

基于FPGA BRAM的多端口地址查找表与FPGA BRAM的资源分析
描述
一、背景
在多端口交换机的设计中,交换机的每个端口都会各自维护一张查找表,数据帧进入到交换机后,需要进行查表和转发。但随着端口数量和表项需求的增加,每个端口都单独维护一张表使得FPGA的资源变得非常紧张。因此,需要一张查找表(本质是可读可写的RAM),能够满足多读多写的功能。但在Xilinx FPGA上,Xilinx提供的BRAM IP最高只能实现真双端口RAM。不能满足多读多写的需求。
补充:这里不使用其他RAM类型如URAM的原因是,BRAM拥有更好的时序,更适合在高速交换中用于查找表。
二、手写Multiport Ram
Multiport Ram,即多读多写存储器,本工程实现的是1个口写,同时满足11个口读的BRAM。
为了让vivado在综合的时候把手写ram例化为BRAM,我们需要按照官方手册的要求编写multiport ram。这时需要通过(*ram_style="block"*)对array进行修饰。
查看Vivado的官方手册ug901可知,对于Distributed RAM(LUTRAM)和Dedicated Block RAM(BRAM),二者都是写同步的。主要区别在于读数据,前者为异步,后者为同步的。

下面给出一种手写多端口bram的方案并给出一种优化FPGA bram资源利用的方法。
Multiport RAM 代码方案
实现多端口bram最简单的方法就是把读数据部分的逻辑复制11份,写数据部分的逻辑保留1份。
部分代码如下,实现位宽73bit,深度为16K的multiport ram:
(*ram_style="block"*)reg [DATA_WIDTH-1:0] bram [0:DEPTH-1];
/*-------------复制读端口11份---------------*/
always @(posedge clk)
begin
if(re1)
rd_data1 <= bram[rd_addr1];
else
rd_data1 <= rd_data1;
end
/*-----------------------------------------*/
//write
always @(posedge clk)
begin
if(we)
bram[wr_addr]<=wr_data;
end
endmodule
资源评估
利用vivado综合实现后,消耗的资源如下
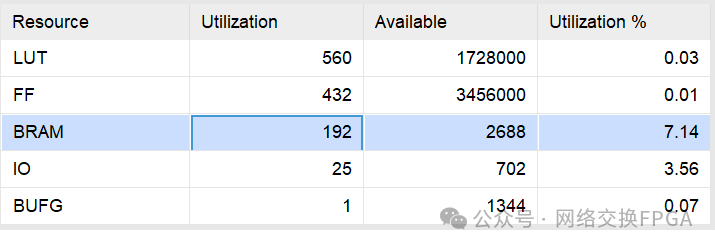
MultiportRAM:16K深度,73位宽的单口写,11口读的RAM消耗的BRAM数为192个。
普通真双口RAM:利用vivado IP核生成的16K深度,73bit位宽的真双口RAM消耗的BRAM数为32个。即如果11个端口各自维护一张地址查找表共使用352个RAM。
对比发现,在满足11个端口同时读地址查找表的条件下,多端口RAM比普通RAM节约了45%左右的BRAM资源
三、Multiport RAM 资源利用的优化
可能有的同学说,在某些大工程里面,192个BRAM还是有点多。下面我给出了一种降低BRAM资源消耗的方法。
首先我们把例化的ram array的位宽翻倍
//原本 (*ram_style="block"*)reg [DATA_WIDTH-1:0] bram [0:DEPTH-1]; //现在 (*ram_style="block"*)reg [DATA_WIDTH+DATA_WIDTH-1:0] bram [0:DEPTH-1];
(有同学会问了,这样资源消耗不是翻倍了吗?···别急!)
我们把需要写入RAM的数据,73位写data复制成两份,同时写进bram的高73位和低73位,地址不变,其中multi_wdata是我们要写进表中的73位表项,代码如下:
//bram例化模块的写使能、地址和数据
.we ( multi_wr),
.wr_addr (multi_waddr),
.wr_data ({multi_wdata,multi_wdata})
在bram输出中,每两个端口共用一个143位的bram行,并根据使能情况赋值:
//read1
assign rd_data1_wire = rd_data1[72:0] ;
assign rd_data2_wire = rd_data2[145:73];
always @(posedge clk)
begin
if (re1 & re2) begin
rd_data1 <= bram[rd_addr1];
rd_data2 <= bram[rd_addr2];
end
else
if(re1) begin
rd_data1 <= bram [rd_addr1];
end
else if (re2) begin
rd_data2 <= bram [rd_addr2];
end
end
***补充:具体代码在文章开头链接
资源评估
利用vivado综合实现后,消耗的资源如下
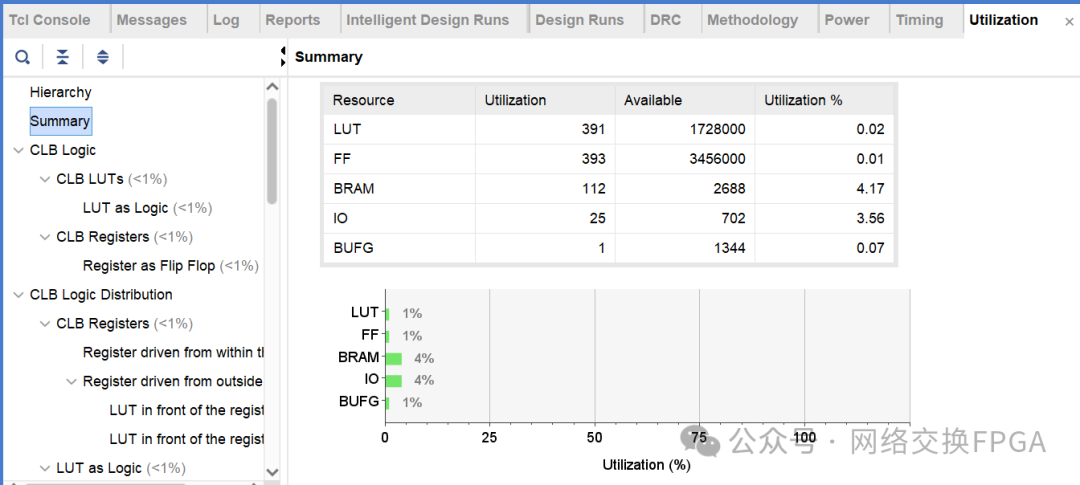
MultiportRAM:16K深度,146位宽的单口写,11口读的RAM消耗的BRAM数为112个。
普通真双口RAM:利用vivado IP核生成的16K深度,73bit位宽的真双口RAM消耗的BRAM数为32个。即如果11个端口各自维护一张表共使用352个RAM
对比发现,在满足11个端口同时读地址查找表的条件下,多端口RAM比普通RAM节约了68%左右的BRAM资源
四、防止读写冲突的组合逻辑设计(写优先)
代码原理,利用组合逻辑时序,当写入地址和读地址相同时,写入地址、数据正常进行,但读端口不对RAM进行读取,而是将写入端的数据直接赋值给读出端的数据。
下一拍,即读写冲突结束后的下一拍,再读一拍RAM中的数据,使得读端口数据保持这一次读的结果(因为组合逻辑在读写冲突时没有真正读RAM,所以RAM输出data会保持上一次输出的data),但这一步不是必要的,纯粹为了好看。
部分代码如下:
//防止读写冲突,且为写优先逻辑 assign multi_rdata0 =(multi_raddr0_f ==multi_waddr_f && multi_raddr0_f !='b0 )?multi_wdata_f:multi_rdata0_ram ; assign multi_rdata1 =(multi_raddr1_f ==multi_waddr_f && multi_raddr1_f !='b0 )?multi_wdata_f:multi_rdata1_ram ; assign multi_rdata2 =(multi_raddr2_f ==multi_waddr_f && multi_raddr2_f !='b0 )?multi_wdata_f:multi_rdata2_ram ; assign multi_rdata3 =(multi_raddr3_f ==multi_waddr_f && multi_raddr3_f !='b0 )?multi_wdata_f:multi_rdata3_ram ; assign multi_rdata4 =(multi_raddr4_f ==multi_waddr_f && multi_raddr4_f !='b0 )?multi_wdata_f:multi_rdata4_ram ; assign multi_rdata5 =(multi_raddr5_f ==multi_waddr_f && multi_raddr5_f !='b0 )?multi_wdata_f:multi_rdata5_ram ; assign multi_rdata6 =(multi_raddr6_f ==multi_waddr_f && multi_raddr6_f !='b0 )?multi_wdata_f:multi_rdata6_ram ; assign multi_rdata7 =(multi_raddr7_f ==multi_waddr_f && multi_raddr7_f !='b0 )?multi_wdata_f:multi_rdata7_ram ; assign multi_rdata8 =(multi_raddr8_f ==multi_waddr_f && multi_raddr8_f !='b0 )?multi_wdata_f:multi_rdata8_ram ; assign multi_rdata9 =(multi_raddr9_f ==multi_waddr_f && multi_raddr9_f !='b0 )?multi_wdata_f:multi_rdata9_ram ; assign multi_rdata10=(multi_raddr10_f==multi_waddr_f && multi_raddr10_f!='b0 )?multi_wdata_f:multi_rdata10_ram; assign multi_raddr0_ram =(multi_raddr0_f ==multi_waddr_f && multi_raddr0_f !='b0 )?multi_waddr_f: multi_raddr0; assign multi_raddr1_ram =(multi_raddr1_f ==multi_waddr_f && multi_raddr1_f !='b0 )?multi_waddr_f: multi_raddr1; assign multi_raddr2_ram =(multi_raddr2_f ==multi_waddr_f && multi_raddr2_f !='b0 )?multi_waddr_f: multi_raddr2; assign multi_raddr3_ram =(multi_raddr3_f ==multi_waddr_f && multi_raddr3_f !='b0 )?multi_waddr_f: multi_raddr3; assign multi_raddr4_ram =(multi_raddr4_f ==multi_waddr_f && multi_raddr4_f !='b0 )?multi_waddr_f: multi_raddr4; assign multi_raddr5_ram =(multi_raddr5_f ==multi_waddr_f && multi_raddr5_f !='b0 )?multi_waddr_f: multi_raddr5; assign multi_raddr6_ram =(multi_raddr6_f ==multi_waddr_f && multi_raddr6_f !='b0 )?multi_waddr_f: multi_raddr6; assign multi_raddr7_ram =(multi_raddr7_f ==multi_waddr_f && multi_raddr7_f !='b0 )?multi_waddr_f: multi_raddr7; assign multi_raddr8_ram =(multi_raddr8_f ==multi_waddr_f && multi_raddr8_f !='b0 )?multi_waddr_f: multi_raddr8; assign multi_raddr9_ram =(multi_raddr9_f ==multi_waddr_f && multi_raddr9_f !='b0 )?multi_waddr_f: multi_raddr9; assign multi_raddr10_ram=(multi_raddr10_f==multi_waddr_f && multi_raddr10_f!='b0 )?multi_waddr_f: multi_raddr10; assign multi_rd0_ram =(multi_raddr0 ==multi_waddr && multi_raddr0!='b0 )? 1'b0:((multi_raddr0_f ==multi_waddr_f && multi_raddr0_f !='b0 )?multi_rd0_f :multi_rd0 ); assign multi_rd1_ram =(multi_raddr1 ==multi_waddr && multi_raddr1!='b0 )? 1'b0:((multi_raddr1_f ==multi_waddr_f && multi_raddr1_f !='b0 )?multi_rd1_f :multi_rd1 ); assign multi_rd2_ram =(multi_raddr2 ==multi_waddr && multi_raddr2!='b0 )? 1'b0:((multi_raddr2_f ==multi_waddr_f && multi_raddr2_f !='b0 )?multi_rd2_f :multi_rd2 ); assign multi_rd3_ram =(multi_raddr3 ==multi_waddr && multi_raddr3!='b0 )? 1'b0:((multi_raddr3_f ==multi_waddr_f && multi_raddr3_f !='b0 )?multi_rd3_f :multi_rd3 ); assign multi_rd4_ram =(multi_raddr4 ==multi_waddr && multi_raddr4!='b0 )? 1'b0:((multi_raddr4_f ==multi_waddr_f && multi_raddr4_f !='b0 )?multi_rd4_f :multi_rd4 ); assign multi_rd5_ram =(multi_raddr5 ==multi_waddr && multi_raddr5!='b0 )? 1'b0:((multi_raddr5_f ==multi_waddr_f && multi_raddr5_f !='b0 )?multi_rd5_f :multi_rd5 ); assign multi_rd6_ram =(multi_raddr6 ==multi_waddr && multi_raddr6!='b0 )? 1'b0:((multi_raddr6_f ==multi_waddr_f && multi_raddr6_f !='b0 )?multi_rd6_f :multi_rd6 ); assign multi_rd7_ram =(multi_raddr7 ==multi_waddr && multi_raddr7!='b0 )? 1'b0:((multi_raddr7_f ==multi_waddr_f && multi_raddr7_f !='b0 )?multi_rd7_f :multi_rd7 ); assign multi_rd8_ram =(multi_raddr8 ==multi_waddr && multi_raddr8!='b0 )? 1'b0:((multi_raddr8_f ==multi_waddr_f && multi_raddr8_f !='b0 )?multi_rd8_f :multi_rd8 ); assign multi_rd9_ram =(multi_raddr9 ==multi_waddr && multi_raddr9!='b0 )? 1'b0:((multi_raddr9_f ==multi_waddr_f && multi_raddr9_f !='b0 )?multi_rd9_f :multi_rd9 ); assign multi_rd10_ram=(multi_raddr10==multi_waddr && multi_raddr1!='b0 )? 1'b0:((multi_raddr10_f==multi_waddr_f && multi_raddr10_f!='b0 )?multi_rd10_f:multi_rd10);
***补充:具体代码在文章开头链接
读写冲突的仿真结果如下:
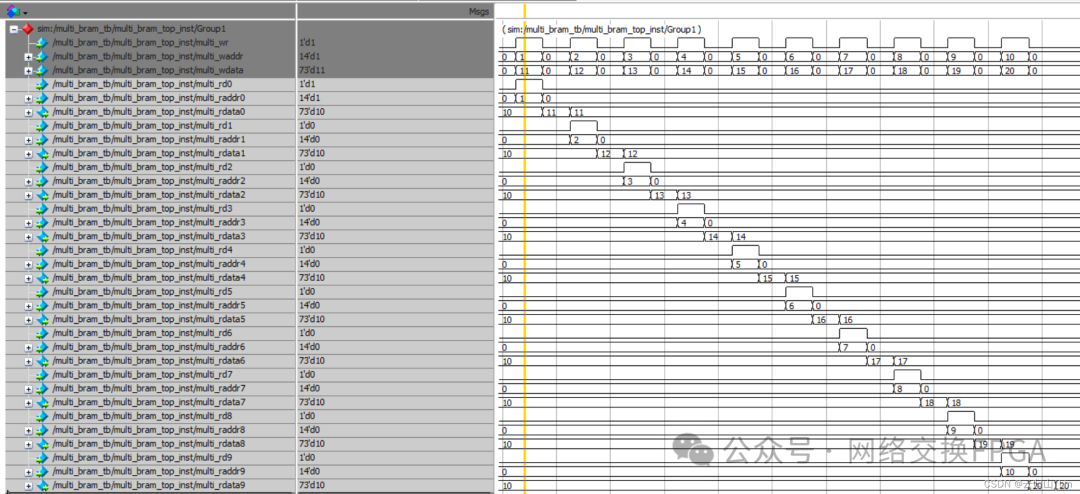
五、Multiport RAM仿真和时序
所有写端口都是一拍写入。读端口是第一拍读使能,读地址,第二拍读出数据。
1.单口写数据

2.单端口读数据

3.多口读相同数据
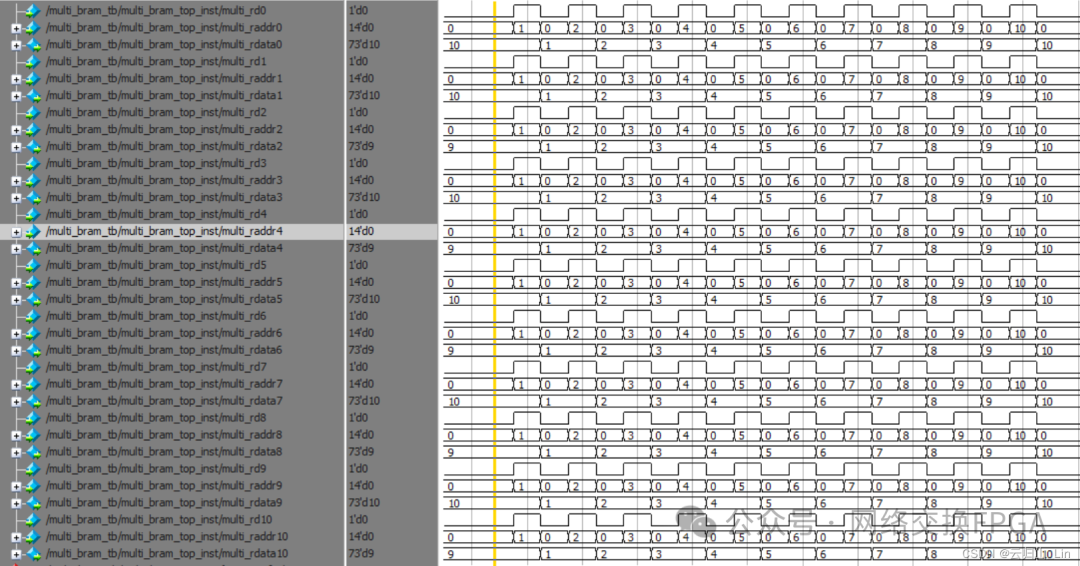
4.多口同时读不同数据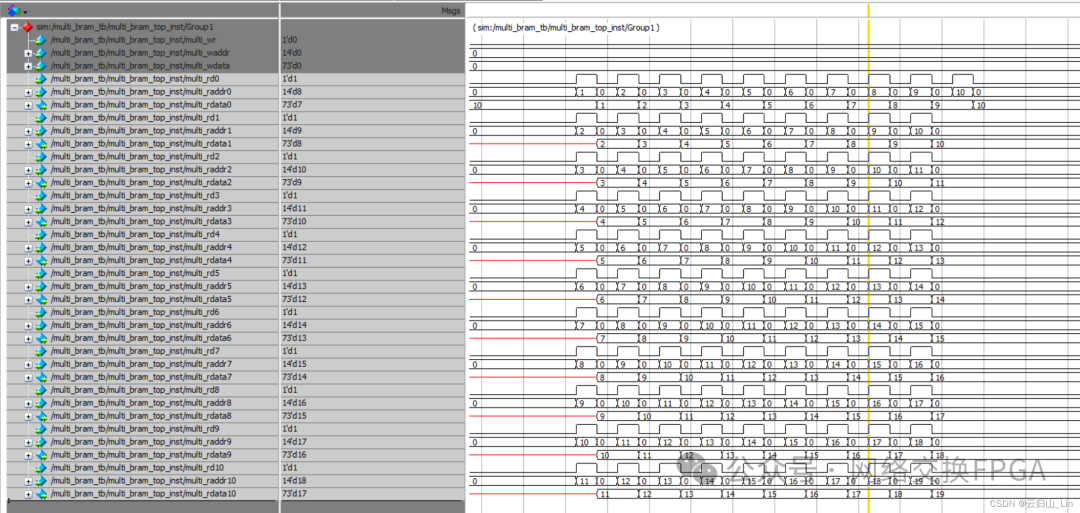
-
HLS设计中的BRAM使用优势2026-01-28 595
-
基于FPGA设计的BRAM内部结构2024-04-25 1369
-
FPGA的BRAM资源使用优化策略2023-08-30 6000
-
Vivado中BRAM IP的配置方式和使用技巧2023-08-29 11189
-
FPGA设计中BRAM的知识科普2023-08-15 8456
-
URAM和BRAM有哪些区别2022-07-25 8033
-
【FPGA ZYNQ Ultrascale+ MPSOC教程】33.BRAM实现PS与PL交互2021-02-22 10379
-
URAM和BRAM有什么区别2021-01-27 2407
-
使用FPGA调用RAM资源的详细说明2020-12-30 2265
-
FPGA实现基于Vivado的BRAM IP核的使用2020-12-29 13827
-
URAM和BRAM的区别是什么2020-12-23 4822
-
无法正确写入双端口BRAM2019-04-17 2126
-
如何在不使用DDR内存控制器的情况下设计FPGA BRAM大容量存储单元?2019-04-04 3100
-
怎么从Virtex 6的FPGA中取出BRAM转储2019-03-20 1622
全部0条评论

快来发表一下你的评论吧 !
