

基于掩码模型的LiDAR感知模型预训练策略
MEMS/传感技术
描述
本文提出了BEV-MAE,一种高效的3D点云感知模型预训练算法,可直接使用大量的无标记点云数据对感知模型进行预训练从而降低对点云标记的需求。BEV-MAE首先使用鸟瞰图引导的掩码策略来对3D点云输入进行掩码,该部分被掩盖的点云将被替换为共享的可学习令牌。之后被处理过的点云依次输入到3D编码器和轻量级的解码器中,由轻量级的解码器重建被掩盖的点云并预测被掩盖区域的点云密度。BEV-MAE在自动驾驶感知数据集Waymo上以最低的预训练代价取得了最高的3D目标检测精度提升。同时,基于Transfusion-L检测器,BEV-MAE在自动驾驶感知数据集nuScenes上取得了领先的3D点云目标检测结果。
研究背景:
3D目标检测是自动驾驶中最基本的任务之一。近年来,由于标注数据集和数据量的增加,基于激光雷达(LiDAR)的3D目标检测算法取得了显著的成功。然而,现有的基于激光雷达的3D目标检测算法通常采用从头开始训练的范式(training from scratch)。这种范式存在两个显著的缺陷。首先,从头开始训练的范式在很大程度上依赖于大量的标注数据,而对于3D目标检测而言,标注准确的物体包围框和分类标签是需要大量人工参与的,且非常昂贵和耗时的。例如,在KITTI数据集上标注一个物体需要大约114秒。其次,在许多实际应用场景中,自动驾驶车辆在行驶过程中可以生成大量无标注的点云数据,而从头开始训练的范式不能很好地将这部分数据利用起来。
方法部分:
针对该问题,作者研究了一种针对自动驾驶场景的 3D 点云自监督预训练方法,提出了一种名为 BEV-MAE 的鸟瞰图掩码自编码器框架,专门用于预训练自动驾驶场景的 3D 目标检测器。具体流程图如下图所示:
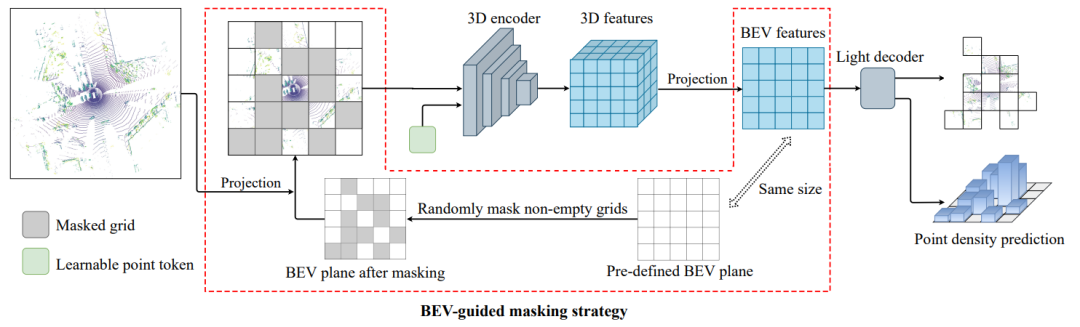
BEV-MAE首先使用鸟瞰图引导的掩码策略来对3D点云输入进行掩码。然后,这部分被掩盖的点云将被替换为共享的可学习令牌。之后,将处理后的点云依次输入到3D编码器和轻量级的解码器中。最后,轻量级的解码器将重建被掩盖的点云并预测被掩盖区域的点云密度。
a、鸟瞰图掩码策略
在基于激光雷达的3D目标检测中,点云通常被划分为规则的体素块。一种简单的掩码策略是像视觉中的补丁掩码一样,对体素化后的点云进行掩码。然而,这种简单的体素掩码策略没有显式地学习自动驾驶中主流的3D目标检测方法中使用的鸟瞰图特征表示。
为此,作者提出了一种鸟瞰图引导的掩码策略对鸟瞰图平面中的点云进行掩码操作。
具体而言,假设点云被编码和转换后鸟瞰图视角中的特征分辨率为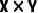 ,首先预定义一个大小为的网格状鸟瞰图平面。然后,根据点云的坐标将每个点云投影到预定义平面的相应鸟瞰图网格中。之后,作者将随机选择一部分非空的鸟瞰图网格作为被掩码的网格,并将其余的鸟瞰图网格视为可见网格。最后将所有投影到可见网格中的点云视为掩码后的点云输入到网络中。
,首先预定义一个大小为的网格状鸟瞰图平面。然后,根据点云的坐标将每个点云投影到预定义平面的相应鸟瞰图网格中。之后,作者将随机选择一部分非空的鸟瞰图网格作为被掩码的网格,并将其余的鸟瞰图网格视为可见网格。最后将所有投影到可见网格中的点云视为掩码后的点云输入到网络中。
b、共享可学习token
常用的基于体素的3D目标检测器的3D编码器通常由多个稀疏卷积操作组成,而稀疏卷积仅会处理非空体素附近的特征,因此,将掩码后的点云作为输入时,3D编码器的感受野将会变小。为了解决这个问题,作者采用一个共享的可学习令牌替换被掩盖的点云。具体来说,作者使用完整点云的坐标作为稀疏卷积的输入索引,并在第一个稀疏卷积层中用共享的可学习令牌替换被掩码点云的特征,同时保持其他稀疏卷积层不变。所提出的共享可学习令牌的唯一目的是将信息从一个点或体素传递到另一个点或体素,以维持感受野大小不变,而不引入任何额外的信息,包括被掩码点的坐标,来降低重建任务的难度。
c、掩码预测任务
所提出的BEV-MAE由两个任务作为监督,即点云重建和密度预测。对于每个任务,都采用独立的线性层作为预测头来预测结果。
对于点云重建,与之前的工作类似,BEV-MAE通过预测被掩码点云的坐标来重建掩码输入。采用chamfer-distance作为训练损失函数。
对于密度预测,不同于图像、语言和室内点云,自动驾驶场景中室外点云的密度具有随离激光雷达传感器越远而越稀疏的特性。因此,密度可以反映每个点或物体的位置信息。而对于目标检测而言,检测器的定位能力至关重要。因此,点云密度预测任务能够一定程度上指导3D编码器获得更好的定位能力。
具体而言,对于每个被掩码的网格,计算此网格中的点云数量,并通过将点云数量除以其在3D空间中的占用体积来得到对应的密度真值。然后,BEV-MAE使用线性层作为预测头来预测密度。密度预测使用Smooth-L1损失来监督此任务。
实验部分:
BEV-MAE主要在两个主流的自动驾驶数据集nuScenes和Waymo上进行实验。
在Waymo上,BEV-MAE以较低的预训练代价,取得了更高的3D目标检测性能提升,如下图所示:
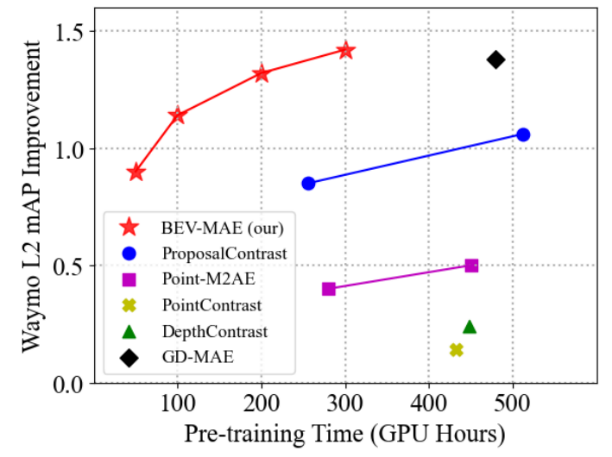
在nuScenes上,以BEV-MAE作为预训练算法,能够进一步提升当前最强点云3D目标检测器的性能。以TransFusion-L作为基础3D检测器,外加BEV-MAE的预训练算法,在nuScenes数据集上取得了先进的单模态点云3D目标检测结果。
结论:
本文针对点云预训练问题,提出了BEV-MAE,一种基于掩码模型的LiDAR感知模型预训练策略,在预训练效率和性能上表现出色,可缓解LiDAR感知模型对标记数据的需求。
审核编辑:黄飞
-
大语言模型的预训练2024-07-11 1939
-
预训练模型的基本原理和应用2024-07-03 6073
-
【大语言模型:原理与工程实践】大语言模型的预训练2024-05-07 1572
-
什么是预训练AI模型?2023-05-25 2218
-
什么是预训练 AI 模型?2023-04-04 2717
-
预训练数据大小对于预训练模型的影响2023-03-03 2665
-
使用 NVIDIA TAO 工具套件和预训练模型加快 AI 开发2022-12-15 2287
-
利用视觉语言模型对检测器进行预训练2022-08-08 2456
-
一种基于乱序语言模型的预训练模型-PERT2022-05-10 2618
-
如何实现更绿色、经济的NLP预训练模型迁移2022-03-21 3196
-
2021 OPPO开发者大会:NLP预训练大模型2021-10-27 2348
-
基于预训练模型和长短期记忆网络的深度学习模型2021-04-20 1414
-
小米在预训练模型的探索与优化2020-12-31 4078
-
字符感知预训练模型CharBERT2020-11-27 2756
全部0条评论

快来发表一下你的评论吧 !
