

 围剿Kimi,只是大模型“新赛季”play的一环
围剿Kimi,只是大模型“新赛季”play的一环
描述
大模型巨头“围剿”Kimi的战役,已经进行了一段时间了。想必读者们已经从Kimi带来的震撼中冷静下来,开始理性审视2024的大模型“新赛季”。
毫无疑问,“卷”长文本,是基础通用大模型在新赛季的首个赛点。3月18日,月之暗面宣布Kimi智能助手支持200万字超长无损上下文,并开启内测。200万字是什么概念呢?《红楼梦》等古典名著、企业财报等专业文献,Kimi都能“手拿把掐”,展现出了极强的理解分析能力。

打擂台容易守擂难。Kimi这位新秀的亮相固然惊艳,但其他更早问世的TOP级基础大模型,也都不是吃素的,很快百度文心一言、阿里通义千问,都宣布跟进长文本能力,直接卷到1000万字。
Kimi突如其来的热度、巨头的积极反扑、长文本赛事的狂飙,无不说明基础大模型已经进入了新赛段。
Kimi不是来终结比赛的,而是来加入这个家的。而去年仓促备战、紧跟ChatGPT的第一梯队厂商,如今也对大模型的商业化前景、落地方向等,有了更成熟的思考。
Kimi掀起的“长文本之战”,只是大模型“新赛季”paly中的一环,接下来还会有哪些看点,我们来预测一下。
Kimi,终结不了比赛
月之暗面(Moonshot AI)是大模型赛道上,第一波获得较大规模融资的明星创业公司。而相比同时期动作不断的AI大厂如BAT、明星企业如百川,月之暗面直到去年10月才交出了第一份成绩单Kimi,颇有种“谋定而后动”的味道。

从参数上看,Kimi的长文本能力超越了当时的谷歌gemini 1.5、Claude3,处于全球领先水平。
从市场动作看,Kimi的宣传,也不像其他基础通用大模型厂商那样谨慎,而是大规模投流,广告铺天盖地,在B站、抖音、小红书等平台都有信息流投放。据媒体报道,Kimi每天获客成本都在20万,正在“烧钱换规模”。
从实际效果看,有大量个人用户和企业开发者在使用Kimi后表示,其在中文上的理解、分析、问答能力,确实优于当时主流的国产大模型,上下文衔接更好,总结能力更强。
几重因素叠加,升级后的Kimi引爆了资本市场的新一波热情,甚至出现了“Kimi概念股”。
那么,Kimi能“乱拳打死老师傅”,一举终结基础大模型的比赛吗?子弹飞了这么久,结果已经很明显了,不能。
一方面,随着用户规模的增多、应用场景和用例的增加,Kimi的能力局限越来越多地暴露出来,比如有用户提到,Kimi的编程能力跟ChatGPT、GLM4、文心一言有很大的差距,ToC场景下长文本处理的需求并不高频,新鲜感过了之后,感觉没有其他太大用处。
同时,Kimi视为核心差异化优势的长文本能力,并不构成真正的护城河。从其他巨头很快就跟进并上线了相关能力,就可以看出,长文本处理技术的壁垒并没有很高,能做基础通用大模型的头部厂商,都有相关技术和人才积累。
而过去一年AI大厂在多模态大模型、智算基础设施、ToC应用、Tob客情关系等多个维度构筑起的壁垒,则是月之暗面很难快速追赶的。比如,目前月之暗面还没有发布多模态大模型,云服务运维跟不上,难以保证B端用户的体验。
目前Kimi面向大众免费试用,但其付费API的定价,有的版本几乎达到了GPT-3.5等领先大模型的数倍,后续付费转化也要打一个问号。
总的来说,Kimi是月之暗面在大模型技术上的一次成功“秀肌肉”,但别说直接终结比赛,要跻身“可规模落地大模型”这一赛道的TOP席位,恐怕为时尚早。
新赛季,“遭遇战”告一段落
有读者可能会问,既然大厂有做长文本处理的能力,为什么去年不卷,非要Kimi火了之后才卷?
所以说,Kimi爆火是一个很好的契机,标志着中国大模型已经从仓促备战的“遭遇战”,进入到了步步为营的“阵地战”。
简单来说,2023年ChatGPT横空出世,中国的AI大厂是在猝不及防的情况下,极短的时间内统筹资源、组织人马,快速跟上OpenAI的技术进展,一度出现了“大模型日抛”的局面。这时候最重要的是争取主动,避免中国AI在大模型浪潮中缺席。文心一言、讯飞星火、腾讯混元、华为盘古、百川智能、智谱AI等一大批基础大模型厂商和初创机构,确实让中国在“遭遇战”中拿下一城。
狂奔一年,无论海内外都对大模型有了更清晰,也更务实的认知。中国的基础大模型厂商,已经开始“高筑墙、广积粮”,逐步进入到充分准备、保障严密、战略稳定的“阵地战”了。
为什么之前不卷长文本,Kimi出现又快速集体围剿?恰恰是新赛季“阵地战”开始的信号。
信号一,不打没意义的仗。
国内基础大模型的竞争基本告一段落了。
随着Sora、Claude3等开源或闭源大模型都越来越强大,基础通用大模型的投入门槛也更加高昂,不能长期拿出天文数字来卷的都心生退意,转而去挖掘垂直场景和细分行业的机会,这也让头部厂商的认知度和市场认可度更加稳固。
基础大模型厂商也开始精打细算,关注如何从硬件中压榨出更多算力、降低单位推理成本、构建可持续的国产算力、挖掘商业化项目潜力等。而长文本处理要消耗大量的硬件资源,平白无故瞎卷,烧钱费力还未必讨好,确实没必要。
但Kimi的爆火,更多是让ToB场景,尤其是金融、政务客户,看到了大模型的应用价值,读财报、读合同、做客服,更长的文本确实能在这类知识密集型场景,发挥出更好的效果,减少幻觉问题。这代表了基础模型的底层能力,所以Kimi的长文本之战,必须打。
信号二,竞争更加立体复杂
2023年末,大模型热度已经开始降温。应用侧落地困难,所谓的杀手级AI应用似乎还是没有出现,而投入成本持续加码,基础模型一升级就会覆盖创业者的工作,导致投资市场态度也偏向谨慎。于是,很多人开始质疑这一波大模型只是自嗨,唯一赚钱的只有卖铲子的英伟达,焦虑情绪开始弥漫。
这时候,Kimi作为一款现象级产品,确实打破了僵局。
作为一个有实际意义的应用层产品,Kimi让大众再一次感受并认可了大模型的价值。根据产业规律,应用爆发往往会在产业基础平台条件具备之后的一两年内出现,Kimi正处于这一时间轴的关节上,标志着AI应用爆发即将开始。
Kimi对大模型价值的再度确认,也会让接下来的通用大模型竞争,从卷参数、卷benchmark等基础项PK,进入到更加复杂、多元的能力角斗。
信号三,跑马圈地白热化。
这一竞争阶段,“遭遇战”时的灵活、机动、大干快上,就不太管用了,而需要细致部署、步步为营,跑马圈地。
对Kimi的围剿说明各家基础大模型厂商的底层能力,会很快趋同。除非像OpenAI那样,技术的飞轮效应极强,跟竞争对手的差距越拉越大,否则,技术天然会扩散,很难长期成为商业秘密与护城河。
坏消息是,国内的基础大模型,想要建立差异化优势越来越难,没有人能获得垄断地位;好消息是,政企客户更希望构建“模型花园”,根据需要调用多个大模型,减少对单一供应商的依赖,所以市场仍在增长,仍然开放,大家都还有机会。
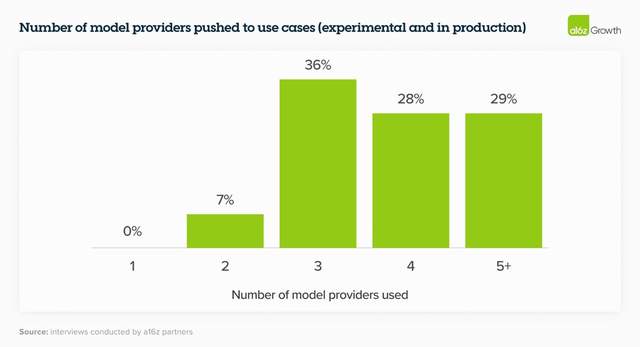
(企业希望引入的模型数量)
a16z调研了七十多位财富500强企业和顶级企业领袖,发现这些公司2024年在AI上的支出预算比2023年增加了2-5倍。国内市场的智能化速度也不会逊色,更增强了对基础大模型的需求,所以接下来,会进入到白热化的跑马圈地阶段。
大模型新赛季,正式拉开帷幕。
长文本,只是“阵地战”的一环
长文本,是“秀肌肉”的必争之地,但解决政企客户的切实需求,长文本却未必那么实用。从Kimi的长短板,我们可以看到目前市场更需要怎样的大模型。
首先说说短板。前面提到了,Kimi的长文本在很多场景下属于低频需求,再长的token只会带来更大的计算量、更高的资源成本,对用户来说性价比不高。对此,吴恩达也认为,快速生成token,可能比使用更强的模型更重要。长文本处理导致的硬件资源需求、GPU短缺和云服务能力,也是Kimi面临的现实挑战。
而Kimi的长板在于,在文本摘要和知识管理等任务中,发挥出了极高的生产力效能,对企业的吸引力很大。应用更友好,企业不需要从头开始训练自己的LLM。
所以,长文本之战引发的连锁反应,会让一些能力,成为battle重点:
1.与云的深度融合。Maas服务会成为模型购买决策的首要原因之一,继续深化、细化。
2.对Agent开发的支撑。基础大模型很难提供所有端到端的解决方案,长文本处理是应用层公司的舞台,通过基础大模型+Agent式工作流,去解决客户的专有问题。而Agent式推理拼的是token生成速度,而非文本有多长。试想一下,如果一个金融客服助手半天憋不出一段话,即使生成的效果再好,用户也不会有耐心等待。所以,长文本能力并非应用型企业选择基座模型的唯一标准,甚至不是最重要的标准。
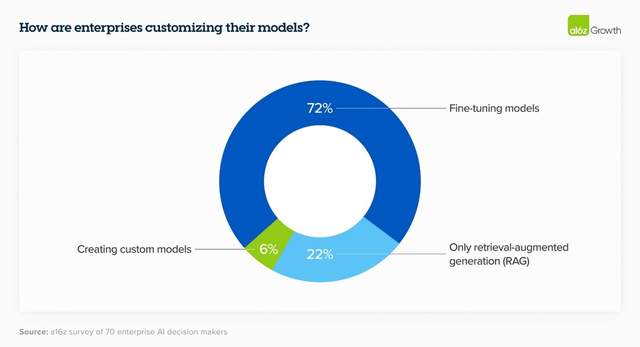
3.生态规模。Kimi的爆火说明,大厂不可能垄断所有应用方向。利用新的技术能力(如长文本处理)来解决新的问题,创业公司和个人开发者更具备贴近客户、深入场景的优势,为各类行业用户的特定需求进行微调、定制。大模型的商业城池,必须由众多生态伙伴一起来守,谁能在2024奠定生态的规模优势,是接下来博弈的关键点。
总的来说,大模型落地,是一个复杂的系统工程。2024进入“阵地战”的大模型市场,准备更加充分,作战更有条理,商业化战略也日益清晰。基础模型厂商,将在一次又一次的迎敌与防御中,构筑起系统性的攻防能力。
一个平台级的大模型公司,一定会是万亿级别,也一定会诞生在中国。让我们拭目以待。
-
Kimi K3登顶全球榜单,但AI真正落地考验的是系统可靠性2026-07-20 81
-
Kimi K2.6模型发布当天上线华为云2026-04-23 848
-
Kimi发布新一代推理模型k0-math2024-11-19 1915
-
Kimi发布新一代数学推理模型k0-math2024-11-18 1941
-
【附实操视频】聆思CSK6大模型开发板接入国内主流大模型(星火大模型、文心一言、豆包、kimi、智谱glm、通义千问)2024-08-22 4195
-
智能硬件接入主流大模型做语音交互(附文心一言、豆包、kimi、智谱glm、通义千问示例)2024-08-21 14391
-
Kimi爆火背后的技术奥秘 大模型长文本能力的技术难点2024-04-17 2653
-
Kimi AI模型崛起 各大厂商竞相效仿2024-04-08 4249
-
新火种AI|大厂围剿,“长文本”成不了Kimi的护城河2024-03-28 1332
-
KIMI与海内外主流模型对比及应用方向2024-03-26 2553
-
线性技术公司宣布能源收集应用中缺少的一环2021-04-17 816
-
最终等到了能源采集这一环2021-03-21 584
-
无人车最关键的一环是高精地图2018-03-31 5674
-
五环电阻第一环识别的方法2010-01-13 7001
全部0条评论

快来发表一下你的评论吧 !
