

李彦宏说开源模型会越来越落后,为什么很多人不认同?
描述
上周,百度董事长兼CEO李彦宏对于开源大模型的一番言论引发了争议。
李彦宏在Create 2024百度AI开发者大会上表示:“开源模型会越来越落后。”
李彦宏的解释是,百度基础模型文心4.0可根据不同需求,在效果、响应速度和推理成本等方面灵活剪裁,生成适应各种场景的精简模型,并支持精调和post pretrain。相较于直接使用开源模型,文心4.0剪裁出的模型在同等尺寸下表现更佳,而在同等效果下成本更低,因此他预测开源模型将会越来越落后。
但很多AI从业者都不太认同这一结论。比如猎豹移动董事长兼CEO、猎户星空董事长傅盛很快发视频反驳,说“开源社区将最终战胜闭源”。
开源模型到底能否超越闭源模型?这个问题从去年开始就备受争议。
去年5月,外媒曾报道谷歌流出一份文件,主题是“我们没有护城河,OpenAI也没有。当我们还在争吵时,开源已经悄悄地抢了我们的饭碗”。
去年Meta发布开源大模型Llama 2后,Meta副总裁、人工智能部门负责人杨立昆(Yann LeCun)表示,Llama 2将改变大语言模型的市场格局。
人们对于Llama系列模型所引领的开源社区备受期待。但直到今天,最新发布的Llama 3仍然没有追上最先进的闭源模型GPT-4,尽管两者的差距已经很小了。
「甲子光年」采访了多位AI从业者,一个普遍的反馈是,讨论开源好还是闭源好,本身是由立场决定的,也不简简单单是一个二元对立的问题。
开源与闭源并非一个技术问题,更多是一个商业模式的问题。然而,大模型当前的发展现状是,不论是开源还是闭源,都还没有找到切实可行的商业模式。
所以,未来到底会如何发展呢?
1.差距没有拉大,而是在缩小
开源模型与闭源模型到底谁更强?不妨先看一下客观的数据排名情况。
大模型领域最权威的榜单是大模型竞技场(LLM Arena),采用了国际象棋一直采用了ELO积分体系。它的基本规则是,让用户向两个匿名模型(例如 ChatGPT、Claude、Llama)提出任何问题,并投票给回答更好的一个。回答更好的模型将获得积分,最终的排名由累计积分的高低来确定。Arean ELO收集了50万人的投票数据。 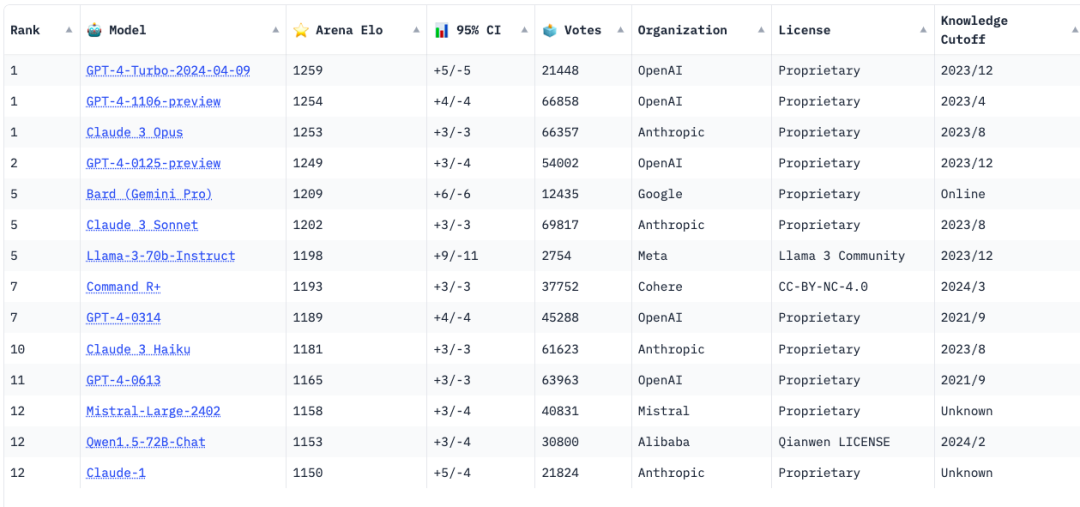
大模型排行榜,图片来自LLM Arena截图
在LLM Arena榜单上,OpenAI的GPT-4长期霸榜第一。Anthropic最新发布的Claude 3曾短期取代GPT-4取得第一名的桂冠,但OpenAI很快发布最新版本的GPT-4 Turbo,重新夺回第一的宝座。
LLM Arena排名前十的模型基本上被闭源模型垄。能够挤进前十名榜单的开源模型只有两个:一是Meta上周刚刚发布的LLama 3 70B,排名第五,也是表现最好的开源模型;二是“Transformer八子”之一的Aidan Gomez创立的Cohere近期发布的Command R+,排名第七。值得一提的是,阿里发布的开源模型Qwen1.5-72B-Chat,排名第十二,是国内表现最好的开源模型。
从绝对排名上看,闭源模型仍然遥遥领先开源模型。但若从两者的差距来看,并非李彦宏所说的越来越大,而是越来越小。 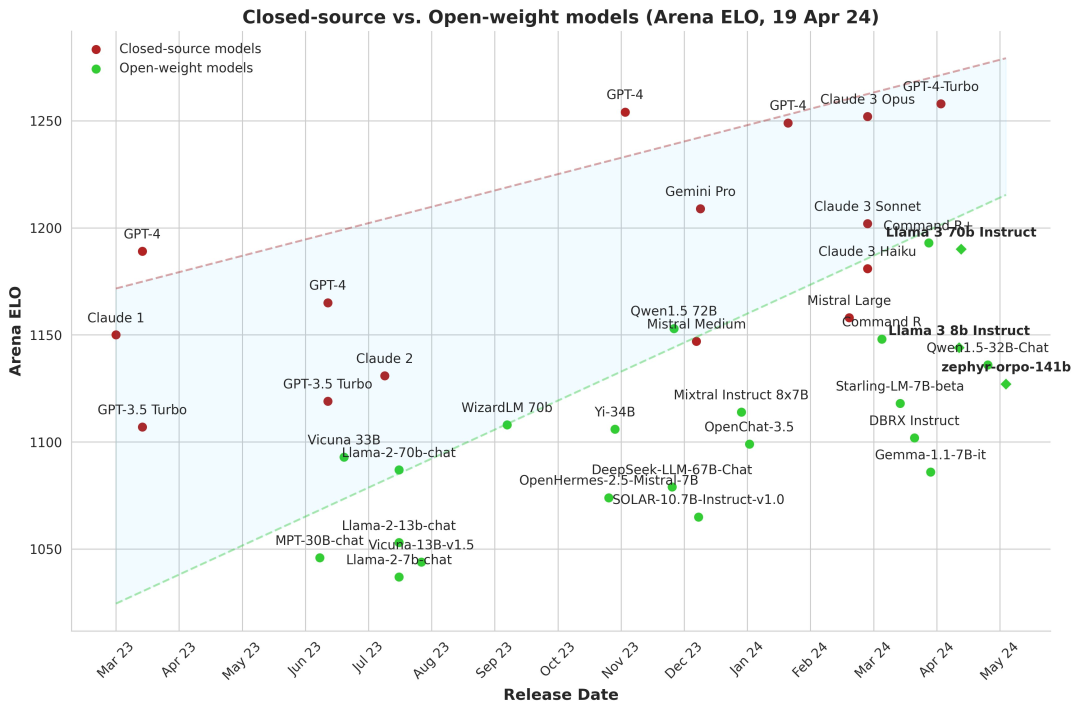
闭源模型与开源模型的差距,图片来自X
昆仑万维董事长兼CEO方汉此前曾对「甲子光年」表示,开源模型与闭源模型的差距已经从落后2年追到仅落后4~6个月了。
什么因素会影响开源和闭源模型的能力差异?
微博新技术研发负责人张俊林认为,模型能力增长曲线的平滑或陡峭程度比较重要。如果模型能力增长曲线越陡峭(单位时间内,模型各方面能力的增长数量,越快就类似物体运动的“加速度”越大),则意味着短时间内需要投入越大的计算资源,这种情况下闭源模型相对开源模型是有优势的,主要是资源优势导致的模型效果优势。
反过来,如果模型能力增长曲线越平缓,则意味着开源和闭源模型的差异会越小,追赶速度也越快。这种由模型能力增长曲线陡峭程度决定的开源闭源模型的能力差异,可以称之为模型能力的“加速度差”。
张俊林认为,往后多看几年,开源与闭源的能力是缩小还是增大,取决于在“合成数据”方面的技术进展。如果“合成数据”技术在未来两年能获得突破,则两者差距是有可能拉大的;如果不能突破,则开源和闭源模型能力会相当。
所以,“合成数据”是未来两年大语言模型最关键的决定性的技术,很可能没有之一。
2.开源模型的“真假开源”
人们对于开源模型的期待,很大程度上就在于“开源”两个字。
开源是软件行业蓬勃发展的决定性力量。正如360集团创始人周鸿祎近期在哈佛大学演讲中提到的那样:“没有开源就没有Linux,没有PHP,没有MySQL,甚至没有互联网。包括在人工智能的发展上,如果没有当初谷歌开源Transformer,就不会有OpenAI和GPT。我们都是受益于开源成长起来的个人和公司。”
但是,这一次的开源模型可能要让很多开源信徒失望了。
去年Llama 2发布后不久,就有批评声音称,Meta其实是在“假开源”。
比如,开源友好型风险投资公司RedPoint的董事总经理Erica Brescia表示:“谁能向我解释一下,如果Llama 2实际上没有使用OSI(开放源码计划)批准的许可证,也不符合OSD(开放源码定义),Meta公司和微软公司又如何称Llama 2为开放源码?他们是在故意挑战OSS(开放源码软件)的定义吗?”
的确,Llama 2并没有遵循上述协议,而是自定义了一套“开源规则”,包括禁止使用Llama 2去训练其它语言模型,如果该模型用于每月用户超过7亿的应用程序和服务,则需要获得Meta的特殊许可证。
Llama 2虽然自称为开源模型,但仅仅开放了模型权重——也就是训练之后的参数,但训练数据、训练代码等关键信息都未开放。
零一万物开源负责人林旅强告诉「甲子光年」,现在说的开源模型,对比开源软件来说,是一种介于闭源与开源的中间状态,开发者可以在其基础上做微调、做RAG,但又无法像开源软件那样对模型本身做修改,更无法得到其训练源数据。
在“真开源”的开源软件领域,一个显著的特点是软件源代码共享,开源社区的开发者不仅可以反馈Bug,而且可以直接贡献代码。 比如,国产开源数据库TiDB就分享过一组数据,在每年更新的40%的代码中,有40%是由外部贡献者贡献的。
但由于大模型的算法黑盒,仅仅开放模型权重的“半开源”,导致了一个结果:用Llama 2的开发者再多,也不会帮助Meta提升任何Llama 3的能力和Know-how,Meta也无法靠Llama 2获取任何的数据飞轮。
Meta想要训练更强的Llama 3,还是只能靠自己团队内部的人才、数据、GPU资源来做,还是需要做实验(比如Scailing Law)、收集更多的优质数据、建立更大的计算集群。这本质上与OpenAI训练闭源的GPT-4无异。
正如李彦宏在百度内部信中所言,开源模型并不能像开源软件那样做到“众人拾柴火焰高”。
今天,很多开源模型都注意到了这个问题。比如谷歌在发布开源模型Gemma的时候,谷歌特意将其命名为“开放模型(Open Model)”而非“开源模型(Open Source Model)”。谷歌表示:开放模型具有模型权重的免费访问权限,但使用条款、再分发和变体所有权根据模型的具体使用条款而变化,这些条款可能不基于开源许可证。
昆仑万维AI Infra负责人成诚在知乎上对于开源模型做了以下分级:
仅模型开源(技术报告只列举了 Evaluation)。主要利好做应用的公司(继续训练和微调)和普通用户(直接部署)
技术报告开源训练过程。比较详尽的描述了模型训练的关键细节。利好算法研究。
训练代码开源/技术报告开源全部细节。包含了数据配比的核心关键信息。这些信息价值连城,是原本需要耗费很多GPU资源才能得到的Know-how。
全量训练数据开源。其他有算力资源的团队可以基于训练数据和代码完全复现该模型。训练数据可以说是大模型团队最核心的资产。
数据清洗框架和流程开源。从源头的原始数据(比如CC网页、PDF电子书等)到 可训练的数据的清洗过程也开源, 其他团队不仅可以基于此清洗框架复现数据预处理过程,还可以通过搜集更多的源(比如基于搜索引擎抓取的全量网页)来扩展自己的数据规模,得到比原始模型更强的基座模型。
他表示,实际上大部分的模型开源诸如LLama2、Mistral、Qwen等,只做到Level-1, 像DeepSeek可以做到Level-2。 而Level-4及以上的开源一个都没有。至今没有一家公司开源自己的全部训练数据和数据清洗代码,以至于开源模型无法被第三方完整复现。
这样做的结果是: 掌握着模型进步的核心机密(数据、配比)被大模型公司牢牢掌握在自己手里,除了大模型公司自己的团队,没有任何其他来自开源社区的力量可以帮助其提升下一次训练模型的能力。
因此,这就回到一个关键问题:如果开源不能借助外部力量帮助提升模型性能,为什么还要开源?
3.模型开源的意义是什么?
开源还是闭源,本身并不决定模型性能的高低。闭源模型并非因为闭源而领先,开源模型也并非因为开源而落后。甚至恰恰相反,模型是因为领先才选择闭源,因为不够领先不得不选择开源。
因此,如果一家公司做出了性能很强的模型,它就有可能不再开源了。
比如法国的明星创业公司Mistral,其开源的最强7B模型Mistral-7B和首个开源MoE模型8x7B(MMLU 70)是开源社区声量最大的模型之一。 但是,Mistral后续训练的Mistral-Medium(MMLU-75)、Mistral-Large(MMLU-81) 均是闭源模型。
目前性能最好的闭源模型与性能最好的开源模型都是由大公司所主导,而大公司里又属Meta的开源决心最大。如果OpenAI不开源是从商业回报的角度来考虑,那么Meta选择开源让用户免费试用的目的又是什么呢?
在上一季度的财报会上,扎克伯格对这件事的回应是,Meta开源其AI技术是出于推动技术创新、提升模型质量、建立行业标准、吸引人才、增加透明度和支持长期战略的考虑。
具体来说,开源带来了诸多战略好处。
首先,开源软件通常会更安全,更可靠,而且会由于社区提供的持续反馈和审查而变得更高效。这点非常重要,因为安全正是AI领域的最关键议题之一。
其次,开源软件会时常成为行业标准。而当其他企业基于Meta的技术栈建立标准时,新创新就会更容易融入Meta的产品中。这种微妙的优势,就是巨大的竞争优势。
再次,开源在开发者中非常受欢迎。因为科技工作者们渴望参与到广泛采纳的开放系统中,这就会让Meta吸引更多顶尖人才,从而在新兴技术领域保持领先地位。同时,由于Meta具有独特的数据和产品集成,开源Llama基础设施并不会削弱Meta的核心竞争力。
Meta是大公司中开源决心最大的公司,也是收益最大的公司。尽管训练大模型需要耗费几千亿美元,但自从2023年把业务重心聚焦在开源大模型上以来,Meta的股价已经上涨了大约272%。Meta不仅从开源中收获了名声,也收获了巨大的财务回报。
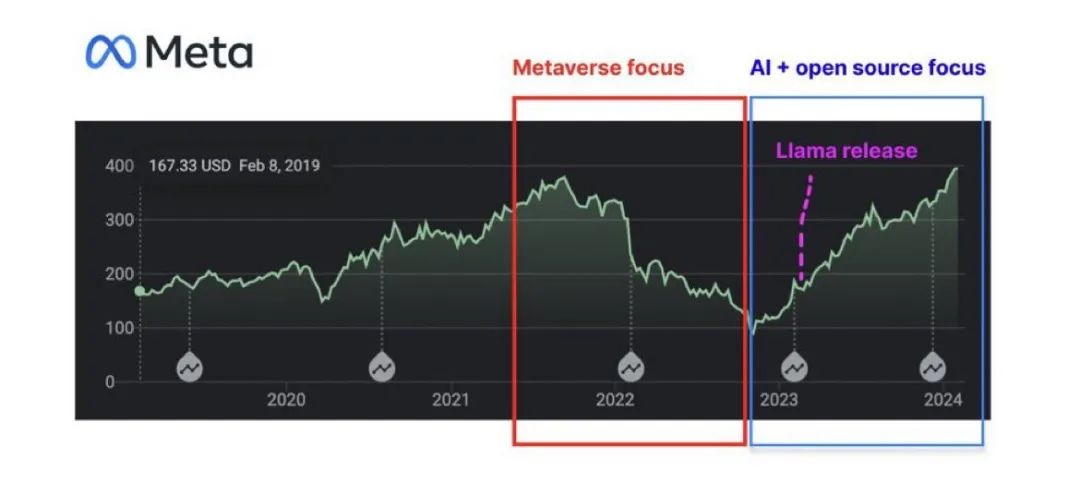
Meta股价走势图,图片来自X
Meta最新发布的Llama 3也是开源模型。除了8B与70B两个较小参数的模型,正在训练中的Llama 3 400B大概率也会是开源模型,而且有望成为第一个超越GPT-4的开源模型。
4.闭源to C,开源to B
不论开源模型还是闭源模型,都需要找到合适的商业模式。
今天大模型行业逐渐形成的一个趋势是,闭源模型更倾向做to C,开源模型更倾向于做to B。
月之暗面创始人杨植麟曾表示,要想做to C领域的Super App,就必须用自研(闭源)模型,因为“只有自研模型才能在用户体验上产生差异化”。
杨植麟认为,开源模型本质上是一种to B的获客工具,或者是在Super App之外的长尾应用,才可能基于开源模型去发挥数据的优势或场景的优势。
但开源模型无法构建产品壁垒。比如,在海外有几百个基于开源扩散模型Stable Diffusion的应用出现,但最后其实没有任何一个跑出来。
其次,无法在开源技术的基础上通过数据的虹吸效应让模型持续地优化,因为开源模型本身是分布式部署,没有一个集中的地方接收数据。
相比之下,开源模型更加适合在to B领域落地。
零一万物开源负责人林旅强告诉「甲子光年」,toB是一单一单直接从客户身上赚钱,提供的不是产品,而是服务和解决方案,而且是一个定制化的服务。做服务是用开源还是闭源?To B的客户肯定首选开源模型,因为不仅能省下授权费用,还有更高的定制空间。
开源模型往往被当成一种最便宜的获得销售线索的手段。厂商可通过几十B或以下规模的开源模型扩大用户群体,以获取销售线索、证明技术实力。如果客户有更多定制化需求,模型厂商也可以提供更多的服务。
同时,开源与闭源并非一个单选题,很多公司都采用了开源与闭源双轮驱动的战略,比如智谱AI、百川智能、零一万物等等。
王小川就认为,从to B角度,开源闭源其实都需要。未来80%的企业会用到开源的大模型,因为闭源没有办法对产品做更好的适配,或者成本特别高,闭源可以给剩下的20%提供服务。二者不是竞争关系,而是在不同产品中互补的关系。”
不论开源还是闭源,大模型商业化面临的根本问题是,如何降低推理成本。只有降低了推理成本,大模型才有可能真正大规模落地。
今天,开源与闭源阵营分别有自己的支持者。但如果参考iOS与安卓操作系统的发展轨迹来看,彼此之间的良性竞争大大促进了产品的迭代与用户体验的升级。这才是开闭源之争最终的价值。
-
李彦宏:未来20年人们对手机的依赖度会越来越低2019-01-02 948
-
苹果手机越来越贵 为什么很多人还坚持要去买iPhone呢?2019-08-18 8318
-
李彦宏:大模型即将改变世界2023-06-02 2039
-
李彦宏:AI原生应用比大模型数量更重要2023-06-26 1133
-
李彦宏极客公园对谈 大模型时代真正的价值在于原生应用2023-12-17 2368
-
李彦宏:开源模型将逐渐滞后,文心大模型提升训练与推理效率2024-04-16 1313
-
李彦宏:DeepSeek启示我们应将顶尖模型开源2025-02-20 1083
全部0条评论

快来发表一下你的评论吧 !
