

佐思汽研发布《2024年端到端自动驾驶研究报告》
描述
佐思汽研发布《2024年端到端自动驾驶研究报告》。
1
国内端到端方案现状
端到端自动驾驶是直接从传感器信息输入(如摄像头图像、LiDAR等)到控制命令输出(如转向、加减速等)映射的一套系统,最早出现在1988年的ALVINN项目,通过相机和激光测距仪进行输入和一个简单的神经网络生成的转向进行输出。
2024年初,特斯拉FSD V12.3版本发布,智驾水平让人惊艳,端到端自动驾驶方案受到国内主机厂和自动驾驶方案企业的广泛关注。
与传统的多模块方案相比,端到端自动驾驶方案将感知、预测和规划整合到单一模型中,简化了方案结构,可模拟人类驾驶员直接从视觉输入做出驾驶决策,以数据和算力为主导,能够有效解决模块化方案的长尾场景,提升模型的训练效率和性能上限。
传统多模块方案与端到端方案的对比(部分)
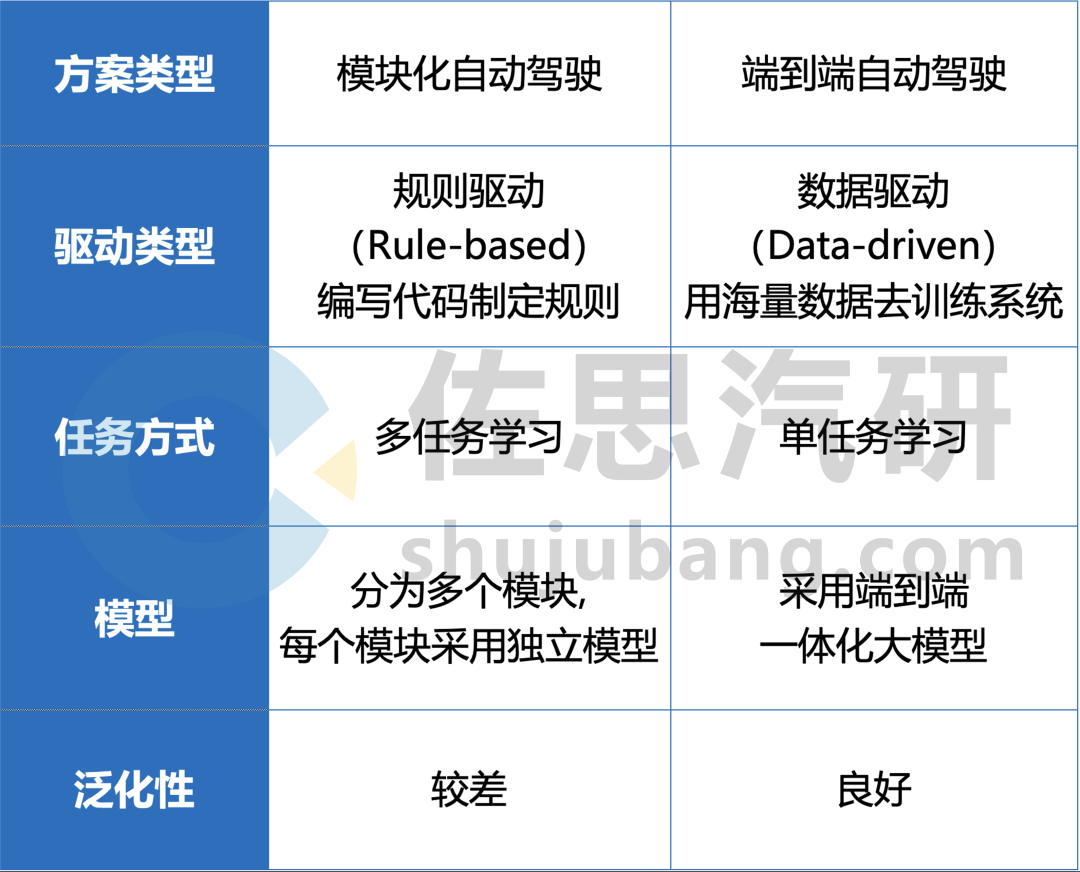
来源:佐思汽研《2024年端到端自动驾驶研究报告》
FSD V12.3版本实测图

来源:公开渠道
部分主机厂对端到端方案落地量产的规划
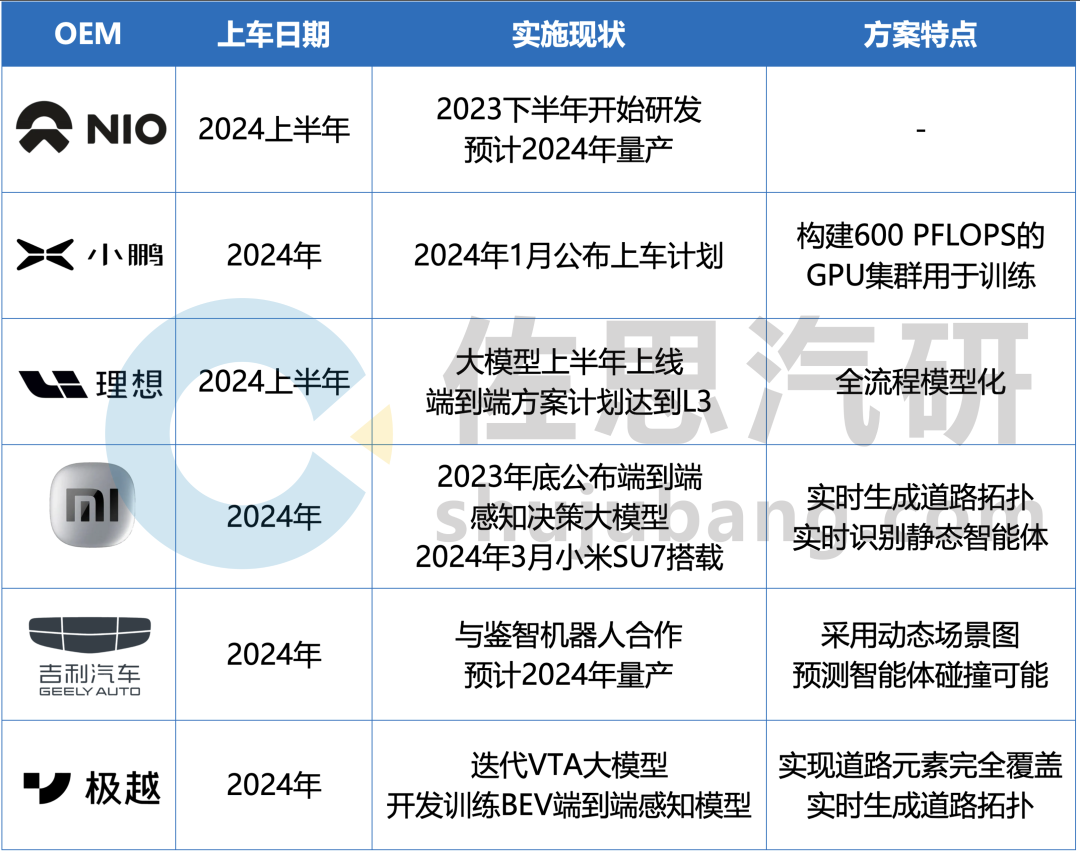
来源:佐思汽研《2024年端到端自动驾驶研究报告》
理想端到端方案
理想认为,完整的端到端需要完成感知、跟踪、预测、决策、规划整个过程的模型化,是实现L3级别自动驾驶的最佳方案。2023年,理想推送AD Max3.0,其整体框架已经具备端到端的理念,但距离完整的端到端尚有一定差距,2024年理想预计以此为基础,推进该系统成为一个彻底的端到端方案。
理想构建的自动驾驶框架如下图,分为两个系统:
快系统:System1,感知周围环境后直接执行,为理想现行的端到端方案。
慢系统:System2,多模态大语言模型,针对未知环境进行逻辑思考与探索,以解决L4未知场景下的问题。
理想自动驾驶框架
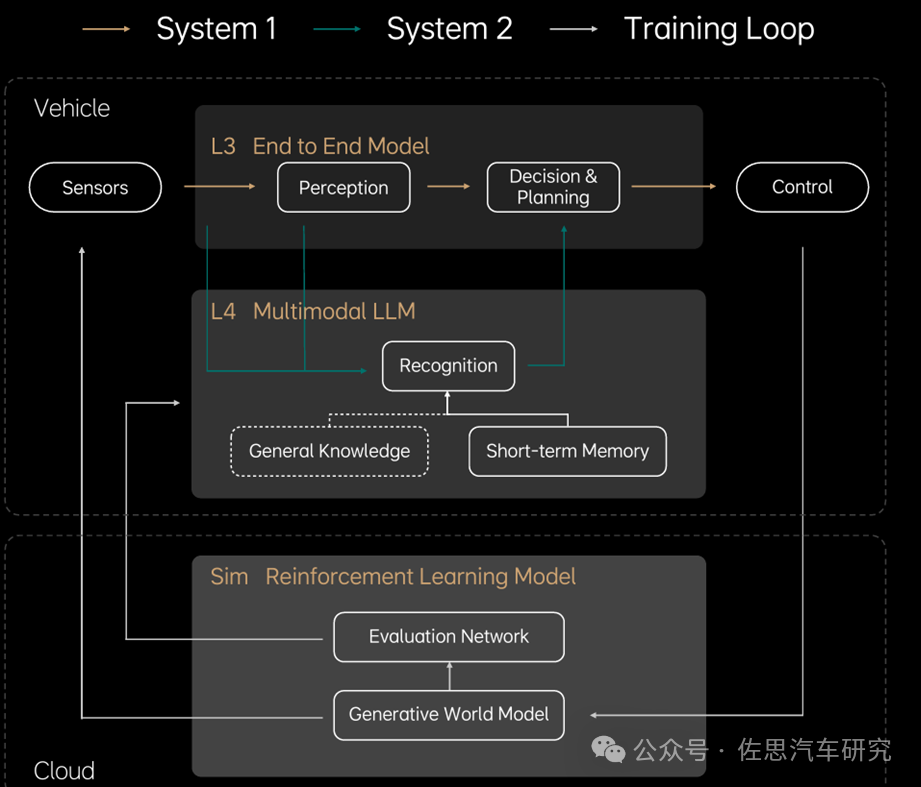
来源:理想汽车
在端到端方案推进的过程中,理想计划把规划/预测模型与感知模型进行统一,并在原基础上完成Temporal Planner的端到端,实现泊车/行车一体化。
2
数据成为端到端落地的关键
端到端方案的落地需要经历构建研发团队、配置硬件设施、数据收集处理、算法训练与策略定制、验证评估、推广量产等流程,部分场景痛点如表中所示:
端到端方案的部分场景痛点
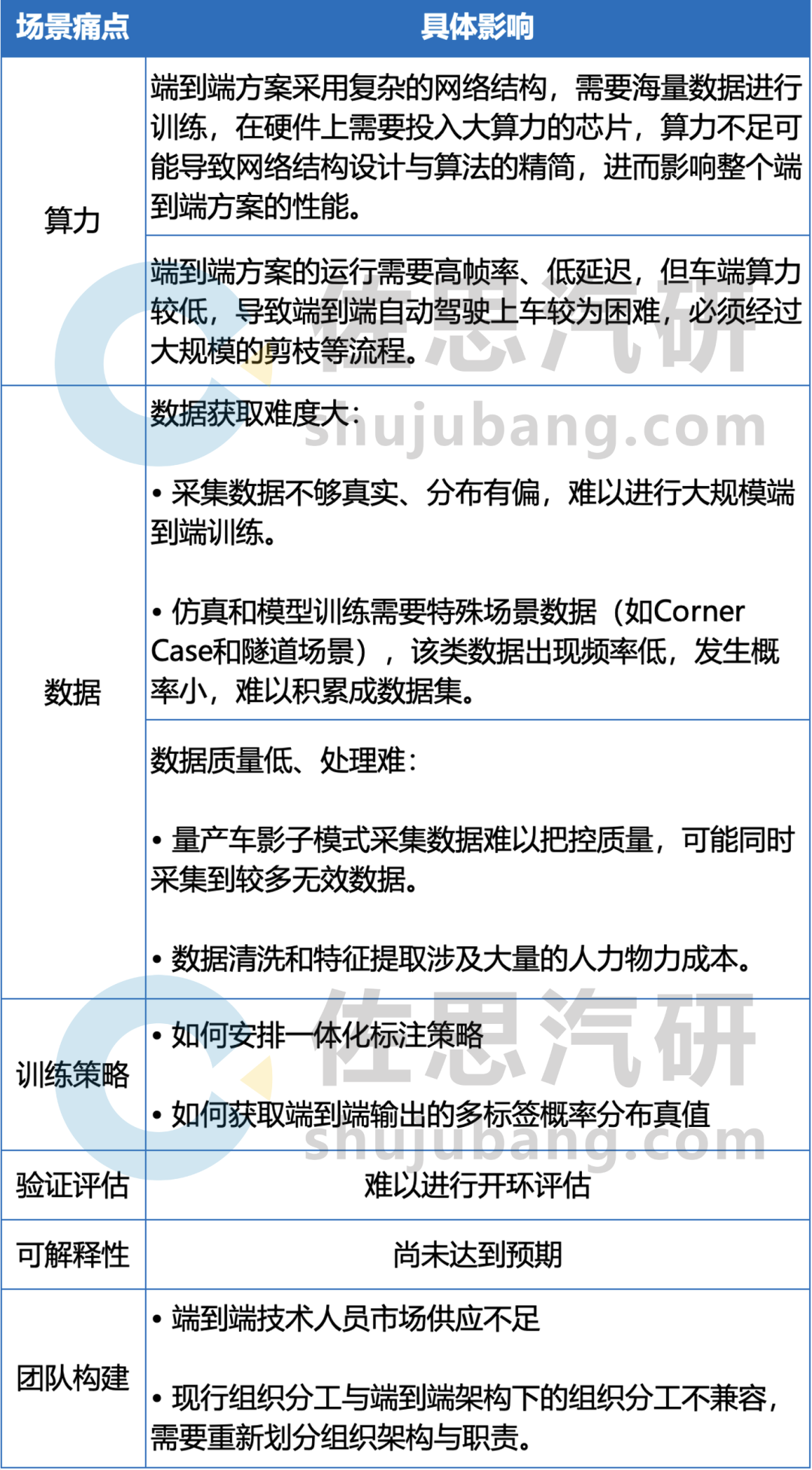
来源:佐思汽研《2024年端到端自动驾驶研究报告》
其中,端到端自动驾驶方案中的一体化训练需要大量的数据,因此其面临的难点之一在于数据的收集和处理。
首先,数据的收集需要大量的时间和渠道,数据类型除了驾驶数据外还包括各种不同的道路、天气和交通情况等场景数据,其中在实际驾驶中驾驶员前方视野的驾驶数据相对便于收集,周围方位的信息收集则难以保证。
再次,数据处理时需要设计数据提取维度、从海量的视频片段中提取有效的特征、统计数据分布等,以支持大规模的数据训练。
元戎启行
截至2024年3月,元戎启行端到端自动驾驶方案已经获得长城汽车的定点项目,并与英伟达开展合作,预计2025年适配英伟达Thor芯片;在元戎启行的规划中,从传统方案过渡到“端到端”自动驾驶方案,经历传感器前融合、去高精度地图、感知决策控制三个模型一体化等环节。
元戎启行在数据环节的布局

来源:佐思汽研《2024年端到端自动驾驶研究报告》
极佳科技
极佳科技的自动驾驶世界模型DriveDreamer,具备场景生成、数据生成、驾驶动作预测等功能;在场景/数据生成上,分为两个步骤:
涉及单帧结构化条件,引导DriveDreamer生成驾驶场景图像,便于其理解结构交通约束。
将其理解扩展到视频生成。利用连续的交通结构条件,DriveDreamer输出驾驶场景视频,进一步增强其对运动转换的理解。
DriveDreamer的功能包括可连续驾驶视频生成、与文本提示和结构化交通限制无缝对齐

来源:极佳科技
3
端到端方案加快具身机器人落地
除了自动驾驶汽车,具身机器人是端到端方案另一个主流场景。从端到端自动驾驶到机器人,需要构建更加通用的世界模型,来适应更加复杂、多元的现实使用场景,主流AGI(通用人工智能)发展的框架分为两个阶段:
阶段一:基础大模型理解和生成实现统一,进一步与具身智能结合,形成统一世界模型;
阶段二:世界模型+复杂任务的规控能力和抽象概念的归纳能力,逐步演化进入交互AGI 1.0时代。
在世界模型落地的过程中,构建端到端的VLA(Vision-Language-Action) 自主系统成为关键一环。VLA作为具身智能基础大模型,能够将3D感知、推理和行动无缝链接起来,形成一个生成式世界模型,并建立在基于3D的大型语言模型(LLM)之上,引入一组交互标记以与环境进行互动。
3D-VLA解决方案
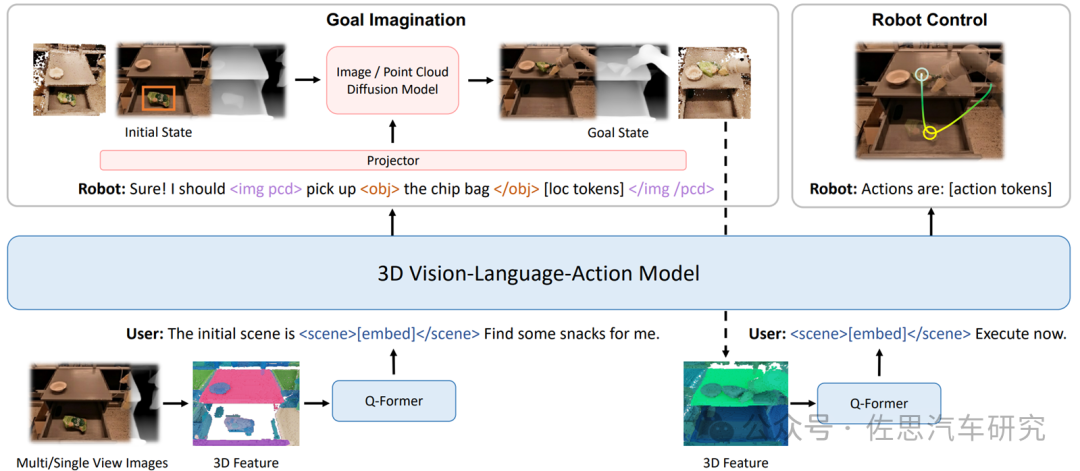
来源:University of Massachusetts Amherst、MIT-IBM Watson AI Lab等机构
截至2024年4月,部分采用端到端方案的具身机器人厂商如下:
部分具身机器人如何应用端到端方案
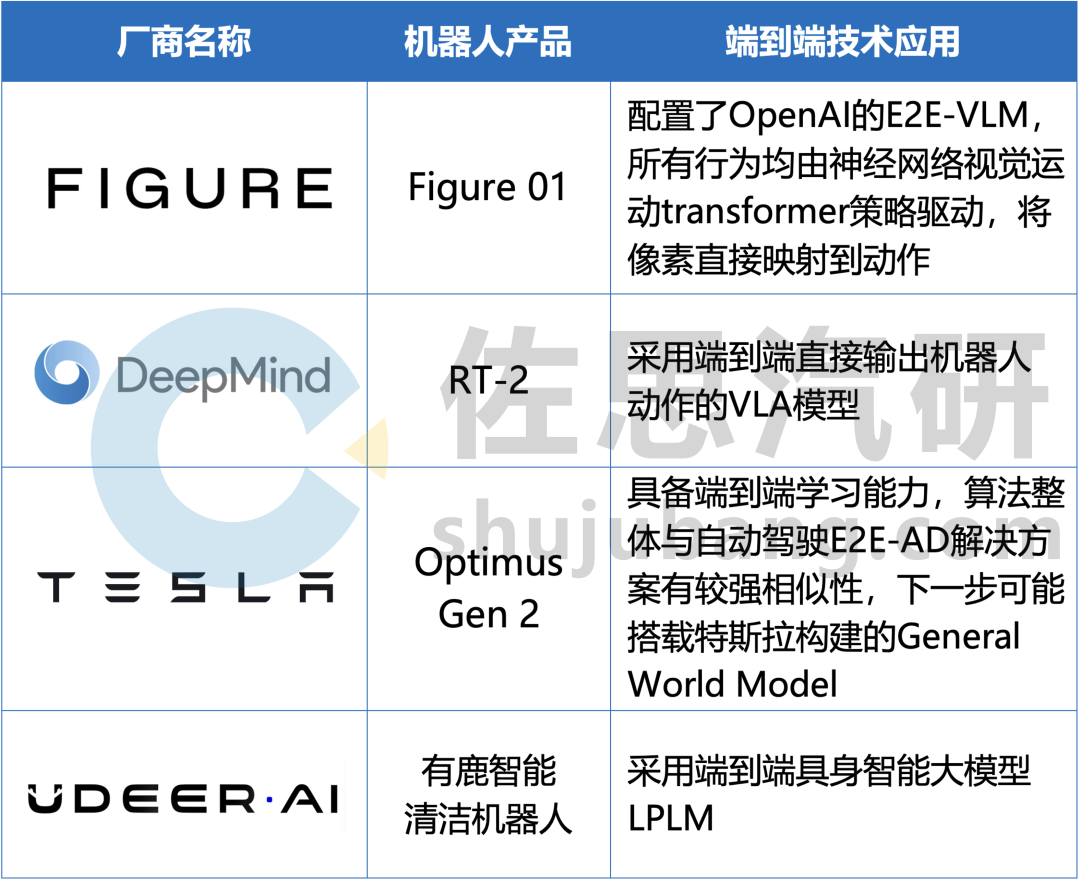
来源:佐思汽研《2024年端到端自动驾驶研究报告》
以有鹿机器人为例,其具身智能大模型LPLM(Large Physical Language Model)为端到端的具身智能解决方案,通过自我标注机制提升模型从未标注数据中的学习效率和质量,从而加深对世界的理解,进而加强机器人的泛化能力与跨模态、跨场景、跨行业场景下的环境适应性。
LPLM模型架构
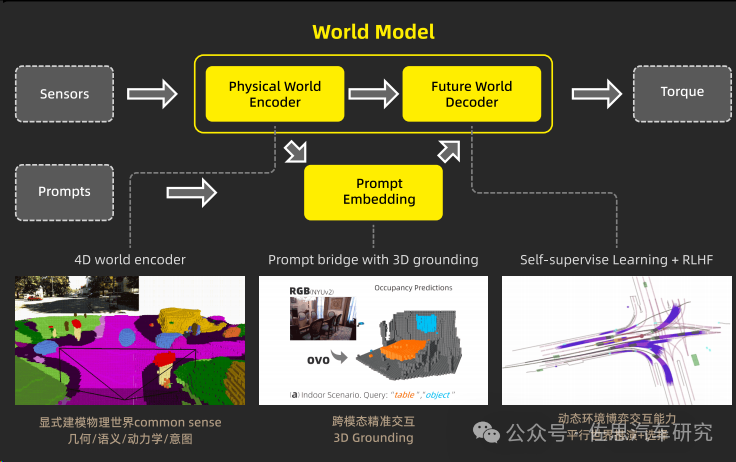
来源:有鹿机器人
LPLM 将物理世界抽象化,确保该类信息与 LLM 里特征的抽象等级对齐,将物理世界中每一个所指的实体显式建模为 token,编码几何、语义、运动学与意图信息。
此外,LPLM 在自然语言指令的编码中加入了 3D grounding,一定程度上弥补了自然语言不够精确的缺陷;其解码器能够通过不断预测未来的方式去学习,从而加强了模型从海量无标签数据中学习的能力。
审核编辑:刘清
-
汽车自动驾驶产业链深度研究报告:自动驾驶驶向何方 精选资料分享2021-08-27 3032
-
佐思汽研发布2020年中国汽车智能后视镜行业研究报告2020-09-04 7080
-
2020年自动驾驶传感器芯片行业研究报告2021-01-18 6073
-
佐思汽研发布2020年智慧停车行业研究报告2021-01-27 6686
-
2020年中国L2级自动驾驶市场研究报告2021-02-05 8059
-
全球及中国矿山自动驾驶行业研究报告2021-03-18 5388
-
2023年汽车车内通信及网络接口芯片行业研究报告2023-08-02 4009
-
混合动力汽车研究:电动化计划推迟 PHEV&增程式占比将抬升至40%2024-01-25 4370
-
佐思汽研发布《2024年北京车展新四化趋势分析报告》2024-05-21 2950
-
端到端自动驾驶技术研究与分析2024-12-19 2187
-
自动驾驶域控研究:One board/One Chip方案将对汽车供应链产生深远影响2024-12-30 3677
-
2025年汽车微电机及运动机构行业研究报告2025-02-20 3166
-
东风汽车推出端到端自动驾驶开源数据集2025-04-01 1522
-
Nullmax端到端自动驾驶最新研究成果入选ICCV 20252025-07-05 2182
-
自动驾驶物理AI和端到端之间是如何配合的?2026-07-03 347
全部0条评论

快来发表一下你的评论吧 !
