

干货满满:ARM的内核寄存器讲解
嵌入式技术
描述
对于嵌入式开发者来说,了解汇编语言和内核寄存器是对内核深入理解的基础 从开始写起也没想到内容有这么多,其中有很多干货的东西,希望自己能够说明到了。
开头直接来看几个简单的汇编指令:
MOV R0,R1MOV PC,R14 上面的指令中使用了汇编 MOV指令,但是其中的 R0,R1,R14,PC分别是什么?哪来的?怎么用? 要讲 ARM 汇编语言,必须得先了解ARM的内核寄存器,内核处理所有的指令计算,都需要用到内核寄存器,所以ARM汇编里面指令大都是基于寄存器的操作。 文章前推荐韦东山老师的单片机核心视频,视频可以在韦东山老师官网里面找到:百问网 ARM版本简单介绍: 内核(架构)版本 处理器版本
| ARMv1 | ARM1 |
| ARMv2 | ARM2、ARM3 |
| ARMv3 | ARM6、 |
| ARMv4 | ARM7、StrongARM |
| ARMv5 | ARM9、ARM10E |
| ARMv6 | ARM11 |
| ARMv7 | ARM Cortex-A、ARM Cortex-M、ARM Cortex-R |
| ARMv8 | ARM Cortex-A30、ARM Cortex-A50、ARM Cortex-A70 |
一、ARM内核寄存器
内核寄存器与外设寄存器: 内核寄存器与外设寄存器是完全不同的概念。内核寄存器是指 CPU 内部的寄存器,CPU处理所有指令数据需要用到这些寄存器保存处理数据;外设寄存器是指的 串口,SPI,GPIO口这些设备有关的寄存器。 在我的另一篇博文:FreeRTOS记录(三、FreeRTOS任务调度原理解析_Systick、PendSV、SVC)内核中断管理 章节讲到过Cortex-M的寄存器的相关内容,这里我们再简单说明一下:
1.1 M3/M4内核寄存器
对于M3/M4而言:
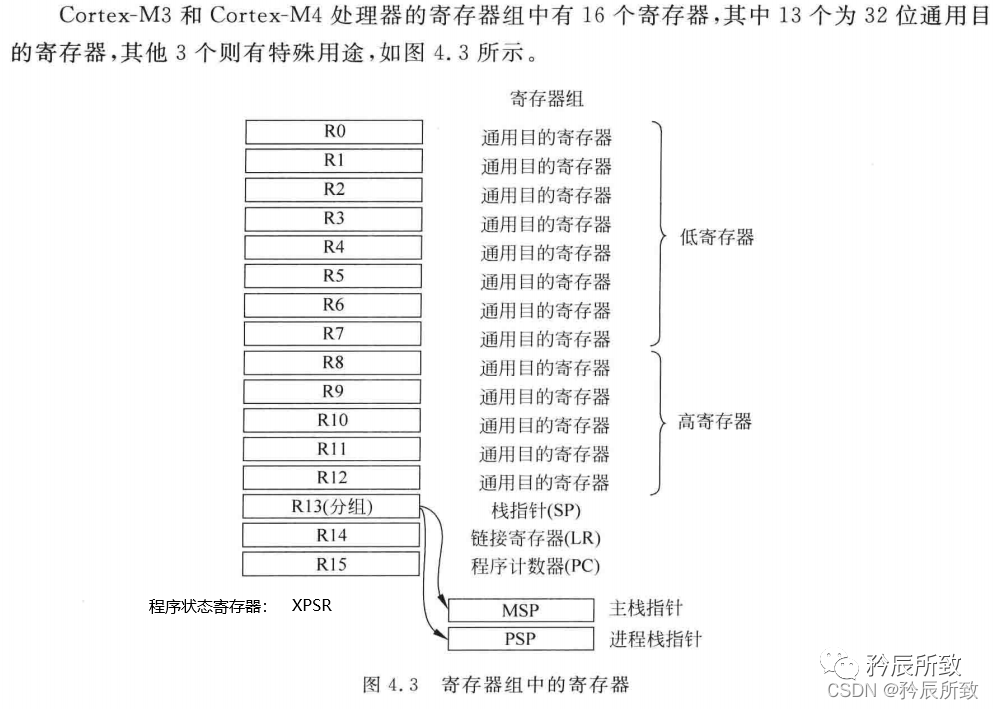
R13,栈指针(Stack Pointer)
R13寄存器中存放的是栈顶指针,M3/M4 的栈是向下生长的,入栈的时候地址是往下减少的。
裸机程序不会用到PSP,只用到MSP,需要运行RTOS的时候才会用到PSP。
堆栈主要是通过POP,PUSH指令来进行操作。在执行 PUSH 和 POP 操作时, SP 的地址寄存器,会自动调整。
R14 ,连接寄存器(Link Register)
LR 用于在调用子程序时存储返回地址。例如,在使用 BL(分支并连接, Branch and Link)指令时,就自动填充 LR 的值(执行函数调用的下一指令),进而在函数退出时,正确返回并执行下一指令。如果函数中又调用了其他函数,那么LR将会被覆盖,所以需要先将LR寄存器入栈。
保存子程序返回地址。使用BL或BLX时,跳转指令自动把返回地址放入r14中;子程序通过把r14复制到PC来实现返回
当异常发生时,异常模式的r14用来保存异常返回地址,将r14如栈可以处理嵌套中断
R15,程序计数器(Program Count)
在Cortex-M3中指令是3级流水线,出于对Thumb代码的兼容的考虑,读取pc时,会返回当前指令地址+4的值。
读 PC 时返回的值是当前指令的地址+4,关于M3、M4 和 A7的 PC值的问题需要单独来解释一下
其中程序状态寄存器 XPSR:

程序状态寄存器,该寄存器由三个程序状态寄存器组成应用PSR(APSR) :包含前一条指令执行后的条件标志,比较结果:大于等于,小于,进位等等;中断PSR(IPSR ) :包含当前ISR的异常编号执行PSR(EPSR) :包含Thumb状态位
1.2 A7内核寄存器
对于 A7 而言:
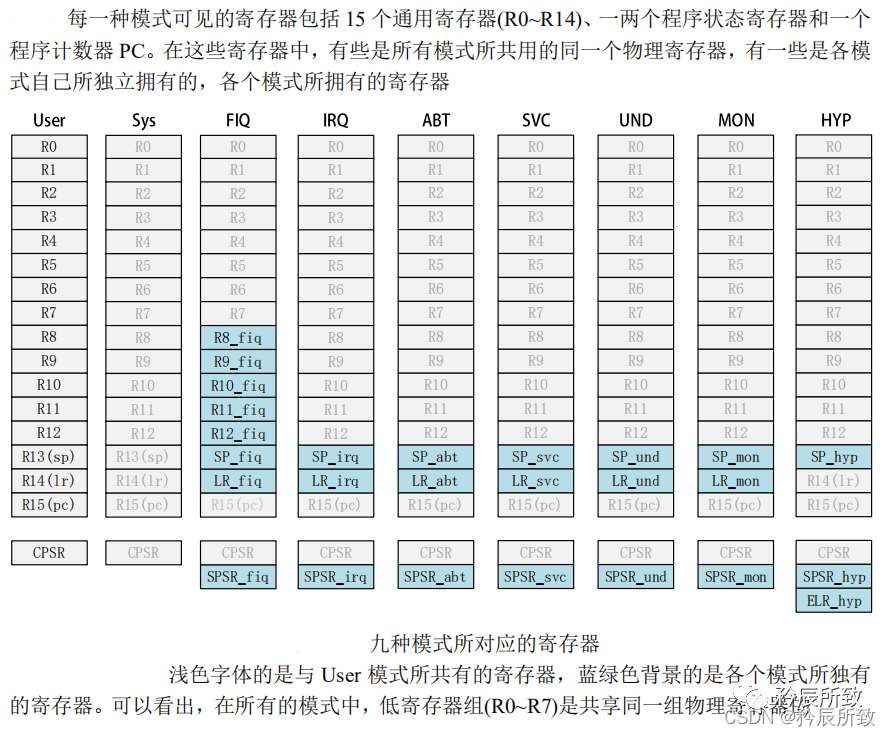
(上图取自原子教材,此图在官方文档《ARM Cortex-A(armV7)编程手册V4.0》中第3章.ARM Processor Modes and Registers 部分有英文原版,这里用中文版本更容易理解) A7的 R13、R14、R15 的作用和 M3/4类似。 需要注意的一点就是,对于A7而言**R15,程序计数器(Program Count)**:
读 PC 时返回的值是当前指令的地址+8, PC 指向当前指令的下两条指令地址。
由于ARM指令总是以字对齐的,故PC寄存器 bit[1:0] 总是00。
A7内核的程序状态寄存器 CPSR:
1.3 ARM中的PC指针的值
因为ARM指令采用三级流水线机制,所以PC指针的值并不是当前执行的指令的地址值:
当前执行地址A的指令,
同时已经在对下一条指令进行译码,
同时已经在读取下下一条指令:PC = A +4 (Thumb/Thumb2指令集)、PC = A + 8 (ARM指令集)
在文档《ARM ArchitectureReference Manual ARMv7-A and ARMv7-R edition》中对于 PC 的值有明确的说明: M3/M4/M0:
M3/M4/M0:
PC的值 = 当前地址 + 4;
下面是一个 STM32F103 反汇编程序,找了一段有[pc,#0]的代码,方便判断: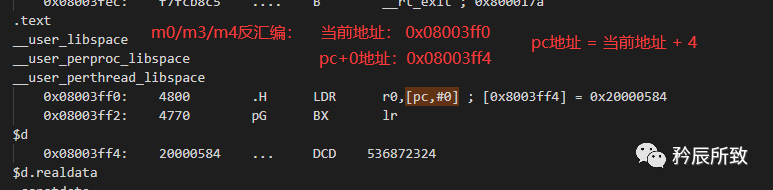
A7:
PC的值 = 当前地址 + 8; 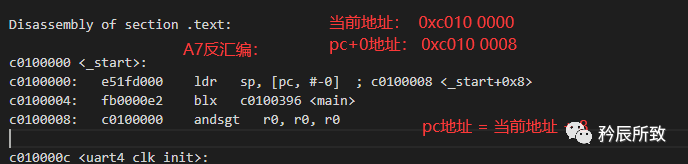
二、ARM汇编语言
ARM芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),具体说明在下面这篇博文5.4小结有过说明:
STM32的内存管理相关(内存架构,内存管理,map文件分析)
2.1 ARM汇编基础
2.1.1 ARM指令集说明
最初,ARM公司发布了两类指令集:
ARM指令集,32位的ARM指令,每条指令占据32位,高效,但是太占空间;
Thumb指令集,16位的Thumb指令,每条指令占据16位,节省空间;
比如:MOV R0,R1 这条指令,可能是16位的,也可能是32位的
那么在汇编中是如何在 ARM 指令 和 Thumb 指令之间切换呢:
/*ARM指令 与 Thumb 指令 的切换*/ CODE16 ;(表示下面是 Thumb 指令) ... ... ;(调用下面的B函数) bx B_addr;(B的地址B_addr的bit0 = 0,表示跳转过去执行 ARM 指令) ;A 函数 ... CODE32 ;(表示下面是 ARM 指令) ... ... ;B 函数 ;(回到上面的A函数) bx A_addr + 1 ;(A的地址A_addr的bit0 = 1,表示跳转过去执行 Thumb 指令) ... /**********************/
对于A7、ARM7、ARM9 内核而言它们支持 16位的Thumb 指令集 和 32位的 ARM 指令集
对于M3、M4 内核而言它们支持的是 Thumb2 指令集,它支持16位、32位指令混合编程
对于内核来说使用的是 ARM指令集 还是 Thumb指令集,就是在 XPSR 和 CPSR
在M3/M4中, XPSR 寄存器的 T(bit24):1表示 Thumb指令集 根据上面所述,M3是使用的 Thumb2 指令集,所以会有 T 总是 1.
根据上面所述,M3是使用的 Thumb2 指令集,所以会有 T 总是 1.
在A7中 CPSR中的:T(bit5) :控制指令执行状态,表明本指令是 ARM 指令还是 Thumb 指令,通常和 J(bit24)一起表明指令类型
| J(bit24) | T(bit5) | 指令集 |
|---|---|---|
| 0 | 0 | ARM |
| 0 | 1 | Thumb |
| 1 | 1 | ThumbEE -- 提供从Thumb-2而来的一些扩充性,在所处的运行环境下,使得指令集能特别适用于运行阶段的编码产生(例如实时编译)。Thumb-2EE是专为一些语言如Limbo、Java、C#、Perl和Python,并能让实时编译器能够输出更小的编译码却不会影响到性能。 |
| 1 | 0 | Jazelle |
回到开始的指令 MOV R0,R1
code 16 ;(表示下面指令是16位的 Thumb 指令) MOV R0,R1 code 32 ;(表示下面指令是32位的 ARM 指令) MOV R0,R1 Thumb ;(编译器会根据指令自动识别是32位还是16位的 Thumb2) MOV R0,R1
2.1.2 ARM汇编格式
编码格式:
不同指令集的编码格式(以 LDR 为例),摘自《ARM ArchitectureReference Manual ARMv7-A and ARMv7-R edition》: 以“数据处理”(其他的还有内存访问,分支跳转等)指令为例,UAL汇编格式为:
以“数据处理”(其他的还有内存访问,分支跳转等)指令为例,UAL汇编格式为: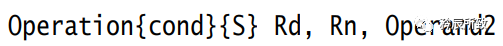 Operation
Operation
表示各类汇编指令,比如 ADD、MOV;cond表示conditon,即该指令执行的条件,如 EQ,NE 等;S表示该指令执行后,是否会影响CPSR寄存器的值, 是否影响CPSR 寄存器的值,书写时影响CPSR,否则不影响;Rd
为目的寄存器,用来存储运算的结果;Rn第一个操作数的寄存器Operand2第二个操作数 ,其可以有3种操作源:1-- 立即数2-- 寄存器3-- 寄存器移位
其指令编码格式如下(32位):|bit 31-28 |27-25 |24-21 |20 |19-16 | 15-12 |11-0 ||--|--|--|--|--|--|--|--|--||cond | 001 |Operation |S |Rn |Rd | Operand2 |
举个例子:
... CMP R0,R2 ;比较R0和R2的值 MOV EQ R0,R1 ;加上EQ,如果上面R0的值和R2的值相等的话,才执行此语句 ...
对于“数据处理”处理指令中的Operation ,指令集如下: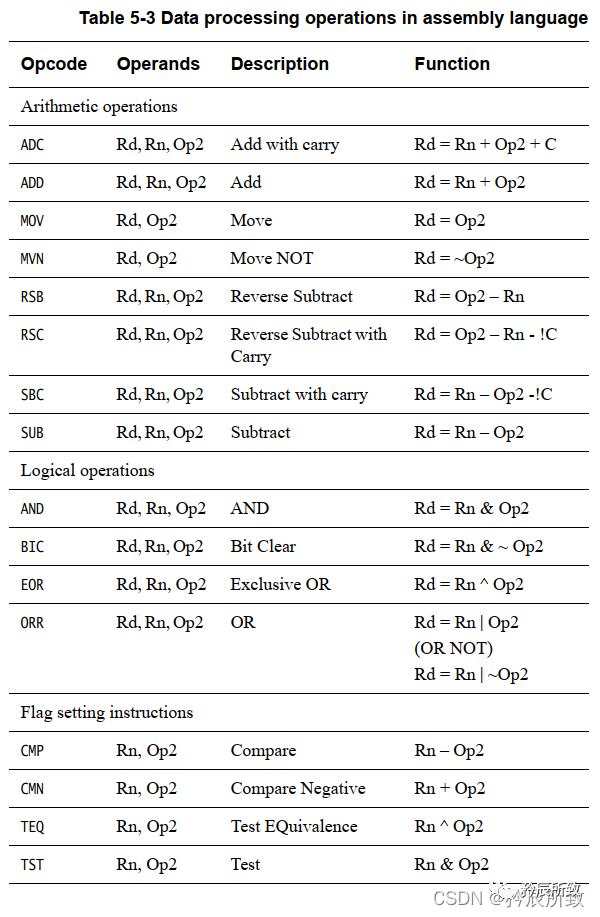 对于其中的条件cond ,如下:
对于其中的条件cond ,如下: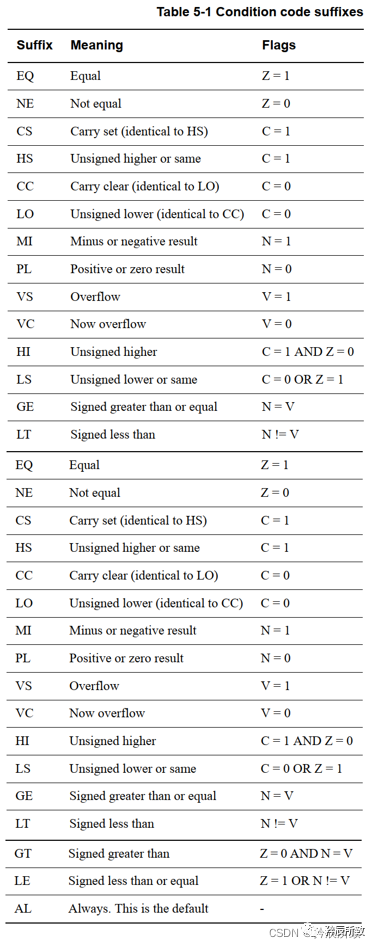
2.1.3 立即数
在一条ARM数据处理指令中,除了要包含处理的数据值外,还要标识ARM命令名称,控制位,寄存器等其他信息。这样在一条ARM数据处理指令中,能用于表示要处理的数据值的位数只能小于32位;
在上面的ARM汇编格式中我们介绍过,ARM在指令格式中设定,只能用指令机器码32位中的低12位来表示要操作的常数。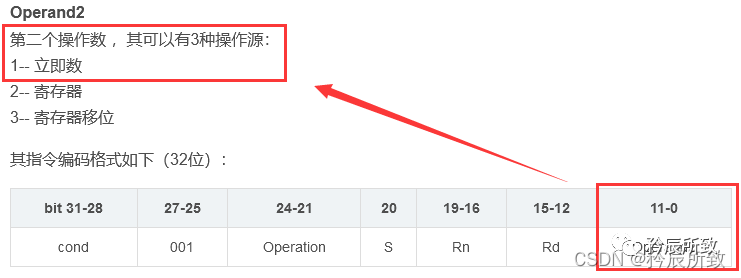
那么对于指令MOV R0, #value(把value的值存入R0寄存器)而言,value 的值也不能是任意的值,其值只能是符合某些规定的数,在官方文档中 value 的值需要满足如下条件: 什么是立即数?
什么是立即数?
满足上图中条件的数我们称之为 立即数,立即数就是符合一定规矩的数。
立即数表示方式:每个立即数由一个8位的常数循环右移偶数位得到。其中循环右移的位数由一个4位二进制的两倍表示。
立即数 = 一个8位的常数 循环位移 偶数位
一个8bit常数循环右移(Y*2 = {0,2,4,6,8, ...,26, 28, 30})就得到一个立即数了;(为什么是0到30的偶数下面解释)
如果需要深入理解立即数,推荐一篇博文:深刻认识 -->> 立即数
ARM处理器是按32位来处理数据的,ARM处理器处理的数据是32位,为了扩展到32位,因此使用了构造的方法,在12位中用8位表示基本数据值,用4位表示位移值,通过用8位基本数据值往右循环移动4位位移值*2次,来表示要操作的常数。
这里要强调最终的循环次数是4位位移值乘以2得到的,所以得到的最终循环次数肯定是一个偶数,为什么要乘以2呢,实质还是因为范围不够,4位表示位移次数,最大才15次(移位0,等于没有循环),加上8位数据还是不够32位,这样只能通过ALU的内部结构设计将4位位移次数乘以2,这样就能用12位表示32位常数了。
所以 12bit 数据存放格式如下:|bit 11-8 |7-0 ||--|--|--|--|--|--|--|--|--||移位 1111b (0~15) | 8bit常数 |
但是我们去判断一个数是否立即数,实在是太麻烦了,但是我们想把任意数值赋给 R0 寄存器,怎么办? 这就需要用到伪指令了,下面说一说什么是伪指令。
2.2 汇编伪指令
汇编语言分成两块:标准指令集和非标准指令集。伪指令属于非标准指令集。
什么是伪指令?
类似于宏的东西,把复杂的有好几天指令进行跳转的完成的小功能级进行新的标签设定,这就是伪指令。
类似于学c语言的时候的预处理,在预处理的时候把它定义于一堆的宏转化为真正的c语言的代码。同样,伪指令是在定义好之后的汇编,汇编的时候会把它翻译成标准指令,也许一条简单的伪指令可以翻译成很多条标准的汇编指令集,所以这就是伪指令最重要的作用。
我们前面说的 CODE16 CODE32也是伪指令,用来指定其后的代码格式。
伪指令的作用?
基本的指令可以做各类操作了,但操作起来太麻烦了。伪指令定义了一些类似于带参数的宏,能够更好的实现汇编程序逻辑。(比如我现在要设置一个值给寄存器R0,但下次我修改了寄存器R0之后又需要读出来刚才的值,那我们就要先临时保存值到SPSR,CPSR,然后不断切换。)
伪指令只是在汇编器之前作用,汇编以后翻译为标准的汇编令集。
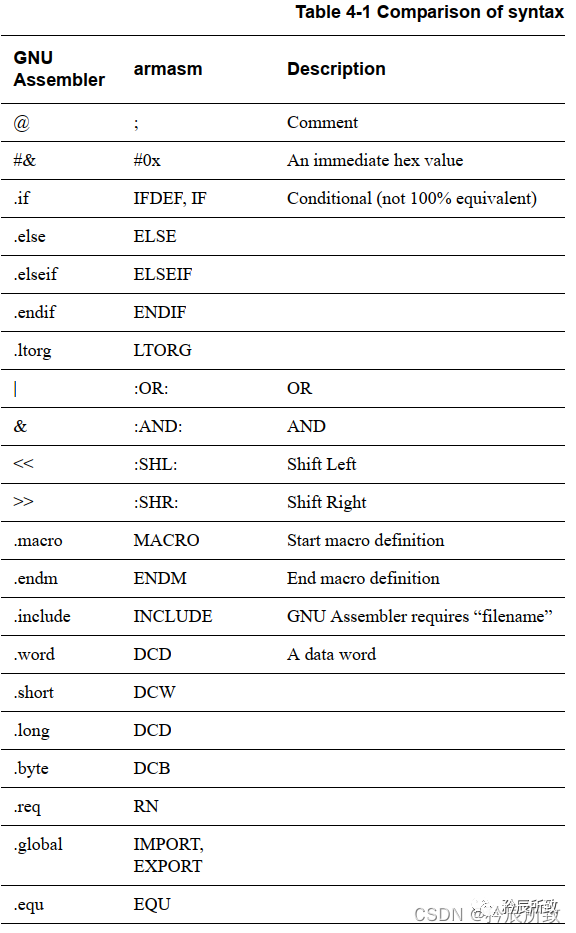
伪指令的类别伪指令可分为ARM汇编伪指令和GNU汇编伪指令
ARM汇编伪指令是ARM公司的,GNU汇编伪指令是GNU平台的。他们有自己的汇编器,不同的汇编器的解释语法可以设成不同。
 在这里插入图片描述
在这里插入图片描述
2.2.1 GNU汇编伪指令
这里列出部分伪指令说明,具体的伪指令可以结合 ARM汇编伪指令分析:
| bit 11-8 | 7-0 |
|---|---|
| .word | 分配一个4字节空间 |
| .byte | 定义单字节数据 |
| .short | 定义双字节数据 |
| .long | 定义一个4字节数据 |
| .equ | 赋值语句:.equ a, 0x11 |
| .align | 数据字节对齐:.align 4 (4字节对齐) |
| .global | 定义全局符号:.global Default_Handler |
| .end | 源文件结束 |
2.2.2 ARM汇编伪指令
在我的另一篇博文:STM32的启动过程(startup_xxxx.s文件解析)
里面有过一些对伪指令意思的的说明,下面也列出部分说明:
AREA:
用于定义一个代码段或数据段。属性字段表示该代码段(或数据段)的相关属性,多个属性用逗号分隔。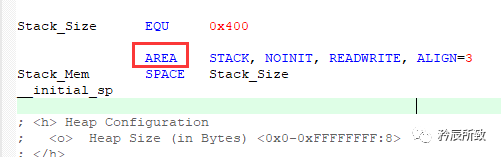 其中,段名若以数字开头,则该段名需用 “ | ” 括起来:
其中,段名若以数字开头,则该段名需用 “ | ” 括起来: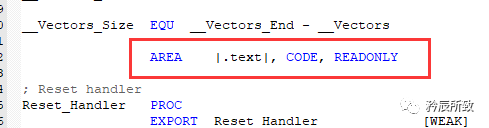
ALIGN:
ALIGN 伪指令可通过添加填充字节的方式,使当前位置满足一定的对其方式。其中,表达式的值用于指定对齐方式,可能的取值为2的幂,如 1 、2 、4 、8 、16 等。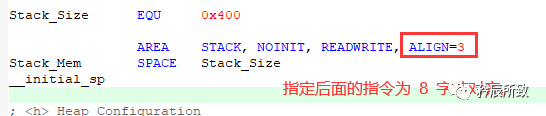 若未指定表达式,则将当前位置对齐到下一个字的位置。
若未指定表达式,则将当前位置对齐到下一个字的位置。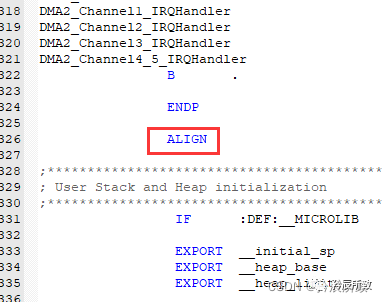
CODE16和CODE32:
指定其后面的指令为 ARM 指令还是 Thumb 指令,前面介绍过。
ENTRY:
用于指定汇编程序的入口点。在一个完整的汇编程序中至少要有一个 ENTRY (也可以有多个,当有多个 ENTRY 时,程序的真正入口点由链接器指定),但在一个源文件里最多只能有一个 ENTRY。
在startup_stm32f103xg.s里面就没有。
END:
用于通知编译器已经到了源程序的结尾。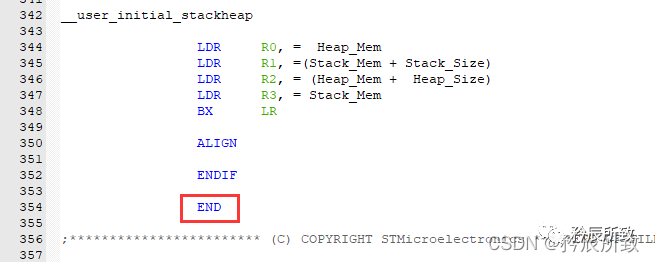 IMPORT 和 EXPORT:
IMPORT 和 EXPORT:
IMPORT 定义表示这是一个外部变量的标号,不是在本程序定义的EXPORT 表示本程序里面用到的变量提供给其他模块调用的
2.2.3 LDR 和 ADR
LDR伪指令:
简单介绍了伪指令基础,回到上一小结留下的问题,想要把任意值复制给 R0,怎么处理,我们使用伪指令: LDR R0, =value
编译器会把“伪指令”替换成真实的指令:
LDR R0, =0x12
0x12是立即数,那么替换为:MOV R0, #0x12
LDR R0, =0x123456780x12345678不是立即数,那么替换为:LDR R0, [PC, #offset] // 2. 使用Load Register读内存指令读出值,offset是链接程序时确定的……Label DCD 0x12345678 // 1. 编译器在程序某个地方保存有这个值
ADR伪指令:
ADR的意思是:address,用来读某个标号的地址:ADR{cond} Rd, labe1
ADR R0, Loop ... Loop ADD R0, R0, #1 ;(它是“伪指令”,会被转换成某条真实的指令,比如:) ADD R0, PC, #val ; loop的地址等于PC值加上或者减去val的值,val的值在链接时确定, ... Loop ADD R0, R0, #1
2.3 ARM汇编指令集
在《ARM Cortex-M3与Cortex-M4权威指南》一文中第5章节有详细的指令集说明: 汇编指令可以分为几大类:数据处理、内存访问、跳转、饱和运算、其他指令。
汇编指令可以分为几大类:数据处理、内存访问、跳转、饱和运算、其他指令。
数据传输命令 MOV
MOV指令,用于将数据从一个寄存器拷贝到另外一个寄存器,或者将一个立即数传递到寄存器。
MOV指令的格式为:MOV{条件}{S} 目的寄存器,源操作数
MOV R0,R1 ;@将寄存器R1中的数据传递给R0,即R0=R1 MOV R0, #0X12 ;@将立即数0X12传递给R0寄存器,即R0=0X12
状态寄存器访问 MRS 和 MSR
MRS指令,用于将特殊寄存器(如CPSR和SPSR)中的数据传递给通用寄存器。
MSR指令,和MRS相反,用来将普通寄存器的数据传递给特殊寄存器。
;M3/M4 MRS R0, APSR ;单独读APSR MRS R0, PSR ; 读组合程序状态 ;A7 MRS R0, CPSR ; 读组合程序状态 ... MSR CPSR,R0 ;传送R0的内容到CPSR
存储器访问 LDR 和 STR
LDR:
LDR 指令用于从存储器中将一个32位的字数据传送到目的寄存器中。该指令通常用于从存储器中读取32位的字数据到通用寄存器,然后对数据进行处理。
指令的格式为:LDR{条件} 目的寄存器,<存储器地址>
当程序计数器PC作为目的寄存器时,指令从存储器中读取的字数据被当作目的地址,从而可以实现程序流程的跳转。
LDRB: 字节操作
LDRH: 半字操作
LDR Rd, [Rn , #offset] ;从存储器Rn+offset的位置读取数据存放到Rd中。 ... LDR R0, =0X02077004 ;伪指令,将寄存器地址 0X02077004 加载到 R0 中,即 R0=0X02077004 LDR R1, [R0] ;读取地址 0X02077004 中的数据到 R1 寄存器中 ... LDR R0,[R1,R2] ;将存储器地址为R1+R2的字数据读入寄存器R0。 LDR R0,[R1,#8] ;将存储器地址为R1+8的字数据读入寄存器R0。 ... LDR R0,[R1,R2,LSL#2]! ;将存储器地址R1+R2×4的字数据读入寄存器R0,并将新地址R1+R2×4写入R1。 LDR R0,[R1],R2,LSL#2 ;将存储器地址R1的字数据读入寄存器R0,并将新地址R1+R2×4写入R1。 ... LDRH R0,[R1] ;将存储器地址为R1的半字数据读入寄存器R0,并将R0的高16位清零。
STR:
STR 指令用于从源寄存器中将一个32位的字数据传送到存储器中。该指令在程序设计中比较常用,且寻址方式灵活多样,使用方式可参考指令LDR。
指令的格式为:STR{条件} 源寄存器,<存储器地址>
STRB: 字节操作,从源寄存器中将一个8位的字节数据传送到存储器中。该字节数据为源寄存器中的低8位。
STRH: 半字操作,从源寄存器中将一个16位的半字数据传送到存储器中。该半字数据为源寄存器中的低16位。
STR Rd, [Rn, #offset] ;将Rd中的数据写入到存储器中的Rn+offset位置。 ... LDR R0, =0X02077004 ;将寄存器地址 0X02077004 加载到 R0 中,即 R0=0X02077004 LDR R1, =0X2000060c ;R1 保存要写入到寄存器的值,即 R1=0X2000060c STR R1, [R0] ;将 R1 中的值写入到 R0 中所保存的地址中 ... STR R0,[R1],#8 ;将R0中的字数据写入以R1为地址的存储器中,并将新地址R1+8写入R1。 STR R0,[R1,#8] ;将R0中的字数据写入以R1+8为地址的存储器中。 ...
压栈和出栈 PUSH 和 POP
PUSH :
压栈,将寄存器中的内容,保存到堆栈指针指向的内存上面,将寄存器列表存入栈中。
PUSH < reg list >
POP :
出栈,从栈中恢复寄存器列表
POP < reg list >
push {R0, R1} ;保存R0,R1
push {R0~R3,R12} ;保存 R0~R3 和 R12,入栈
pop {R0~R3} ;恢复R0 到 R3 ,出栈
以M3内核来举个例子:
假设当前 MSP 值为 0x2000 2480;寄存器 R0 的值为 0x3434 3434寄存器 R1 的值为 0x0000 1212寄存器 R2 的值为 0x0000 0000
执行push {R0, R1,R2}之后,
内存地址的数据为:0x2000 2474的值为: 0x3434 3434 (R0的值)0x2000 2478的值为: 0x0000 1212 (R1的值)0x2000 247C的值为: 0x0000 0000 (R2的值)MSP 的值变成 0x2000 2474
高位寄存器保存到高地址,先入栈,如果是POP,数据先出到低位寄存器
跳转指令 B 和 BL
B :
ARM 处理器将立即跳转到指定的目标地址,不再返回原地址。
B指令的格式为:B{条件} 目标地址
注意存储在跳转指令中的实际值是相对当前PC值的一个偏移量,而不是一个绝对地址,它的值由汇编器来计算。
//设置栈顶指针后跳转到C语言 _start: ldr sp,=0X80200000 ;设置栈指针 b main ;跳到 main 函数
BL :
BL 跳转指令,在跳转之前会在寄存器LR(R14)中保存当前PC寄存器值,所以可以通过将LR 寄存器中的值重新加载到PC中来继续从跳转之前的代码处运行,是子程序调用的常用的方法。
BL loop ;跳转到标号loop处执行时,同时将当前的PC值保存到R14中
BLX:
该跳转指令是当子程序使用Thumb指令集,而调用者使用ARM指令集时使用。
BLX指令从ARM指令集跳转到指令中所指定的目标地址,并将处理器的工作状态有ARM状态切换到Thumb状态,该指令同时将PC的当前内容保存到寄存器R14中。
BX:
BX指令跳转到指令中所指定的目标地址,目标地址处的指令既可以是ARM指令,也可以是Thumb指令。
算数运算指令
算数运算指令和下面的逻辑运算指令表格摘自《【正点原子】I.MX6U嵌入式Linux驱动开发指南》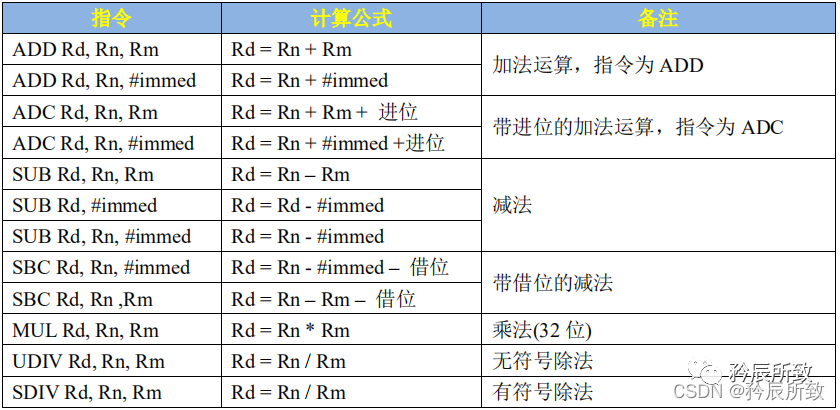
逻辑运算指令
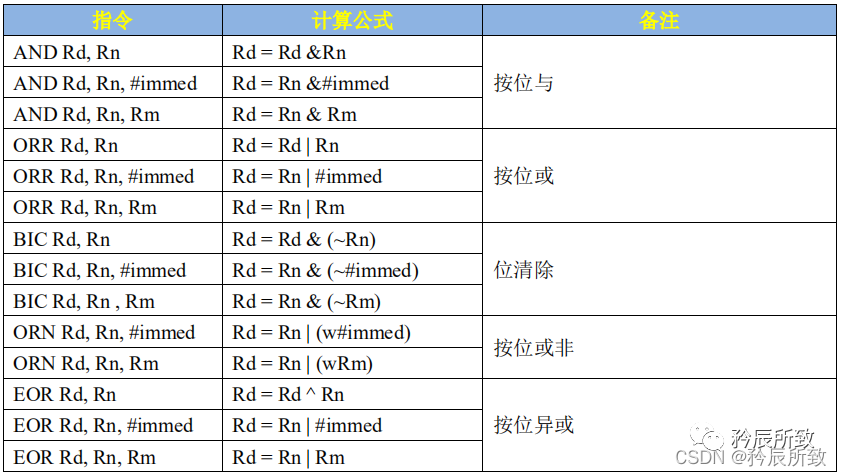 在这里插入图片描述
在这里插入图片描述
三、代码反汇编简析
汇编汇编文件转换为目标文件(里面是机器码,机器码是给CPU使用的,烧录保存在Flash空间的就是机器码)。
反汇编可执行文件(目标文件,里面是机器码),转换为汇编文件。
3.1 不同编译器的反汇编
3.1.1 Keil下面生成反汇编文件
fromelf –text -a -c –output=(改成你想生成的反汇编名字一般是工程名字).dis (需要的axf文件,根据你工程生成axf的路径填写).axf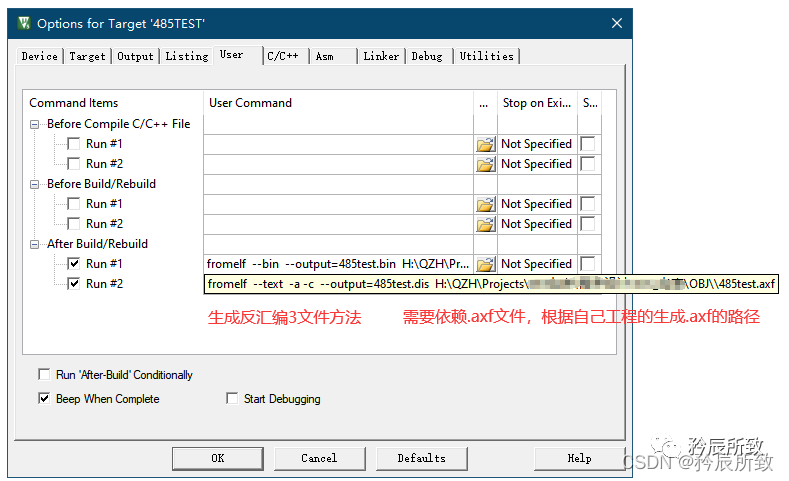 设置好以后编译之后就会生成反汇编.dis文件:
设置好以后编译之后就会生成反汇编.dis文件: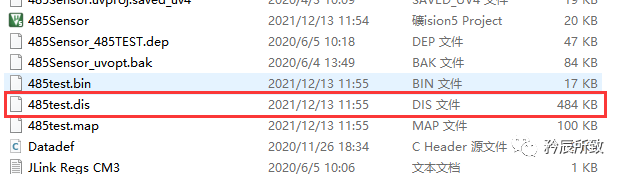
打开如下所示: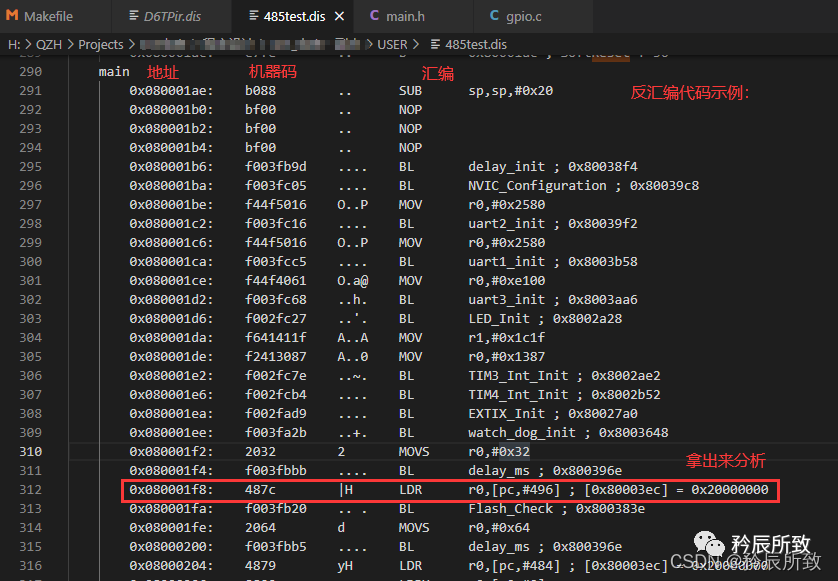 对于上图中的红色圈出来的语句,我们可以根据本文 第 二 章节的第2小节 ARM汇编格式中的介绍来分析一下:
对于上图中的红色圈出来的语句,我们可以根据本文 第 二 章节的第2小节 ARM汇编格式中的介绍来分析一下: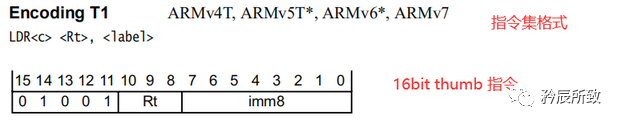
简单分析如下(立即数就不分析了= =!):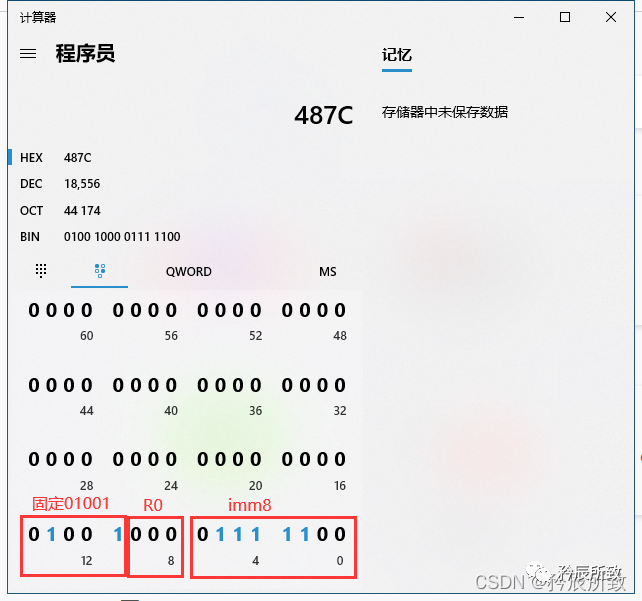
3.1.2 gcc下生成反汇编文件
在X86架构下的电脑上生成ARM架构的汇编代码有两种方式:
使用交叉编译工具链 指定-S选项可以生成汇编中间文件。ex:gcc -S test.c
使用 objdump 反汇编 arm二进制文件。
上述两种方法的区别为:
(1)反汇编可以生成ARM指令操作码,-S生成的汇编没有指令码(2)反汇编的代码是经过编译器优化过的。(3)反汇编代码量很大。
对于ARM Cortex-M,使用的是 arm-none-eabi-objdump,常用指令如下:
arm-none-eabi-objdump -d -S(可省) a1.o 查看a1.o反汇编可执行段代码
arm-none-eabi-objdump -D -S(可省) a1.o 查看a1.o反汇编所有段代码
arm-none-eabi-objdump -D -b binary -m arm ab.bin 查看ab.bin反汇编所有代码段
对于使用 arm-none-eabi-gcc 工具链(以STM32CUbeMX)的内核来说,使用如下方式生成反汇编文件:
$(OBJDUMP) -D -b binary -m arm (需要的elf文件,一般是工程名字).elf > (改成你想生成的反汇编名字,一般是工程名字).dis # OBJDUMP = arm-none-eabi-objdump
-D表示对全部文件进行反汇编,-b表示二进制,-m表示指令集架构
Makefile修改如下:
... TARGET = D6TPir ####################################### # paths ####################################### # Build path BUILD_DIR = build ... PREFIX = arm-none-eabi- ... OBJDUMP = $(PREFIX)objdump dis: $(OBJDUMP) -D -b binary -m arm $(BUILD_DIR)/$(TARGET).elf > $(BUILD_DIR)/$(TARGET).dis # $(OBJDUMP) -D -b binary -m arm $(BUILD_DIR)/$(TARGET).bin > $(BUILD_DIR)/$(TARGET).dis
执行 make dis 即可生成 .dis 文件: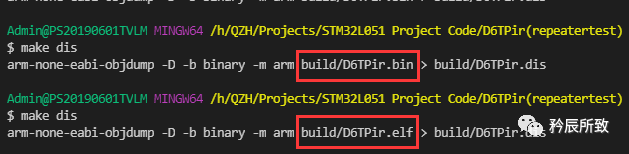
 打开文件查看,发现怎么这个汇编语言有点不一样:
打开文件查看,发现怎么这个汇编语言有点不一样: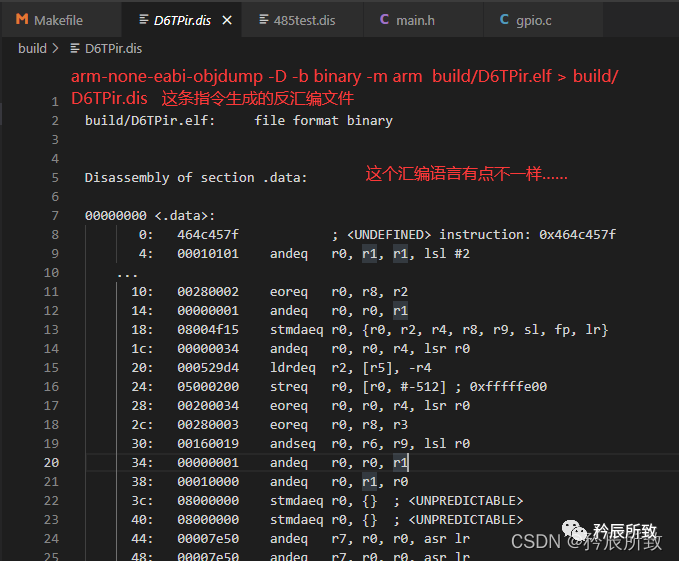 经过研究了一段时间,加上了-M force-thumb后稍微有点样子了:
经过研究了一段时间,加上了-M force-thumb后稍微有点样子了:
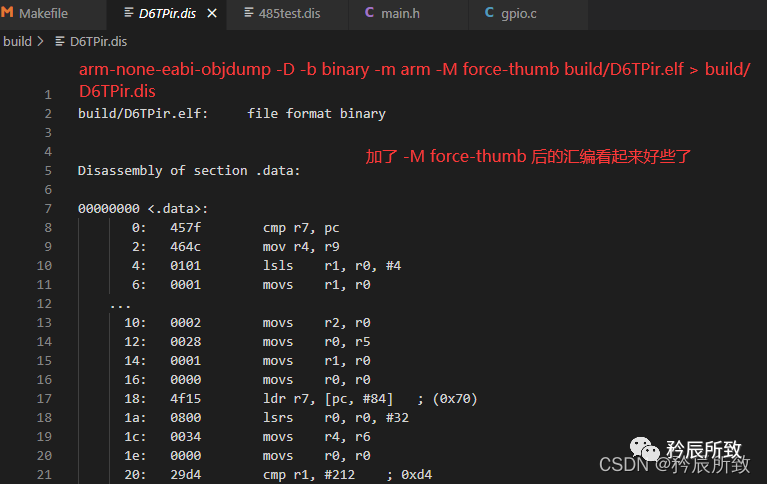 在网上有各种参考,但是我都测试过了,并没有找到合适的生成完全和标准汇编一致的那种,-M后面的参数也不能乱加,需要根据自己的交叉编译器,因为这里用的是 arm-none-eabi-gcc,所以可以通过arm-none-eabi-objdump --help 查看能用的命令和参数:
在网上有各种参考,但是我都测试过了,并没有找到合适的生成完全和标准汇编一致的那种,-M后面的参数也不能乱加,需要根据自己的交叉编译器,因为这里用的是 arm-none-eabi-gcc,所以可以通过arm-none-eabi-objdump --help 查看能用的命令和参数: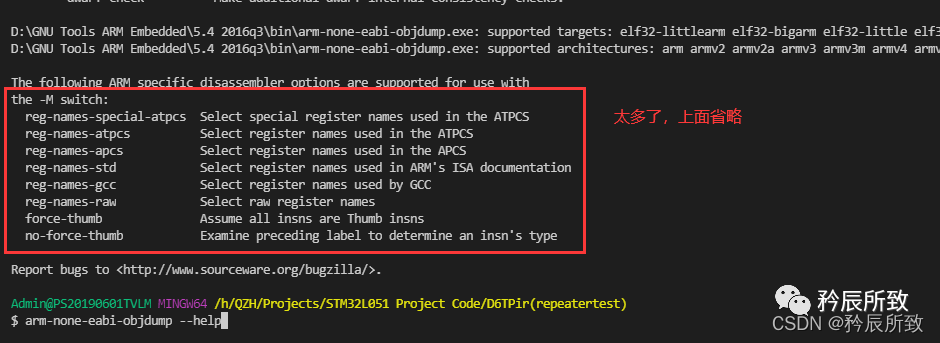 gcc工具链下的汇编还是不太熟悉,所以我们下面反汇编文件与 C语言的对比,使用Keil下的反汇编进行说明。
gcc工具链下的汇编还是不太熟悉,所以我们下面反汇编文件与 C语言的对比,使用Keil下的反汇编进行说明。
3.2 C 和 汇编 比较分析
前面介绍了那么多,最终用一个简单的程序对比一下C语言反汇编后的汇编语言,加深一下印象,当作个实战总结。
基于STM32L051(Cortex-M0)内核,目的是为了比较C和汇编,用了个最简单的程序来分析,没有用到任务外设,程序如下:
//前面省略...
void delay(u32 count)
{
while(count--);
}
u32 add(u16 val1,u16 val2)
{
u32 add_val;
add_val = val1 + val2;
return add_val;
}
int main(void)
{
u16 a,b;
u32 c;
a = 12345;
b = 45678;
c = add(a,b);
while(1)
{
c--;
delay(200000);
}
}
反汇编的代码对应部分如下(因为基于硬件平台,其他异常中断,堆,栈,包括其他一些也有汇编代码,这里省略):
;省略前面 delay 0x080001ae: bf00 .. NOP 0x080001b0: 1e01 .. SUBS r1,r0,#0 0x080001b2: f1a00001 .... SUB r0,r0,#1 0x080001b6: d1fb .. BNE 0x80001b0 ; delay + 2 0x080001b8: 4770 pG BX lr add 0x080001ba: 4602 .F MOV r2,r0 0x080001bc: 1850 P. ADDS r0,r2,r1 0x080001be: 4770 pG BX lr main 0x080001c0: f2430439 C.9. MOV r4,#0x3039 0x080001c4: f24b256e K.n% MOV r5,#0xb26e 0x080001c8: 4629 )F MOV r1,r5 0x080001ca: 4620 F MOV r0,r4 0x080001cc: f7fffff5 .... BL add ; 0x80001ba 0x080001d0: 4606 .F MOV r6,r0 0x080001d2: e003 .. B 0x80001dc ; main + 28 0x080001d4: 1e76 v. SUBS r6,r6,#1 0x080001d6: 4804 .H LDR r0,[pc,#16] ; [0x80001e8] = 0x30d40 0x080001d8: f7ffffe9 .... BL delay ; 0x80001ae 0x080001dc: e7fa .. B 0x80001d4 ; main + 20 $d 0x080001de: 0000 .. DCW 0 0x080001e0: e000ed0c .... DCD 3758157068 0x080001e4: 05fa0000 .... DCD 100270080 0x080001e8: 00030d40 @... DCD 200000 ;省略后面
3.2.1 MOV后面 立即数的疑问
在对比分析这段代码前,在 main 函数中的第一句:
0x080001c0: f2430439 C.9. MOV r4,#0x3039
就有一个大大的疑问, MOV r4,#0x3039中 0x3039 并不是立即数(按照我们第二章 立即数的说明) ,包括接下来的 0xb26e 也不是立即数,怎么可以直接用 mov,按理来说需要用 LDR伪指令的??
至于这个问题,网上简单查找了一下,找到一篇有关说明的文章:ARM 汇编的mov操作立即数的疑问 其中有说到,在 keil 公司方网站里关于arm汇编的说明里有这么一段:
SyntaxMOV{cond} Rd, #imm16where: imm16 is any value in the range 0-65535.
所以是不是在 Keil 中的arm汇编 立即数可以使16位的?
为了验证一下,我稍微修改了一下程序,就是把a的值赋值超过16位(当然定义函数之类的也要跟着改,测试代码中a为u16的无符号整形),测试了一下。
a赋值为 65535,结果如下(65535不是立即数,也可以直接mov):
0x080001c0: f64f75ff O..u MOV r5,#0xffff
a赋值为 65536,结果如下(65536是立即数,可以直接mov):
0x080001c0: f44f3580 O..5 MOV r5,#0x10000
a赋值为一个大于16位的,不是立即数的数,比如:0x1FFFF :
0x080001c0: 4d08 .M LDR r5,[pc,#32] ; [0x80001e4] = 0x1ffff
果然,最后当 a 大于16位,不是立即数时候,会使用伪指令 LDR,所以我们可以得出结论:
在 Keil 中的arm汇编中,16位内(包括16位)的数都直接使用 MOV 赋值,大于16位,如果是立即数,直接使用MOV,不是立即数用LDR (立即数的判断方式还是前面讲的那样)
3.2.2 反汇编文件解析
对于上面的示例程序的汇编码,简单解析如下: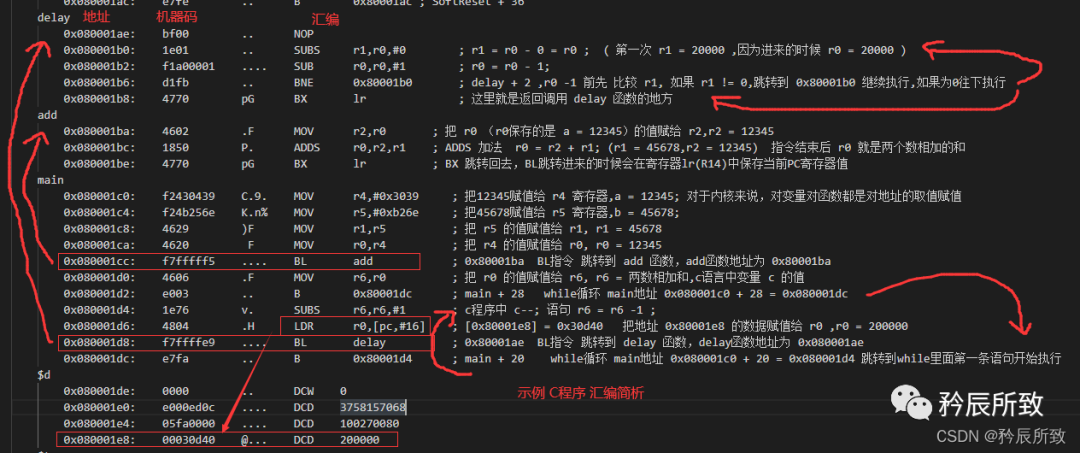 添加一个有意思的测试对于delay函数中的语句,上图是while(count--);改成while(--count);后汇编代码如下:
添加一个有意思的测试对于delay函数中的语句,上图是while(count--);改成while(--count);后汇编代码如下:
对于上面的测试程序,汇编中并没有使用到 PUSH 和 POP 指令,因为程序太简单了,不需要使用到栈,为了能够熟悉下单片机中必须且经常需要用到的 栈,我们稍微修改一下add函数,在add函数中调用了delay函数:
u32 add(u16 val1,u16 val2)
{
u32 add_val;
add_val = val1 + val2;
delay(10);
return add_val;
}
对于的add函数汇编代码如下:
add
0x080001ba: b530 0. PUSH {r4,r5,lr} ;把r4 r5 lr的值入栈
0x080001bc: 4603 .F MOV r3,r0
0x080001be: 460c .F MOV r4,r1
0x080001c0: 191d .. ADDS r5,r3,r4
0x080001c2: 200a . MOVS r0,#0xa
0x080001c4: f7fffff3 .... BL delay ; 0x80001ae
0x080001c8: 4628 (F MOV r0,r5
0x080001ca: bd30 0. POP {r4,r5,pc} ;把r4 r5 lr的值出栈,
(汇编中可以看到指令后面后面加了个S ,MOVS 、ADDS,这就是我们前面说到的,带了S 会影响 xPSR 寄存器中的值)
可以看到,因为存在函数的多次调用,main函数中调用add函数,add函数中调用delay函数,所以在add函数运行之前,通过 push 把 r4,r5,lr 寄存器的值先存入栈中,等待程序执行完(函数调用结束)再吧 r4,r5,lr 寄存器的值恢复。
上面的程序虽然简单,但是通过我们C程序 与 汇编程序的对比分析,能够让我们更加深入的理解汇编语言.
审核编辑:黄飞
-
ARM处理器的寄存器组织及功能2024-09-10 4210
-
ARM寄存器的分类及功能2024-09-05 4312
-
U54内核中断控制和状态寄存器2023-10-08 2526
-
深度剖析ARM内核寄存器及基本汇编语言12023-04-24 1906
-
ARM通用寄存器及状态寄存器详解2023-01-06 10229
-
ARM开发中几个常见的寄存器详解2022-11-22 5878
-
鸿蒙内核源码中C7,C2,C13三个寄存器2021-04-24 5124
-
基于ARM单片机中的部分寄存器地址为什么会相差42018-11-09 4075
-
寄存器由什么组成2018-08-21 38613
-
浅谈ARM寄存器组织2017-10-18 1549
-
arm程序状态寄存器访问指令2017-01-04 734
-
ARM寄存器详解2010-07-10 3348
全部0条评论

快来发表一下你的评论吧 !
