

探索ChatGPT模型的人工智能语言模型
人工智能
描述
作者:陈珍 伍雅乐
背景
2022年11月30日,OpenAI发布了一款具有多种能力的通用大模型ChatGPT,开启了人工智能新时代的序幕。
2023年7月,OpenAI发布公告称给ChatGPT加了一个名为Custom instructions的新功能,使机器人更具有个性化特色的同时,更好地贴近使用者的需求。同时,安卓版ChatGPT也于7月25日正式上线。
2023年11月,OpenAI前总裁兼董事长Greg Brockman宣布,所有用户均可使用其语音功能ChatGPT Voice。2024年4月1日,OpenAI宣布,将允许用户直接使用ChatGPT,而无需注册该项服务。
ChatGPT:我是什么?
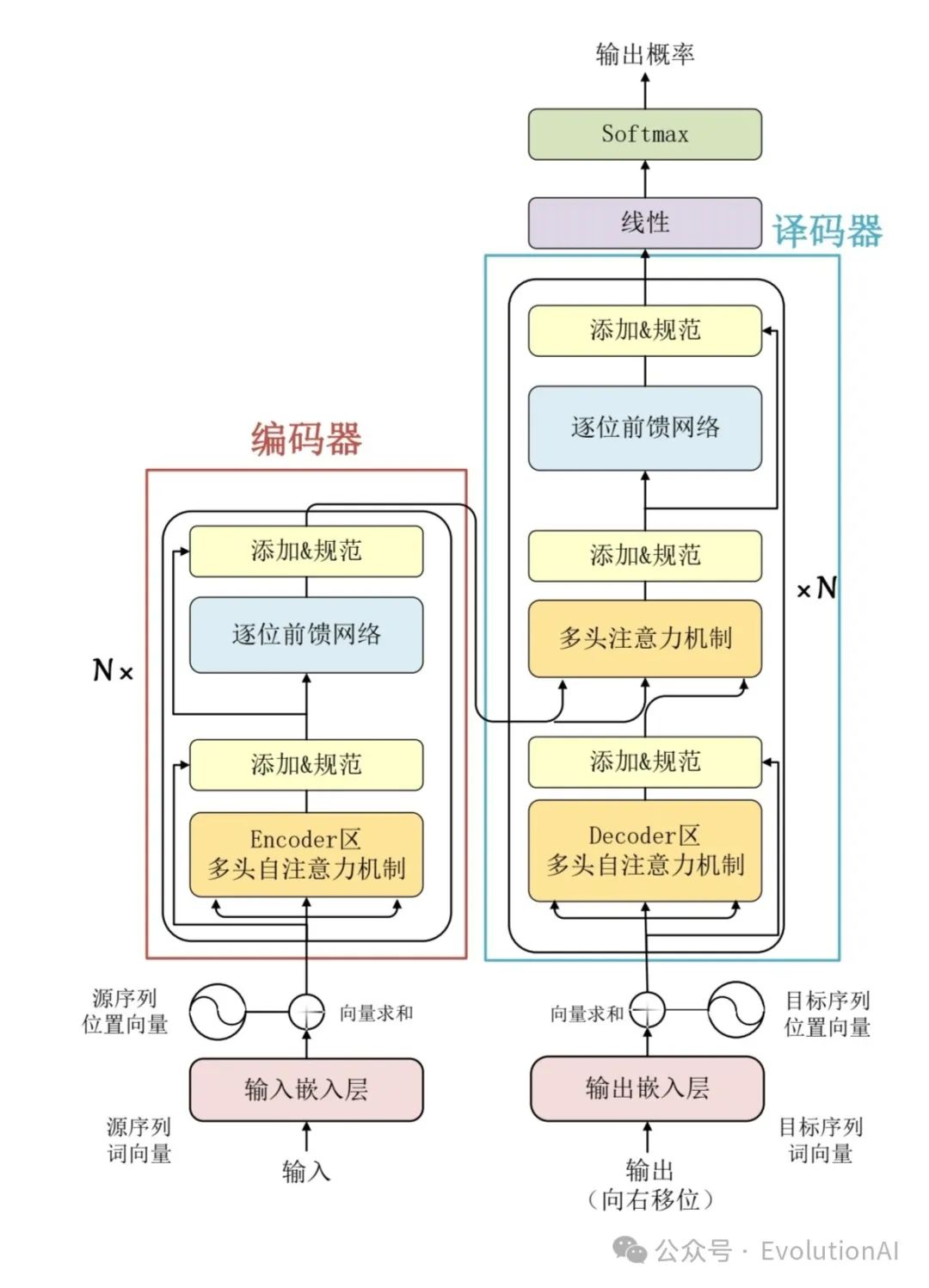
ChatGPT是一款由OpenAI公司开发的人工智能技术驱动的自然语言处理工具。它建立在先进的深度学习模型之上,特别是Transformer模型,采用了自注意力机制来捕捉输入文本中的长距离依赖关系,并通过多层编码器-解码器结构来实现输入到输出的映射,使得模型能够逐步捕捉和理解输入序列中的复杂关系,并生成更加准确和自然的回复。ChatGPT不仅能够回答各种问题,还能进还能进行流畅的对话交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码等任务。
多层编码器-解码器结构:Transformer模型的核心组件,它模拟了大脑理解自然语言的过程。
编码器(Encoder):将输入序列(如用户的提问或对话内容)映射到一组中间表示,这个过程可以理解为将语言转化为大脑能够理解和记忆的内容。在ChatGPT中,编码器由多层的注意力模块和前馈神经网络模块组成,其中自注意力模块能够学习序列中不同位置之间的依赖关系。这种机制使得模型能够有效地处理长距离依赖关系,从而更好地理解输入的上下文信息。
解码器(Decoder):将这些中间表示转换为目标序列,即生成连贯、合理的回复。在ChatGPT中,解码器同样由多层的注意力模块和前馈神经网络模块组成。解码器在生成回复时,会考虑之前生成的内容以及编码器提供的上下文信息,从而模拟人类的对话方式。
Transformer模型:
ChatGPT:我与GPT系列模型是一样吗?
ChatGPT与GPT系列模型是不一样的ChatGPT专门针对对话式交互任务进行了优化,可以生成具有上下文感知和连贯性的自然语言回复。与其它GPT系列模型相比:
1.最大的区别ChatGPT是通过对话数据进行预训练,而不仅仅是通过单一的句子进行预训练,这使得ChatGPT能够更好地理解对话的上下文,并进行连贯的回复。
2.ChatGPT还使用了一种叫做Dialog Response Ranking(DRR)的训练方法,该方法通过给定正样本对话和负样本对话,强调了正确回答的重要性,提高了模型的表现。
快看工作原理和代码!
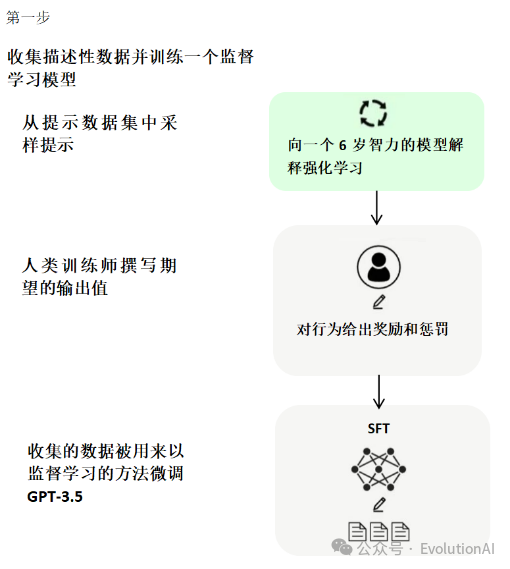
ChatGPT的核心方法就是引入“人工标注数据+强化学习”来不断微调预训练语言模型。训练ChatGPT主要分为以下三个阶段:
第一阶段,使用标准数据(提示和对应的回答)进行微调,也就是有监督微调(Supervised Fine-Tuning, SFT)。为了让ChatGPT能够理解用户提出的问题中所包含的意图,首先需要从用户提交的问题中随机抽取一部分,由专业的标注人员给出相应的高质量答案,然后用这些人工标注好的<提示, 答案> 数据来微调 GPT-3模型。微调技术是ChatGPT实现对话生成的关键技术之一,它可以通过在有标注数据上进行有监督训练,从而使模型适应特定任务和场景。微调技术通常采用基于梯度下降的优化算法,不断地调整模型的权重和偏置,以最小化损失函数,从而提高模型的表现能力。
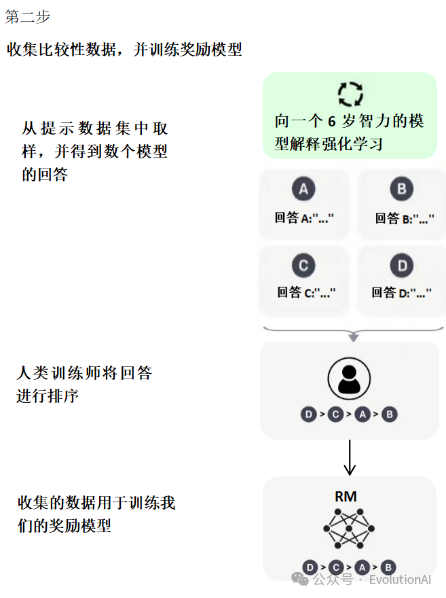
第二阶段,训练奖励模型(Reward Model, RM)。给定提示(大约3万左右),使用微调后的模型生成多个回答,人工对多个答案进行排序,然后使用成对学习(pair-wise learning)来训练奖励模型,也就是学习人工标注的顺序(人工对模型输出的多个答案按优劣进行排序)。目的是用人工标注数据来训练奖励模型(Reward Model, RM)。
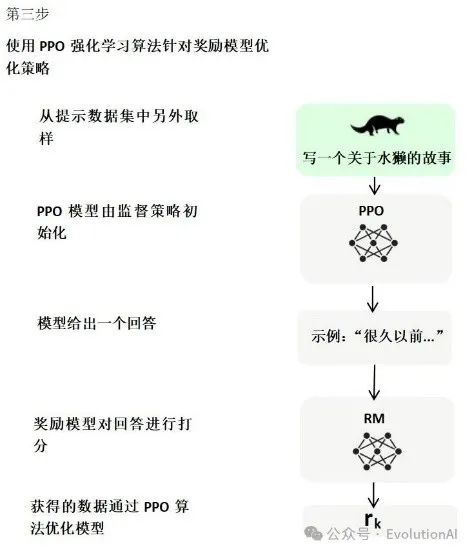
第三阶段,使用强化学习,微调预训练语言模型。利用奖励模型的打分结果来更新模型参数,从而使模型更加符合用户的期望。
代码:
import torchimport torch.nn.functional as Ffrom transformers import GPT2LMHeadModel, GPT2Tokenize
# 加载预训练模型和分词器:使用 GPT2LMHeadModel.from_pretrained() 和 GPT2Tokenizer.from_pretrained() 函数加载预训练的 GPT 模型和分词器 model=GPT2LMHeadModel.from_pretrained('gpt2')
# 加载预训练模型
tokenizer=GPT2Tokenizer.from_pretrained('gpt2')
# 加载分词器# 定义对话生成函数:使用模型和分词器生成对话文本。输入参数包括模型 model、分词器 tokenizer、对话前缀 prompt、生成文本的最大长度max_length 和温度 temperature。首先使用分词器将对话前缀转换为输入张量 input_ids,并将其移动到 GPU 上。然后使用模型的 generate() 方法生成文本,并将输出张量转换为文本返回
def generate(model, tokenizer, prompt, max_length=30, temperature=1.0):
# 将对话前缀转换为输入张量
input_ids= tokenizer.encode(prompt, add_special_tokens=False, return_tensors='pt')input_ids = input_ids.cuda()
# 将输入张量移动到 GPU 上
# 使用模型生成文本
output=model.generate(input_ids,max_length=max_length,temperature=temperature)
# 将输出张量转换为文本并返回
return tokenizer.decode(output[0],skip_special_tokens=True)
# 微调对话数据:首先定义对话数据 conversation,然后将其拼接成一个字符串 text,其中奇数句子末尾添加 eos 标记。然后使用分词器将对话数据转换为输入张量 input_ids,并将其移动到 GPU 上。接着使用模型计算损失并反向传播,以微调模型。我们使用 model.train() 将模型设置为训练模式,并使用 optimizer.step() 和 optimizer.zero_grad() 分别执行参数更新和梯度清零操作
conversation = [
"你好,我是小明。",
"你好,我是小红。",
"你喜欢什么运动?",
"我喜欢打篮球。",
"你呢?",
"我喜欢跑步。"]
text = "
"for i, sentence in enumerate(conversation): text += sentence
if i % 2 == 0: text +=tokenizer.eos_token # 在奇数句子末尾添加 eos 标记
model.train()
# 设置模型为训练模式
for epoch in range(3):
# 将对话数据转换为输入张量
input_ids = tokenizer.encode(text,add_special_tokens=True,return_tensors='pt')
input_ids = input_ids.cuda()
# 将输入张量移动到 GPU 上
# 使用模型计算损失并反向传播
output = model(input_ids, labels=input_ids) loss =output.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 测试对话生成函数:使用 generate() 函数生成对话文本,并将其打印出来
prompt = "你喜欢什么运动?"
response = generate(model, tokenizer, prompt, max_length=20, temperature=0.7)print(response)
GhatGPT:我的优点太多啦
1.ChatGPT的模型架构主要基于Transformer结构,与传统的基于RNN(循环神经网络)的结构不同。这种基于Transformer的结构能够更好地捕捉文本中的长距离依赖关系,从而提高了模型的性能。具体来说,Transformer结构通过使用自注意力机制(Self-Attention Mechanism)来计算输入序列中每个位置的表示,这使得模型能够更好地理解文本的上下文信息。
2.ChatGPT还采用了生成式AI技术,可以生成连贯且符合语法的文本。这种技术使得ChatGPT能够为人们提供各种问答和文本生成服务,如智能客服、智能助手等。同时,ChatGPT还具备人机交互的能力,可以与用户进行交互,根据用户的输入和反馈生成个性化的回答和回复。
3.ChatGPT模型在大量的文本数据上进行预训练,这使得模型能够更好地学习到语言的特征和规律。在训练过程中,ChatGPT使用了大量的语料库,包括网页文本、书籍、文章等,从而保证了模型的通用性和泛化能力。
GhatGPT:我也有缺点
1.在生成文本时可能会出现一些不符合实际或常识的错误,或者在某些情况下无法准确地理解用户的意图。
2.由于ChatGPT是在大量的文本数据上进行预训练的,因此其可能会包含一些不适当或冒犯性的内容。因此,在使用ChatGPT时需要注意其生成的文本内容是否合适和准确。
3.中文训练语料库比英文训练语料库要少,所以中文知识也少。
4.无法给出这个信息提供的来源,这就跟百度和Google有本质的不同,在搜索引擎中,我们知道文章是谁写的,所以ChatGPT只能使用它训练的知识。
5.无法获取最新的数据,只能获取训练时间节点的数据来提供知识。
使用注意事项
简单的说,其实就是一句话,提出好的问题,对于ChatGPT来说,问题比答案更重要,因为GPT模型本身就是基于提示(Prompt)来起作用的,它的回答,取决于你给他的提示的内容和质量,那么怎么才能提出好的问题呢?
1.增加细节(增加提示的细节和要求)。
2.不断追问(基于ChatGPT生成的内容不断追问)。
3.心存疑问(对于ChatGPT的回答不能盲目相信)。
ChatGPT的未来与应用
ChatGPT的发展趋势:更加智能化、多模态交互、知识图谱的融合、个性化定制、隐私和安全性。
ChatGPT的挑战(在多模态交互上):数据获取和标注、跨模态理解和融合、计算资源和效率、隐私和安全性。
ChatGPT的应用:客户服务与智能助手、社交媒体与聊天应用、在线教育与培训、金融与投资.医疗健康、内容创作与生成、信息检索与问答系统、虚拟角色和游戏NPC等领域。随着技术的不断发展,ChatGPT在更多领域的应用也将不断拓展。
审核编辑:黄飞
-
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》2024-04-30 1335
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 890
-
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》2.02024-05-07 1522
-
【《大语言模型应用指南》阅读体验】+ 俯瞰全书2024-07-21 745
-
最新人工智能硬件培训AI 基础入门学习课程参考2025版(大模型篇)2025-07-04 2502
-
路径规划用到的人工智能技术2021-07-20 2429
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
ChatGPT系统开发AI人功智能方案2023-05-18 23981
-
AI 人工智能的未来在哪?2023-06-27 4408
-
人工智能大模型、应用场景、应用部署教程超详细资料2023-11-13 18998
-
谷歌推出1.6万亿参数的人工智能语言模型,打破GPT-3记录2021-01-18 2990
-
盘古大模型和ChatGPT42023-08-31 6572
-
大语言模型概述2023-12-21 3447
-
大模型LLM与ChatGPT的技术原理2024-07-10 19477
-
ChatGPT 与人工智能的未来发展2024-10-25 3254
全部0条评论

快来发表一下你的评论吧 !
