

探究GPGPU体系结构优化策略
描述
最近读了 GPGPU Architectural Survey[1],这篇survey很长,这里简要的介绍内容,将我理解的方向和重点的论文介绍一下。
相关的论文我只介绍缩写的名字,大致介绍文章的内容,具体的内容还是要看survey和原文。
GPGPU的优化方向主要包括以下五点:
控制分支分叉优化
control flow divergence
Memory带宽优化
Efficient utilization of memory bandwidth
提高并行度和优化流水线
Increasing parallelism and improving execution pipelining
增强GPGPU可编程性
Enhancing GPGPU programmability
CPU GPU异构架构优化
CPU–GPU heterogeneous architecture
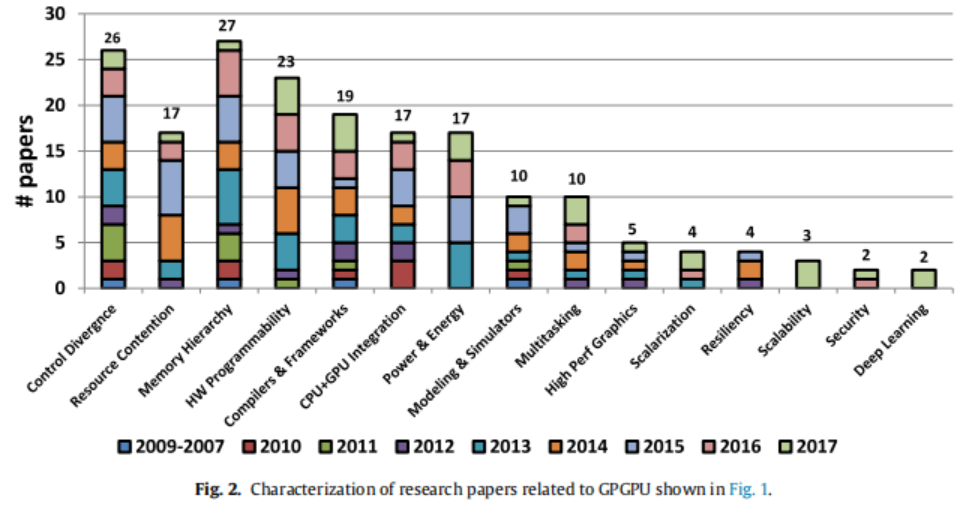
上图为近几年各个方向文章发表的比例
优化方向的前两点在这篇文章中介绍,后三点将会在下一篇文章介绍。
文末附有总结,也可以直接拉到文末。
文中baseline即指默认的GPGPU的配置。
控制分支分叉优化
GPU Warp内,32个线程(NVIDIA)锁步lock step执行时,如果遇到每个分支走上了不同分支,比如20个线程if,12个执行else,那么20个线程会先执行,mask调另外的12个。20个线程执行到分支合并点之后,另外12个再执行,直到这12个线程也进行到分支合并点。
如下图左侧所示。
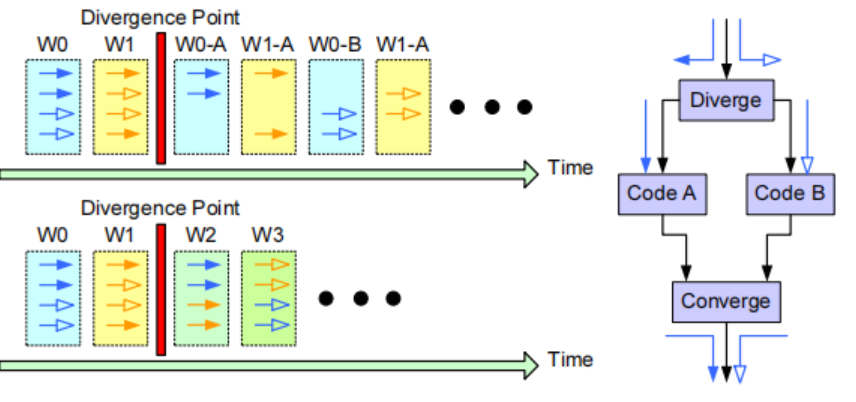
这样的缺点:
不同的分支顺序执行
warp本应执行32个,这样导致单元利用率不高
分支divergence可能进一步导致memory divergence
具体优化的子方向如下图所示:
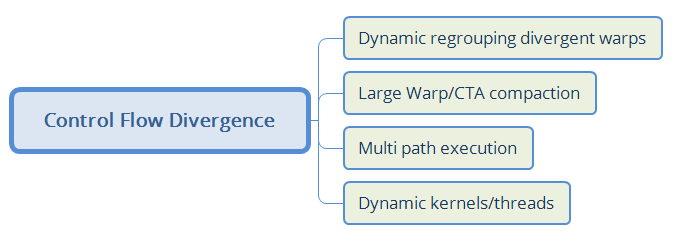
Dynamic Regrouping Divergent Warps即为不同warp的分支合并为新的warp。
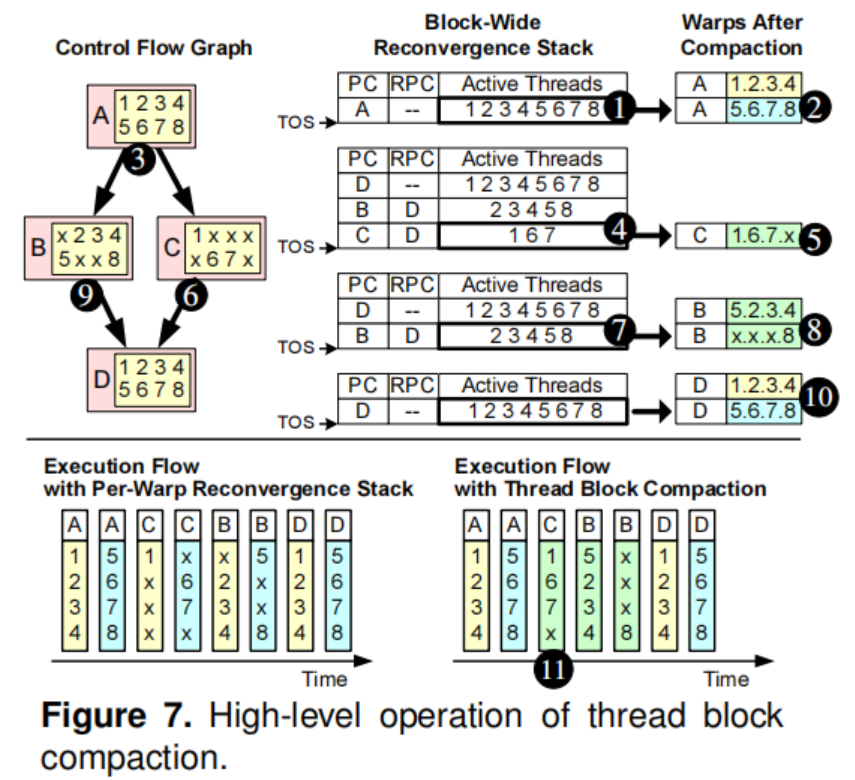
Large Warp/CTA compaction 中的Thread Block Compaction,将thread block 内的thread共享分支mask栈(baseline 每个warp单独有自己的分支mask栈)。
Multi path execution即为if 和 else分支两路同时执行。
Dynamic kernels/threads 比如在图形应用中,可能会动态的创建kernel,在[3]中提出了在irregular benchmark中怎么减少创建的开销.
Memory带宽优化
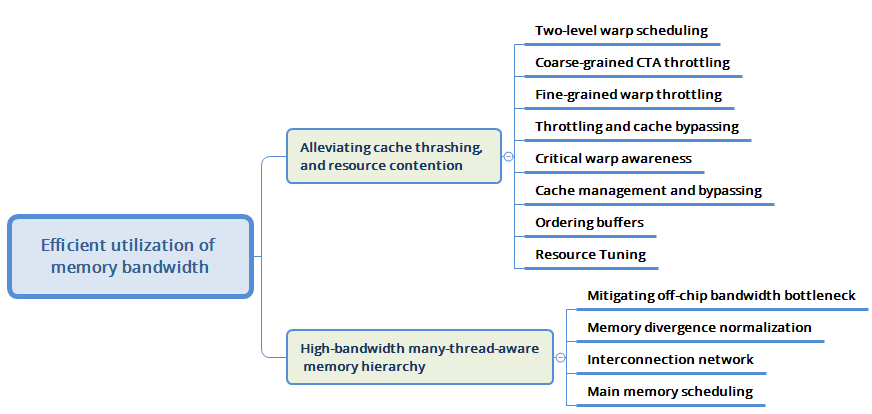
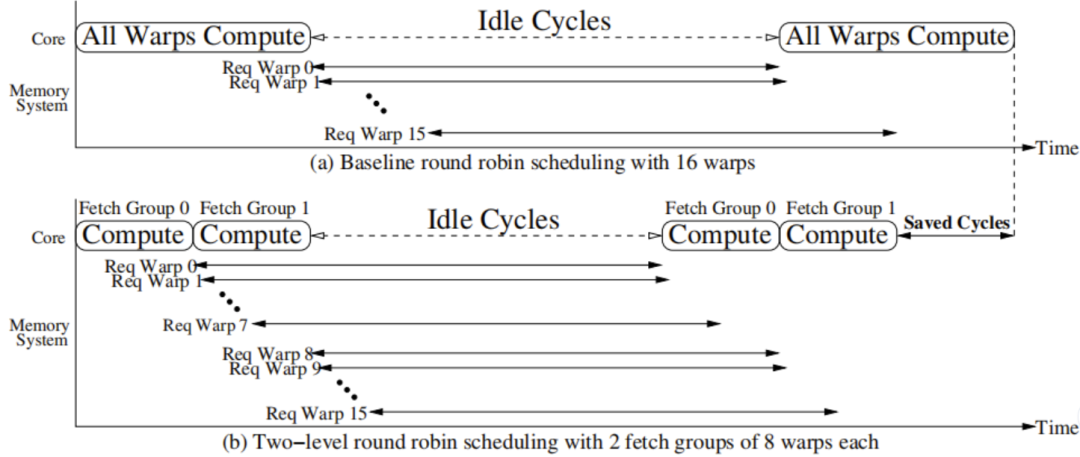
Two-level warp scheduling
baseline将所有的warp按照轮询的方式调度,但是如果程序是一致的,那么可能会所有的warp同时遇到cache miss的指令,导致很长的延迟。
TPRR(Two-Level Warp Scheduling):如果将warp分成两个level的warp。将32个warp组成了细粒度的4个fetch group,每个fetch group内部8个warp。直到一个fetch warp执行阻塞时,再执行另一组warp可以提高效率。
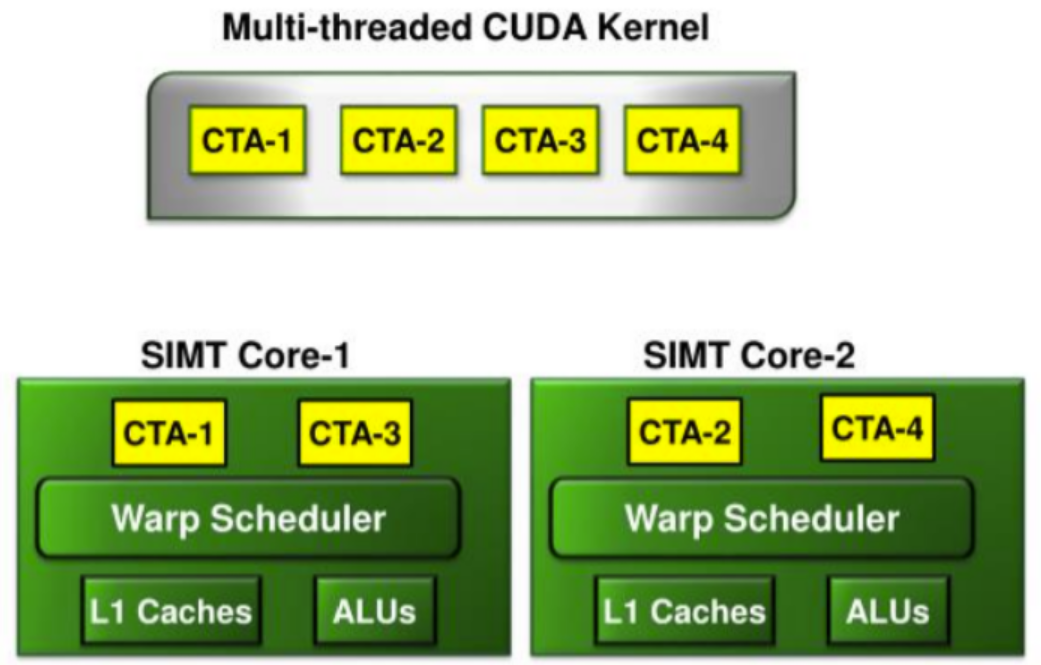
Coarse-grained CTA throttling
baseline将在一个GPU core上尽量执行最多的CTA以增加线程并行度。
但是这样可能会导致大量的线程竞争memory,因此也有优化方案DYNCTA提出调度最佳而不是最多的CTA。
Fine-grained warp throttling
baseline将在一个warp内的memory优化。不同的warp之间可能也会竞争共享的资源,比如一个warp访问的cache反复的被另一个warp竞争出去,即thrashing。可以通过将被thrashing的 warp优先执行,进行优化,即为PCAL(Priority-based cache allocation in throughput processors )。
Critical warp awareness
baseline对各个warp无感,但是实际上warp中也会有critical warp,执行的最慢成为关键路径,以下的情况可能会产生critical warp。
warp执行的workload比较重
warp执行了另外的控制分支
竞争memory。执行最慢的warp持续的刷LRU,导致这个warp占用了最多的cache
warp如果按照轮询调度,那么N个warp ready了之后,需要等待N个周期才能再次被调度
CAWA(Coordinated Warp Scheduling and Cache Prioritization for Critical Warp Acceleration of GPGPU Workloads)通过识别critical warp,优先调度并且优先cache 分配到这些warp上,来加速执行。
Cache management and bypassing
baseline 的cache之间没有配合。GCache(Adaptive Cache Bypass and Insertion for Many-core Accelerators)通过在L2 tag array中增加额外的标记来给L1 cache提供这个hot line在之前被evict出来,L1 Cache通过自适应的方法来锁定这些hot cacheline,防止thrashing,cache抖动。
Ordering buffers
如果不同的warp以interleave的方式发送memory的请求,这样memory footprint是所有warp整体的总和,如果能够一个warp先执行完,另一个warp再执行,那么memory footprint只是一个warp的memory footprint。
比如下图,将W3聚合在一起,可以减少footprint。即为ordering buffer, 详见MRPB: Memory request prioritization for massively parallel processors 。

Mitigating off-chip bandwidth bottleneck
LAMAR(local-aware memory hierarchy)注意到对于规范的GPGPU workload,每次memory 访问,进行粗粒度的内存访问可以利用空间局部性,也可以提高带宽。但是对于不规则的workload,细粒度的内存访问则更好,因此它对于不同的workload进行不同粒度的内存访问。
CABA(Core-Assised Bottleneck Acceleartion) 如果存在带宽瓶颈,那么会使用空闲的计算单元,创建warp压缩内存,以避免带宽瓶颈。
Memory divergence normalization
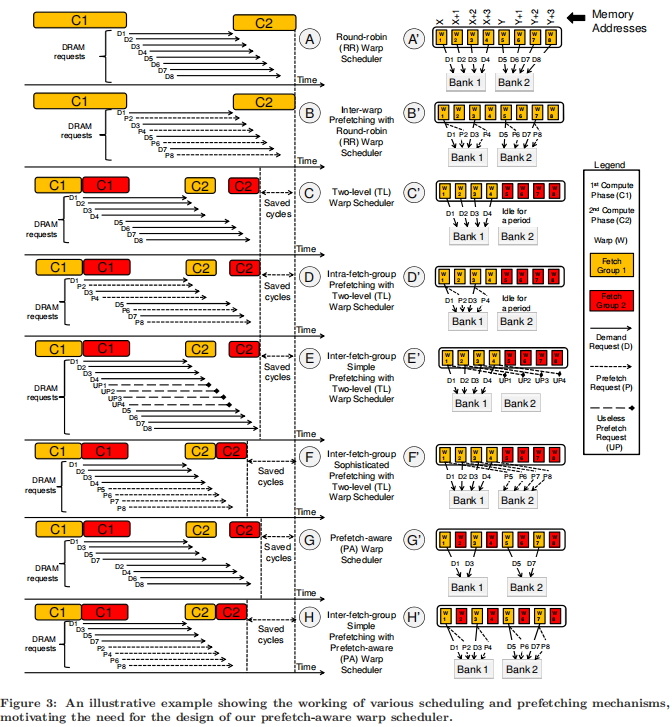
baseline的prefetcher会根据当前的warp对下一个warp的内存进行预取,但是这样可能会late prefetch或者不准确产生useless prefetch。 Orchestrated Scheduling and Prefetching for GPGPUs 论文比对了之前的TPRR,认为使用当前的fetch group预测下一个fetch group进行预测是不准确的,因为从使用warp1-warp4的访问去预测warp5-warp8的访问可能不准确,因此它细粒度的先执行warp 1/3/5/7,使用产生的地址去预测warp 2/4/6/8. 下图中的D1-D7即为warp产生的访问内存的请求,黄色和红色的即为TPRR中不同的fetch group,在之前的TPRR fetch group中包含8个warp。
Main memory scheduling
baseline的linux page placement主要处理CPU-only NUMA系统,致力于减少memory latency。但是GPU对bandwidth更加敏感,因此论文Page Placement Strategies for GPUswithin Heterogeneous Memory Systems通过平衡page placement来最大化memory bandwidth。
CPU–GPU memory transfer overhead
baseline的GPGPU启动时,需要等待CPU将数据完全将内存拷贝到GPU内存,才能开始计算。
Reducing GPU Offload Latency via Fine-Grained CPU-GPU Synchronization通过增加full-empty bists,来追踪已经传输完成的page。如果GPGPU计算所依赖的数据已经传输完毕,就可以直接执行。这样可以overlap 执行和数据搬运的时间。
总结
1. Control Divergence
因为warp内可能存在不同的分支执行路径,因此合并不同warp的相同分支,产生新的warp,也可以在整个CTA的范围内合并warp。
也可以同时执行分支的不同路径。
因为CUDA后面支持kernel执行时自己产生新的kernel,但是产生新的kernel开销很大,所以可以减少开销。
2. Memory 带宽和利用率优化
不是简单的轮询调度warp,而是将其切割成fetch group。后面的优化方案又结合了fetch group和prefetch
可以在CTA的粒度上节流线程的执行,以减少memory竞争。同样,也可以在warp的力度上进行节流,防止warp之间的竞争。
可以优化cache,防止cache的抖动,thrashing问题。也可以bypass
识别关键的warp,优先执行关键warp
对访问内存的请求进行ordering,减少memory footprint
利用空闲的执行单元进行压缩,避免bandwidth bottleneck
针对GPU memory系统设计bandwidth有限的page placement 策略
审核编辑:黄飞
-
ARM SOC体系结构2016-11-22 6094
-
Microarchitecture指令集体系结构2021-12-14 1984
-
浅析嵌入式实时系统的体系结构设计2021-12-22 1649
-
Arm的DRTM体系结构规范2023-08-08 1121
-
Arm Power Policy Unit 1.1版体系结构规范2023-08-11 707
-
ARM体系结构与编程2010-02-11 820
-
LTE体系结构2009-06-16 10294
-
网络体系结构,什么是网络体系结构2010-04-06 2135
-
ARM体系结构与程序设计2011-10-27 2745
-
XScale体系结构及编译优化问题2016-04-18 901
-
软件体系结构的分析2017-11-24 1444
-
基于DoDAF的卫星应用信息链体系结构2018-01-10 1198
-
微处理器体系结构2021-04-14 1444
-
Oracle体系结构讲解2021-09-27 958
-
GPGPU体系结构优化方向(1)2024-10-09 1811
全部0条评论

快来发表一下你的评论吧 !
