

基于网络的嵌入式IP可视电话设计方案
通信设计应用
描述
引 言
由于成本和视频通信质量的因素,可视电话从推出到现在,一直受到用户的冷落。现在因为技术的进步和宽带因特网的普及,可视电话呈现出新的生机。业内专家预测,未来几年内,可视电话不仅可与电信固话、小灵通、移动/联通手机互联,还可与3G 手机互通。可视电话将成为独立的产业,发展前景良好。
笔者基于TI公司的单颗600 MHz TMS320DM643(简称为DM643)数字媒体处理器,开发了一套性能优异、价格低廉的嵌入式IP可视电话,实现点对点网络音视频实时通信。
1 基于TMS320DM643的硬件设计
DM643数字媒体处理器[1]集成了一系列外设,以适应视频和影像技术的发展。其中包括3个可配置视频端口,1个10/100 Mbps的以太网MAC(EMAC),1个面向音频应用的串行口(McASP),1个串行口(McBSP)以及一些其他外设。C64x核内有8个并行的处理单元,采用VLIW(甚长指令集)结构,处理能力高达4800MIPS,并在C6OOO公共指令集的基础上扩展了88条指令。这些指令使C64x能够更方便地执行图象处理中的算法。
基于单颗DM643的嵌入式IP可视电话的组成如图1所示。从摄像机输入的视频信号和从麦克风输入的音频信号经A/D转换后送入DSP,DSP对音/视频信号进行压缩、编码、合流;然后通过局域网或因特网将数据传输出去,同时将从网络上接收的数据分流,并分别进行视频信号的解码显示和音频信号的解码播放。系统中,还通过DM643的McBSP/UART 口外接了一个键盘,以实现电话的拨号功能。
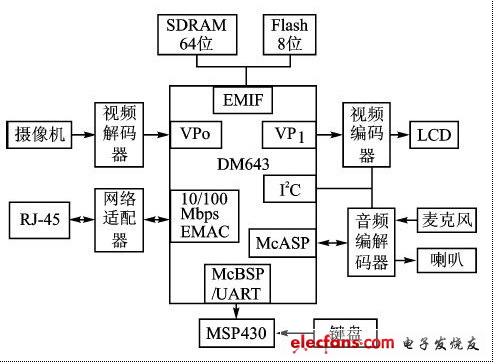
图1:嵌入式IP可视电话的组成
1.1 视频采集电路
本系统采用的视频解码芯片是Philips公司的SAA7l15.从摄像机输入的全电视信号在SAA7l15内部经过钳位、抗混叠滤波、A/D转换、YuV分离电路之后,在YuV到YCrCb的转换电路中转换成BT.656视频数据流,通过DM643的视频口VPo输入到压缩核心单元DM643中。视频数据的行/场同步信号包含在BT.656数字视频数据流的EAV(End of Active Video)和SAV(Startof Active Video)时基信号中,视频口只需视频采样时钟和采样使能信号。SAA7l15内部寄存器参数的配置和状态的读出通过1 C总线进行。视频采集接口的原理如图2所示。
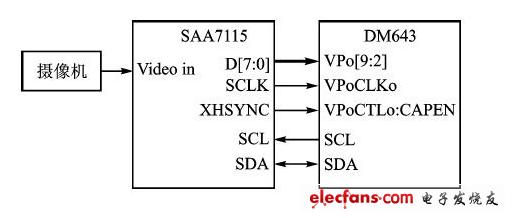
图2:视频采集口原理
DM643将解码后的视频数据通过视频口VP1通道送给SAA7121显示输出。SAA7121是Philips公司的一款视频编码芯片,可实现数字视频的D/A 变换。SAA7121的工作模式由其内部的控制寄存器决定,控制寄存器的初始化通过1 C总线完成。DM643利用自身具有的1 C总线模块,作为主控制器,对SAA7121进行参数编程控制。
1.3 音频输入/输出电路
本系统采用TI的高性能立体声编/解码器TI V320AIC23(简称AIC23),实现音频信号的采集和播放。AIC23与DM643的I/0电压兼容,可实现与DM643的McASP接口无缝连接。
在本系统中,AIC23工作于主模式,左右声道的采样字宽均为16位。数据接口为DSP mode模式。通过12 C总线设置内部寄存器的工作参数和反馈状态信息。
由于网络传输的固有特点,音频数据和视频数据传输到接收方时不可能是均匀的。如果发送方不作任何纠正处理,则很难保证音/视频的同步输出。为了实现音频和视频的采样同步,利用锁相环PI I 1708.从SAA7115的U C引脚输出27 MHz时钟,经PLI 1708的SCKO 3引脚输出默认时钟频率18.433 MHz,作为AIC23的输入主时钟MCI K.AIC23内部采用的时钟可通过设置寄存器由主时钟MCLK分频得到。由于音视频采样信号采用同一个时钟源,因此不会出现音/视频不同步的问题。
1.4 以太网接口电路
本系统用LXT971作为快速以太网物理层自适应收发器。LXT971支持IEEE 802.3标准,提供MII(MediaIndependent Interface)接口,可以支持MAC;而DM643内部正好集成有MAC控制器,所以LXT971可与DM643实现无缝连接。连接电路如图3所示,其中BH1102为1:1的隔离变压器。
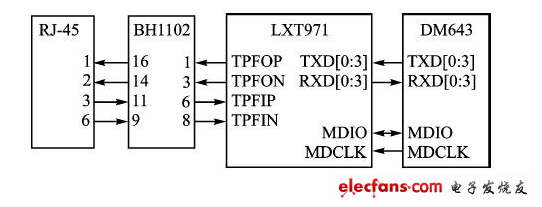
图3:网络接口原理
1.5 存储器扩展电路
DM643通过EMIF接口扩展了2片32 MB的SDRAM来存放原始图像数据,1片4 MB的Flash来存放应用程序。二者都映射到DM643的外部数据空间。
2 软件实现和优化
在本系统中,视频编/解码算法采用H.264标准[2],音频编解码算法采用G.723.1a,回音消除采用G.167,媒体协议采用RTP/RTCP,网络协议采用TCP/UDP/IP,通信协议采用H.323v.4;另外还软件实现了静音、电话功能,并运用抖动缓冲媒体同步技术实现了各种网络状况下的音唇一致。操作系统采用基于DSP/B10S的TI参考架构5(RF5)。基于RF5操作系统的应用程序模块主要包括:音/视频采集模块、音/视频编解码模块、UART控制模块和网络传输模块。
本系统采用的H.264编/解码可大大提高图像质量或降低像通信带宽。同等图像质量,H.264算法比H.263算法码流降低了5O ;但同时H.264算法比H.263算法复杂得多,需要更强的处理能力,以及做更多的软件优化工作。H.264算法在DM643上的实现和优化是整个系统软件设计的难点和重点。下面以它为例说明软件的开发、优化工作。
DM643上的软件开发过程可分为3个阶段:
第1阶段是开发C代码,然后使用profiling工具确定代码可能存在的低效率段。为进一步改进代码性能,需进入第2阶段。
第2阶段是优化C代码。利用内联函数、编译器的外壳选项等方法进一步优化C代码。再次使用profiling工具检查其性能,如果代码仍达不到所期望的效果,须进入第3阶段。
第3阶段是编写线性汇编代码 从C代码中抽出对性能影响很大的代码段,用线性汇编重新编写这段代码,然后使用汇编优化器优化该代码。
2.1 C代码的开发和优化
开发过程中要充分利用Tl公司为用户提供的功能强大的函数库,比如IMAGE.LIB库中就包含许多常用函数,可以实现DCT/IDCT变换、DCT量化、自适应滤波等功能。这些函数都是优化过的,完全能够实现软件流水,效率很高。另外,开发C语言代码还需要考虑的要点包括:① 使用适当的数据结构- - 对定点乘法,应尽可能使用short型数据;对循环计数器应使用int或者无符号int 类型。②使用查找表或常数值代替通过直接计算得到结果的语句或函数。
代码分析结果显示DCT、IDCT 、运动估计占程序总运算量的比重很大,因此这部分是程序优化的重点。优化C 代码包括使用编译器选项、使用内联函数、使用软件流水等。
(1)向编译器指明不相关的指令。
为使指令并行操作,编译器必须确定指令间的相关性,只有不相关的指令才可并行执行。若编译器不能确定两条指令是不相关的,则只能安排它们串行执行。用户可通过如下方法指明相关的指令:
①关键字cons t 表示一个变量或一个变量的存储单元保持不变,使用const 可提高代码的性能和适应性。
②使用-mt 选项向编译器说明在代码中不存在存储器相关性,即允许编译器在无存储器相关性的假设下进行优化。
(2)使用内联函数(intrinsics)。
可用内联函数快速优化C 代码。如在算术操作中,常对计算的结果做饱和(saturation)处理,使用intrinsics只须调用SADD, 一个指令周期便可得到最终结果。比花费两个嵌套的条件判断语句来判断结果是否溢出,最后得到结果效率要高得多。
(3)使用软件流水。
在编译时,使用-o2 选项和-o3 选项,编译器可对循环代码实现软件流水。为填满软件流水线,软件流水结构需要执行的最小循环迭代次数称为最小循环次数。循环总数小于最小循环次数时,执行不流水形式循环;循环总数大于最小循环次数时,执行软件流水形式循环。可以使用-ms 选项,使编译器根据循环次数仅产生一种循环形式; 可使用-o3 和-pm 选项,使优化器访问整个程序,了解循环次数信息; 使用-nassert 内联函数,防止冗余循环产生;使用-mh 选项,消除软件流水循环的排空,从而减小代码尺寸。
由于在嵌套循环中编译器仅对最里面的循环执行软件流水,因此对于执行周期很少的内循环进行循环展开,对外循环进行软件流水。
使用软件流水应当注意的问题: 尽管软件流水循环可以包含内联函数,但不能包含函数调用; 在循环中不使用break 语句;循环控制变量不能与循环体内的语句有关; 如果循环体内复杂的条件代码需要超过5 个条件寄存器或者32 个以上寄存器,则这个循环不可进行软件流水。
(4)片内存储器的分配及DMA技术的运用。
DM643 内部有16 KB 的一级程序缓存、16 KB 的一级数据缓存和256 KB 的程序数据共享二级缓存,远小于执行程序和待处理图像数据,不可能将程序和图像数据都在片内RAM 中缓存,因此合理地配置和使用存储空间,对系统整体效率影响很大。
提高算法程序执行速度的关键是使核心循环代码和要访问的数据在第1 次访问之后全部发生L1P 和L1D 命中。核心循环代码占的空间很小,执行过一次之后,完全可以全部在L1P 中缓存,因此,不用考虑代码如何在存储器中存放,主要问题是图像数据的存放。
由于L1D 采取LRU (Least Recently Used)分配机制,因此对于小于等于16 KB 的连续存放的数据块可完全在L1D 中命中。以解码过程为例,IDCT 和运动补偿模块都是以宏块为单位进行运算的,IDCT 数据类型为short型,运动补偿中的预测帧和当前帧的数据类型为unsignedchar 型。计算一个宏块(420 格式)的IDCT 和运动补偿要访问的数据大小共需1 536 字节,运动补偿的数据包括预测宏块和当前宏块的数据,实际解码中以6 个宏块(10 KB)作为1 次处理对象。待处理的数据要从外部存储器搬到L2 中连续的存储空间,可利用EDMA 与CPU 并行工作的特点,采取Ping??Pong 技术,使CPU 在处理Ping空间数据的同时,由EDMA 将下次要处理的数据搬到Pong 空间中; 当CPU 处理Pong 空间数据时,再由EDMA将Ping 空间已处理好的数据搬回外部存储器,并将下次要处理的数据搬到Ping 空间,这样就可达到CPU 的最大计算能力。Ping、Pong 空间各占用的大小为20 KB, 两个总共约40 KB.L2 中的剩余空间分出64 KB 留给数据空间,用于解码中常用的解码表、量化步长、输入压缩码流缓冲区和输出码流缓冲区等。64 KB 的程序空间用于存储H. 264 算法中的运动预测、运动补偿和中断服务程序等关键代码。L2 其余部分配置为Cache, 操作与L1D 类似。
2. 2 编写线性汇编代码
为了提高代码性能,对影响处理速度的关键C 代码段可以用线性汇编重新编写。线性汇编代码类似于汇编代码,不同的是线性汇编代码中不需要给出汇编代码必须指出的所有信息(如所使用的寄存器、指令的并行与否、指令的延迟周期和指令使用的功能单元等),汇编优化器会根据代码的情况确定这些信息。当然,如果能够事先确定一些信息(如循环的执行次数、存储区的地址等),则编写的线性汇编代码的效率更高。具体的优化措施如下:
①使用伪指令向汇编优化器提供较为详细的信息。
②画出指令的相关图,根据相关图合理分配逻辑单元,最大限度地保证指令的并行执行。
③充分使用C64x DSP 提供的强大包处理指令处理数据(包处理指令可同时处理2 个l6 位数据和4 个8 位数据)。本系统中使用了AVGU4、MIN2、M AX2、SPACKU4、PACK2、D0T P2、D0T PN2 和UNPKLU4 等指令。C64x DSP 还提供了STDW(STNDW)、LDDW(LDNDW)指令,可一次存取连续的64 位数据。可利用LDDW 指令,将作1 次行变换所需数据1 次取来,并将处理后的结果利用STDW 指令一次存好。这样大大缩短了代码长度,提高了代码效率。
④利用Schedule Table 确定循环的重复间隔,合理安排功能单元,进行软件的流水。
⑤对于两重循环嵌套,可将内层循环展开为外层循环内部的条件指令。这样可减小由内层循环所带来的循环前后的prolog 和epilog 的开销。
3 性能分析
设计、调试好硬件系统,并在DM643 上对整个系统软件进行设计和优化后,视/ 音频编/ 解码的处理速度及系统功能得到了很大提高。IP 可视电话基本做到话音清晰并实时传输,在网络速度为30 kbps 以上时能实现CIF 图像25~ 30 帧/ s, 并可以音唇同步。
结语
该系统能在一颗DM643 芯片上实现网络可视电话的几乎全部功能,能对音/ 视频进行实时的编解码和网络传输,图像质量高且易于升级,是一种比较理想的网络可视电话解决方案。下一步的工作是把短信、电子邮件等其他功能整合进来。这样,网络IP 可视电话必将成为家庭或办公室的真正桌面通信中心。
- 相关推荐
- 热点推荐
- 嵌入式
- TMS320DM643
- IP可视电话
-
什么是可视电话网线2024-08-16 2006
-
基于N-ISDN网络可视电话的一种实现方案2023-10-09 393
-
在RISC架构嵌入式平台上实现简单的无线可视电话设计2018-11-21 2643
-
关于嵌入式宽带可视电话系统的设计及实现方案2018-04-27 1061
-
基于ARM7的可视电话机设计2018-04-09 860
-
基于Windows CE的可视电话的研究与实现2016-04-18 1066
-
网络可视电话与IP可视电话有差异 混用存疑虑2013-04-25 1676
-
嵌入式H.324可视电话终端系统设计与实现2011-09-21 1267
-
可视电话接收显示是什么意思2010-03-06 3395
-
什么是可视电话/多点会议?2010-02-21 1142
-
可视电话遵从标准2009-12-31 1067
-
什么用户才能使用可视电话?2009-06-15 1578
全部0条评论

快来发表一下你的评论吧 !
