

CAM在FPGA上的最优化实现方案
可编程逻辑
描述
编 者 按
TCAM(Ternary content-addressable memory)在FPGA里并没有专门的资源,其在网络应用上是一个比较常见的资源。关于如何在FPGA中实现TCAM功能有不少的论文,在翻阅借鉴之后,本文就TCAM在FPGA上的最优化实现进行探讨。
01
TCAM基本原理
我们都知道RAM是根据地址查找对应的数据,而对于CAM,则恰好相反,是已知数据查找其对应的地址。像在网络报文处理里,根据报文的五元组的一些信息去查询其所属的规则地址,随后通过该地址去查询对应的RAM获取对应的Action信息。而TCAM,其只不过是在CAM的基础上引入了 X(don't care)状态。借助一篇论文里的图来说明:
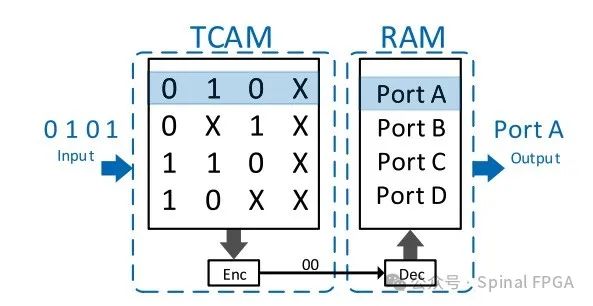
这里通过TCAM和RAM实现了一张路由表,输入报文通过TCAM获取对应的命中Entry地址,随后通过该地址查找RAM获取对应的端口信息。
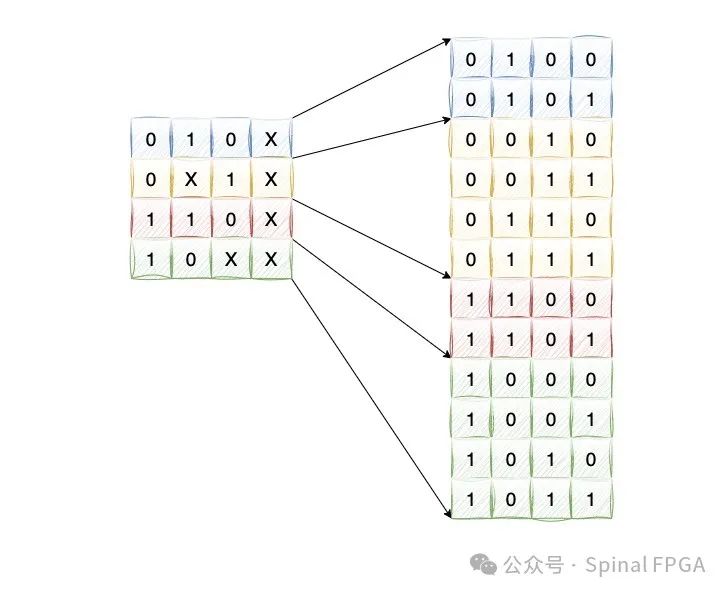
做逻辑设计的都清楚,X只存在于仿真中。在FPGA里不存在X态的概念。回到上面这个4输入的TCAM表中,X意味着0或者1都可以,那么这里就可以给出完整的表项:
在FPGA里,所具备的资源无非是LUT,RAM,寄存器。TCAM的结构本质上看更像是RAM类型的使用风格。针对Input的输入,如果我们将input key作为地址输入进行查找,每个RAM存储一个entry,RAM中存储是否命中当前Entry,四个Entry进行并行查找,那么四个entry ram 的存储结构就是:
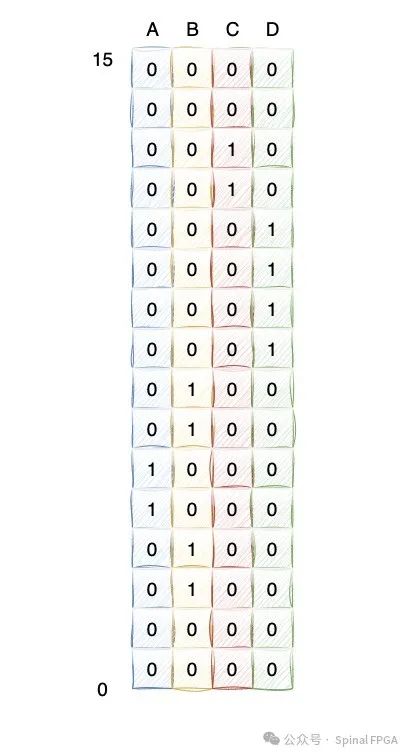
上面每一列对应一个Entry RAM存储表项。如果输入为0100(addr=4),那么在4个Entry RAM中,只有PortA RAM中地址4存储值为1,意味着命中PortA。对于input,我们同时查找4个RAM 得到四个查找,经过译码即可获取对应的命中结果。在FPGA中对应的结构即为:
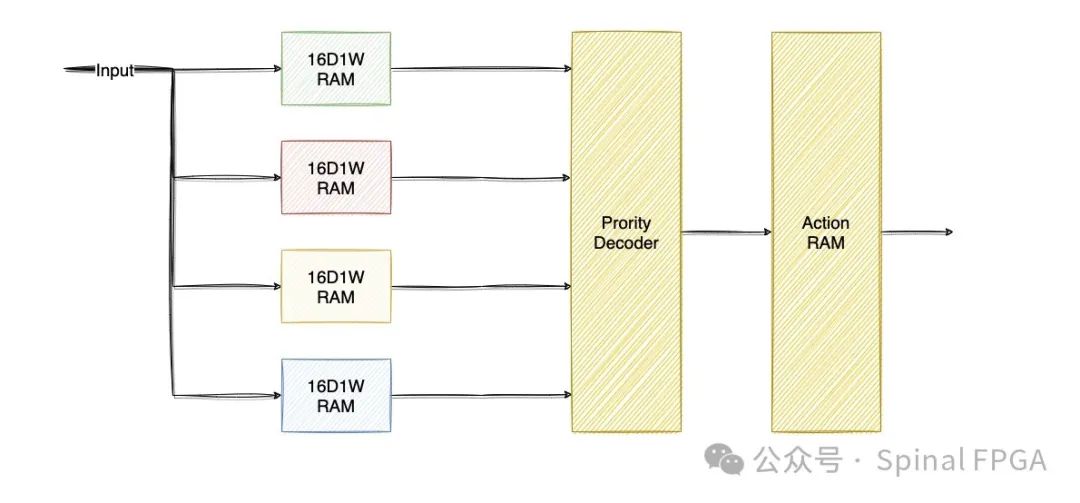
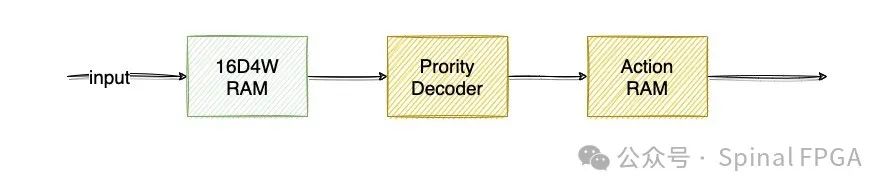
如此我们借助四个16D(Depth)1W(Width) RAM、一个Prority Decoder(用于判断选取哪个命中)、一个Action RAM实现了上面的一个简单的路由表。
更进一步,由于四个RAM的地址线是接到的同一个信号源,那么我们可以更进一步,将四个16D1W RAM合并成一个16D4W的RAM,每个Entry占据其中的一个比特用于存储对应的Entry RAM值:
02
input膨胀问题
通过上面的内容,大概能够明白,其实TCAM在FPGA上的实现基本就是一种暴力展开,对于input key,每个entry会遍历所有的key进行展开来判定是否命中。那么随之而来的就是input key width膨胀问题。按照上面的思路,每个entry需要存储的比特容量是1<
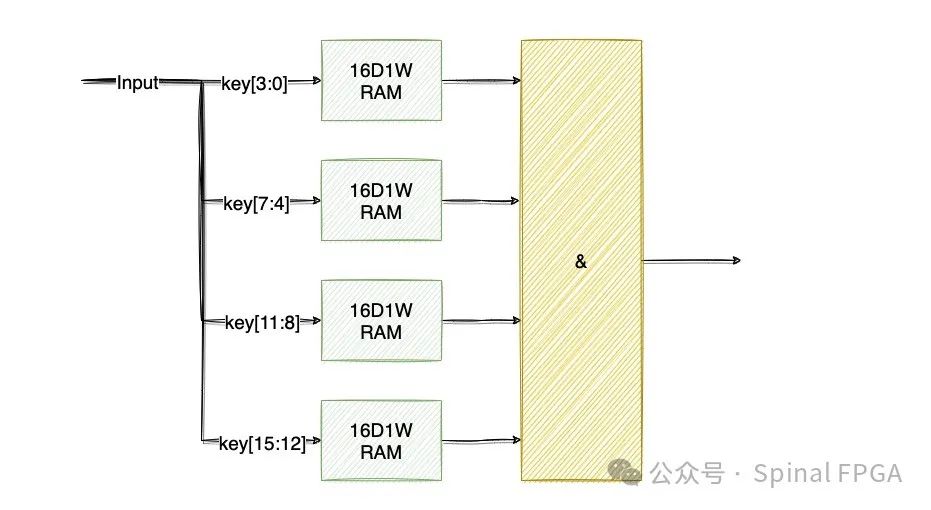
显然,无脑的展开势必带来资源的爆炸。那么,可以采用分而治之的思想。我们将key按比特进行拆分,每段key分别查询不同的ram,最终所有的RAM查询结构都为1则才表示命中。我们以16bit input key为例,则可以表述为:
如此,对于一个Entry的存储,其仅需4个16D1W存储空间加上一个&操作即可,共计64bit存储空间。
03
资源选取
到此,如何在FPGA中实现TCAM,其核心原理大概你已经相对来讲比较清楚了。那么回到具体的实现上。在FPGA中实现这种结构,我们所能采用的无外乎Block RAM或者LUT RAM来实现。那么究竟采用哪种资源更合适呢?先说结果:采用LUT RAM更合适。
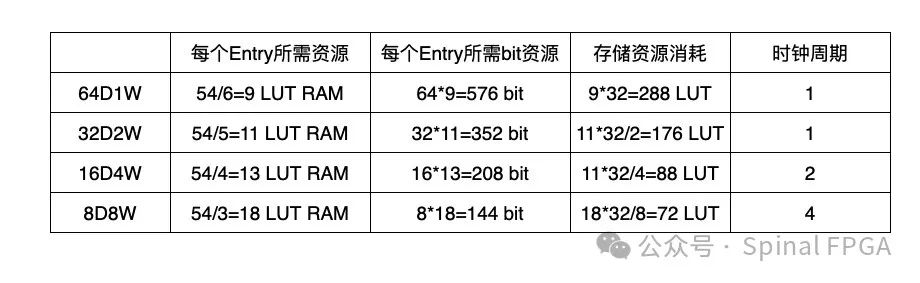
这里我们采用最常规的配置来进行说明。Block RAM可以配置成512D32W模式,LUT RAM采用64D1W模式。参照上面的结构,一个512D32W的Block RAM地址位宽为9,也就意味着其所能容纳的key width为9 bit。而64D1W所能容纳的key width为6 bit。
我们实现一个54 key width,32 entry的TCAM所需要消耗的资源分别为:
对比下来,采用LUT RAM每个Entry所消耗的存储资源远小于BlockRAM,而且采用BRAM33 Entry与64Entry所消耗的资源量是一致的。
除此之外,还有一个重要的点就是在TCAM的实现中,还牵涉到TCAM表项的插入。在这种结构里,每一个entry是在RAM的每个entry里占据一个比特。如果要插入一条表项,那就要将RAM所有的Entry进行更新,这里采用BRAM就带来表项的更新需要512个时钟周期,而LUT RAM仅需64个时钟周期,对于表项的插入速度显然也是LUT RAM也更具优势。
同时参照之前的文章《LUT RAM,Xilinx VS Altera》,无论是Xilinx还是Intel,都是可以将LUT RAM设置成32x2的模式,那么采用LUT RAM还能够进一步的资源优化:
04
性能/资源平衡
看到这儿,也许你已经意识到,RAM的深度越浅,其所消耗的资源也就越少。在上面的论述里,其相当于都是1拍出结果。对于FPGA跑三四百MHz的频率时,这么高的PPS可能不是我们所必需的。根据我们的设计需求,我们完全可以两拍或者四拍出一个结果,那么相当于可以将一个LUTRAM 变相的拆分成一个16D4W、8D8W的RAM,同样以上面的54 key width,32 entry为例:
除此之外,对于后面的Prority Decoder而言,单拍/两拍/四拍出结果对资源的消耗在随着Entry数的增加时所带来的资源节省也有着显著的降低。
审核编辑:黄飞


-
FPGA芯片用于神经网络算法优化的设计实现方案2020-09-29 6178
-
【PDF】最优化方法及MATLAB的实现2011-02-28 9764
-
Verilog 设计思想--模块划分最优化2013-09-11 7754
-
怎么利用Synphony HLS为ASIC和FPGA架构生成最优化RTL代码?2019-08-13 2700
-
什么是基于Spartan-3 FPGA的DSP功能优化方案?2019-10-18 1879
-
FPGA芯片_Gowin器件设计优化与分析手册2022-09-29 1041
-
用APEX 20KE 和Virtex 实现CAM 的比较2009-05-13 983
-
Ansoft软件在电机最优化设计中的应用2011-03-01 1617
-
基于SCA的软件无线电在FPGA上设计与实现2011-12-22 4940
-
基于FPGA的SM3算法优化设计与实现2015-10-29 964
-
在FPGA上实现CRC算法的程序2016-06-07 1150
-
混沌扩频SPWM最优参数选取方法及其在FPGA上的实时实现_朱少2017-01-08 681
-
爱立信性能优化器实现用户体验最优化2022-05-10 1878
-
FPGA设计如何最优化2023-06-25 1496
-
在FPGA上构建EVM硬件的实现2023-06-26 1407
全部0条评论

快来发表一下你的评论吧 !
