

FPGA 原型设计开发复杂性策略
可编程逻辑
描述
将区块划分为可管理的片段变得越来越难,但新的工具和方法正显示出前景。
ASIC 和 SoC 设计的多 FPGA 原型验证使验证团队能够实现仿真技术中最高的时钟速率,但为原型验证设置设计非常复杂且具有挑战性。这正是机器学习和其他新方法开始提供帮助的地方。 根本问题在于设计变得如此庞大和复杂,以至于必须将其分割成更易于管理的部分。但碎片的数量在成倍增加,分割的难度也在成比例上升。
Cadence 公司产品管理部总监 Juergen Jaeger 说:“你需要将一大团逻辑进行分割,而分割的方式最重要的是要保留功能,也就是说不能破坏设计中的任何部分。”无论是仿真器还是 FPGA 原型,你都希望有效地利用所划分的资源,并尽可能实现最佳性能。这就像在空中玩弄多个球一样。
由于新一代 FPGA 刚刚出现,该行业正处于一个有趣的关头。“对于设计规模相对较小的用户来说,这确实是一个很好的机会。Synopsys公司产品营销高级总监Johannes Stahl表示:”对于以前不得不将设计分割到两个FPGA中的用户来说,这是一个绝佳的机会,因为他们省去了分割,并获得了更好的结果。“例如,以前一个设计的运行速度是 20MHz,而现在可以达到 50MHz,所以这是一个巨大的影响。在这些新型 FPGA 上线的许多情况下,这种情况还会继续发生。”
Aldec 硬件验证产品经理 Krzysztof Szczur 说:“换句话说,逻辑密度的大幅提高使得在单个 FPGA 芯片中实现更小的 SoC 设计成为可能,并以接近实际运行条件的时钟频率运行原型。 Aldec 硬件验证产品经理 Krzyztof Szczur 说:”与此同时,由于当今最先进的 FPGA 实际上并不是一个芯片,因此出血边缘器件增加了另一个层次的复杂性。
Jaeger说:“赛灵思和英特尔/Altera的高端FPGA现在包含多个裸片,其中的多个芯片用线连接,因此FPGA内部也有分区。Jaeger 说:”作为额外的复杂性,如果你现在正在研究功能(必须具备的功能)、性能和资源的有效利用,那么分区算法就会试图采用‘最小切割算法’。它们试图尽量减少必须在多个分区之间传输的信号数量。除此之外,进行分区的工程师还试图平衡每个 FPGA 的利用率,这样就不会出现一个 FPGA 满载 90%,而另一个只满载 10%的情况,因为这会对性能产生负面影响。“
当然,在有些情况下,也无法实现 Stahl 所提到的同样显著的效果。例如,一些公司在使用自己的电路板进行原型开发时,会遇到多 FPGA 分区以外的挑战,具体来说,就是因为需要添加调试信号,所以要反复进行多 FPGA 分区。
Stahl 说:”如果你必须在一个主要是手动的流程中引入调试信号,你就必须将它们引入引脚,这就会影响分区。Stahl 说:“因此,你必须重新运行分区,这相当痛苦。一位用户就非常讨厌这样做,因为他永远无法预测下一次分区运行的时间会在什么时候结束,而他却可以再次把原型提供给用户。由此可见,它与调试确实息息相关。调试和自动分区对于使用原型设计的用户来说是同一个主题。这一切都必须协同工作”。
多 FPGA 原型验证的另一个挑战是分区的连接。Aldec 的 Szczur 说:“随着逻辑密度的不断提高,FPGA 被封装在更大的封装中,从而提供了更多的 I/O。”然而,I/O 的增加并不像逻辑资源那样引人注目。例如,最大的 Virtex UltraScale 提供 1,456 个常规 I/O,比 Virtex-7 系列多出约 21%。为了缩小这一差距,FPGA 供应商为现代 FPGA 配备了高速串行 I/O(如 XCVU440 中的 48 条 GTH 线),从而提高了连接带宽。这些 I/O 通常与用于 PCI Express、USB 3.0 或 QSFP 等标准接口的 PHY 相耦合。在某些情况下,它们也可用于多 FPGA 原型中的芯片间连接,但在这种情况下,它们的使用仅限于实现专用协议握手的事务接口,而且最好使用突发传输,以最大限度地减少此类链路延迟增加的影响。此外,在高端 FPGA 中,由于支持低压差分信令 (LVDS),加上专用的串行器/解串器 (SerDes) 逻辑,标准 I/O 被设计为以更高的数据传输速率进行传输,从而促进了此类链接的实现。不过,在 LVDS 模式下同时设置 GTH/GTX 或标准 I/O 可能比较麻烦,如果由分区软件自动进行设置,则可以节省大量时间,减少麻烦。
如果设计规模大于单个 FPGA,则必须进行分区,每个分区都要与单个 FPGA 的容量相匹配。有两个目标:第一个目标是将 FPGA 资源利用率控制在一个阈值内,以确保流畅的布局布线。第二个目标是尽量减少分区之间的互连,这是影响原型速度的最重要因素。
Szczur 说:“在两个 FPGA 的情况下,这个过程相对简单,但在增加下一个分区时,难度就会迅速增加,尤其是在设计结构(层次结构)与原型板布局不一致的情况下。”一种方法是手动分区,这需要更改设计源。分区块在 HDL 中创建,以匹配原型验证板资源和连接性。由于 FPGA I/O 的限制,每个分区都必须与互连物理层和多路复用器或串行器的定制实现进行手动封装。这种方法不仅容易出错、难以扩展或涵盖设计变更,而且需要修改设计,从而对 ASIC 后端综合优化产生负面影响。为了降低这种风险,可以为 FPGA 原型和 ASIC 设计流程保留不同的 HDL 源集和配置。但这样一来,在 FPGA 原型验证过程中真正验证的是什么就值得怀疑了。比手动分区好得多的方法是使用编译原始设计 HDL 源文件的软件,这有助于在设计层次结构中对模块实例进行分组,从而将其分成不同的分区“。
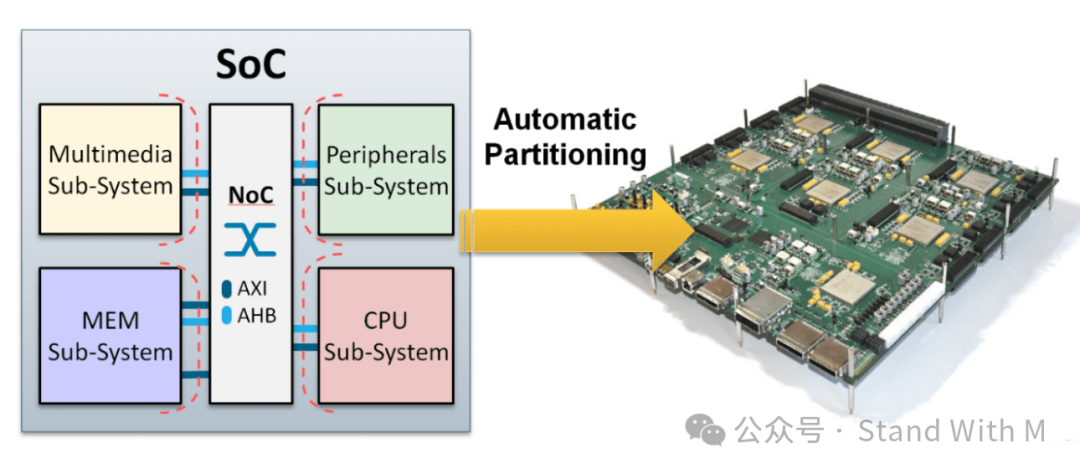
图 1:自动分区工具。来源:Aldec
执行分区
分区由软件架构师完成,他们负责设计整体结构并确定分区算法的工作方式。这些架构师由工程师团队提供支持,工程师团队负责具体实施。”有些人只负责引脚复用,例如分区之间的连接,“Cadence 的 Jaeger 说。”另一些人则只负责贴片,专注于如何拆分。然后再细分到各个专家小组“。
这在很大程度上取决于设计/验证团队的规模。”他解释说:“架构是实现良好分区的关键。”第二重要的可能是全局布局。如何将不同的设计块放置到不同的 FPGA 中。连接和引脚复用是机械工作。没有太多的创造性。它只是实现它。正如你所能想象的那样,当你有多个东西需要一起工作时,你总得从某个地方入手。你必须把木桩放在地上,‘我把这个放在这里,把那个放在那里,再把那个放在那里。让我们看看现在它们是如何结合在一起的。所有的算法都是以种子或随机起点为基础的。然后,这些算法经过多次迭代,对起点进行变化“。
在这一领域,我们正在努力提高可预测性,包括机器学习。”预测算法在其中发挥了作用,有助于提高可预测性,因为这样做的目的是,当你提高了可预测性,你就不需要那么多的迭代,不需要那么多的重复,就能得到好的结果。这就是为什么我们希望将更多的机器学习引入其中,“Jaeger 说。
这是一个计算能力问题,也是一个时间问题。”这其中很重要的一点是,并不是每个问题都能解决。比方说,你有一个特定的设计,你说’我想把它装进四个 FPGA‘。但由于种种原因,可能无法实现。可能有太多的门。中间的连接可能太多,也许还有其他原因。当你熟悉 FPGA 时,往往要花上好几天时间才能发现它无法进行布局布线,而且没有解决方案。您需要尽快了解情况。ML 算法能在几分钟或半小时后帮助你,所以你不用等上两三天,直到你的软件说’哎呀,我做不了‘。他补充说:“你可以提前知道,也可以提前做出改变。
不过,目前还不清楚该行业是否已准备好在这一领域应用机器学习。”虽然机器学习可以实现,但挑战在于你需要有大量的运行来优化这种机器学习,“Stahl 说。”如果你花费了足够的计算能力,你就可以进行优化,运行许多次,然后找到一个更优化的版本。因此,就像任何本质上略带启发式的优化问题一样--放下电缆本质上也略带启发式--人工智能算法可以使其受益。今天我们还没有进入市场,但未来一定会进入市场。
分区最佳实践
在构建 FPGA 原型时,有一些关键的注意事项需要牢记。
Imagination Technologies 开发平台团队首席系统架构师 Daniel Aldridge 说:“最有用的第一种方法是在设计时考虑到 FPGA。”作为 FPGA 工程师,我们倾向于你计划放入 FPGA 的 IP 核是’FPGA 友好型‘的,这意味着它没有会大量消耗 FPGA 资源或难以在 FPGA 之间拆分的组件。如果设计能事先考虑到这些因素,如果最终产品将被放入 FPGA 或至少是其变体,那就更好了。如果 IP 核必须为硅设计,那么硅面积和速度就是首要考虑因素。那么,我们就必须将就。有时,这就意味着用经过正式测试的、可用于 FPGA 的同类元件来替换同类元件。归根结底,就是’你能不能让进入 FPGA 的元件尽可能对 FPGA 友好?
在多 FPGA 平台上,如果设计必须拆分,那么最好能在已注册的边界上拆分,这样就有了协议。
Aldridge 说:“这样就可以在 FPGA 之间拉动寄存器到寄存器。Aldridge 说:”它为你提供了一条引脚数相对较少的总线,而你最终不得不拆分这条总线。如果是像 AMBA 总线这样的总线,引脚数不会太多。虽然仍有数百个,但不会达到数万个。但是,这并不总是可能的。因此,我们需要在 FPGA 和 PCB 上拆分设计,而这些设计在硅片中一直是相邻的。这就是我们开始寻找工具来帮助实现这一过程自动化的原因。如果要拆分通过有效协议连接的高级模块,手工编辑这些子组件的实例是一件相对容易的事情。如果你要开始拆分次层级的区块,或者拆分许多大型区块,这些区块之间有数千或数万个信号,那么我们就需要使用工具来帮助实现流程自动化。这可以帮助你自动计算模块将占用的面积,从而计算出哪些模块应该放在哪里,还可以帮助你计算出哪些信号将在哪些FPGA之间传输,以及需要进行哪些复用。这就是我们开始讨论的地方,现在最大的 FPGA 有几千个 I/O 引脚。但是,如果你要放一万个信号,你仍然需要进行某种时分复用,将信号从一个 IP 块或 IP 的子块传输到另一个块。
区块大小对分区也有很大影响。
Aldridge 说:“如果你能让一个组件的大小不超过 FPGA,那么你的工作就会变得更轻松。”在 ASIC 领域,这就是子块可能占用的平方毫米面积。然后,从这些大得多的设计的 ASIC 布局出发,开始考虑这些块之间的互连是什么。从 FPGA 的角度来看,当你进行原型设计时,我们希望在设计阶段就考虑到这一点。从一开始,当 IP 核的架构完成后,你就应该考虑应该将其分解到哪个层次,应该有哪些分层。是否应该在它们之间商定一个最大 I/O 或通用 I/O 接口?确保有流水线阶段,因为这将有助于 FPGA 时序和 ASIC 时序。希望你能事先说服设计人员,这对大家都有好处。
多 FPGA 原型开发将走向何方?
如今,设计原型的依赖性如此之大,下一步的发展方向也在不断变化。
EDA 领域主要解决的一个问题是,当连接多个分区时,FPGA 之间的边界有不同的布线方式。这包括如何进行引脚多路复用,以及数据传输后的转换速度。
Jaeger 说:“越来越多的引脚复用方案采用混合方案。”你可以采用非常传统的异步引脚多路复用。你以相对较低的速度运行线路,然后超频,这样就可以在另一端恢复数据。如果引脚多路复用率较小,这种方法就非常有效。它的延迟非常低,因此线路中的延迟非常短。如果你有成百上千个信号需要通过一条线发送,这将是一个限制因素。因此,你需要使用基于 SerDes 的高速连接技术,在这种技术中,你基本上是在运行一条传输线,并以千兆赫兹的速度在电线上运行。这样做的缺点是,设置这些端点的串行化/反串行化会增加延迟,因此只有在引脚复用率非常高的情况下才有意义“。
审核编辑:黄飞
-
大数据分析学习的挑战:复杂性、不确定性及涌现性2022-11-17 4040
-
验证中的FPGA原型验证 FPGA原型设计面临的挑战是什么?2022-07-19 2553
-
了解 AV 复杂性2022-07-15 2648
-
驾驭软件定义车辆的复杂性2022-07-14 1741
-
如何用可重构射频前端简化LTE设计复杂性?2021-05-24 1914
-
嵌入式调试的复杂性分析2021-02-19 1176
-
抑制嵌入式系统设计的复杂性解析2020-12-30 1494
-
FPGA原型验证的技术进阶之路2020-08-21 4867
-
将要采取哪些策略降低物联网跨平台设计的复杂性2018-09-27 3301
-
怎么采用FPGA原型系统加速物联网设计?2018-08-07 2656
-
基于构件回归测试的复杂性度量框架2018-01-19 994
-
利用FPGA开发板进行ASIC原型开发的技巧2017-11-25 1433
-
谈谈如何利用FPGA开发板进行ASIC原型开发2017-02-11 1449
-
有效解决实时IoT环境监测的复杂性2016-07-14 840
全部0条评论

快来发表一下你的评论吧 !
