

CVPR'24 Highlight!跟踪3D空间中的一切!
描述
0. 这篇文章干了啥?
运动估计一直通过两种范式来处理:特征跟踪和光流。虽然每种方法都可以实现许多应用,但它们都不能完全捕捉视频中的运动:光流只能为相邻帧产生运动,而特征跟踪只能跟踪稀疏像素。
一个理想的解决方案将涉及在视频序列中估计密集和长程像素轨迹的能力。但当前的解决方案在挑战性场景中仍然存在困难,特别是在复杂变形伴随频繁自遮挡的情况下。这种困难的一个潜在原因在于仅在二维图像空间中进行跟踪,从而忽略了运动的固有三维性质。由于运动发生在三维空间中,某些属性只能通过三维表示来充分表达。例如,旋转可以用三维中的三个参数简洁地解释,遮挡可以简单地用z缓冲表示,但在二维表示中要复杂得多。图像投影可以将空间上远离的区域带到二维空间中,这可能导致用于相关性的局部二维邻域可能包含不相关的上下文(特别是在遮挡边界附近),从而导致推理困难。
为了解决这些挑战,作者建议利用最先进的单目深度估计器的几何先验,将二维像素提升到三维,并在三维空间中进行跟踪。这涉及在三维空间中进行特征相关性计算,为跟踪提供更有意义的三维上下文,特别是在复杂运动的情况下。在三维中跟踪还允许强制执行三维运动先验,例如ARAP约束。鼓励模型学习哪些点一起刚性移动可以帮助跟踪模糊或被遮挡的像素,因为它们的运动可以通过同一刚性组中相邻的清晰可见区域推断出来。
下面一起来阅读一下这项工作~
1. 论文信息
标题:SpatialTracker: Tracking Any 2D Pixels in 3D Space
作者:Yuxi Xiao, Qianqian Wang, Shangzhan Zhang, Nan Xue, Sida Peng, Yujun Shen, Xiaowei Zhou
机构:浙江大学、UC伯克利、蚂蚁集团
原文链接:https://arxiv.org/abs/2404.04319
代码链接:https://github.com/henry123-boy/SpaTracker
官方主页:https://henry123-boy.github.io/SpaTracker/
2. 摘要
视频中恢复密集且长距离的像素运动是一个具有挑战性的问题。部分困难来自于3D到2D的投影过程,导致2D运动领域出现遮挡和不连续性。虽然2D运动可能很复杂,但我们认为潜在的3D运动通常是简单且低维的。在这项工作中,我们提出通过估计3D空间中的点轨迹来减轻图像投影引起的问题。我们的方法,命名为SpatialTracker,使用单眼深度估计器将2D像素转换为3D,使用三平面表示高效地表示每一帧的3D内容,并使用变换器执行迭代更新来估计3D轨迹。在3D中进行跟踪使我们能够利用尽可能刚性(ARAP)约束,同时学习将像素聚类到不同刚性部分的刚性嵌入。广泛的评估表明,我们的方法在定性和定量上都实现了最先进的跟踪性能,特别是在诸如平面外旋转之类具有挑战性的场景中。
3. 效果展示
在三维空间中跟踪2D像素。为了估计遮挡和复杂3D运动下的2D运动,作者将2D像素提升到3D,并在3D空间中执行跟踪。

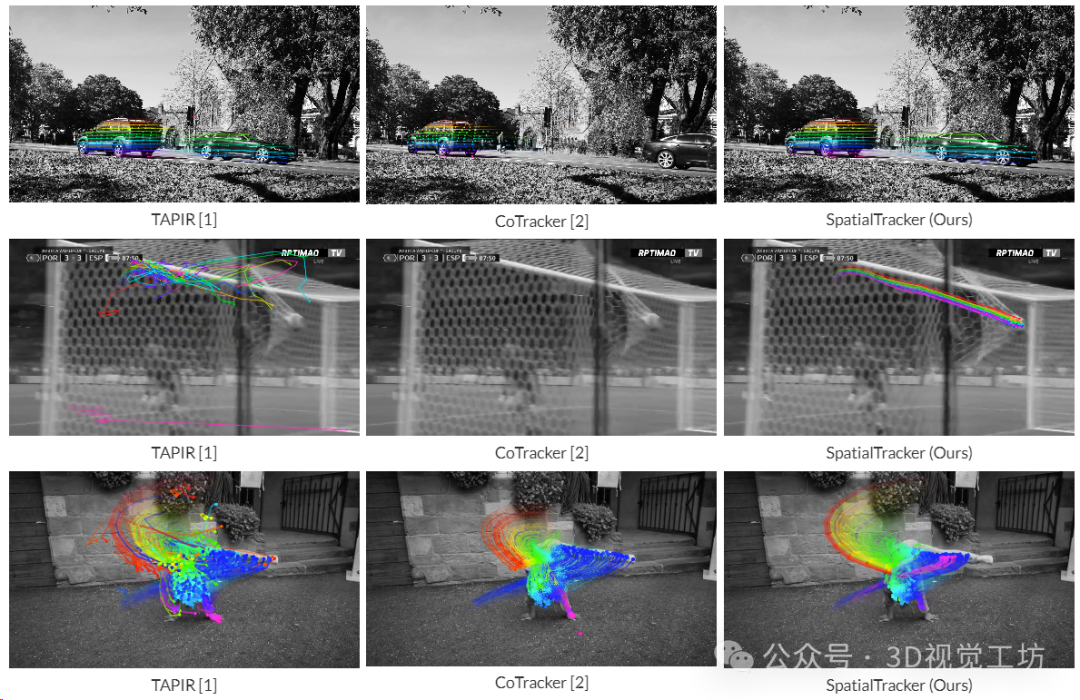
与TAPIR和Cotracker的2D跟踪进行比较。SpatialTracker可以处理具有挑战性的场景,如平面外旋转和遮挡。
视频中刚性部件的分割。SpatialTracker通过聚类它们的3D轨迹来识别场景中不同的刚性部分。

4. 主要贡献
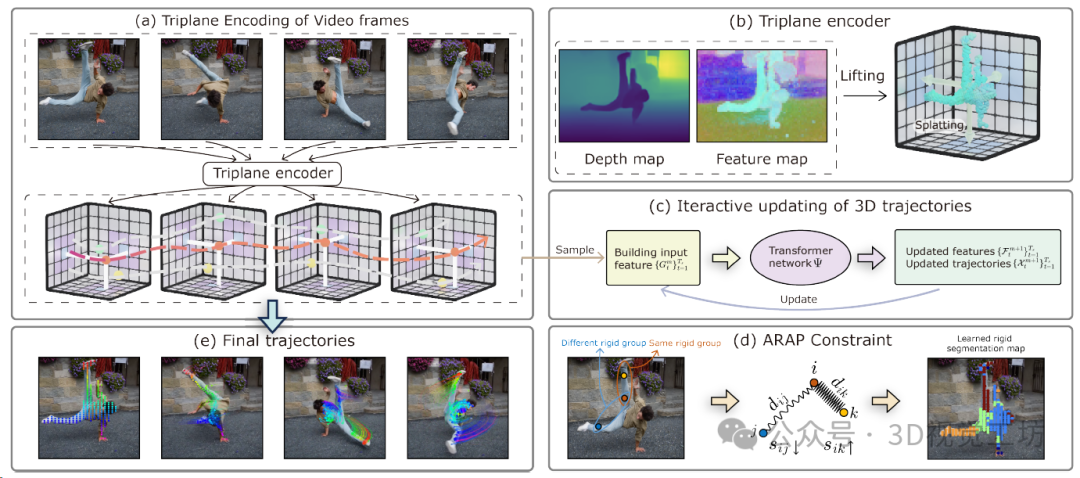
(1)作者建议使用三平面特征图来表示每个帧的三维场景,首先将图像特征提升到三维特征点云,然后将其喷洒到三个正交平面上。三平面表示紧凑而规则,适合学习框架。
(2)三平面在三维空间中密集覆盖,能够提取任何三维点的特征向量进行跟踪。然后,通过迭代更新使用来自三平面表示的特征的变压器预测的查询像素的三维轨迹。
(3)为了使用三维运动先验正则化估计的三维轨迹,模型另外预测了每条轨迹的刚性嵌入,这使能够软地分组表现出相同刚性体运动的像素,并为每个刚性集群强制执行ARAP正则化。作者证明了刚性嵌入可以通过自监督学习,并产生不同刚性部分的合理分割。
(4)模型在各种公共跟踪基准上实现了最先进的性能,包括TAP-Vid、BADJA和PointOdyssey。对具有挑战性的互联网视频的定性结果还表明了模型处理快速复杂运动和延长遮挡的出色能力。
5. 基本原理是啥?
Pipeline概述。首先使用三面编码器将每个帧编码为三面表示(a)。然后,使用从这些三面提取的特征作为输入,使用变换器在三维空间中初始化并迭代更新点轨迹(c)。三维轨迹使用地面真实注释进行训练,并通过具有学习到的刚性嵌入的尽可能刚性(ARAP)约束进行规范化(d)。ARAP约束强制要求具有相似刚性嵌入的点之间的三维距离随时间保持恒定。这里dij表示点i和j之间的距离,而sij表示刚性相似性。SpatialTracker即使在快速移动和严重遮挡下也能产生准确的远距离运动轨迹(e)。
6. 实验结果
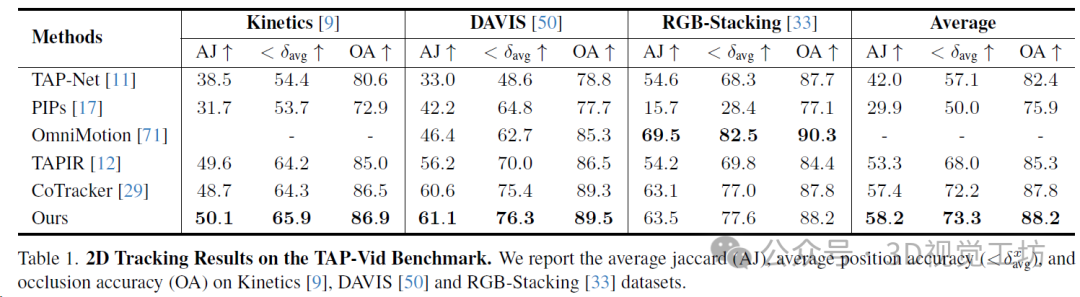
TAP-Vid基准包含几个数据集:TAPVid-DAVIS(约34-104帧的30个真实视频)、TAP-Vid-Kinetics(250帧的1144个真实视频)和RGB-Stacking(250帧的50个合成视频)。基准中的每个视频都使用真实2D轨迹和遮挡进行注释。使用与TAP-Vid基准相同的度量标准来评估性能:平均位置精度(<δavg)、平均Jaccard(AJ)和遮挡精度(OA)。SpatialTracker在所有三个数据集上一致优于所有基线方法,除了Omnimotion之外,展示了在3D空间中进行跟踪的好处。Omnimotion还在3D中执行跟踪,并通过一次性优化所有帧在RGB-Stacking上获得最佳结果,但这需要非常昂贵的测试时间优化。
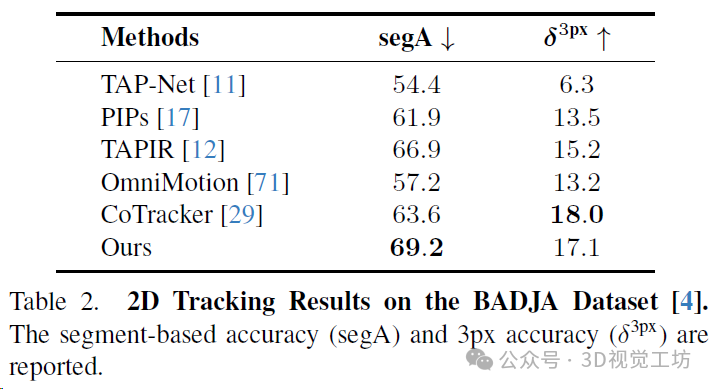
BADJA是一个包含七个带有关键点注释的动物移动视频的基准。此基准中使用的指标包括基于段的准确性(segA)和3px准确性(δ3px)。SpatialTracker在δ3px方面表现出有竞争力的性能,并在基于段的准确性上大幅超过所有基线方法。
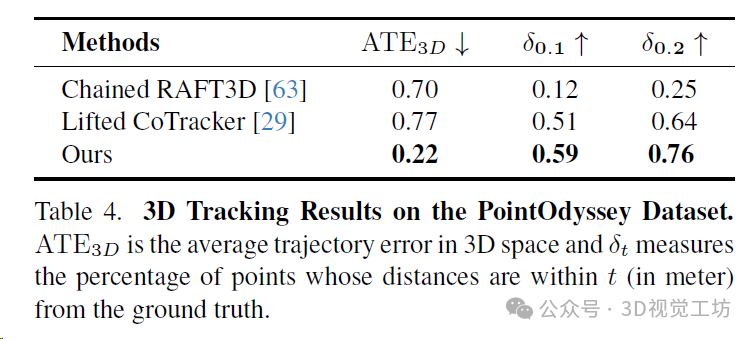
PointOdyssey是一个大规模的合成数据集,其中包含各种各样的动画人物,从人类到动物,置于不同的3D环境中。在PointOdyssey的测试集上评估,该测试集包含12个具有复杂运动的视频,每个视频大约有2000帧。采用PointOdyssey提出的评估度量标准,这些度量标准旨在评估非常长的轨迹。SpatialTracker在所有度量标准上一贯优于基线方法,并且优势明显。特别是,作者展示了通过使用更准确的地面真实深度,模型的性能可以进一步提升。这表明了SpatialTracker在单目深度估计的进步中持续改进的潜力。
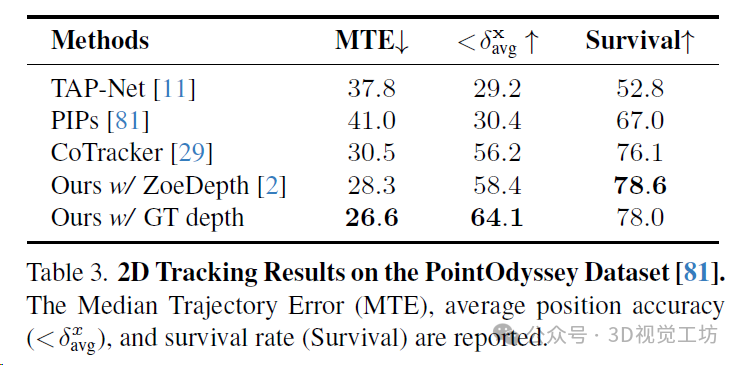
3D跟踪结果。
7. 总结 & 讨论
在这项工作中,作者展示了一个适当设计的三维表示对解决视频中稠密且远距离运动估计的长期挑战至关重要。运动自然发生在三维空间中,而在三维空间中跟踪运动使模型能够更好地利用其在三维空间中的规律,例如 ARAP 约束。作者提出了一个新颖的框架,使用可学习的 ARAP 约束,利用三面体表示来估计三维轨迹,该约束能够识别场景中的刚性群,并在每个群体内强制实施刚性。实验表明,与现有基线方法相比,SpatialTracker具有优越的性能,并适用于具有挑战性的真实世界场景。
SpatialTracker依赖于现成的单目深度估计器,其准确性可能会影响最终的跟踪性能。然而,作者预计单目重建技术的进步将提高运动估计的性能。这两个问题能够更密切地相互作用,相互受益。
-
[视频] 无触摸的3D跟踪界面2013-07-11 7604
-
Labview中如何导入3D 的模型2014-01-26 21069
-
自己搞一个3D打印机2016-06-14 36607
-
3D全息投影技术成舞台新宠2012-01-12 3391
-
3D打印:除了思想 一切皆可打印!2013-04-22 1647
-
3D视频目标分割与快速跟踪2017-01-07 956
-
如何把OpenGL中3D坐标转换成2D坐标2018-07-09 9368
-
3D感应技术TOF占用检测人体跟踪和人数统计2018-08-10 8686
-
Vimeo宣布推出“现场直播”功能,允许用户实时直播3D视频2018-10-18 5346
-
NVIDIA 3D MoMa:基于2D图像创建3D物体2022-06-23 2332
-
构建3D跟踪器开源分享2022-11-11 947
-
海尔智家:一切皆为用户体验!2023-04-25 1335
-
3D机器视觉基本原理及应用场景2023-06-02 4911
-
VR虚拟空间中的3D 技术2024-04-29 2298
-
OpenCV携奥比中光3D相机亮相CVPR 20242024-06-21 1729
全部0条评论

快来发表一下你的评论吧 !
