

深度剖析Sora技术的核心原理与应用
描述
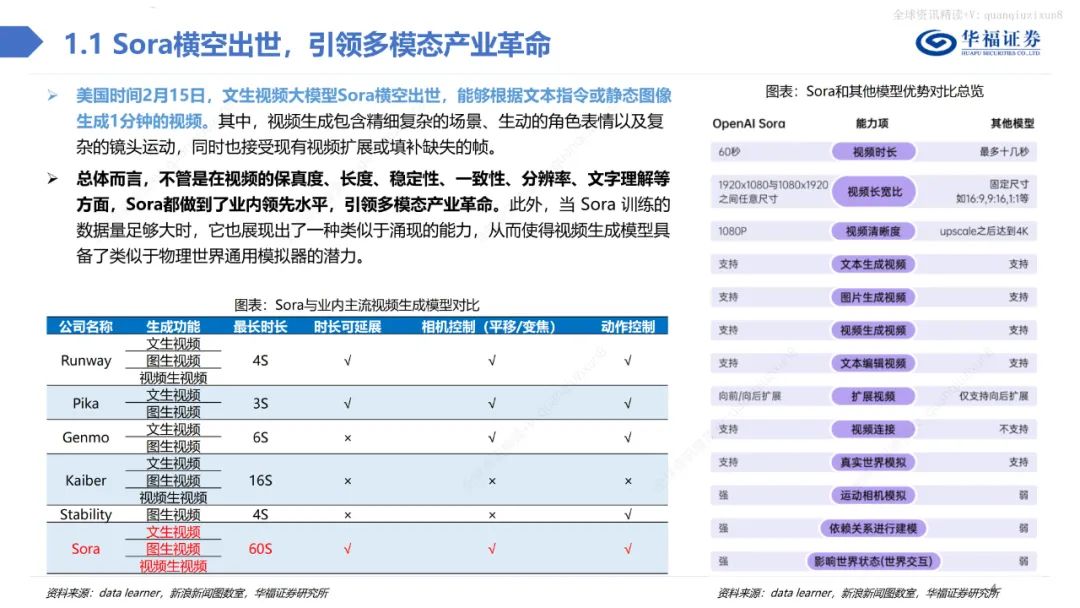
文生视频大模型Sora横空出世,能够根据文本指令或静态图像生成1分钟的视频。其中,视频生成包含精细复杂的场景、生动的角色表情以及复杂的镜头运动,同时也接受现有视频扩展或填补缺失的帧。
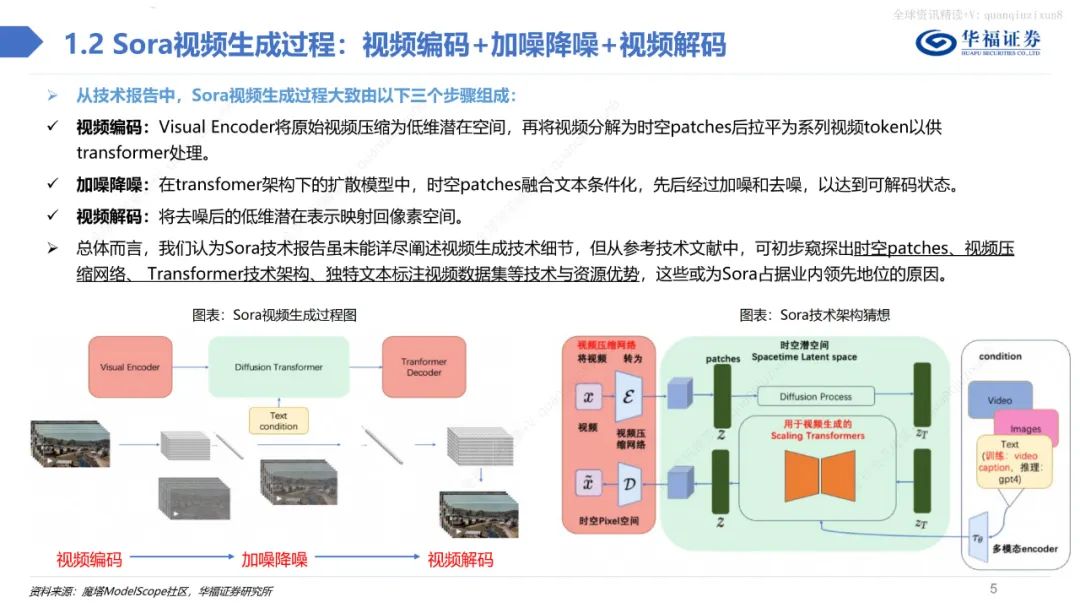
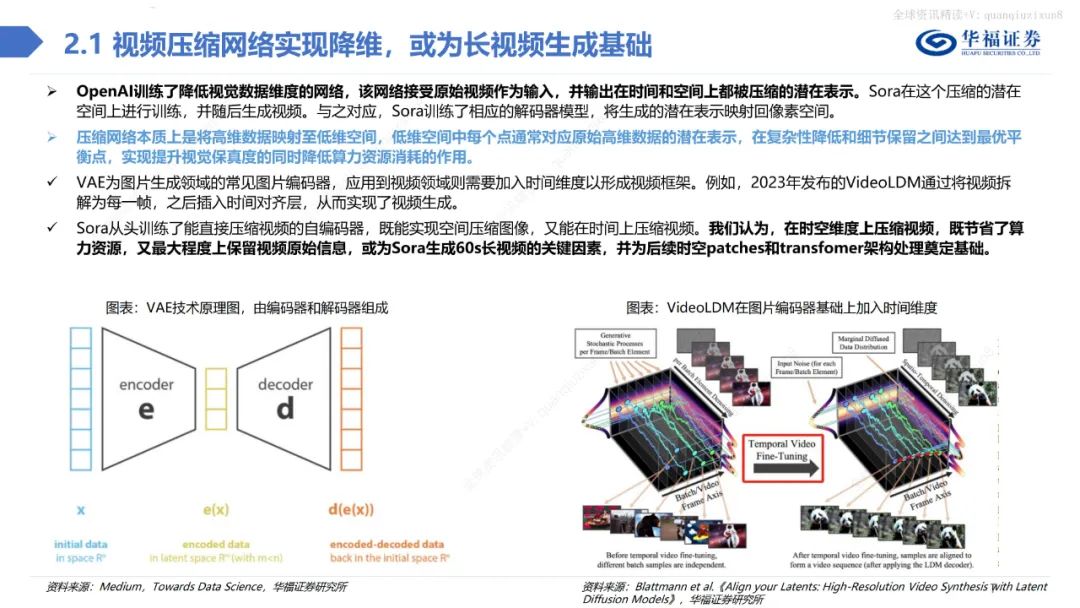
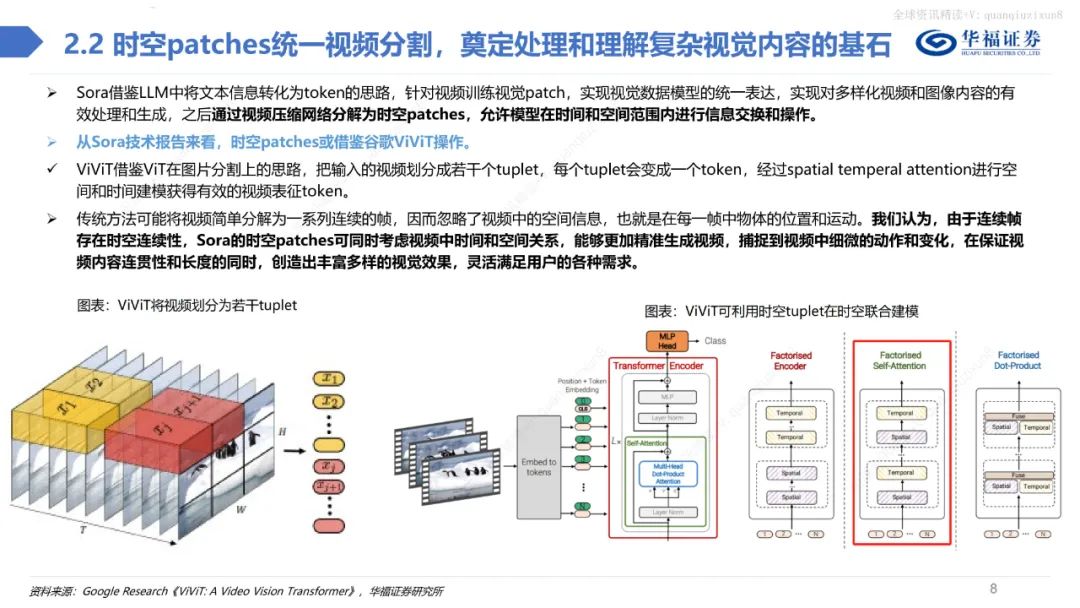
总体而言,不管是在视频的保真度、长度、稳定性、一致性、分辨率、文字理解等方面,Sora都做到了业内领先水平,引领多模态产业革命。此外,当Sora训练的数据量足够大时,它也展现出了一种类似于涌现的能力,从而使得视频生成模型具备了类似于物理世界通用模拟器的潜力。 Sora借鉴LLM中将文本信息转化为token的思路,针对视频训练视觉patch,实现视觉数据模型的统一表达,实现对多样化视频和图像内容的有效处理和生成,之后通过视频压缩网络分解为时空patches,允许模型在时间和空间范围内进行信息交换和操作。
从Sora技术报告来看,时空patches或借鉴谷歌ViViT操作。ViViT借鉴ViT在图片分割上的思路,把输入的视频划分成若干个tuplet,每个tuplet会变成一个token,经过spatial temperal attention进行空间和时间建模获得有效的视频表征token。 传统方法可能将视频简单分解为一系列连续的帧,因而忽略了视频中的空间信息,也就是在每一帧中物体的位置和运动。我们认为,由于连续帧存在时空连续性,Sora的时空patches可同时考虑视频中时间和空间关系,能够更加精准生成视频,捕捉到视频中细微的动作和变化,在保证视频内容连贯性和长度的同时,创造出丰富多样的视觉效果,灵活满足用户的各种需求。






审核编辑:黄飞
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
sora模型怎么使用 sora模型对现实的影响2024-02-22 1971
-
sora系列是哪个公司的 sora视频怎么用2024-02-21 6871
-
openai sora如何使用?Sora 使用指南:快速上手2024-02-20 6390
-
【资料分享】C语言深度剖析2015-10-16 4777
-
linux内核深度剖析,另附有光盘资料2014-01-15 5165
-
陈正冲《C语言深度剖析》2013-08-17 12609
-
c语言深度剖析2013-04-02 3114
-
C语言深度剖析2012-08-14 4083
-
《C语言深度剖析》【超经典书籍】2012-08-02 7865
全部0条评论

快来发表一下你的评论吧 !
