

基于毫米波雷达和多视角相机鸟瞰图融合的3D感知方法
MEMS/传感技术
描述
本文介绍了来自北京大学王选计算机研究所的王勇涛团队与其合作者的最新研究成果RCBEVDet。针对自动驾驶场景,该篇工作提出了一个基于毫米波雷达和环视相机鸟瞰图(BEV)特征融合的3D目标检测模型架构RCBEVDet,在显著提升3D目标检测精度的同时可保持实时的推理速度,且对模态信号丢失、干扰等情况鲁棒,论文已被CVPR 2024录用。
论文概述:
本文提出了一个基于毫米波雷达和环视相机鸟瞰图(BEV)特征融合的3D目标检测模型架构RCBEVDet。该架构针对毫米波雷达的特性设计了一种高效的毫米波雷达主干网络(RadarBEVNet)进行点云鸟瞰图特征提取,提出了一种基于可形变的跨注意力机制进行毫米波雷达特征和环视相机特征融合。该架构对现有主流的环视相机3D检测器具有较强的兼容性,在显著提升3D目标检测精度的同时可保持实时的推理速度,且对模态信号丢失、干扰等情况鲁棒。同时,该架构在自动驾驶感知数据集nuScenes上取得了领先的毫米波雷达-多摄相机3D目标检测精度以及推理速度-精度综合性能。
研究背景:
近期,研究者们关注于使用经济且高效的多视角相机进行自动驾驶场景的3D目标检测。多视角相机能够捕捉物体的颜色和纹理信息,同时提供高分辨率的语义信息。然而,仅依赖单独的多视角相机难以实现高精度且鲁棒的3D目标检测。例如,多视角相机难以提供准确的深度信息,且图像质量受天气和光照的影响较大。为了提升智能驾驶系统的安全性和鲁棒性,智能驾驶车辆通常采用多种模态的传感器获取场景信息进行感知,如环视相机、激光雷达、毫米波雷达等。毫米波雷达是一种经济实惠的常用传感器,能够提供较为准确的深度信息和速度信息,并且能够在各种天气和光照条件下给出高质量毫米波点云。因此,使用毫米波雷达-环视相机多模态组合感知方案具有优秀的感知能力和较高的性价比,受到了现在很多研究人员和车厂的青睐。但是,由于4D毫米波雷达和环视相机模态间的巨大差异,如何融合这两种模态信息高精度且鲁棒地完成智能驾驶感知任务(如3D目标检测)具有非常大的技术挑战性。
方法部分:
作者提出了RCBEVDet,一种基于毫米波雷达和多视角相机鸟瞰图融合的3D感知方法,以实现高精度、高鲁棒性的自动驾驶多模态3D感知。具体架构如下图所示:
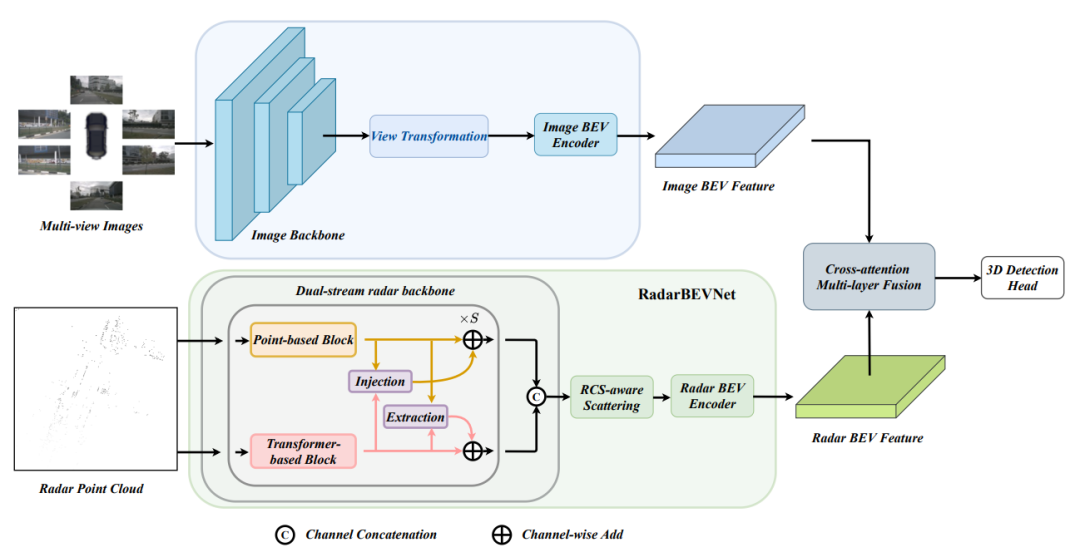
图1 RCBEVDet架构图
RCBEVDet针对毫米波雷达的特性,设计了一种高效的毫米波雷达主干网络(RadarBEVNet),进行点云鸟瞰图特征提取,RadarBEVNet使用两种特征表征方式对毫米波雷达点云进行特征表示,并使用基于雷达反射截面(RCS)的离散方法得到鸟瞰图特征。此外,该方法还提出了一种基于可形变的跨注意力机制进行毫米波雷达特征和多视角相机鸟瞰图特征进行鲁棒和高效的融合,从而提高自动驾驶的3D感知任务的性能和多模态鲁棒性。
1、RadarBEVNet
给定输入的毫米波雷达点云,RadarBEVNet采用point-based和transformer-based两种表征形式对点云进行特征提取,point-based提取器将针对毫米波雷达点云提取局部点云特征,而transformer-based的模块则针对毫米波雷达点云提取全局点云特征。同时两种特征表示通过injection和extraction模块进行特征关联,将局部特征和全局特征进行交互,得到更加全面的毫米波雷达点云特征。
a、两种特征表征方式
两种特征表征的提取器如下图所示:
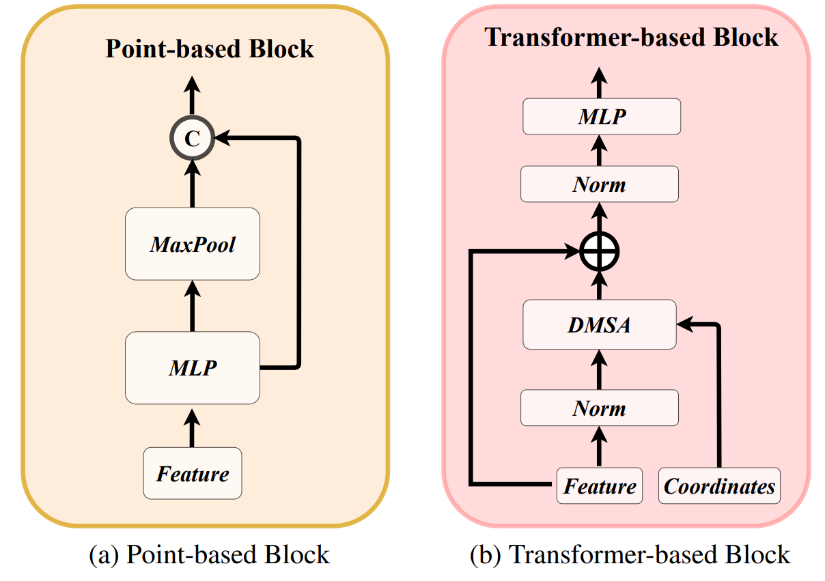
图 2 两种特征表征的提取器
point-based表征的架构采用扁平化设计思路,由多层感知机和最大值池化层组成,毫米波点云特征首先被输入到多层感知机进行特征升维,得到高维的点云特征,之后通过最大值池化模块提取全局的点云特征,并将该全局特征与高维点云特征进行通道连接,得到最终的点云特征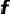 。
。
Transformer-based表征的架构由三个阶段组成,每个阶段是一个标准的Trasnformer块,由一个注意力机制、一个前向网络和归一化层组成。其中,为了提升模型的收敛性,作者采用了距离调制的注意力机制(Distance-Modulated Self-Attention)。具体而言,给定N个毫米波雷达点云的坐标,首先计算点与点之间的距离矩阵D。之后,根据距离矩阵D生成高斯权重图G,G可以表示为
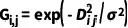
其中 表示可学习参数,可以用来控制高斯分布的带宽。本质上,高斯权重图G会将更大的权重放置在局部区域,将更小的权重给那些远离当前点云的点。给定高斯权重图之后,采用下述公式对自注意力机制进行调制:
表示可学习参数,可以用来控制高斯分布的带宽。本质上,高斯权重图G会将更大的权重放置在局部区域,将更小的权重给那些远离当前点云的点。给定高斯权重图之后,采用下述公式对自注意力机制进行调制:
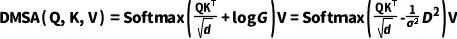
为了保证在训练过程中,基于距离调制的自注意力机制能够退化回常规的自注意力机制,采用b替代1/。当b=0时,基于距离调制的自注意力机制退化回常规的自注意力机制。
b、injection和extraction模块
两种特征表示的每个block中,使用injection和extraction模块进行两个特征的融合和交互。具体而言,来自point-based的第i个block的特征为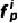 ,来自transformer-based的第i个block的特征为
,来自transformer-based的第i个block的特征为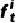 。在injection模块中,将设为query,视为key为value,采用多头跨注意力机制将来transformer-based的特征注入到中。
。在injection模块中,将设为query,视为key为value,采用多头跨注意力机制将来transformer-based的特征注入到中。
类似的,extraction模块采用跨注意力机制将point-based特征抽取出来,并传入transformer-based的block中。两者的架构具体如下所示:
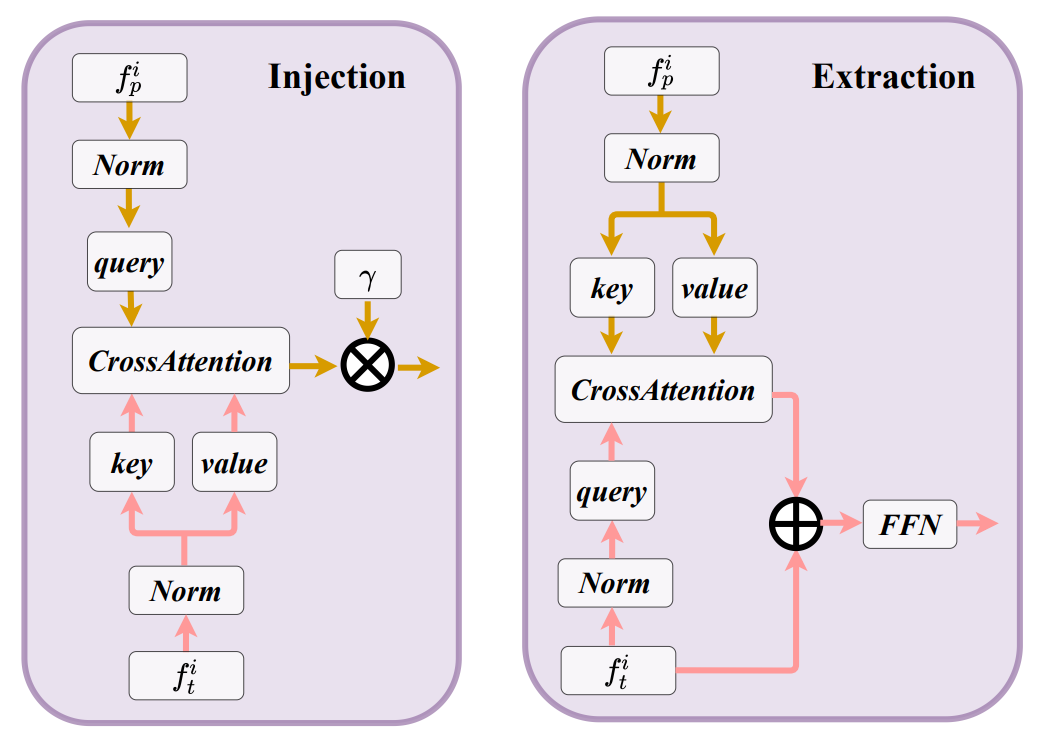
图3 injection和extraction模块架构图
2、基于雷达反射截面(RCS)的离散方法
RCS是毫米波雷达特有的特征,它是用来反映一个物体可检测性的指标。相同条件下(材料、形状),较大的物体会产生较强的毫米波雷达反射响度,从而使毫米波雷达传感器获得较强的雷达反射截面。因此,雷达反射截面能够在一定程度上反映出物体的大小。基于RCS引导的体素离散化操作将雷达反射截面作为物体大小的先验知识,从而能够使得一个毫米波雷达点云被离散化到多个体素栅格上,提高毫米波雷达特征的稠密程度,使后续的特征聚集变得更加简单。如下图所示:
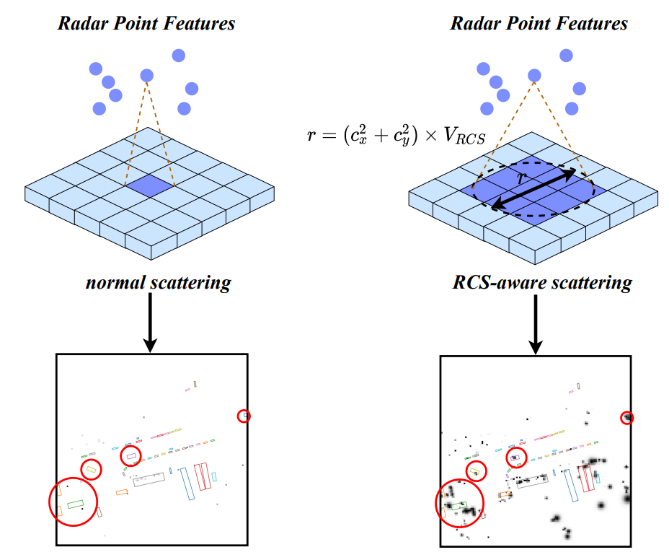
图4 基于RCS的离散方式示意图
3、可形变的跨注意力机制融合模块
毫米波雷达点云会偏离其真实位置,因此作者采用可形变跨注意力机制来动态学习这种位置偏置,提高融合的鲁棒性,如下图所示。同时,采用可形变跨注意力机制能够将普通的跨注意力机制的计算复杂度从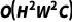 降低到
降低到 ,提高融合的效率。其中H和W分别表示体素的长和宽,C表示特征体素的通道数,K表示可形变跨注意力机制中的参考点数量。
,提高融合的效率。其中H和W分别表示体素的长和宽,C表示特征体素的通道数,K表示可形变跨注意力机制中的参考点数量。
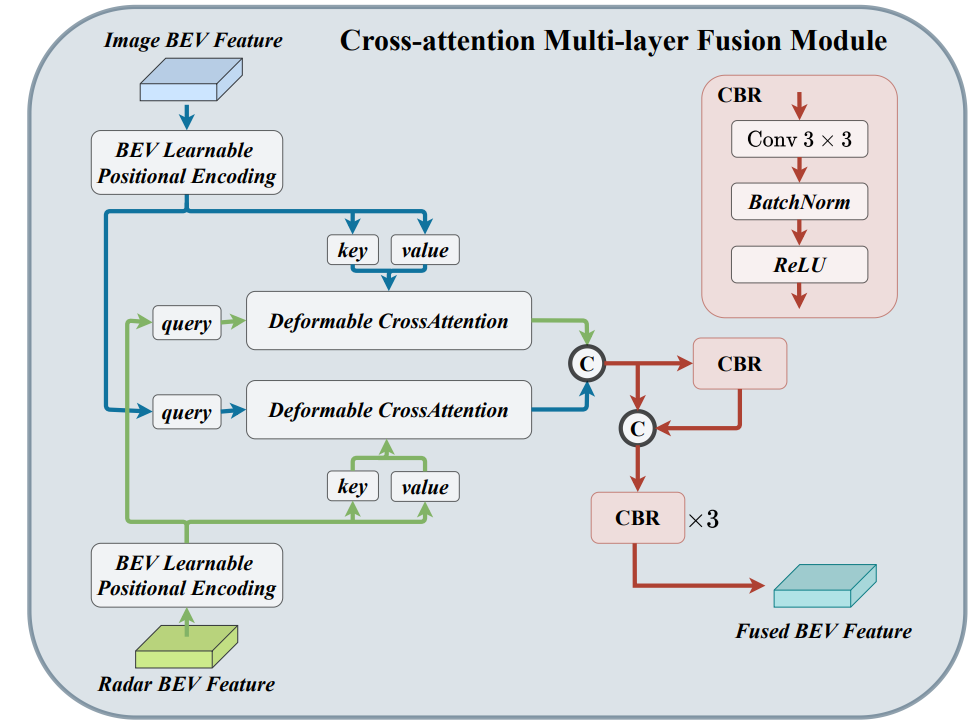
图5 可形变的跨注意力机制融合模块架构图
实验部分:
RCBEVDet主要在多模态自动驾驶数据集nuScenes上进行实验。以BEVDepth为基础模型,RCBEVDet在增加少量推理时延的情况下(仍保证实时推理速度),能够大幅度稳定提升3D检测的性能,同时实现最优的速度-精度权衡,如下所示:
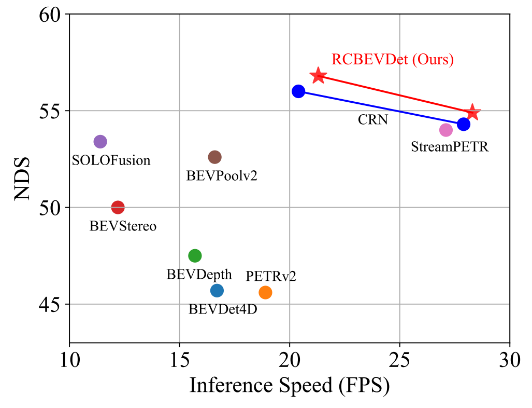
图6 速度-精度权衡图
在nuScenes验证集上,作者验证了RCBEVDet在不同backbone和image size的性能,如下表所示,RCBEVDet在各个设置下相比于之前的方法都有明显提升。
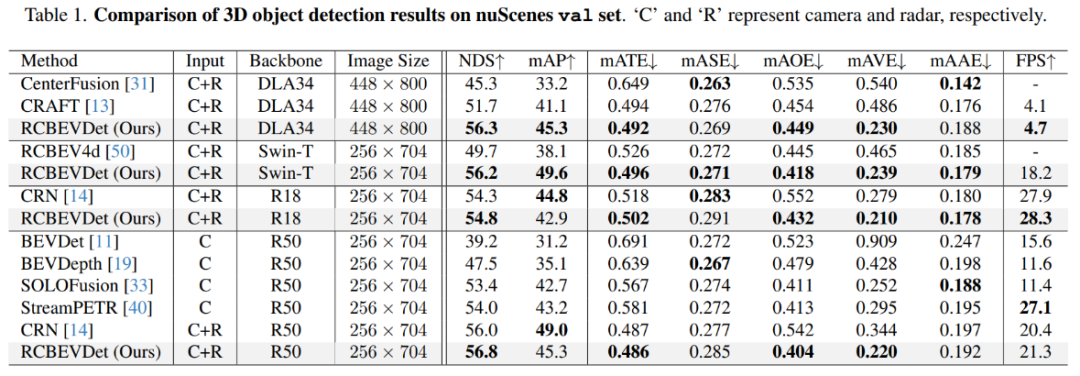
图7 nuScenes验证集结果
在nuScenes测试集上,增加Radar输入后,相比于相机基准模型BEVDepth,RCBEVDet提升了3.4 NDS,实现了63.9 NDS的性能。值得注意的是,RCBEVDet能够非常方便地与现有的其他高精度多视角相机检测器(例如streamPETR)相结合,实现更高精度的3D检测结果。
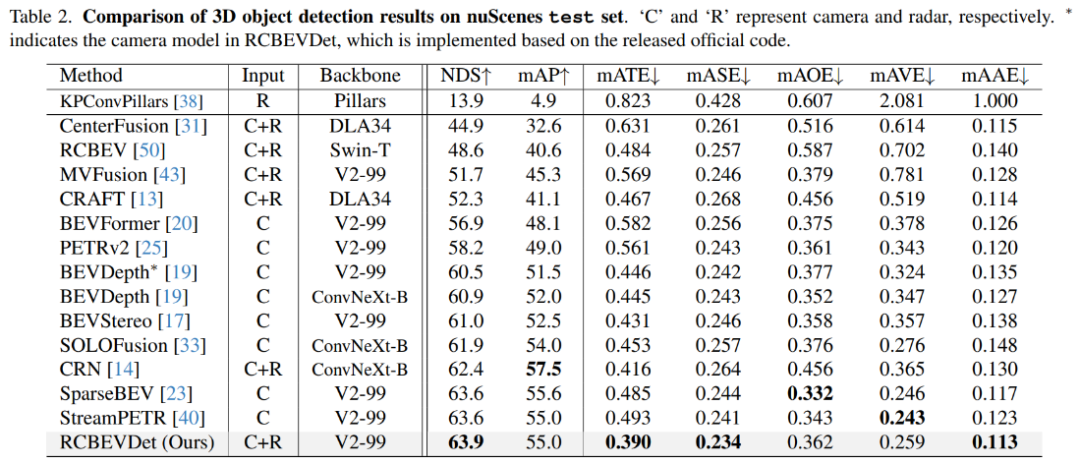
图8 nuScenes测试集结果
此外,作者模拟随机丢失传感器的情况,将部分传感器(相机或者毫米波雷达)的输入设为空,来验证RCBEVDet的鲁棒性,具体结果如下所示
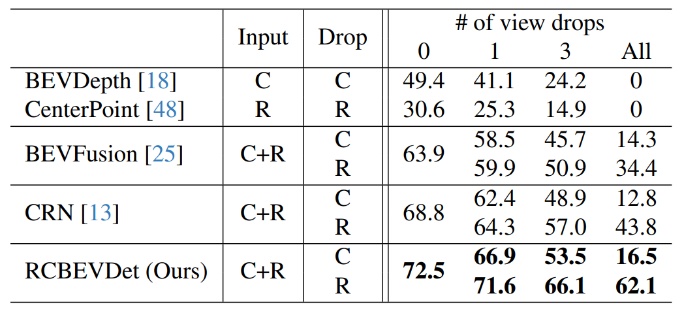
图9 鲁棒性验证
RCBEVDet对相机和毫米波雷达的缺失均表现出较强的鲁棒性。
结论:
本文提出了RCBEVDet,一个基于毫米波雷达和环视相机鸟瞰图(BEV)特征融合的3D目标检测模型架构,在显著提升3D目标检测精度的同时可保持实时的推理速度,且具有较强鲁棒性。
审核编辑:黄飞
-
低速移动无人平台为什么需要毫米波雷达?2019-07-18 9156
-
多毫米波雷达的实车连续测量应用案例2025-06-05 3147
-
毫米波雷达方案对比2018-08-04 12481
-
车载毫米波雷达的技术原理与发展2019-05-10 6203
-
浅析车载毫米波雷达2019-09-19 6957
-
毫米波雷达(一)2019-12-16 14992
-
毫米波雷达感知技术搭建车路协同系统的可行性2020-07-01 9437
-
求大佬分享一种基于毫米波雷达和机器视觉的前方车辆检测方法2021-06-10 2258
-
漫谈车载毫米波雷达历史2022-03-09 12074
-
ADAS系统无人驾驶的眼睛毫米波雷达2023-04-18 2318
-
毫米波雷达智能感知方案2023-02-27 1797
-
基于纯视觉的感知方法2023-06-15 2257
-
对比ZF和特斯拉的4D毫米波雷达设计,国产4D毫米波雷达迅速崛起2023-07-07 3241
-
基于Transformer的相机-毫米波雷达融合3D目标检测方法2023-07-10 4367
-
从3D到4D,毫米波雷达升级了哪里?2026-06-15 126
全部0条评论

快来发表一下你的评论吧 !
