

CNN如何解决边缘检测问题
人工智能
描述
研究人员在研究图像处理算法时提出了CNN(卷积神经网络)的概念。传统的全连接网络是一种黑盒子 - 它接收所有输入并通过每个值传递到一个dense 网络,然后再传递给一个热输出。这似乎适用于少量的输入。
当我们处理1024x768像素的图像时,我们输入3x1024x768 = 2359296个数字(每个像素的RGB值)。使用2359296个数字的输入向量的dense多层神经网络在第一层中每个神经元至少具有2359296个权重 - 第一层的每个神经元具有2MB的权重。对于处理器以及RAM,在20世纪90年代和2000年除,这几乎是不可能的。
这导致研究人员想知道是否有更好的方法来完成这项工作。任何图像处理(识别)中的第一个也是最重要的任务通常是检测边缘和纹理。接下来是识别和处理真实对象。很明显要注意检测纹理和边缘实际上并不依赖于整个图像。人们需要查看给定像素周围的像素以识别边缘或纹理。
此外,用于识别边缘或纹理的算法在整个图像中应该是相同的。我们不能对图像的中心或任何角落或侧面使用不同的算法。检测边缘或纹理的概念必须相同。我们不需要为图像的每个像素学习一组新参数。
这种理解导致了卷积神经网络。网络的第一层由扫描图像的小块神经元组成 - 一次处理几个像素。通常这些是9或16或25像素的正方形。
CNN非常有效地减少了计算量。小的“filter/kernel”沿着图像滑动,一次处理一小块。整个图像所需的处理非常相似,因此非常有效。
虽然它是为图像处理而引入的,但多年来,CNN已经在许多其他领域中得到应用。
一个例子
现在我们已经了解了CNN的基本概念,让我们了解数字的工作原理。正如我们所看到的,边缘检测是任何图像处理问题的主要任务。让我们看看CNN如何用于解决边缘检测问题。
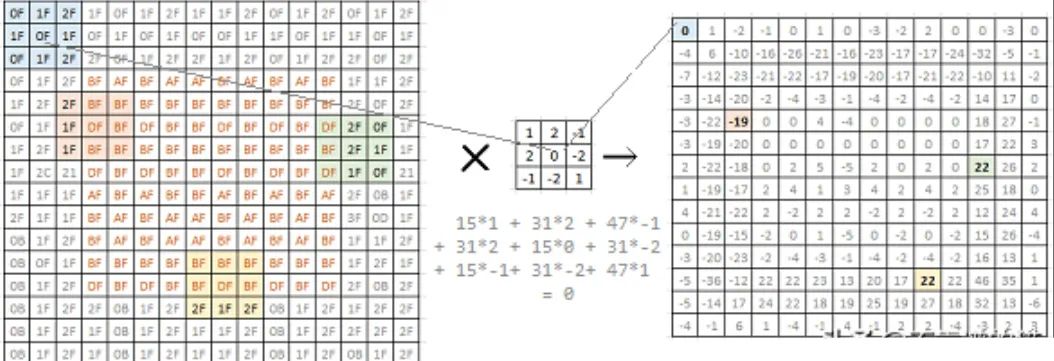
左边是16x16单色图像的位图。矩阵中的每个值表示相应像素的亮度。我们可以看到,这是一个简单的灰色图像,中间有一个方块。当我们尝试将其用2x2 filter(中图)进行卷积时,我们得到一个14x14的矩阵(右图)。
我们选择的filter 可以突出显示图像中的边缘。我们可以在右边的矩阵中看到,原始图像中与边缘对应的值是高的(正的或负的)。这是一个简单的边缘检测filter。研究人员已经确定了许多不同的filter,可以识别和突出图像的各个不同方面。在典型的卷积神经网络(CNN)模型开发中,我们让网络自己学习和发现这些filters。
重要概念
以下是我们在进一步使用CNN之前应该了解的一些重要概念。
Padding
卷积filter的一个明显问题是每一步都通过减小矩阵大小来减少“信息” - 缩小输出。基本上,如果原始矩阵是N×N,并且filter是F×F,则得到的矩阵将是(N-F + 1)×(N-F + 1)。这是因为边缘上的像素比图像中间的像素少。
如果我们在所有边上按(F - 1)/ 2像素填充图像,则将保留N×N的大小。
因此,我们有两种类型的卷积,即Valid Convolution和 Same Convolution。Valid 实质上意味着没有填充。因此每个卷积都会导致尺寸减小。Same Convolution使用填充,以便保留矩阵的大小。
在计算机视觉中,F通常是奇数。奇数F有助于保持图像的对称性,也允许一个中心像素,这有助于在各种算法中应用均匀偏差。因此,3x3, 5x5, 7x7 filter是很常见的。我们还有1x1个filter。
Strided
我们上面讨论的卷积是连续的,因为它连续扫描像素。我们也可以使用strides - 通过在图像上移动卷积filter时跳过s像素。
因此,如果我们有nxn图像和fxf filter并且我们用stride s和padding p进行卷积,则输出的大小为:((n + 2p -f)/ s + 1)x((n + 2p -f)/ s + 1)
卷积v / s互相关
互相关基本上是在底部对角线上翻转矩阵的卷积。翻转会将关联性添加到操作中。但在图像处理中,我们不会翻转它。
RGB图像上的卷积
现在我们有一个nxnx 3图像,我们用fxfx 3 filter进行卷积。因此,我们在任何图像及其filter中都有高度,宽度和通道数。任何时候,图像中的通道数量与filter中的通道数量相同。这个卷积的输出有宽度和高度(n-f + 1)和1通道。
多个filters
一个3通道图像与一个3通道filter卷积得到一个单一通道输出。但我们并不局限于一个filter。我们可以有多个filters——每个filter都会产生一个新的输出层。因此,输入中的通道数应该与每个filter中的通道数相同。filters的数量和输出通道的数量是一样的。
因此,我们从3个通道的图像开始,并在输出中以多个通道结束。这些输出通道中的每一个都表示图像的某些特定方面,这些方面由相应的filter拾取。因此,它也被称为特征而不是通道。在一个真正的深层网络中,我们还添加了一个偏差和一个非线性激活函数,如RelU。
池化层
池化基本上是将值组合成一个值。我们可以有平均池,最大池化,最小化池等。因此,使用fxf池化的nxn输入将生成(n/f)x(n/f)输出。它没有需要学习的参数。
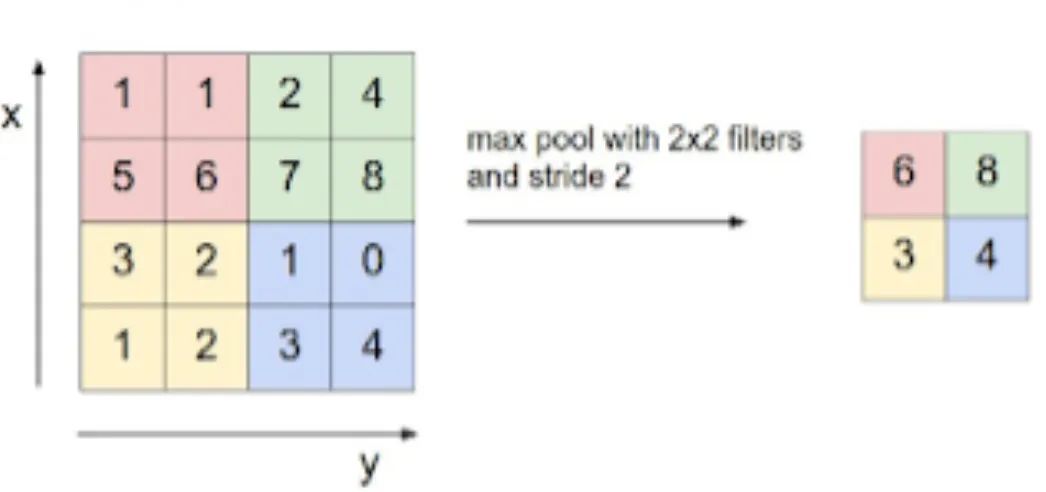
最大池化
CNN架构
典型的中小型CNN模型遵循一些基本原则。

典型的CNN架构
交替卷积和池化层
逐渐减小frame 大小并增加frame 数,
朝向末端的Flat 和全连接层
对所有隐藏层激活RelU,然后为最终层激活softmax
随着我们转向大型和超大型网络,事情变得越来越复杂。研究人员为我们提供了更多可以在这里使用的具体架构(如:ImageNet, GoogleNet和VGGNet等)。
Python实现
通常实现CNN模型时,先进行数据分析和清理,然后选择我们可以开始的网络模型。我们根据网络数量和层大小及其连接性的布局提供架构 - 然后我们允许网络自己学习其余部分。然后我们可以调整超参数来生成一个足以满足我们目的的模型。
让我们看一个卷积网络如何工作的简单例子。
导入模块
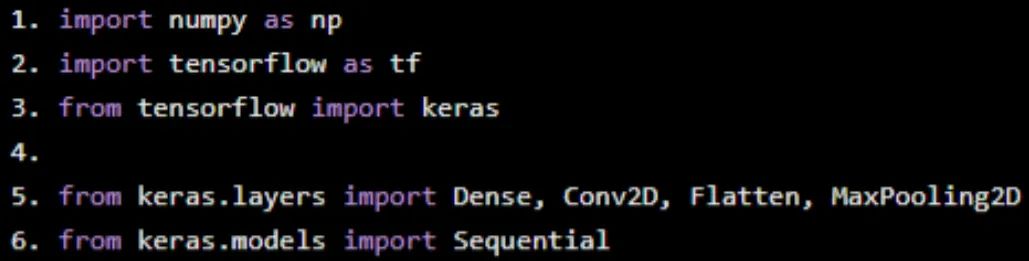
我们首先导入所需的Python库。
import numpy as np import tensorflow as tf from tensorflow import keras from keras.layers import Dense, Conv2D, Flatten, MaxPooling2D from keras.models import Sequential
获取数据
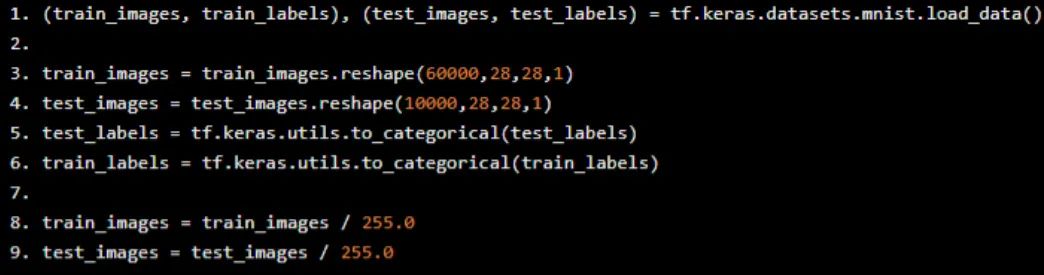
下一步是获取数据。我们使用构建到Keras模块中的机器学习数据集——MNIST数据集。在现实生活中,这需要更多的处理。
我们加载训练和测试数据。我们reshape数据,使其更适合卷积网络。基本上,我们将其reshape为具有60000(记录数)大小为28x28x1的4D数组(每个图像的大小为28x28)。这使得在Keras中构建Convolutional层变得容易。
如果我们想要一个dense 神经网络,我们会将数据reshape为60000x784 - 每个训练图像的1D记录。但CNN是不同的。请记住,卷积的概念是2D - 因此没有必要将其flattening 为1维数组。
我们还将标签更改为分类的one-hot数组,而不是数字分类。最后,对图像数据进行归一化处理,以降低梯度消失的可能性。
(train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data() train_images = train_images.reshape(60000,28,28,1) test_images = test_images.reshape(10000,28,28,1) test_labels = tf.keras.utils.to_categorical(test_labels) train_labels = tf.keras.utils.to_categorical(train_labels) train_images = train_images / 255.0 test_images = test_images / 255.0
构建模型
Keras库为我们提供了准备使用API来构建我们想要的模型。我们首先创建Sequential模型的实例。然后,我们将层添加到模型中。第一层是卷积层,处理28x28的输入图像。我们将核大小定义为3并创建32个这样的核 - 创建32 frames 的输出 - 大小为26x26(28-3 + 1 = 26)
接下来是2x2的最大池化层。这将尺寸从26x26减小到13x13。我们使用了最大池化,因为我们知道问题的本质是基于边缘 - 我们知道边缘在卷积中显示为高值。
接下来是另一个核大小为3x3的卷积层,并生成24个输出frames。每frame的大小为22x22。接下来是卷积层。最后,我们将这些数据flatten 并将其输入到dense 层,该层具有对应于10个所需值的输出。
model = Sequential() model.add(Conv2D(32, kernel_size=3, activation='relu', input_shape=(28,28,1))) model.add(MaxPooling2D(pool_size=(3, 3))) model.add(Conv2D(24, kernel_size=3, activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(10, activation='softmax')) model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
训练模型
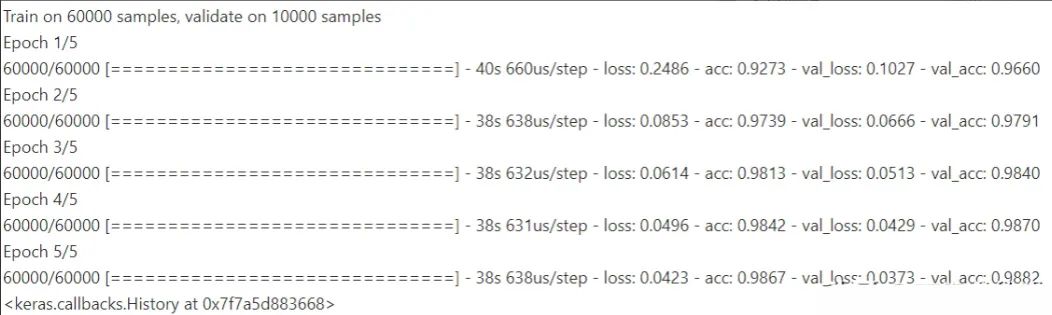
最后,我们用我们拥有的数据训练机器学习模型。五个epochs足以获得一个相当准确的模型。
model.fit(train_images, train_labels, validation_data=(test_images, test_labels), epochs=5)
最后
上面的模型只有9*32 + 9*24 = 504个值需要学习。全连接网络在第一层本身需要每个神经元784个权重!因此,我们大大节省了处理能力 - 同时降低了过度拟合的风险。请注意,我们使用了我们所知道的,然后训练模型来发现其余部分。使用全连接或随机稀疏网络的黑盒方法永远不会以这个成本获得这样的准确性。
审核编辑:黄飞
-
基于FPGA的实时边缘检测系统设计,Sobel图像边缘检测,FPGA图像处理2024-05-24 3493
-
[5.1.1]--边缘检测方法_clip002jf_90840116 2022-12-16
-
labview 边缘检测2011-12-07 3462
-
Labview 边缘检测2011-12-26 7705
-
求大神指点(边缘检测)2017-12-14 9302
-
基于Qualcomm FastCv的边缘检测算法详解2018-09-21 3324
-
TF之CNN:CNN实现mnist数据集预测2018-12-19 3143
-
Labview图像处理——边缘检测2020-12-01 6939
-
边缘检测的几种微分算子2021-07-26 2145
-
openCV边缘检测原理是什么?2023-10-10 574
-
内积能量与边缘检测2011-05-19 772
-
什么是边缘检测?边缘检测的算法由来2021-03-12 10035
-
基于日志信息和CNN-text的软件系统异常检测2021-06-01 953
-
基于CNN分类回归联合学习等的左心室检测方法2021-06-25 1085
-
PyTorch教程-14.8。基于区域的 CNN (R-CNN)2023-06-05 1764
全部0条评论

快来发表一下你的评论吧 !
