

浅析python导入包引发的debug缓慢问题
描述
先上代码
from openpyxl import load_workbook
import numpy as np
import pandas as pd
import xlwings as xw
import csv
import jieba
import pangu
import re
print('hello')
这个样例,在print行加一个断点,即可测试出缓慢效果
Linux下的虚拟环境启用
开始用win来测试效果,发现很慢,难道和系统有关系吗,于是进行linux下的python代码debug尝试。
manjaro或者archlinux用pip安装报错,比如
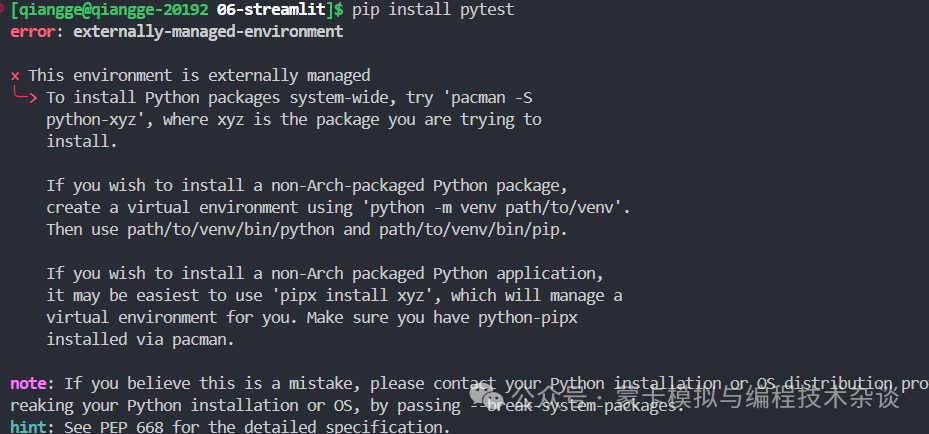
处理这个情况的设置好vscode,做好如下勾选
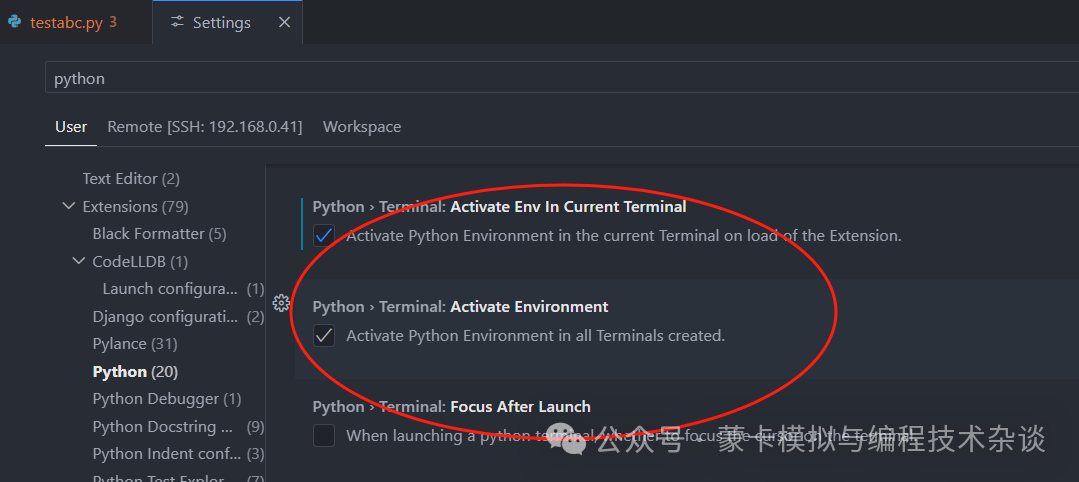
这样debug的时候就可以有效加载虚拟环境。
使用cprofile进行性能跟踪
import cProfile
import pstats
# import some_module
def import_module():
# from openpyxl import load_workbook
import jieba
def profile_import():
# 创建一个性能分析器对象
profile = cProfile.Profile()
profile.enable()
# 运行要分析的函数
import_module()
# 停止性能分析
profile.disable()
# 生成一个性能报告
stats = pstats.Stats(profile)
# stats.sort_stats("cumulative").print_stats(10) # 打印前10行统计信息
stats.sort_stats("cumulative").print_stats() # 打印前10行统计信息
if __name__=="__main__":
profile_import()
发现
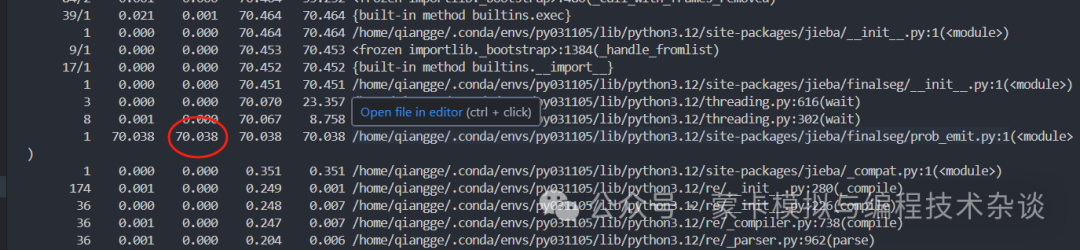
/home/qiangge/.conda/envs/py031105/lib/python3.12/site-packages/jieba/finalseg/prob_emit.py
这里的文件共35000多行,因为这个吗?怀疑是多线程问题导致。
非debug模式下,也就是runcode模式下,并不会出现这个prob_emit.py的加载。这里估计是多线程在debug下会有阻塞问题。
小结
并没有彻底找出根因,但是很显然,有如下结论
导入包,对于运行没有性能问题
导入包,对于不同的包,性能影响很显著
可能是多线程引发了debug性能问题。
审核编辑:刘清
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
python如何导入模块2023-11-22 2057
-
Python导入包操作和本质2023-09-12 1689
-
python包模块相对导入from和import介绍12023-02-21 1713
-
将Python脚本集成到GUI工具包2023-02-15 2116
-
python 包导入的三个冷门知识点2022-03-14 2423
-
详解python常规包与命名空间包2022-03-11 4340
-
python包、模块和库是什么2022-03-09 3085
-
导入Python库失败的缺失库怎么解决2020-11-21 4628
-
Python imports指南:Python的导入有更好的理解2018-05-01 3632
全部0条评论

快来发表一下你的评论吧 !
