

Nvidia AI芯片GPU架构路线图分析与解读
处理器/DSP
描述
Nvidia AI芯片路线图分析与解读、Nvidia芯片工艺洞察和推演、Nvidia AI芯片架构分析。 基于以下两个前提:每一代AI芯片的存储、计算和互联比例保持大致一致,且比上一代提升1.5到2倍以上;工程工艺演进是渐进且可预测的,不存在跳变,至少在2025年之前不会发生跳变。因此,可以对2023年的H100、2024年的B100和2025年的X100的架构进行推演总结。
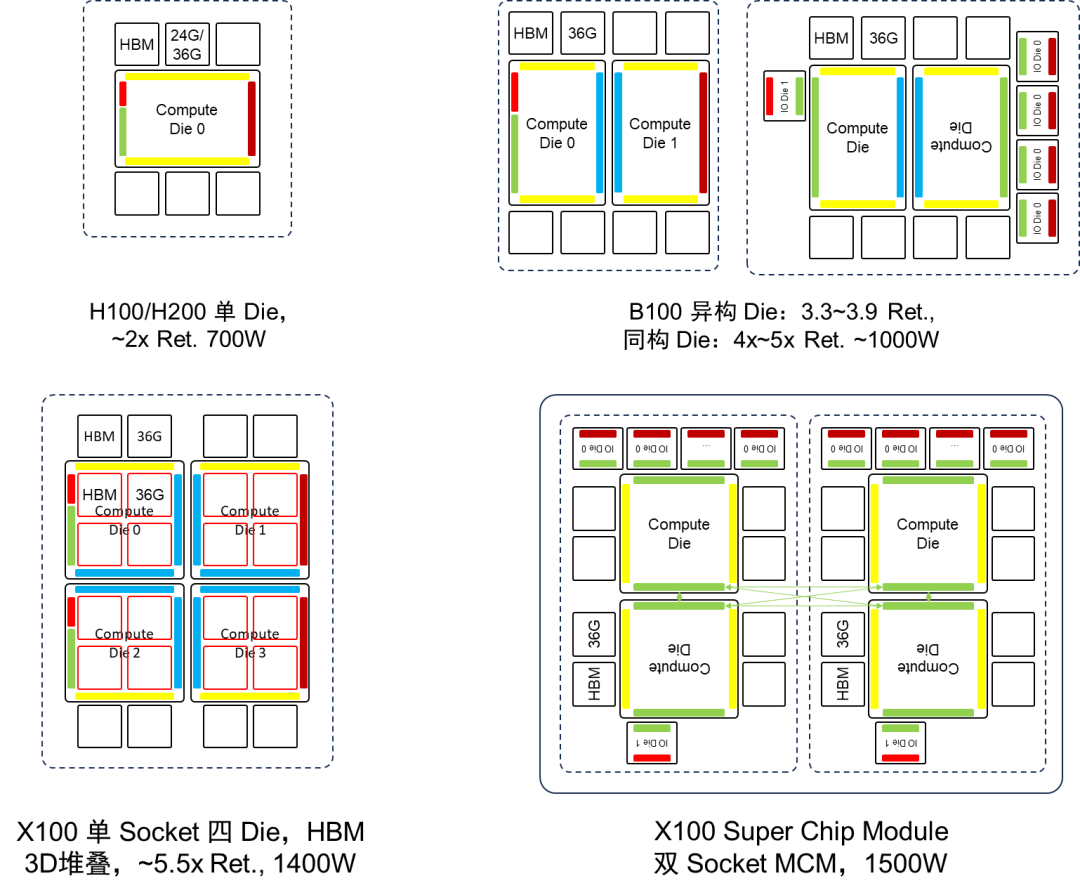
对于工程工艺的基本假设如下:到2025年,工艺将保持在3nm水平,但工艺演进给逻辑器件带来的收益预计不会超过50%。同时,先进封装技术预计将在2025年达到6倍 Reticle面积的水平。此外,HBM内存容量也将继续增长,预计在2024年将达到24GB,而在2025年将达到36GB。 在上述前提假设条件下,针对H100/H200, B100, X100 GPU可以得到如下推演结论:
1. H200是基于H100的基础上从HBM3升级到HBM3e,提升了内存的容量和带宽。
2. B100将采用双Die架构。如果采用异构Die合封方式,封装基板面积将小于当前先进封装4倍Reticle面积的约束。而如果采用计算Die和IO Die分离,同构计算Die和IO Die合封的方式,封装基板面积将超出当前先进封装4倍Reticle面积的约束。如果采用计算Die和IO Die分离,同构计算Die和IO Die分开封装的方式,则可以满足当前的工程工艺约束。考虑到B100 2024年推出的节奏,以及计算Die在整个GPU芯片中的成本占比并不高,因此用异构Die合封方式的可能性较大。
3. 如果X100采用单Socket封装,四个异构Die合封装的方式,需要在计算Die上堆叠HBM,同时需要先进封装的基板达到6倍Reticle面积。但是,如果采用SuperChip超级芯片的方式组成双Socket封装模组,可以避免计算Die上堆叠HBM,并放松对先进封装基板面积的要求,此时需要对NVLink C2C的驱动能力做增强。
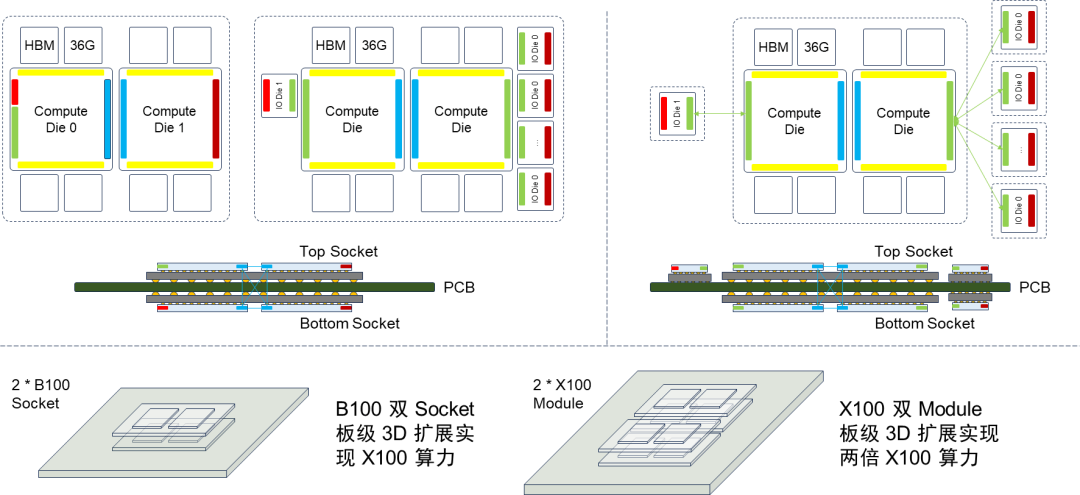
基于B100双Die架构,采用双Socket板级3D扩展可以实现与X100同等的算力。类似的方法也可以应用到X100中进一步扩展算力。板级扩展可以降低对工程工艺的要求,以较低的成本实现算力扩展。虽然基于人们对于先进封装的Chiplet芯粒架构充满了期待,但是其演进速度显然无法满足AI计算系统“三年三个数量级”的增长需求 [33]。在AI计算领域基于先进封装Die间互联Chiplet芯粒架构,很可能因为无法满足AI计算领域快速增长的需求而面临“二世而亡”的窘境,业界需要重新寻找旨在提升AI算力的新技术路径,比如SuperChip超级芯片和SuperPOD超节点。因此,类似于NVLink C2C的低时延、高可靠、高密度的芯片间互联技术在未来AI计算芯片的Scale Up算力扩展中将起到至关重要的作用;面向AI集群Scale Out算力扩展的互联技术也同等重要。这两中互联技术,前者是AI计算芯片算力扩展的基础,而后者是AI计算集群算力扩展的基础。
总结与思考
本文尝试从第一性原理出发,对Nvidia的AI芯片发展路线进行了深入分析和解读,并对未来的B100和X100芯片架构进行了推演预测。并且,希望通过这种推演提取出未来AI计算系统对互联技术的新需求。 本文以互联技术为主线展开推演分析,同时考虑了芯片代际演进的性能提升需求和工程工艺约束。最终得出的结论是:在AI计算领域,基于先进封装Die间互联的Chiplet芯粒架构无法满足AI计算领域快速增长的需求,可能面临“二世而亡”的窘境。低时延、高可靠、高密度的芯片间互联技术在未来AI计算芯片的Scale Up算力扩展中将起到至关重要的作用;虽然未展开讨论,同样的结论也适用于面向AI集群Scale Out算力扩展的互联技术。224G及以上代际中,面向计算集群的互联技术也存在非常大的挑战。需要明确指出的是,互联技术并不是简单地将芯片、盒子、机框连接起来的问题,它并不是一根连线而已,它需要在需求、技术、产业生态等各个方面进行综合考虑,需要极具系统性的创新以及长时间的、坚持不懈的投入和努力。
除了互联技术以外,通过对Nvidia相关技术布局的分析也引发了如下思考:
1. 真正的差异化竞争力源于系统性地、全面地掌握整个价值链中主导无法快速复制的关键环节。Nvidia在系统和网络、硬件、软件这三个方面占据了主导地位,而这三个方面恰恰是人工智能价值链中许多大型参与者无法有效或快速复制的重要部分。然而,要在这三个方面中的任何一方面建立领导地位都离不开长时间坚持不懈的投入和努力带来的技术沉淀和积累。指望在一个技术单点形成突破,期望形成技术壁垒或者技术护城河的可能性为零。“重要且无法快速复制”是核心特征,其中“重要”更容易被理解,而“无法快速复制”则意味着“长时间坚持不懈的投入和努力”带来的沉淀和积累,这是人们往往忽视的因素。
2. 开放的产业生态并不等同于技术先进性和竞争力。只有深入洞察特定领域的需求,进行技术深耕,做出差异化竞争力,才能给客户带来高价值,给自身带来高利润。Nvidia基于NVLink C2C的SuperChip超级芯片以及基于NVLink网络的SuperPOD超节点就是很好的例子。真正构筑核心竞争力的技术是不会开放的,至少在有高溢价的早期不会开放,比如Nvidia的NVLink和NVLink C2C技术,比如Intel的QPI和UPI。开放生态只是后来者用来追赶强者的借口(比如UEC),同时也是强者用来巩固自己地位的工具(比如PCIE)。然而,真正的强者并不会仅仅满足于开放生态所带来的优势,而是会通过细分领域和构筑特定领域的封闭生态,实现差异化竞争力来保持领先地位。
3. 构筑特定领域的差异化竞争力与复用开放的产业生态并不矛盾。其关键在于要在开放的产业生态中找到真正的结合点,并能够果断地做出取舍,勇敢地抛弃不必要的负担,只选择开放产业生态中的精华部分,构建全新的技术体系。为了构筑特定领域的差异化竞争力,更应该积极拥抱开放的产业生态,主动引导其发展以实现这种差异化。比如,InfiniBand与Ethernet在低时延方面的差异化并不是天生的,而是人为构造出来的。两者在基础技术上是相同的。InfiniBand在25G NRZ代际以前抓住了低时延这一核心特征,摒弃跨速率代际兼容的需求,卸掉了技术包袱,并且在HPC领域找到了合适的战场,因此在低时延指标上一直碾压Ethernet,成功实现了高品牌溢价。而InfiniBand在56G PAM4这一代际承袭了Ethernet的互联规范,因此这种低时延上的竞争力就逐渐丧失了。人为制造差异化竞争力的典型例子还有:同时兼容支持InfiniBand和Ethernet的CX系列网卡和BlueField系列DPU;内置在NVSwitch和InfiniBand交换机中的SHARP在网计算协议和技术;Nvidia基于NVLink C2C构筑SuperChip超级芯片以及基于NVLink网络构筑SuperPOD超节点。
4. “天下没有免费的午餐”,这是恒古不变的真理和底层的商业逻辑。商业模式中的“羊毛出在狗身上,由猪买单”其实就是变相的转移支付,羊毛终将是出在羊身上,只是更加隐蔽罢了。这一规律同样适用于对复杂系统中的技术价值的判断上。自媒体分析H100的BOM物料成本除以售价得到90%的毛利率是片面的,因为高价值部分是H100背后的系统竞争力,而不仅仅是那颗眼镜片大小的硅片。这里包含了H100背后的海量的研发投入和技术积累。而隐藏在这背后的实际上是人才。如何对中长期赛道上耕耘的人提供既紧张又轻松的研究环境,使研究人员能安心与具有长期深远影响的技术研究,是研究团队面临的挑战和需要长期思考的课题。从公开发表的D2D和C2C相关文献中可以看到,Nvidia在这一领域的研究投入超过十年,针对C2C互联这一场景的研究工作也超过五年。在五到十年的维度上长期进行迭代研究,需要相当强的战略定力,同时也需要非常宽松的研究环境和持续的研究投入。
5. 在人工智能时代,通过信息不对称来获取差异化竞争力或获得收益的可能性越来越低。这是因为制造信息不对称的难度和代价不断飙升,而其所带来的收益却逐渐减少。在不久的未来,制造信息不对称的代价将会远远超过收益。妄图通过垄断信息而达到差异化的竞争力,浪费的是时间,而失去的是机会。随着大模型的进一步演进发展,普通人可以通过人工智能技术轻松地获取并加工海量的信息且不会被淹没。未来的核心竞争力是如何驾驭包括人工智能在内的工具,对未来技术走向给出正确的判断。
6. Nvidia并非不可战胜,在激进的技术路标背后也隐藏着巨大的风险。如何向资本证明其在AI计算领域的能够长期维持统治地位,保持长期的盈利能力,以维持其高股价、实现持续高速增长,极具挑战性。一旦2025年发布的X100及其配套关键技术不及预期,这将直接影响投资者的信心。这是Nvidia必须面临的资本世界的考验,在这一点上它并没有制度优势。在一些基础技术层面,业界面临的挑战是一样的。以互联技术为例,用于AI计算芯片Scale Up算力扩展的C2C互联技术,以及面向AI集群Scale Out算力扩展的光电互联技术都存在非常大的挑战。谁能在未来互联技术演进的探索中,快速试错,最快地找到最佳路径,少犯错误,谁就抓住了先机。在未来的竞争中有可能实现超越。
作者:陆玉春
审核编辑:黄飞
-
深度解读Nvidia AI芯片路线图2024-03-13 2421
-
嵌入式Linux_Android的学习路线图2023-09-27 844
-
有关芯片光刻路线图的一些知识分享2022-07-10 4824
-
Rockchip处理器路线图及芯片选型2021-06-02 1695
-
嵌入式软件学习的路线图2021-02-04 2400
-
Intel公布2021年CPU架构路线图及封装技术2020-11-02 2585
-
物联网学习路线图2020-04-20 3903
-
嵌入式学习路线图分享2018-07-13 2949
-
韦东山嵌入式Linux+Android学习路线图 pdf 下载2017-09-18 79774
-
NVIDIA火热招聘GPU高性能计算架构师2017-09-01 5197
-
求STM32的成长路线图2015-05-12 2690
-
嵌入式学习指导路线图2013-08-15 21596
-
靠谱不?分析师自制苹果2013年产品路线图2013-01-19 3258
-
嵌入式学习路线图2012-08-16 40642
全部0条评论

快来发表一下你的评论吧 !
