

AWS HPC为什么不用Infiniband?有何原因?
描述
HPC的低延迟需求来自于很多应用都会通过网格刨分来进行并行运算,然后网格间有复杂而频繁的通信数据交互,Brain将其称为“Ghost Cell Exchange”。
因此很多HPC系统将单个报文的延迟(Single packet latency)放在第一位,这也是Infiniband/RoCEv1/RoCEv2非常在意报文大小和HPE Cray构建HPC Ethernet的原因。
在AWS EFA的实践来看,单个报文的延迟并不是问题,而更重要的是网络中的拥塞冲突带来的长尾延迟。通过SRD来解决了几个问题:
多路径降低拥塞冲突概率
多路径解决链路失效等问题
MPI的很多操作不需要Reliable Connection的通信语义严格保序
解决QP数量多的爆炸问题
关于不兼容RC语义的原因:从Brain的履历也能大概看出来,由于Brain大量的OpenMPI的开发经历,所以在构建SRD时选择了不和标准的RC语义兼容,这也给后续的生态带来了一些问题。
1. 不使用Infiniband的原因
访谈中Brain介绍了一些原因: "云数据中心很多时候是要满足资源调度和共享等一系列弹性部署的需求,专用的Infiniband网络构建的集群如同在汪洋大海中的孤岛" 并且国外HPC需求较国内高的原因在访谈中也介绍了:国外并没有太多的线下机房,通常一些HPC任务需要在一些超算集群排队数周,如果有一个性能差不多的云上环境,对客户而言很有吸引力。
2. 应用性能
从应用性能来看,Brain的观点是单个报文的延迟(Single packet latency)并没有那么的重要,更重要的是实现长尾延迟的避免,例如Star-CCM+的测试报告《EFA-enabled C5n instances to scale Simcenter STAR-CCM+》[2], 在3000核时加速比都还非常好。
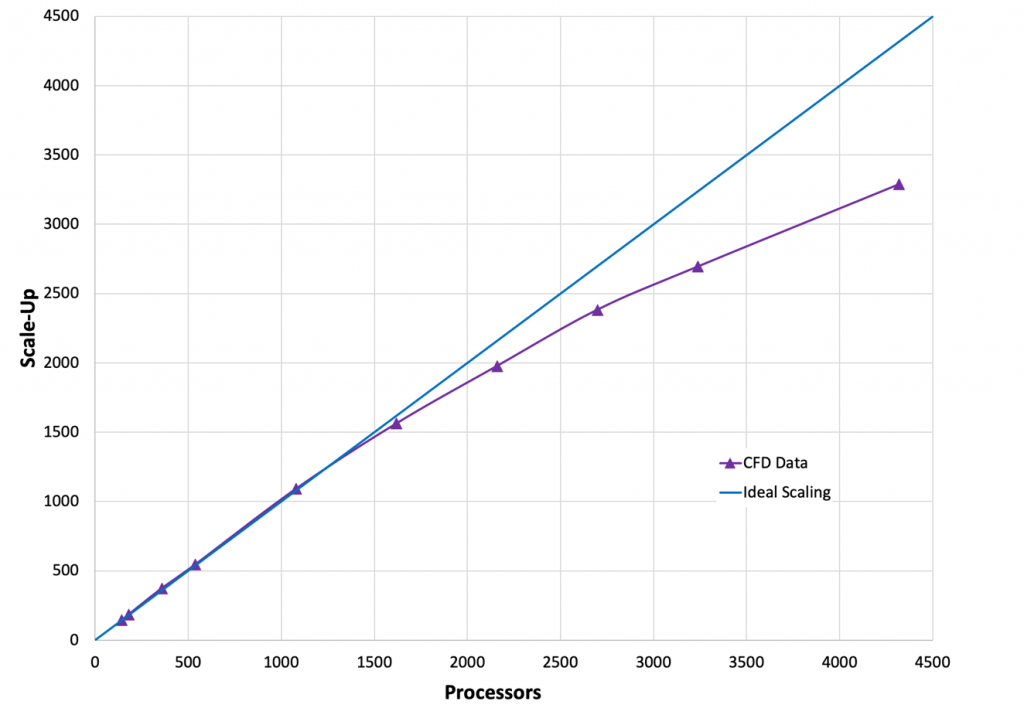
ANSYS Fluent性能也非常好。
访谈中Brain还提到高性能存储是影响HPC应用的另一个关键因素,因此构建了FSx for Lustre的支持。

3. 一些缺点和争议
AWS通过Reliable Datagram实现了多路径的支持能力,但是似乎国内很多人把这个事情搞混了,虽然传输语义上实现了可交换,但是基于Reliable Connection语义Verbs兼容的情况下依旧可以实现多路径的处理,而且这个技术在2002年IETF提出iWARP时构建的Direct Data Placement(DDP)就已经讨论的很清楚了。
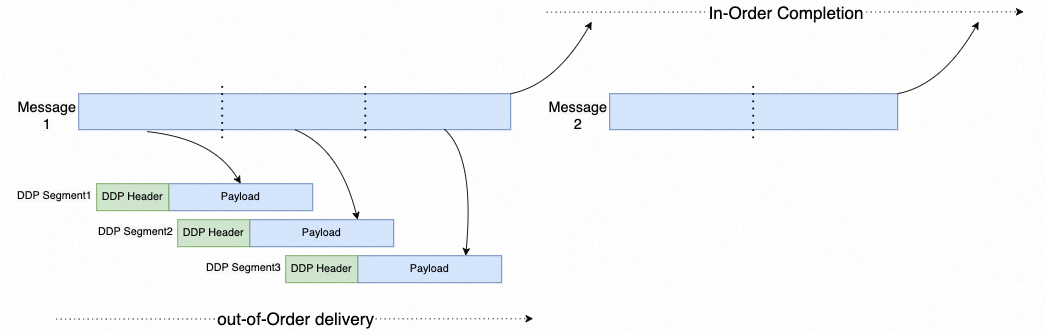
另外在HPC这个领域,特别是在国内部门间的通信壁垒非常高,很多从业者材料/物理/机械这些专业毕业的,对于HPC软件和相应的求解器只会使用,而IT等部门通常也只是使用商用软件测试招标,相应的算法和通信等优化的团队较少,并且企业通常因为软件授权价格等问题停留在较老的软件版本上。针对这些商用软件生态兼容使得RD这样的语义带来了很多负担。
审核编辑:刘清
-
InfiniBand 连接现在和未来2009-11-13 3651
-
InfiniBand系统级调试2019-09-10 1518
-
是何原因导致的STM32的重启2021-08-02 3781
-
是何原因导致的STM32程序仿真重启2021-09-24 2094
-
为什么我不能下载spc5studio呢?是何原因?2023-01-17 633
-
proteus中cpu负载过大无法仿真是何原因?怎么解决?2023-04-23 24459
-
modbus通讯延迟回复导致读取错位是何原因?2023-05-05 1698
-
InfiniBand,InfiniBand是什么意思2010-04-10 1404
-
实现InfiniBand网络优化自动化HPC管理工具2010-05-24 1084
-
是何原因造成芯片产业烂尾潮?2020-11-03 14603
-
半桥谐振LLC效率偏低是何原因?资料下载2021-04-05 1604
-
基于NVIDIA QM8700/8790交换机与HDR网卡的InfiniBand高性能网络解决方案2022-11-03 6643
-
关于InfiniBand网络相关内容简介!2023-03-21 2547
-
一文详解超算中的InfiniBand网络、HDR与IB2024-04-16 15737
-
InfiniBand网络内计算的关键技术和应用2024-10-23 1884
全部0条评论

快来发表一下你的评论吧 !
