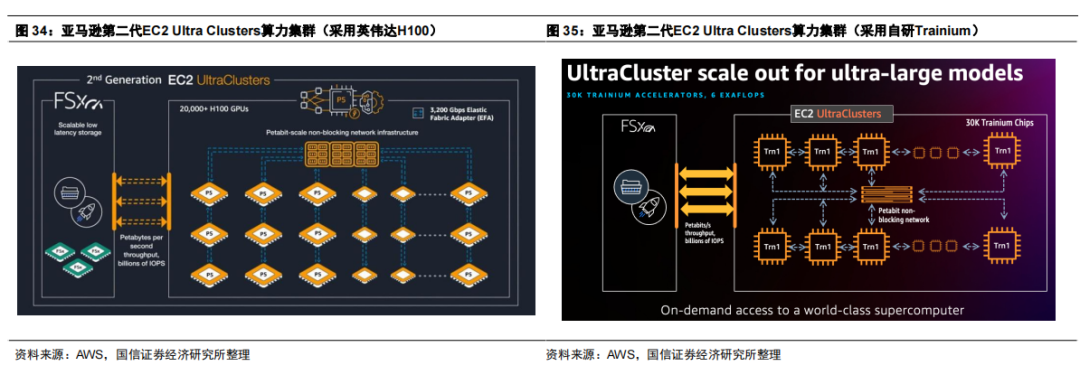
AWS EC2 Ultra Clusters卡间互联分别采用NVLink(H100方案)和NeuronLink(Trainium方案),集群互联采用自研EFA网络适配器。对比英伟达方案,AWS自研Trainium ASIC集群单卡上行带宽推算为100G(1600G聚合带宽/16卡=100G),因此AWS目前架构中暂无800G光模块需求。 Google算力集群架构及应用 Google最新的算力集群由配置为三维环面的TPU阵列组成。一维环面对应每个TPU连接到相邻的2个TPU,二维环面为2个正交的环,对应每个TPU连接到相邻的4个TPU;目前谷歌TPUv4即三维环面,每个TPU连接到6个相邻的TPU。
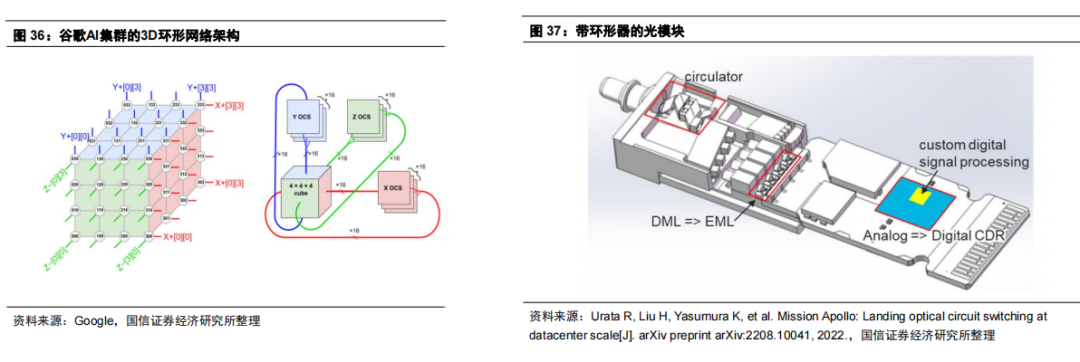
基于此,每个机柜内部构建4*4*4=64颗TPU的3D网络结构。3D结构的外表部分连接到OCS,则一个4096颗TPU互联对应64个机柜、48个OCS交换机即48*64=6144个光模块,内部则采用DAC连接(18000条),则对应TPU:光模块=1:1.5。在OCS方案下,光模块需要采用波分复用方案,并增加环形器(Circulator)减少光纤数量,其光模块方案具有定制化特征(800G VFR8)。
审核编辑:黄飞
-
深度解析:组态 PROFIBUS DP 网络的常见错误与解决方法2026-05-13 331
-
WiFi模块网络配置基本设置2024-05-31 1943
-
深度剖析AI网络中GPU与光模块配比及需求2024-04-23 4877
-
千兆光模块和万兆光模块在网络安全中的重要性2023-11-13 1432
-
万兆光模块是否能够应对未来网络的需求?2023-10-30 1292
-
光模块对网络延迟的影响如何?2023-10-16 2596
-
千兆光模块还能满足现代网络需求吗?2023-10-09 1237
-
C语言深度解析2023-09-28 883
-
未来网络的选择:100G光模块与400G光模块的对比2023-08-19 2658
-
40G光模块的性能及应用解析2023-07-20 2169
-
光模块的结构以及电源需求2022-11-03 2455
-
AUTOSAR架构深度解析 精选资料分享2021-07-28 2029
-
功能安全---AUTOSAR架构深度解析 精选资料分享2021-07-23 1462
-
解析深度学习:卷积神经网络原理与视觉实践2020-06-14 3556
全部0条评论

快来发表一下你的评论吧 !
