

人工智能热潮来袭,硅光子技术迎来杀手级应用?
描述
过去十年来,通用云和互联网应用(如视频流媒体、社交网络、互联网搜索引擎和电子商务平台等)推动了数据中心流量的指数级增长。近年来,利用大语言模型(LLM)进行人工智能(AI)训练和推理的AI及机器学习(ML)的兴起,为传统的数据中心市场提供了巨大的增长前景。回看大语言模型在过去几年中的发展,就不难理解这一市场趋势的变革性影响。
迄今为止,这些模型的建模参数呈超指数增长,数据量的摄取量也成正比。尽管生成式AI仍处于早期阶段,但其应用已扩展到多个领域,包括机器人、自动化设计、先进增强/虚拟现实(AR/VR)、医学、化学以及金融等。所有这些市场的整合应用推动高性能计算和数据中心领域进入了一个全新的技术经济范式。
未来几年,AI专用服务器的市场份额将直线上升,从2022年几乎可以忽略不计,到2027年预计将占据整体市场营收的50%(即900亿美元)。
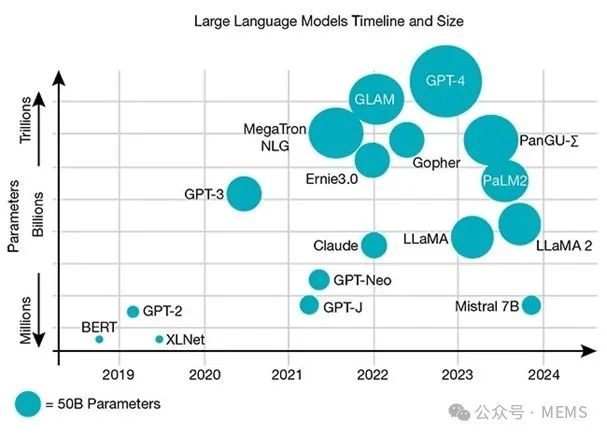
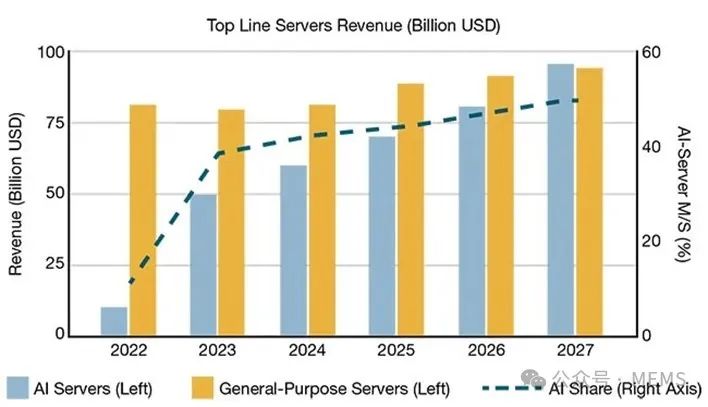
大语言模型演进时间线及其参数数量的相对增长(上图)。AI服务器和通用服务器的营收增长趋势,以及2022年~2027年AI服务器市场份额的相对变化(下图)。
数据间尤其是数据中心内流量的快速增长,推动了对高速可插拔光收发器的需求,目前这种收发器正在从100 Gbps向400 Gbps过渡。此外,已有800 Gbps设备于2023年开始出货,1.6 Tbps可插拔模块目前也可预送样。
互联与人工智能革命
可插拔光收发器用作服务器之间的数据互连,在AI/移动通信应用日益增长的需求中发挥着重要作用。在数据中心,它们在路由器和叶脊架构交换机之间传输和接收数据。具体到云AI/ML应用,它们连接交换机与加速器服务器(即GPU和CPU机架)。此外,这些收发器还可分别通过城域网、长途网和海底网络,在数据中心之间提供短距离、中距离或长距离连接。
一般来说,光收发器必须满足三个同等重要的要求:高速度、低功耗以及最低的成本结构。
功耗方面,数据中心服务器集群的功率密度在50 kW到100 kW之间,以满足新兴的AI要求。然而,2023年~2028年期间,AI在数据中心的功耗预计将增加一倍以上。
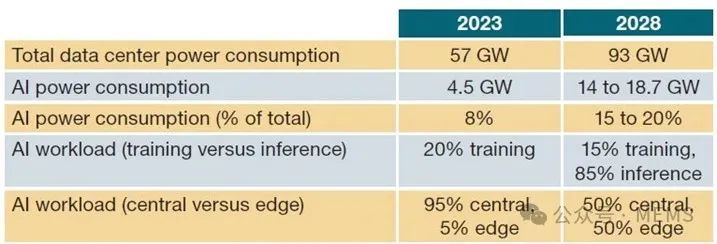
数据中心功耗变化趋势
此外,400 GbE可插拔收发器500 m至2 km链路距离的功耗约为12 W,而800 GbE可插拔收发器的这一数字通常约为16 W。随着数据量的增长,显然需要功耗更低、速度更快的光收发器,这促使可插拔收发器的外形尺寸在不同的架构中不断发展。值得注意的是,可插拔收发器内部的数字信号处理(DSP)是功耗的主要来源之一。这促使业界开始探索新型收发器设计,如线性驱动可插拔光学器件(LPO)、半重定时线性光学器件(HALO)和共封装光学器件(CPO),以利用更先进的器件设计和光电子协同集成,使未来的可插拔收发器能够直接驱动运行,而无需独立的专用DSP组件。
LPO与传统光模块之间的主要区别在于线性驱动(或直接驱动)。LPO采用基于可插拔设计的传统封装形式,使收发器的维护更加方便。LPO收发器,顾名思义,采用线性直接驱动技术,取消了光模块中的DSP和时钟数据恢复芯片。因此,与传统的可插拔光模块相比,这些模块的功耗降低了约50%。此外,由于取消了DSP,并使用高线性跨阻抗放大器和具有均衡器功能的驱动芯片,LPO还进一步缩短了信号恢复时间和延迟。
HALO是介于DSP可插拔模块和LPO之间的最新技术。它解决了无DSP LPO固有的弱点,包括互操作性问题、链路责任以及相对无法解决的问题。
CPO越来越被视为光互连技术自然演进的重要一步,因为它们有可能解决传统光学可插拔技术所面临的带宽和能效挑战。CPO技术通过将光引擎芯片直接与专用集成电路(ASIC)或其它多芯片处理模块共封装到交换机或加速器模块中来实现上述改进。这是通过先进封装工艺实现的,充分利用了电子器件(包括先进的数字功能)和光子器件的协同设计和集成。通过ASIC或其它处理单元(如CPU、GPU和/或存储芯片)直接驱动光学引擎,可以降低延迟和整体功耗。
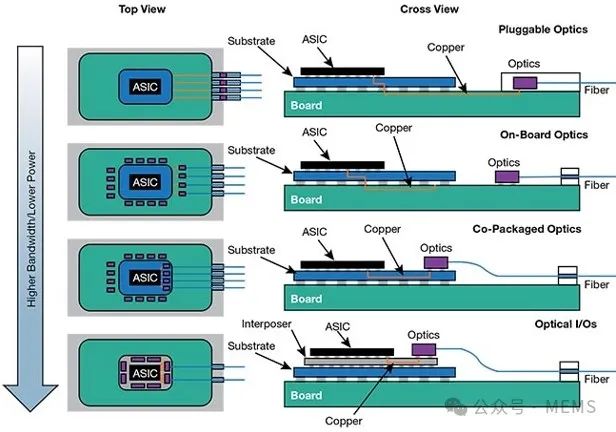
光互连架构演进,从可插拔外形到更先进的板载光学器件、共封装光学器件和光学I/O引擎。光学I/O引擎是实现数字电子器件和光子器件协同集成的终极步骤。
赋能云AI
在AI服务器集群和超级集群中,GPU与网络端口相连,使其可以与其它机架和加速器服务器中的GPU通信。为了最大限度地提高GPU的使用效率,网络速度必须跟上GPU的处理和内存存储速度。这对于AI应用来说极为重要,因为AI应用通常需要实时处理并分析大数据集。
为了满足GPU或xPU(即其它GPU、CPU或存储芯片)之间短距离到长距离连接的需求,硅光子CPO引擎日益被视为这项工作的关键技术。它们可以在计算单元和本地存储器之间以及整个AI结构中实现更灵活的系统网络设计,从而在成本、性能和功耗方面实现收发器功能相对传统可插拔技术的全面改进。已有多家AI公司将集成硅光子技术视为光互连架构面向下一代AI云计算基础设施的自然演进步骤。
这种演进的基础是先进的材料平台,集成光子解决方案将在这些平台上设计和制造。目前最成熟的平台是绝缘体上硅(SOI),它提供了固有的物理和机械特性,有利于多种硅光子学应用,尤其是在光网络领域。
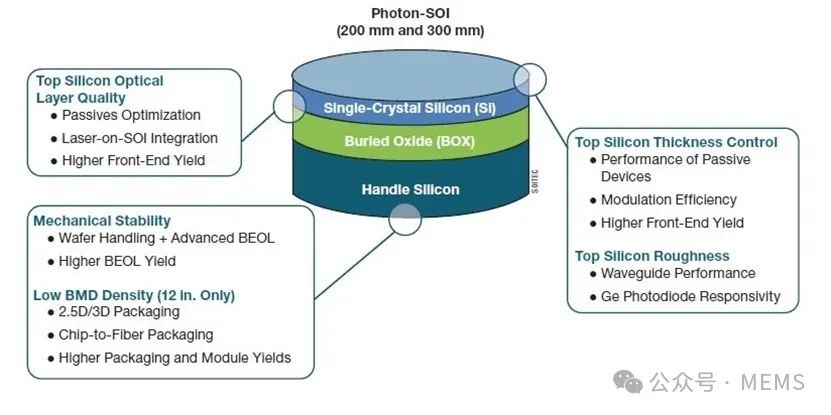
光子SOI衬底结构,以及该技术对硅光子器件、电路及子系统的相应价值主张
这些优势的关键在于提高SOI衬底顶部硅器件层晶圆到晶圆(W2W)和晶圆内(WiW)均匀性和表面粗糙度。此外,块体顶部硅层的整体光学特性(如缺陷、表面状态和作为光散射中心的体微缺陷),对于硅光子元件的最佳良率和性能也非常重要。这还能确保制造出来的器件和电路尽可能接近计算机辅助设计(CAD)工具和图形数据流(GDS)文件中的设计参数。
光损耗是评估衬底材料质量的关键基准,因为它预示着无源器件的整体性能水平以及后续的前端光学良率。随着先进超高速收发器、板载光学器件(特别是CPO)的兴起,元件密度和整体电路复杂性不断提高,衬底材料质量与大面积电路的关系日益密切。
硅光子SOI晶圆直径有200 mm和300 mm两种。更大直径的衬底可以容纳更多的芯片制造,同时能够更严格地控制顶部硅膜厚度的WiW和W2W不均匀性。对于SOITEC的200 mm直径晶圆,目前最先进的顶部硅层厚度WiW不均匀性与前几代产品相比降低了70%以上。此外,顶部硅膜平均厚度W2W变异性也得到了极大改善,从而提高了晶圆级无源光学性能,并在量产时提高了前端良率。
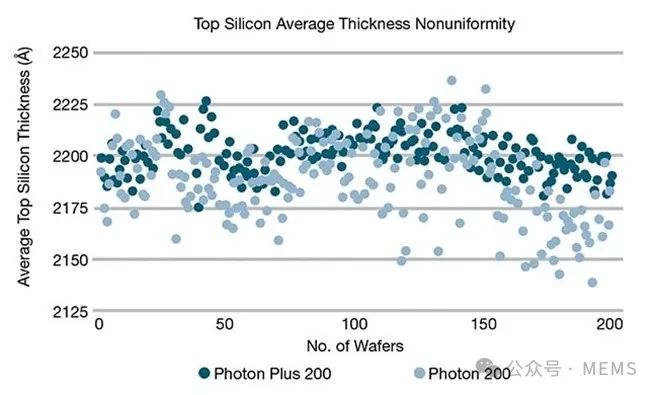
SOITEC两代200 mm SOI晶圆(Photon 200和Photon Plus 200)上测量的顶部硅平均厚度不均匀性。该研究在200多片晶圆上分别采集了17个测量点。厚度测量单位:埃(1/10纳米)。
法国CEA-Leti在其200 mm硅光子工艺设计套件和测试线上进行的光学测试证实了这一趋势。研究数据表明,最先进的SOI技术在硅顶层薄膜不均匀性和缺陷密度方面达到了非常先进的目标。这使得目前的200 mm SOI晶圆能够显著降低损耗(条状波导为1~1.4 dB/cm),并降低晶圆上传播损耗中值的色散(低至0.09 dB/cm)。
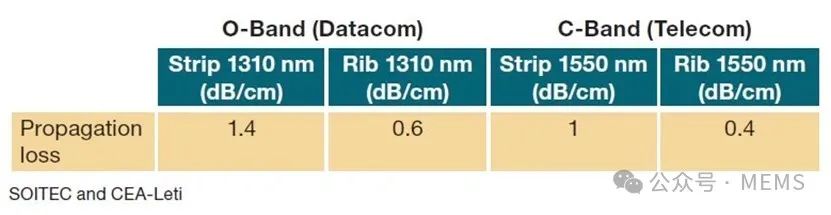
SOITEC Photon/Photon Plus 200的光学性能
应用于300 mm SOI衬底的类似基准测试评估了一家SOITEC商业代工合作伙伴制造的器件。在测试过程中,最先进的SOI晶圆在O波段的单模TE偏振波导损耗介于0.5~0.65 dB/cm。
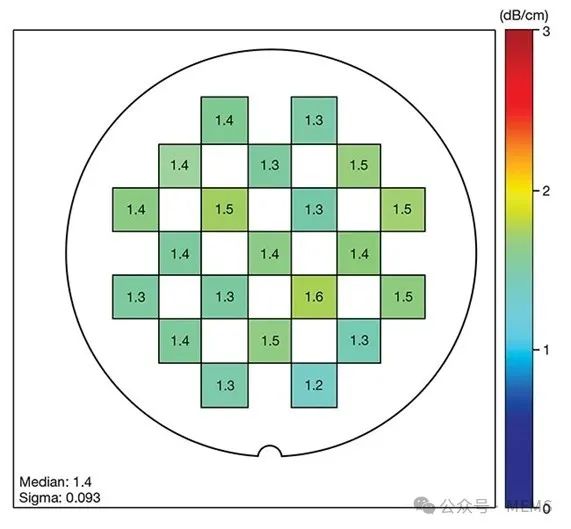
1310 nm波长区域(左)带状、横电(TE)偏振配置的单模波导传播损耗基准(单位:dB/cm)。
面向硅光子应用的先进封装
先进封装和后道(BEOL)技术是推动硅光子路线图发展的关键因素,特别是对于更先进的收发器设计和CPO多芯片模块集成。例如,2.5D和3D CoWoS封装或异构集成方案,对于为日益密集且复杂的硅光子芯粒提供电力以及光纤到芯片的光连接是非常必要的。然而,先进的BEOL和模块封装是目前硅光子技术中的主要良率障碍。
SOI衬底将在应对这些挑战方面发挥另一个重要作用。事实上,从SOI晶圆的操作来看,其潜力远不止支持三层堆叠。先进的SOI加工技术可产生卓越的材料化学物理性能,为新型SOI硅晶圆提供所需要的机械坚固性,使其能够经受激进的热退火循环,以及晶圆代工厂先进硅光子加工中典型的更厚的多层金属BEOL技术。此外,操作晶圆还能使代工厂和设计人员具有足够的灵活性来实施硅通孔(TSV)技术和光纤连接V形槽(或类似的实施方法),从而为光学引擎提供电气和光学互连。
具体来说,在SOI制造过程中,由于热处理的原因,硅中所含的间隙氧往往会在晶核上析出,从而导致体微缺陷的产生。这些缺陷可以充当所谓的“吸杂中心”,吸引潜在的金属污染。此外,还需要这些缺陷来阻止位错的传播,以确保衬底对热应力的机械鲁棒性,从而防止产生膜裂缺陷(也称滑移线)。
然而,用于在硅衬底上创建V形槽或TSV的干法蚀刻也会受到体微缺陷密度的不利影响。体微缺陷会在蚀刻和金属填充过程中造成微掩膜,从而导致缺陷,由于整个芯片上TSV电阻率的变化,有可能给晶圆代工厂带来重大的良率损失。
为了实现新的硅光子技术,某些特定开发有助于SOI晶圆操作衬底提供应对这些挑战所需要的特性。在SOI掩埋氧化层下方创建无体微缺陷区(也称为洁净区)具有双重优势,既能进行无缺陷蚀刻以形成光纤连接V形槽或电气TSV,又能保持SOI衬底在热处理中的鲁棒性。

洁净区操作硅晶圆技术的横截面激光散射断层扫描图像。从洁净区去除体微缺陷,厚度约为100 µm,更低区域仍存在体微缺陷,以保持晶圆的机械性能、正确的几何形状以及对热处理、BEOL和封装处理的整体鲁棒性。
AI的现在与未来
硅光子技术为AI架构提供的光互连有望彻底变革AI算法,并进一步提升这些复杂系统的能力,实现更高效的结构,进而以更高的性能适应日益复杂的工作负载。随着AI网络的内在演进,硅光子技术以及多芯片模块中的异构集成将改变交换层,从而以所需的互连密度和成本实现更低的延迟和功耗。
本文源自SOITEC,麦姆斯咨询编译。
审核编辑:刘清
-
人工智能是什么?2015-09-16 6431
-
人工智能技术—AI2015-10-21 9783
-
人工智能传感技术2016-06-03 35020
-
智能热潮来袭,净水行业的”互联网+“时代2016-09-21 3127
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 8065
-
人工智能成热潮,嵌入式如何分杯羹?2017-09-06 3000
-
人工智能就业前景2018-03-29 8425
-
解读人工智能的未来2018-11-14 4912
-
人工智能技术及算法设计指南2019-02-12 5183
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5881
-
人工智能:超越炒作2019-05-29 5030
-
AI全球格局之人工智能即将变革的三大领域 相关资料分享2021-07-06 2583
-
人工智能芯片是人工智能发展的2021-07-27 6692
-
物联网人工智能是什么?2021-09-09 5344
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2372
全部0条评论

快来发表一下你的评论吧 !
