

主流GPU/TPU集群组网方案深度解析
处理器/DSP
描述
流行的GPU/TPU集群网络组网,包括:NVLink、InfiniBand、ROCE以太网Fabric、DDC网络方案等,深入了解它们之间的连接方式以及如何在LLM训练中发挥作用。为了获得良好的训练性能,GPU网络需要满足以下条件:
1、端到端延迟:由于GPU间通信频繁,降低节点间数据传输的总体延迟有助于缩短整体训练时间。
2、无丢包传输:对于AI训练至关重要,因为任何梯度或中间结果的丢失都会导致训练回退到内存中存储的前一个检查点并重新开始,严重影响训练性能。
3、有效的端到端拥塞控制机制:在树形拓扑中,当多个节点向单个节点传输数据时,瞬态拥塞不可避免。持久性拥塞会增加系统尾延迟。由于GPU之间存在顺序依赖关系,即使一个GPU的梯度更新受到网络延迟影响,也可能导致多个GPU停运。一个慢速链路就足以降低训练性能。
除了以上因素,还需要综合考虑系统的总成本、功耗和冷却成本等方面。在这些前提下,我们将探讨不同的GPU架构设计选择及其优缺点。
一、NVLink 交换系统
用于连接 GPU 服务器中的 8 个 GPU 的 NVLink 交换机也可以用于构建连接 GPU 服务器之间的交换网络。Nvidia 在 2022 年的 Hot Chips 大会上展示了使用 NVswitch 架构连接 32 个节点(或 256 个 GPU)的拓扑结构。由于 NVLink 是专门设计为连接 GPU 的高速点对点链路,所以它具有比传统网络更高的性能和更低的开销。
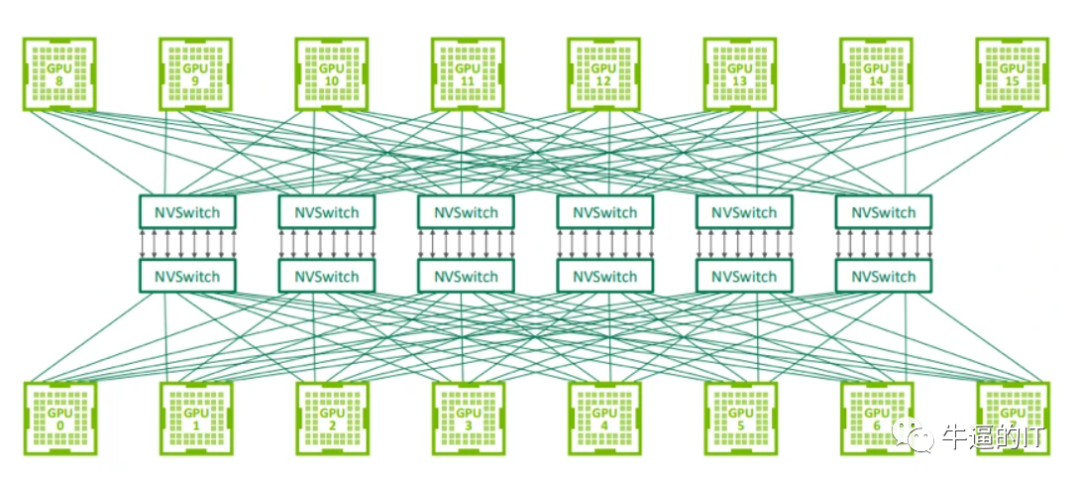
第三代 NVswitch 配备 64 个 NVLink 端口,提供高达 12.8Tbps 的交换容量,同时支持多播和网络内聚合功能。网络内聚合能够在 NVswitches 内部汇集所有工作 GPU 生成的梯度,并将更新后的梯度反馈给 GPU,以便进行下一次迭代。这一特点有助于减少训练迭代过程中 GPU 之间的数据传输量。
据 Nvidia 介绍,在训练 GPT-3 模型时,NVswitch 架构的速度是 InfiniBand 交换网络的 2 倍,展现出了令人瞩目的性能。然而,值得注意的是,这款交换机的带宽相较于高端交换机供应商提供的 51.2Tbps 交换机来说,要少 4 倍。
若尝试使用 NVswitches 构建包含超过 1000 个 GPU 的大规模系统,不仅成本上不可行,还可能受到协议本身的限制,从而无法支持更大规模的系统。此外,Nvidia 不单独销售 NVswitches,这意味着如果数据中心希望通过混合搭配不同供应商的 GPU 来扩展现有集群,他们将无法使用 NVswitches,因为其他供应商的 GPU 不支持这些接口。
二、InfiniBand 网络
InfiniBand(简称IB),这项技术自1999年推出以来,一直作为高速替代方案,有效替代了PCI和PCI-X总线技术,广泛应用于连接服务器、存储和网络。虽然由于经济因素,其最初的宏大设想有所缩减,但InfiniBand仍在高性能计算、人工智能/机器学习集群和数据中心等领域得到了广泛应用。这主要归功于其卓越的速度、低延迟、无丢失传输以及远程直接内存访问(RDMA)功能。
更多InfiniBand技术,请参考文章“英伟达Quantum-2 Infiniband技术A&Q”,“InfiniBand高性能网络设计概述”,“关于InfiniBand和RDMA网络配置实践”,“高性能计算:RoCE v2 vs. InfiniBand网络该怎么选?”,“收藏:InfiniBand与Omni-Path架构浅析”,“InfiniBand网络设计和研究(电子书更新)”,“200G HDR InfiniBand有啥不同?”,“Infiniband架构和技术实战(第二版)”,“关于InfiniBand架构和知识点漫谈”等等。
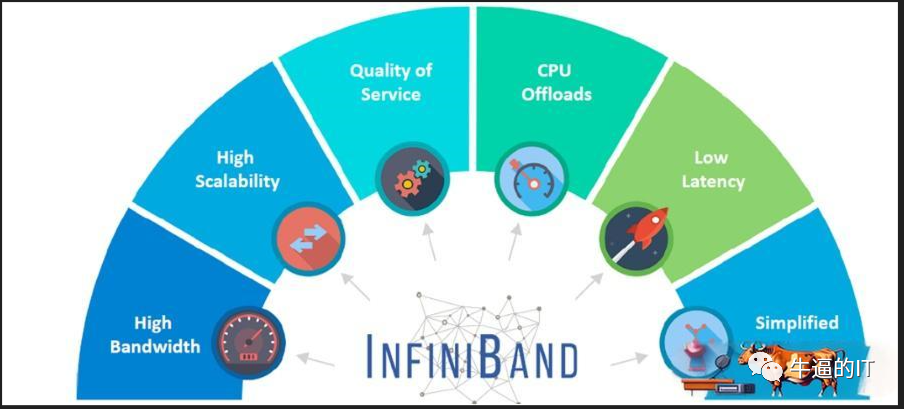
InfiniBand(IB)协议旨在实现高效且轻量化的设计,有效避免了以太网协议中常见的开销。它支持基于通道和基于内存的通信,可以高效处理各种数据传输场景。
通过发/收设备之间的基于信用的流量控制,IB实现了无丢包传输(队列或虚拟通道级别)。这种逐跳的流量控制确保不会由于缓冲区溢出而造成数据丢失。此外,它还支持端点之间的拥塞通知(类似于 TCP/IP 协议栈中的 ECN)。IB提供卓越的服务质量,允许优先处理某些类型的流量以降低延迟和防止丢包。
值得一提的是,所有的IB交换机都支持RDMA协议,这使得数据可以直接从一个GPU的内存传输到另一个GPU的内存,无需CPU操作系统的介入。这种直接传输方式提高了吞吐量,并显著降低了端到端的延迟。
然而,尽管具有诸多优点,InfiniBand交换系统并不像以太网交换系统那样流行。这是因为InfiniBand交换系统在配置、维护和扩展方面相对困难。InfiniBand的控制平面通常通过一个单一的子网管理器进行集中控制。虽然在小型集群中可以运行良好,但对于拥有32K或更多GPU的网络,其扩展性可能会成为一项挑战。此外,IB网络还需要专门的硬件,如主机通道适配器和InfiniBand电缆,这使得其扩展成本比以太网网络更高。
目前,Nvidia是唯一一家提供高端IB交换机供HPC和AI GPU集群使用的供应商。例如,OpenAI在Microsoft Azure云中使用了10,000个Nvidia A100 GPU和IB交换网络来训练他们的GPT-3模型。而Meta最近构建了一个包含16K GPU的集群,该集群使用Nvidia A100 GPU服务器和Quantum-2 IB交换机(英伟达GTC 2021大会上发布全新的InfiniBand网络平台,具有25.6Tbps的交换容量和400Gbps端口)。这个集群被用于训练他们的生成式人工智能模型,包括LLaMA。值得注意的是,当连接10,000个以上的GPU时,服务器内部GPU之间的切换是通过服务器内的NVswitches完成的,而IB/以太网网络则负责将服务器连接在一起。
为了应对更大参数量的训练需求,超大规模云服务提供商正在寻求构建具有32K甚至64K GPU的GPU集群。在这种规模上,从经济角度来看,使用以太网网络可能更有意义。这是因为以太网已经在许多硅/系统和光模块供应商中形成了强大的生态系统,并且以开放标准为目标,实现了供应商之间的互操作性。
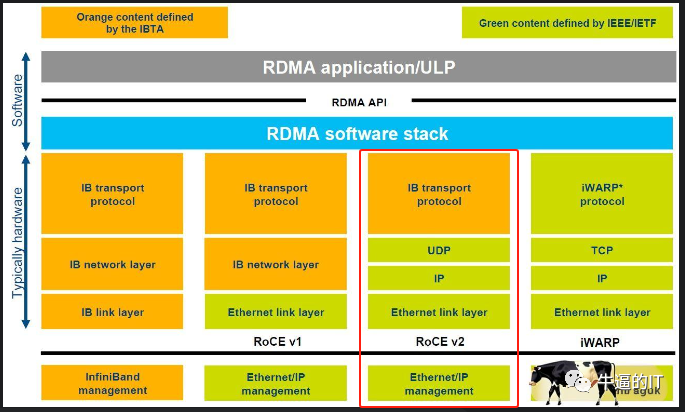
三、ROCE无损以太网
以太网的应用广泛,从数据中心到骨干网络都有其身影,速度范围从1Gbps到800Gbps,未来甚至有望达到1.6Tbps。与Infiniband相比,以太网在互连端口速度和总交换容量上更胜一筹。此外,以太网交换机的价格相对较低,每单位带宽的成本更具竞争力,这主要归功于高端网络芯片供应商之间的激烈竞争,推动了厂商将更多带宽集成到ASIC中,从而降低了每千兆位的成本。
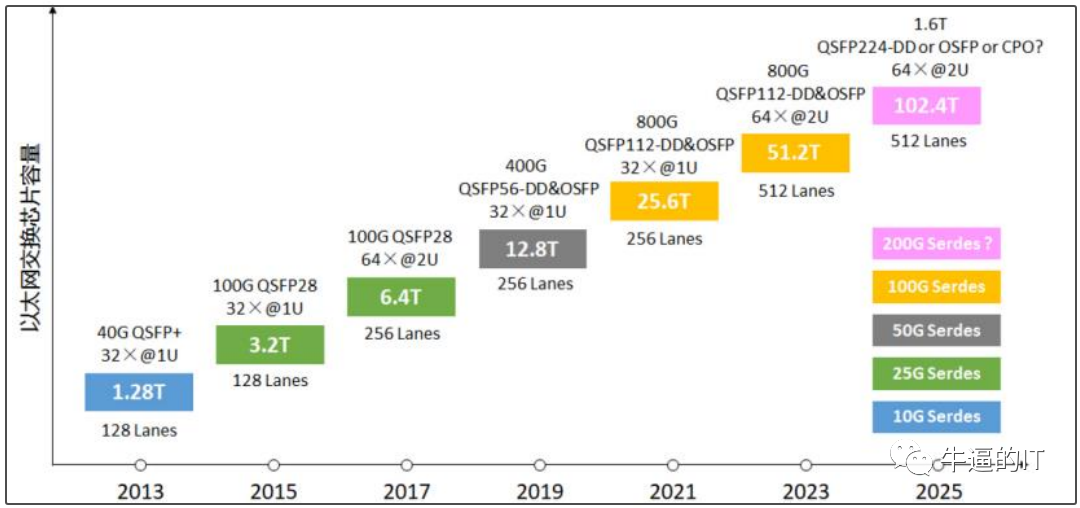
高端以太网交换机ASIC的主要供应商可以提供高达51.2Tbps的交换容量,配备800Gbps端口,其性能是Quantum-2((英伟达GTC 2021大会上发布全新的InfiniBand网络平台,具有25.6Tbps的交换容量和400Gbps端口))的两倍。这意味着,如果交换机的吞吐量翻倍,构建GPU网络所需的交换机数量可以减少一半。
以太网还能提供无丢包传输服务,通过优先流量控制(PFC)实现。PFC支持8个服务类别,每个类别都可以进行流量控制,其中一些类别可以指定为无丢包类别。在处理和通过交换机时,无丢包流量的优先级高于有丢包流量。在发生网络拥塞时,交换机或网卡可以通过流量控制来管理上游设备,而不是简单地丢弃数据包。
更多ROCE技术细节,请参考文章“RoCE、IB和TCP等网络知识及差异对比”,“关于RoCE技术3种实现及应用”,“高性能计算:RoCE技术分析及应用”,“高性能计算:RoCE v2 vs. InfiniBand网络该怎么选?”,“RoCE技术在HPC中的应用分析”,“面向数据中心无损网络技术(IP、RDMA、IB、RoCE、AI Fabric)”,“超算网络演变:从TCP到RDMA,从IB到RoCE”等等。
此外,以太网还支持RDMA(远程直接内存访问)通过RoCEv2(RDMA over Converged Ethernet)实现,其中RDMA帧被封装在IP/UDP内。当RoCEv2数据包到达GPU服务器中的网络适配器(NIC)时,NIC可以直接将RDMA数据传输到GPU的内存中,无需CPU介入。同时,可以部署如DCQCN等强大的端到端拥塞控制方案,以降低RDMA的端到端拥塞和丢包。
在负载均衡方面,路由协议如BGP使用等价路径多路径路由(ECMP)来在多条具有相等“代价”的路径上分发数据包。当数据包到达具有多条到达目标的等价路径的交换机时,交换机使用哈希函数来决定数据包的发送路径。然而,哈希不总是完美的,可能会导致某些链路负载不均,造成网络拥塞。
为了解决这个问题,可以采用一些策略,例如预留轻微过量的带宽,或者实现自适应负载均衡,当某条路径拥塞时,交换机可以将新流的数据包路由到其他端口。许多交换机已经支持此功能。此外,RoCEv2的数据包级负载均衡可以将数据包均匀地分散在所有可用链路上,以保持链路平衡。但这可能导致数据包无序到达目的地,需要网卡支持在RoCE传输层上处理这些无序数据,确保GPU接收到的数据是有序的。这需要网卡和以太网交换机的额外硬件支持。
另外部分厂商的ROCE以太网交换机,也可以在交换机内部聚合来自GPU的梯度,有助于减少训练过程中的GPU间流量,如Nvidia的高端以太网交换机等。
总的来说,高端太网交换机和网卡具备强大的拥塞控制、负载均衡功能和RDMA支持,可以扩展到比IB交换机更大的设计。一些云服务提供商和大规模集群的公司已经开始使用基于以太网的GPU网络,以连接超过32K的GPU。
四、DDC全调度网络
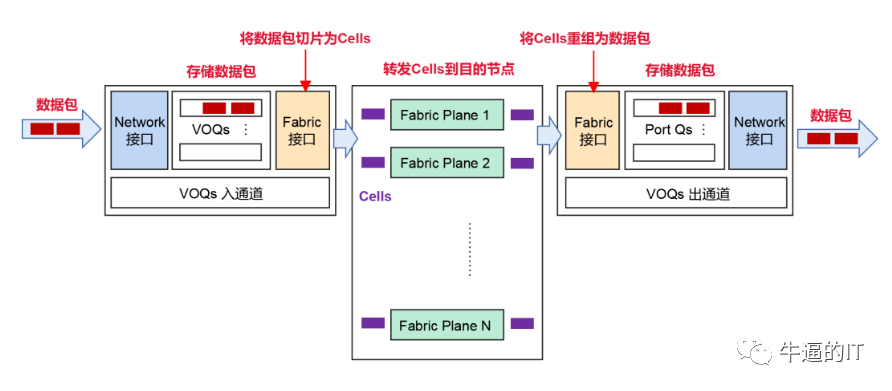
近期,数家交换机/路由器芯片供应商宣布推出支持全调度Fabric或AI Fabric的芯片。这种全调度网络实际上已经应用于许多模块化机箱设计中十多年,其中包括Juniper的PTX系列路由器,它们采用了虚拟出口队列(VOQ)网络。
在VOQ架构中,数据包仅在入口叶子交换机中进行一次缓冲,存放在与最终出口叶子交换机/WAN端口/输出队列相对应的队列中。这些队列在入口交换机中被称为虚拟输出队列(Virtual Output Queues, VOQs)。因此,每个入口叶子交换机为整个系统中的每个输出队列提供缓冲空间。该缓冲区的大小通常足以容纳每个VOQ在40-70微秒内遇到拥塞时的数据包。当VOQ的数据量较少时,它保留在片上缓冲区中;当队列开始增长时,数据会转移到外部存储器中的深度缓冲区。
当入口叶子交换机上的某个VOQ累积了多个数据包后,它会向出口交换机发送请求,要求在网络中传输这些数据包。这些请求通过网络传送到出口叶子交换机。
出口叶子交换机中的调度器根据严格的调度层次以及其浅输出缓冲区中的可用空间来批准这些请求。这些批准的速率受到限制,以避免过度订阅交换机链路(超出队列缓存接受范围)。
一旦批准到达入口叶子交换机,它就会将所收到批准的一组数据包发送到出口,并通过所有可用的上行链路进行传输。
发送到特定VOQ的数据包可以均匀地分散在所有可用的输出链路上,以实现完美的负载均衡。这可能导致数据包的重新排序。然而,出口交换机具有逻辑功能,可以将这些数据包按顺序重新排列,然后将它们传输到GPU节点。
由于出口调度器在数据进入交换机之前就对已批准的数据进行了控制,从而避免了链路带宽的超额使用,因此消除了以太网数据面中99%由incast引起的拥塞问题(当多个端口尝试向单个输出端口发送流量时),并且完全消除了头阻塞(HOL blocking)。需要指出的是,在这种架构中,数据(包括请求和批准)仍然是通过以太网进行传输的。
头阻塞(HOL blocking)是指在网络传输中,一列数据包中的第一个数据包如果遇到阻碍,会导致后面所有的数据包也被阻塞,无法继续传输,即使后面的数据包的目标输出端口是空闲的。这种现象会严重影响网络的传输效率和性能。
一些架构,如Juniper的Express和Broadcom的Jericho系列,通过其专有的分段化(cellified)数据面实现了虚拟输出队列(VOQ)。
在这种方法中,叶子交换机将数据包分割为固定大小的分段,并在所有可用的输出链路上均匀分布它们。与在数据包级别进行均匀分布相比,这可以提高链路利用率,因为混合使用大型和小型数据包很难充分利用所有链路。通过分段转发,我们还避免了输出链路上的另一个存储/转发延迟(出口以太网接口)。在分段数据面中,用于转发分段的spine交换机被定制交换机所替代,这些定制交换机能够高效地进行分段转发。这些分段数据面交换机在功耗和延迟方面优于以太网交换机,因为它们不需要支持L2交换的开销。因此,基于分段的数据面不仅可以提高链路利用率,还可以减少VOQ数据面的总体延迟。
VOQ架构确实存在一些局限性:
每个叶子交换机的入口端应具有合理的缓冲区,以供系统中所有VOQ在拥塞期间缓冲数据包。缓冲区大小与GPU数量及每个GPU的优先级队列数量成正比。GPU规模较大直接导致更大的入口缓冲区需求。
出口队列缓冲区应具备足够的空间,以覆盖通过数据面的往返延迟,以防在请求-批准握手期间这些缓冲区耗尽。在较大的GPU集群中,使用3级数据面时,由于光缆延迟和额外交换机的存在,此往返延迟可能会增加。如果出口队列缓冲区未适当调整以适应增加的往返延迟,输出链路将无法达到100%的利用率,从而降低系统的性能。
尽管VOQ系统通过出口调度减少了由于头阻塞引起的尾延迟,但由于入口叶交换机必须在传输数据包之前进行请求-批准握手,因此一个数据包的最小延迟会增加额外的往返延迟。
尽管存在这些限制,全调度的VOQ(fabric)在减少尾延迟方面的性能要明显优于典型的以太网流量。如果通过增加缓冲区而使链路利用率提高到90%以上,则在GPU规模扩大时带来的额外开销可能是值得投资的。
此外,供应商锁定是VOQ(fabric)面临的一个问题。因为每个供应商都使用自己的专有协议,所以在同一fabric中混合使用和匹配交换机变得非常困难。
总结:主流GPU集群组网技术应用情况
NVLink交换系统虽然为GPU间通信提供了有效解决方案,但其支持的GPU规模相对有限,主要应用于服务器内部的GPU通信以及小规模跨服务器节点间的数据传输。
InfiniBand网络作为一种原生的RDMA网络,在无拥塞和低延迟环境下表现卓越。然而,由于其架构相对封闭且成本较高,它更适用于中小规模且对有线连接有需求的客户群体。
ROCE无损以太网则凭借其依托成熟的以太网生态、最低的组网成本以及最快的带宽迭代速度,在中大型训练GPU集群的场景中展现出更高的适用性。
至于DDC全调度网络,它结合了信元交换和虚拟输出队列(VOQ)技术,因此在解决以太网拥塞问题方面有着显著的优势。作为一种新兴技术,目前业界各家仍处于研究阶段,以评估其长期潜力和应用前景。
更多GPU技术细节,请参考文章“最新版:GPU显卡天梯图(2023年11月)”,“全球GPU呈现“一超一强”竞争格局”,“2023年GPU显卡词条报告”,“HBM崛起:从GPU到CPU”,“英伟达GPU龙头稳固,国内逐步追赶(2023)”,“英伟达L40S GPU架构及A100、H100对比”,“AI芯片第一极:GPU性能、技术全面分析”,“主流国产GPU产品及规格概述(2023)”,“新型GPU云桌面发展白皮书”,“国内外GPU现状:海外龙头领跑,国产差距明显”,“GPGPU流式多处理器架构及原理”等等。
审核编辑:黄飞
- 相关推荐
- 热点推荐
- gpu
- 服务器
- InfiniBand
- TPU
- LLM
-
一文理清CPU、GPU和TPU的关系2018-09-04 5632
-
GPU集群组网技术详解2023-12-25 7968
-
微功率低功耗MESH组网模块在水表与燃气表无线抄表中的应用2015-05-06 7683
-
LoRa扩频低功耗MESH组网路由模块的应用2015-05-08 10954
-
从CPU、GPU再到TPU,Google的AI芯片是如何一步步进化过来的?2017-03-15 3683
-
TPU透明副牌.TPU副牌料.TPU抽粒厂.TPU塑胶副牌.TPU再生料.TPU低温料2021-11-21 885
-
GPU八大主流的应用场景2021-12-07 6293
-
CPU,GPU,TPU,NPU都是什么2021-12-15 3261
-
一文了解CPU、GPU和TPU的区别2018-09-06 29678
-
TPU和GPU的带宽模型2018-10-21 5386
-
CPU和GPU与TPU是如何工作的到底有什么区别2020-01-20 7533
-
CPU、GPU、TPU、NPU等的讲解2021-01-05 12687
-
无人机集群通信组网系统—无人机自组网2022-03-02 4466
-
GPU/TPU集群网络组网间的连接方式2024-04-16 2239
-
GPU架构深度解析2025-05-30 2226
全部0条评论

快来发表一下你的评论吧 !
