

先进节点上glitch功耗问题
描述
这个问题在 AI 加速器中尤为严重,修复这个问题需要一些tradeoff。
据估计,一些最先进和最复杂的芯片设计中总功耗的 20% 到 40% 被浪费了。
glitch功耗并不是一个新现象。在先进节点上,glitch功耗问题正变得越来越突出,没有一种解决方案适用于所有芯片或设计类型。
在组合电路中,时钟控制不同状态寄存器的传播。但是,在栅极或导线中经常存在延迟,因此输入不会同时到达栅极。
假设你有一个 AND 或 OR 门,你所有的信号不会同时到达,所以需要有一个允许范围内的稳定时间窗口。输入越多,发生这种情况的概率就越大,浪费的glitch功耗就越多。
这种现象也被称为hazards。hazards是电路中可能产生这种glitch的原因。根据逻辑的类型,如果存在非常宽的扇入逻辑,或者非常长深度的组合逻辑,那么这些glitch发生的可能性就更高。glitch是非常高频率的东西,它们toggle,然后几乎立即关闭,这种情况可能在任何地方发生多次。
AI 加速器中的glitch
对于 AI 加速器来说,这个问题尤其麻烦,因为 AI 加速器旨在以最小的功耗实现最大的性能。
在神经网络处理硬件中,有很多乘法累加计算。事实上,许多神经网络处理器的评级标准是每秒执行数以百万计的MAC,这是性能的衡量标准。但是,如果你看一下硬件乘法器和加法器的传统设计,并且这些类型的电路串联在一起,并采用流水线连接。发生的情况是,即使在单个时钟周期内,也发生了很多这些信号转换。由于不同电路的不同延迟,最终稳定下来,得出最终结果。
由于电路的设计方式,这些神经网络处理器中的乘法器非常容易出现glitch功耗,并且需要多次转换才能稳定到最终结果。
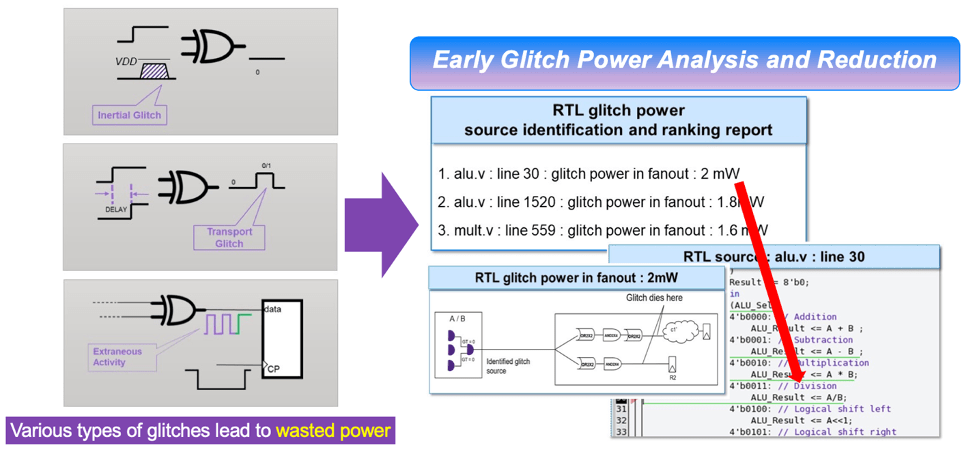
glitch源识别和排序
整体效率
Glitch 也会影响设计的整体效率。当你切换某些东西时,它使用来自电压源的能量,一直到引脚,但也使用存储在网络电容中的能量。因此,如果你像这样打开和关闭,你就会不必要地充电和放电这些电容器。
由于 RC 延迟增加,先进工艺使情况变得更糟。在先进节点中,晶体管越来越小,延迟开始由RC部分主导。当进入越来越先进的节点时,这些小晶体管必须驱动这些大负载,信号延迟和变化的机会就越多。
如果在线路中存在hazards,就会增加发生glitch的可能性。由于两个输入信号的到达时间不同,因此出现了输出glitch。
很多时候这个glitch的传播实际上影响更大,对于芯片设计师来说,更令人担忧的是它的下游影响,因为这种glitch不仅仅停留在那个信号上。这就是事情变得非常复杂的地方。很多时候它可以向下游传播,因为组合逻辑是多级的。如今,数据路径更深,时钟频率更快。数据路径可以深达 15 或 20 级,该信号的glitch可以一直传播,并导致它通过的每个栅极的功耗浪费。
过去,对glitch功耗的担忧并不多,因为它在总动态功耗中占比不大。但是,我们开始在7nm左右看到的情况,组合逻辑路径开始变得如此之深,以至于glitch功耗成为一个大问题。突然之间,在某些设计中,它占总动态功耗的 25% 到 40%。
审核编辑:黄飞
-
CYBT-213043-MESH如何降低低功耗节点的电流消耗?2025-07-04 5040
-
如何减小unbuffered ADC sampling glitch?2025-01-17 446
-
如何在低功耗Bluetooth® PEPS系统中添加CAN节点2022-11-09 767
-
美光正式出货全球最先进的 1β技术节点DRAM2022-11-02 1890
-
在低功耗 Bluetooth® PEPS 系统中添加 CAN 节点2022-10-31 664
-
5nm及更先进节点上FinFET的未来:使用工艺和电路仿真来预测2022-05-27 956
-
5nm及更先进节点上FinFET的未来2022-05-05 2783
-
低功耗无线传感器网络节点设计与实现2021-06-23 1416
-
先进工艺节点下的芯片设计需考虑更多变量2021-05-06 3306
-
一文读懂蓝牙网状网络什么是“友邻节点”与低功耗2017-11-12 8760
-
电机温度监测系统低功耗无线节点的模块设计2017-09-26 890
-
电机温度监测系统低功耗无线节点模块设计2017-09-25 805
-
在40-nm工艺节点实现世界上最先进的定制逻辑器件2010-02-04 1762
-
用于油管检漏的WSNs节点低功耗设计2010-01-18 696
全部0条评论

快来发表一下你的评论吧 !
