

NVLink的演进:从内部互联到超级网络
描述
随着人工智能(AI)技术的迅猛发展,对于高效、快速的数据传输和处理变得越来越迫切。英伟达的NVLink技术一直处于技术前沿,不断推动着GPU之间和GPU与其他组件之间的互联效率。
本文将介绍NVLink的演进历程,从最初的内部互联到如今的超级网络,探索其在AI芯片架构中的重要作用。

Part 1
NVLink的起源
NVLink是NVIDIA开发的一种高速、低延迟的互联技术,旨在连接多个GPU以实现高性能并行计算。与传统的PCIe总线相比,NVLink提供了更高的带宽和更低的延迟,使得GPU之间可以更加高效地共享数据和通信。

NVLink最初的目标是解决GPU之间的互联问题。早期的GPU一定需要保留与CPU互联的PCIe接口,因此NVLink自然而然地继承了这一技术。
NVLink利用了Ethernet生态的成熟互联技术,但并未完全遵循Ethernet的规范,采用了不同的调制方式以降低时延。这使得NVLink在速率和时延上都具有优势,逐渐成为了PCIe的竞争对手。
NVLink采用了基于差分信号线的高速串行通信技术,通过将多个Sub-Link(子链接)组合成Port(端口),实现GPU之间的快速数据传输。每个Port由多个Sub-Link组成,每个Sub-Link都由一对差分信号线构成,可以实现高达几百Gbps的传输速率。NVLink还支持内存一致性和直接内存访问(DMA),进一步提高了数据传输效率和计算性能。
Part 2
NVLink的发展
NVLink 首次作为与 NVIDIA P100 GPU 的 GPU 互连推出,并与每个新的 NVIDIA GPU 架构保持同步发展。随着技术的不断发展,NVLink逐渐走出了盒子和机框,成为了一个独立的网络设备,对标InfiniBand和Ethernet网络。
每一代NVLink的速率都会是上一代的1.5到2倍,未来NVLink5.0预计将采用更高的速率,如200G每通道。同时,NVLink在带宽指标上对PCIe形成了碾压式的竞争优势,不断拓展着其应用领域。
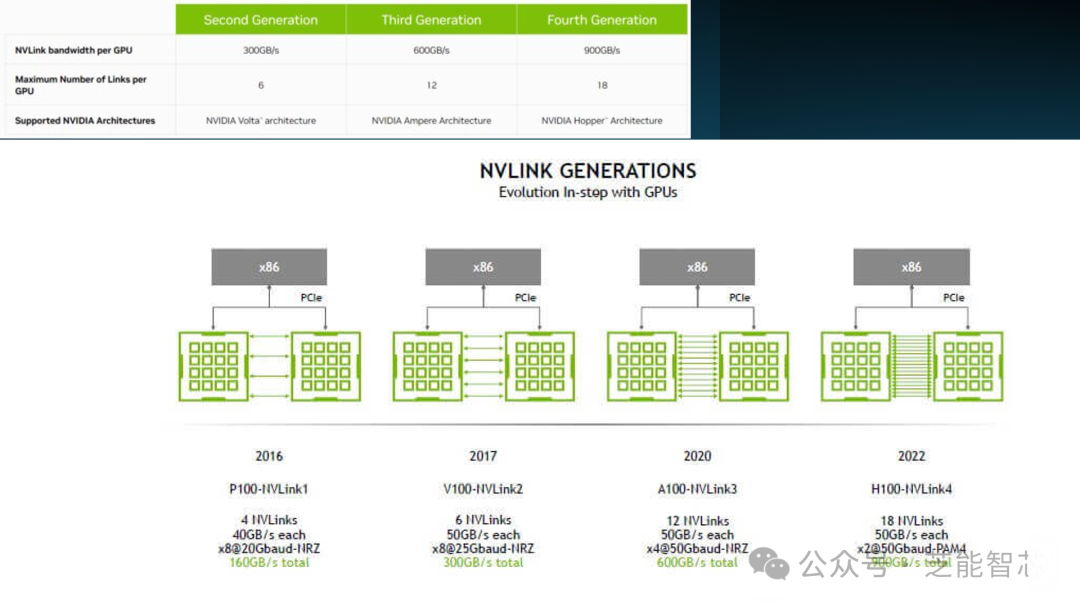
NVLink的发展经历了多个版本,每一代都在带宽、延迟和能效方面有所提升。新的NVLink带宽比上一代提高了两倍,这意味着数据传输更快,GPU之间的协作更加高效。第五代NVLink还在总带宽和性能方面有所提升。
NVSwitch3芯片集成了SHARP功能,对多个GPU单元的计算结果进行聚合和更新,减少网络数据包并提高计算性能。这些改进使得第五代NVLink在多GPU系统中的应用更加高效和灵活。
NVLink将继续发挥重要作用,随着AI芯片架构的不断演进,NVLink将进一步优化其性能和效率。NVLink的未来发展方向可能包括更高速率的互联技术以及更广泛的应用场景,从而满足不断增长的数据处理需求。
小结
NVLink是一种由NVIDIA开发并推出的高速连接技术,作为Nvidia的核心技术之一,在AI芯片领域扮演着至关重要的角色。
-
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片2024-05-13 6796
-
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理2025-06-18 1858
-
如何从CDMA2000 1X到CDMA2000 1x EV的平滑演进2009-06-13 4135
-
特斯拉V100 Nvlink是否支持v100卡的nvlink变种的GPU直通?2018-09-12 9007
-
GSM网络向WCDMA网络平滑演进的几点建议2019-07-16 1551
-
探讨互联网IPv6技术的发展与演进2021-05-25 2607
-
英伟达GPU卡多卡互联NVLink,系统累积的公差,是怎么解决的?是连接器吸收的?2022-03-05 25909
-
从固定互联网到移动互联网2012-08-06 2280
-
语音网络架构的演进2021-12-13 5076
-
SDN网络到ADN网络该如何演进2022-10-14 1551
-
一文解析Nvlink的诞生和技术演进历程2023-07-03 6375
-
什么是 NVLink?2023-10-27 2027
-
NVLink的演进2023-10-11 5100
-
分布式通信的原理和实现高效分布式通信背后的技术NVLink的演进2024-11-18 2848
-
动态IP技术演进:从网络基石到智能连接时代的创新引擎2025-05-20 1004
全部0条评论

快来发表一下你的评论吧 !
