

浅谈AI技术在SSD控制器中的应用
描述
背景介绍
当前AI技术蓬勃发展,深度学习、强化学习等技术不断突破,使得AI在图像识别、语音识别、自然语言处理等领域取得了显著成果。在图像处理方面,卷积神经网络(CNN)被广泛应用于图像识别、目标检测等任务,极大地提升了计算机视觉的准确性和效率。在自然语言处理领域,深度学习模型如循环神经网络(RNN)和Transformer架构则助力机器理解并生成人类语言,实现了智能对话、文本分类等功能。此外,机器学习算法如决策树、随机森林和支持向量机(SVM)在数据分析和预测建模中发挥着关键作用。同时,强化学习技术也在游戏AI、机器人控制等领域得到广泛应用,使智能体能够自主学习和优化行为策略。
SSD控制器是固态硬盘(SSD)中的核心组件,它负责协调SSD内部各个部件的运作,是数据读写的关键管理者。面向主机方向,SSD控制器需要有效管理主机请求,通过精准的调度、流控和预测确保主机响应的及时和稳定;面向底层NAND方向,它需要负责SSD上NAND介质的全生命周期管理,确保底层NAND在全场景下的寿命和稳定性除了基础的数据管理功能,还需要具备强大的错误校正能力,能够及时发现并修复数据传输中的错误,保证数据的完整性;同时,它还负责执行垃圾回收任务,通过智能算法优化存储空间的使用,避免数据碎片化的发生,提高SSD的持久性和性能;此外,随着数据安全性的日益受到重视,SSD控制器还集成了数据加密和保护功能,通过先进的加密算法和安全机制,它能够有效防止数据被非法访问或篡改,保护用户的隐私和信息安全。
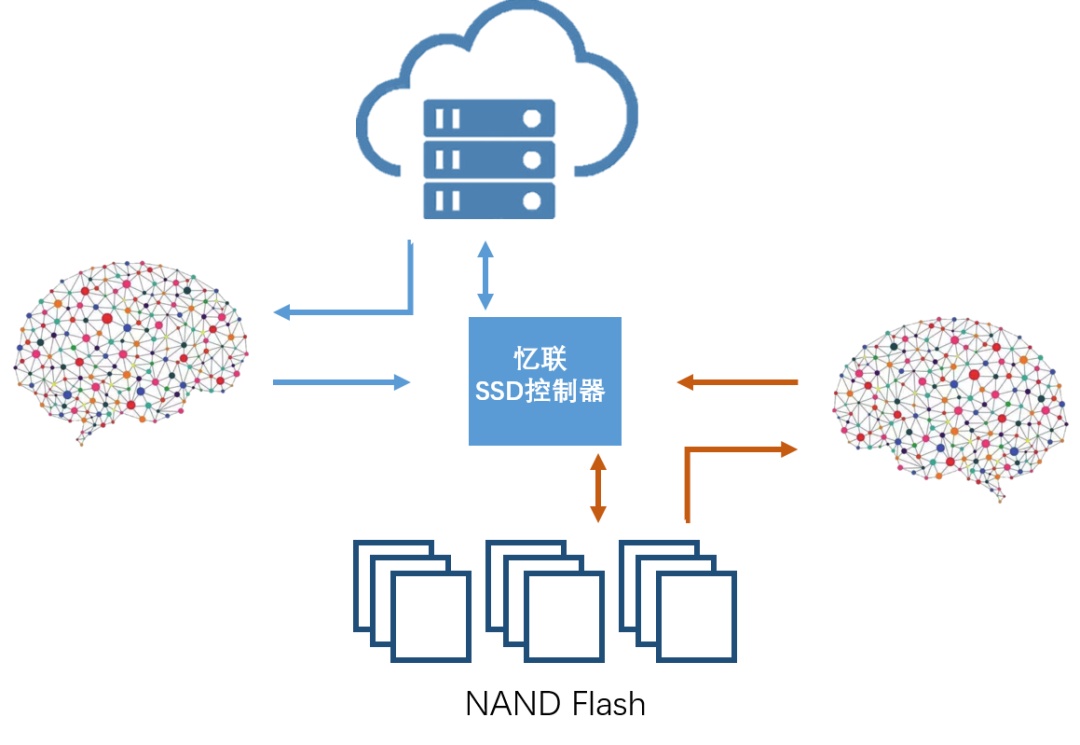
图1:AI加持的SSD控制器
总的来说,AI是一个强大的建模工具,可以完成复杂模型的抽象,在SSD的应用场景下能够基于经验数据给出IO和介质的行为级预测;而SSD控制器是一个复杂的管理系统,需要基于主机IO和底层介质的行为完成数据管理和性能优化的功能。AI的能力和SSD的控制器需求可以很好的互补,因此,本文对AI在SSD上的应用进行简单探索。
经典AI技术介绍
本章我们简单介绍RF、MLP和CNN这三种经典AI算法,其中,随机森林属于传统机器学习算法,MLP和CNN属于深度学习算法。
随机森林属于机器学习中的集成学习算法,属于Bagging类型。
集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。Bagging也叫自举汇聚法(bootstrap aggregating),是一种在原始数据集上通过有放回抽样重新选出k个新数据集来训练分类器的集成技术。它使用训练出来的分类器的集合来对新样本进行分类,然后用多数投票或者对输出求均值的方法统计所有分类器的分类结果,结果最高的类别即为最终标签。在实现上,可以通过简单的决策树作为不同抽样的分类器,通过多个决策树的预测结果投票,完成最终的预测。
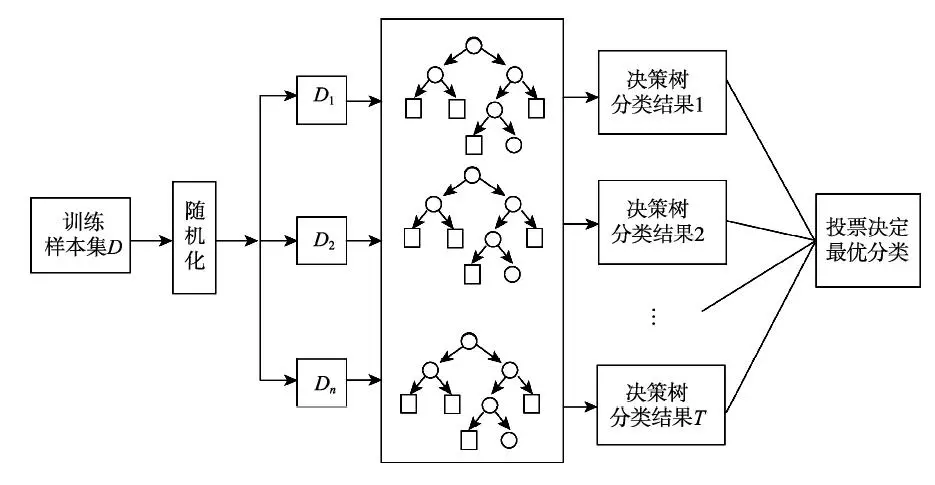
图2:包含n个决策树的随机森林
多层感知机(MLP)是一种基本的前馈神经网络结构,由多个全连接层组成。
每个层中的神经元接收上一层的输出作为输入,并将其加权求和后通过一个激活函数进行非线性转换。这种结构允许模型学习非线性关系并对输入数据进行抽象表示。MLP的基本组件包括输入层、隐藏层和输出层:输入层负责接收输入特征向量,每个特征对应输入层的一个神经元;隐藏层位于输入层和输出层之间,可以包含多个层。每个隐藏层的神经元从前一层的输出中获取数据,并进行加权求和和激活函数处理;输出层提供模型的最终输出,可以是一个或多个神经元的组合。在回归问题中,输出层通常只有一个神经元,它提供了预测的连续值。
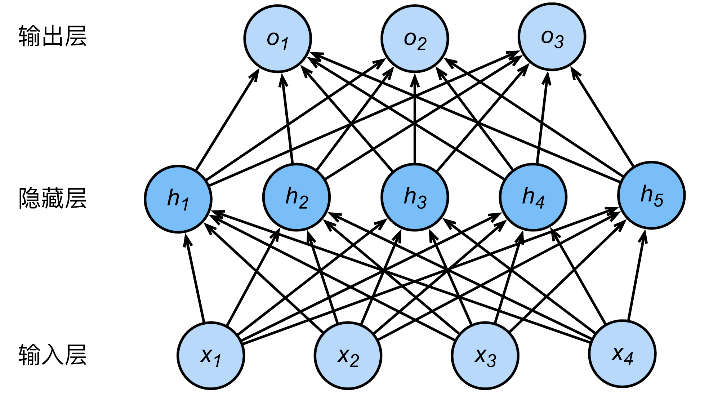
图3:包含一个隐藏层的MLP
卷积神经网络(CNN)是一种具有局部连接、权值共享等特点的深层前馈神经网络,具有表征学习能力,能够按其阶层结构对输入信息进行平移不变分类。
CNN的基本组件包括卷积层、池化层和全连接层:卷积层通过卷积操作对输入数据进行特征提取。卷积层由一组可学习的过滤器(或称为卷积核)组成,每个过滤器通过滑动窗口在输入数据上进行卷积操作,以计算得到特定位置的特征图;池化层用于对特征图进行下采样,减少计算量并保留最重要的特征。常见的池化操作是最大池化,它选择窗口中最大值作为池化结果;全连接层类似于MLP中的隐藏层和输出层,用于将卷积和池化层的输出转换为最终的预测结果。CNN的训练也使用反向传播算法和梯度下降优化器。不同于MLP,CNN在处理图像等数据时利用了卷积和池化操作的局部连接性和参数共享特性,可以有效地捕捉到输入数据的空间结构和局部特征。
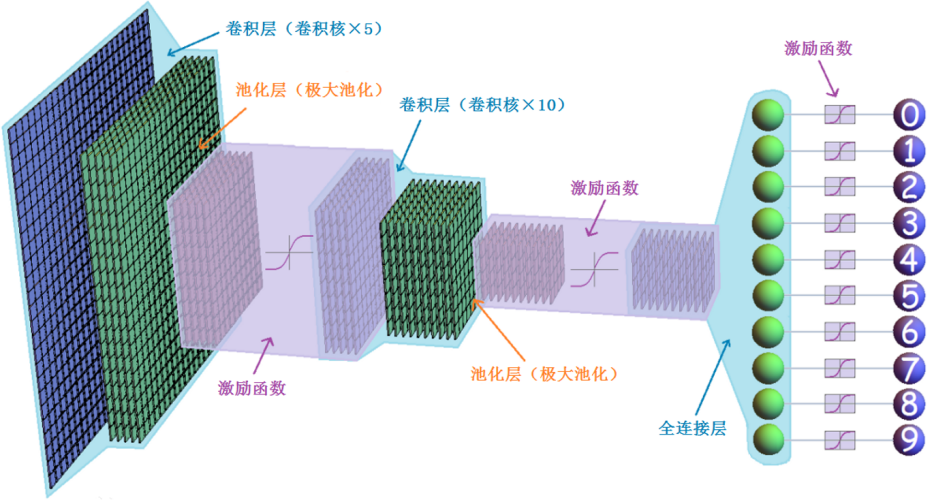
图4:包含卷积核池化层的CNN网络
基于AI的SSD控制器技术
本章我们以AI读电压预测的一个简单例子介绍SSD控制器上AI技术的应用。SSD的存储单元为NAND颗粒,每个NAND存储单元可以视为一个可以保存电子的三极管,通过下发一定检测电压判断三极管是否开启,可以检测出其保存电子的数量,进而获取NAND中保存的数据。在NAND中,该检测电压即为NAND读电压。为了准确的读取NAND中的数据,需要尽可能准确的读电压,否则就会得到错误的三极管开启阈值,造成读取错误。
在实际使用中,NAND的阈值电压受多种因素影响:NAND的擦写次数影响NAND单元中电子流失的速度;NAND的上电保持时间等于NAND中电子持续流失的时间;对相邻NAND单元的读取可能造成NAND内电子增加;不同物理位置的NAND单元因为工艺的不一致性,在不同的场景中的阈值电压的变化也会有差异。NAND受各种因素影响的阈值电压变化量就构成了一个数值模型,我们可以尝试通过AI对其进行建模。
我们选取了一款主流厂商TLC颗粒进行建模,TLC的一个wordline包含7个不同的读状态,为了简化模型,我们仅考虑了不同磨损次数和不同上电保持时间的阈值电压模型,最终得到模型的输入信息为磨损次数PE,上电保持时间T,目标page的所在的plane、block和wordline编号,以及采用读取得到数据最准确的读电压RL1~RL7,采用随机森林与MLP算法,分别进行AI训练。
训练的数据集包括3000个不同位置page在不同PE和T下最优读电压的数据。我们在训练中对数据集进行随机划分,按71划分为训练集、测试集和验证集,训练集用于模型权重的训练,验证集用于模型超参数调整和过拟合监控,测试集用于评估模型的性能,我们在训练中采用模型输出电压与数据集中最优电压的均方误差作为模型评估的标准。
随机森林比较简单,我们采用一个50个随机决策树的森林进行随机样本的训练,将所有数据进行随机划分,进行多次训练,当均方误差收敛后停止训练,最终得到的随机森林在测试集上获得了2.98的均方误差。
在MLP中,我们采用了一种简洁高效的架构:输入层直接接收磨损次数PE、时间T、plane、block和wordline位置这五个关键的物理参数,这些参数是影响读电压的主要因素;隐藏层中包含两个大小为128的隐藏层,这种设计旨在提供足够的模型复杂度,以学习输入特征与读电压之间的潜在关系。ReLU激活函数在这里发挥作用,帮助模型捕捉非线性依赖;输出层是一个包含7个神经元的线性层,它输出预测的读电压值,对应于TLC NAND存储单元中可能的不同状态。训练后,在测试集上,MLP最终获得2.99的均方误差,略高于随机森林。
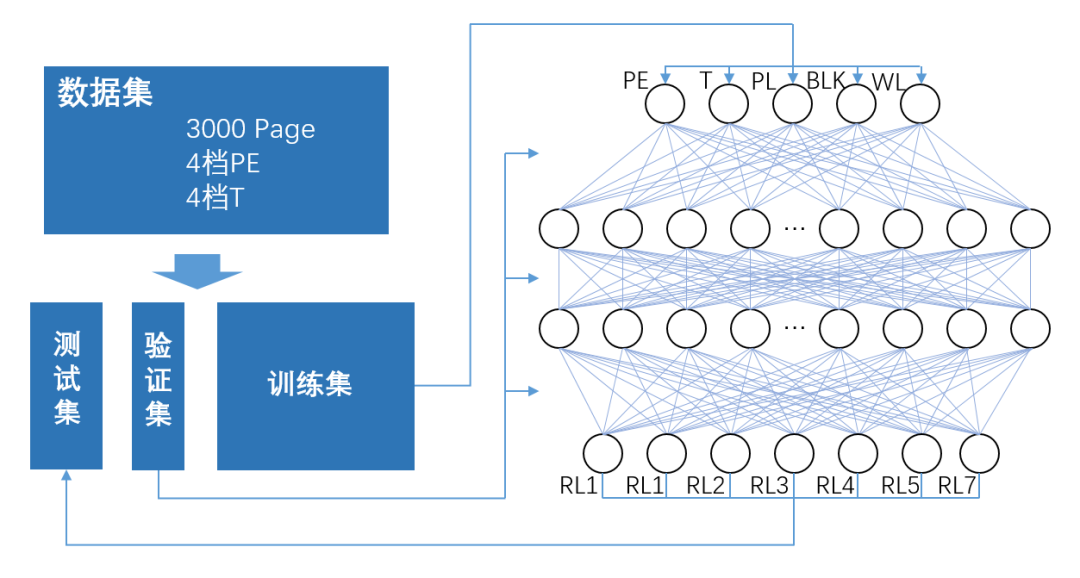
图5:电压预测MLP训练架构
因为在本实验中,选取的场景比较单一,样本量不大,传统的机器学习算法与深度学习算法都以很小的模型量级取得了非常不错的学习效果,模型预测得到的阈值电压与最优读电压的误差不超过3个电压档位,验证了AI技术在NAND电压模型上的应用潜力。随着使用场景的复杂化,深度学习可以通过增加隐藏层,获得更大精确的模型能力,提供全场景下的准确NAND读电压预测。
忆联在AI领域的布局及应用
在本文我们通过一个简单的示例展示了AI作为一个新技术,在SSD控制器底层管理上的应用潜力。除了NAND读电压,还有NAND健康管理和寿命预测、主机负载预测、IO冷热预测等多方面,都可以通过AI的建模,针对使用场景在线获得SSD的最优运行参数,帮助用户获得更快、更可靠、更安全的数据管理服务。
在人工智能的趋势下,不管是AI PC还是超大规模数据中心,都对存储容量和性能提出了更高要求。一直以来,忆联持续打磨产品的存储性能,在7系DSSD、8系ESSD以及SAS产品上,已将AI算法融入了NAND管理、主机访问优化、性能稳定性等功能。未来,忆联还将不断推出具备强劲竞争力的全产品线SSD产品,满足AI时代算力需求,实现存力突围,为客户创造最大价值。
审核编辑:刘清
-
慧荣科技预计2019全年SSD控制器出货量攀升2019-08-02 6863
-
英韧科技切入SSD控制器市场 推出4款NVMe SSD控制器2019-08-03 2640
-
Novachips发布其最新SATA3 6Gbps SSD控制器NVS3600A2012-08-24 3804
-
浅谈电机控制器逆变原理2016-01-28 14078
-
SSD1289控制器资料2016-01-08 1122
-
控制器SSD1963规格书2016-12-13 1312
-
SSD控制器哪家强?英特尔、三星、美光……2018-05-08 10440
-
Marvell推出NVMe-oF以太网SSD技术和新一代SSD控制器解决方案2019-08-19 5908
-
基于和SEP3203处理器和驱动控制器SSD1770的应用接口设计2021-03-16 3749
-
新型控制技术在新能源汽车控制器中的应用2021-05-19 1069
-
浅谈如何评估TI C2000系列微控制器程序的堆栈使用情况2022-10-31 951
-
浅谈固态存储中的SSD黄金赛道2023-01-11 1694
-
浅谈闪存控制器架构2023-08-29 1797
-
工业机器人应用中的AI边缘控制器:技术创新与效率提升的双重驱动2024-03-08 1849
-
SSD控制器的作用、构成及功能2024-09-02 3403
全部0条评论

快来发表一下你的评论吧 !
