

内核(linux-3.12)的文件系统预读设计和实现
嵌入式技术
描述
概述
本文主要阐述内核(linux-3.12)的文件系统预读设计和实现。
所谓预读,是指文件系统为应用程序一次读出比预期更多的文件内容并缓存在page cache中,这样下一次读请求到来时部分页面直接从page cache读取即可。当然,这个细节对应用程序透明,应用程序可能的感觉就是下次读的速度会更快,当然这是好事。文中我们会通过设置几个情境(顺序读、随机读、多线程交织读)来分析预读的逻辑。
情境1:顺序读
// 事例代码
{
...
f = open("file", ....);
ret = read(f, buf, 4096);
ret = read(f, buf, 2 * 4096);
ret = read(f, buf, 4 * 4096);
...
}
该场景非常简单:打开文件,共进行三次读(且是顺序读),那让我们看看操作系统是如何对文件进行预读的。
Read 1
第一次进入内核读处理流程时,在page cache中查找该offset对应的页面是否缓存,因为首次读,缓存未命中,触发一次同步预读:
static void do_generic_file_read(struct
file *filp, loff_t *ppos,
read_descriptor_t *desc,
read_actor_t actor)
{
......
for (;;) {
......
cond_resched();
find_page:
// 如果没有找到,启动同步预读
page = find_get_page(mapping, index);
if (!page) {
page_cache_sync_readahead(
mapping, ra, filp,
index,
last_index - index
);
该同步预读逻辑最终进入如下预读逻辑:
// 注意: 这里offset 和req_size其实是页面数量
static unsigned long ondemand_readahead(
struct address_space *mapping,
struct file_ra_state *ra,
struct file *filp,
bool hit_readahead_marker,
pgoff_t offset,
unsigned long req_size)
{
unsigned long max =
max_sane_readahead(ra->ra_pages);
// 第一次读文件,直接初始化预读窗口即可
if (!offset)
goto initial_readahead;
......
initial_readahead:
ra->start = offset;
ra->size = get_init_ra_size(req_size, max);
// ra->size 一定是>= req_size的,这个由get_init_ra_size保证
// 如果req_size >= max,那么ra->async_size = ra_size
ra->async_size = ra->size > req_size ? ra->size - req_size : ra->size;
readit:
/*
* Will this read hit the readahead marker made by itself?
* If so, trigger the readahead marker hit now, and merge
* the resulted next readahead window into the current one.
*/
if (offset == ra->start &&
ra->size == ra->async_size) {
ra->async_size = get_next_ra_size(ra, max);
ra->size += ra->async_size;
}
return ra_submit(ra, mapping, filp);
}
读逻辑会为该文件初始化一个预读窗口:
(ra->start, ra->size, ra->async_size)
本例中的预读窗口为(0,4,3),初始化该预读窗口后调用ra_submit提交本次读请求。形成的读窗口如下图所示:
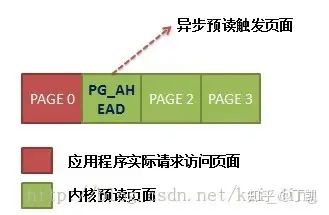
图中看到,应用程序申请访问PAGE 0,内核一共读出PAGE0 ~PAGE3,后三个属于预读页面,而且PAGE_1被标记为PAGE_READAHEAD,当触发到该页面读时,操作系统会进行一次异步预读,这在后面我们会仔细描述。
等这四个页面被读出时,第一次读的页面已经在pagecache中,应用程序从该page中拷贝出内容即可。
Read 2
接下来应用程序进行第二次读:offset=4096, size=8192。内核将其转化为以page为单位计量,offset=1,size=2。即读上面的PAGE1和PAGE2。
感谢第一次的预读,PAGE1和PAGE2目前已经在内存中了,但由于PAGE1被打上了PAGE_AHEAD标记,读到该页面时会触发一次异步预读:
find_page:
......
page = find_get_page(mapping, index);
if (!page) {
page_cache_sync_readahead(
mapping, ra, filp,
index,
last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(
mapping, ra, filp,
page,index,
last_index - index);
}
static unsigned long
ondemand_readahead(
struct address_space *mapping,
struct file_ra_state *ra,
struct file *filp,
bool hit_readahead_marker,
pgoff_t offset,
unsigned long req_size)
{
unsigned long max =
max_sane_readahead(ra->ra_pages);
........
/* 如果:
* 1. 顺序读(本次读偏移为上次读偏移 (ra->start) + 读大小(ra->size,包含预读量) -
* 上次预读大小(ra->async_size))
* 2. offset == (ra->start + ra->size)???
*/
if ((offset == (ra->start + ra->size - ra->async_size) ||
offset == (ra->start + ra->size))) {
// 设置本次读的offset,以page为单位
ra->start += ra->size;
ra->size = get_next_ra_size(ra, max);
ra->async_size = ra->size;
goto readit;
}
经历了第一次预读,文件的预读窗口状态为
(ra->start,ra->size, ra->async_size)=(0, 4, 3)
本次的请求为(offset,size)=(1, 2),上面代码的判断条件成立,因此我们会向前推进预读窗口,此时预读窗口变为
(ra->start,ra->size, ra->async_size) = (4, 8, 8)
由于本次是异步预读,应用程序可以不等预读完成即可返回,只要后台慢慢读页面即可。本次预读窗口的起始以及大小以及预读大小可根据前一次的预读窗口计算得到,又由于本次是异步预读,因此,预读大小就是本次读的页面数量,因此将本次预读的第一个页面(PAGE 4)添加预读标记。

由于上面的两次顺序读,截至目前,该文件在操作系统中的page cache状态如下:

Read 3
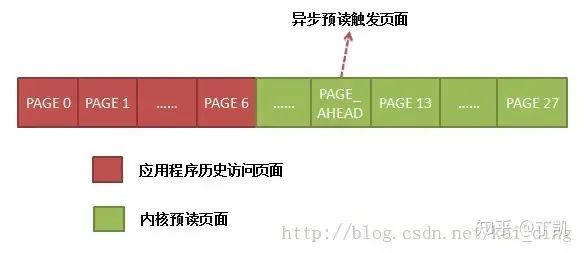
接下来应用程序进行第三次读,顺序读,范围是[page3, page6],上面的预读其实已经将这些页面读入page cache了,但是由于page4被打上了 PAGE_READAHEAD 标记,因此,访问到该页面时会触发一次异步预读,预读的过程与上面的步骤一致,当前预读窗口为 (4,8,8) ,满足顺序性访问特征,根据特定算法计算本次预读大小,更新预读窗口为 (12,16,16) ,新的预读窗口如下:

对该情境简单总结下,由于三次的顺序读加上内核的预读行为,文件的page cache中的状态当前如下图所示:
审核编辑:黄飞
-
Linux平台/proc虚拟文件系统详解2023-06-08 2458
-
Linux文件系统课程2009-04-10 565
-
Linux根文件系统简介2010-04-21 5311
-
《Linux设备驱动开发详解》第5章、Linux文件系统与设备文件系统2017-10-27 1115
-
了解Linux默认文件系统的发展历史2018-09-14 7296
-
嵌入式Linux常用文件系统2019-05-04 3038
-
Linux 内核/sys 文件系统介绍2019-04-25 5080
-
你知道嵌入式Linux内核?文件系统的制作也是有密切关联的2019-04-28 1160
-
Linux FAT文件系统预性能或有大幅提升2020-04-12 3039
-
Linux文件系统解析2020-09-16 3452
-
如何实现Linux内核移植和yaffs2根文件系统制作2021-03-24 997
-
深入剖析Linux内核虚拟文件系统2022-05-14 4210
-
移植Linux内核ramfs和ramdisk文件系统2023-10-04 2380
-
Linux的文件系统特点2023-11-09 2513
-
Linux根文件系统的挂载过程2024-10-05 2157
全部0条评论

快来发表一下你的评论吧 !
