

一文深度梳理AI算力芯片
描述
几十年前,CPU 作为通用处理器几乎处理所有计算任务,那个时代的显卡有助于加快应用程序中图形的绘制速度。但在今天ChatGPT引爆的人工智能iPhone时刻,GPU成为了整个行业最具主导地位的芯片之一。大家都在抢购GPU,龙头企业英伟达也因此赚的盆满钵满。
在此前的文章中我们介绍了AI算力的主要载体数据中心IDC的商业模式和组成部分,并进一步走进服务器这个数据中心中主要负责计算的硬件。服务器中有处理器、内存、硬盘等零部件,其中最核心的负责计算的当属处理器,也就是芯片。因此,今天我们继续梳理AI算力芯片,看看为什么在当今AI时代GPU占据了主导地位以及我国目前的发展情况与相关企业。
产业链
从产业链说起,首先来看芯片在产业链中扮演的角色。这里从两方面说,站在算力产业链角度,芯片属于上游产品,正如我们在《AI服务器革命:硬件进化驱动人工智能新纪元》一文中提到,芯片与其它硬件组成服务器,也就是产业链中游,服务器又与其它设备共同组成下游的数据中心。
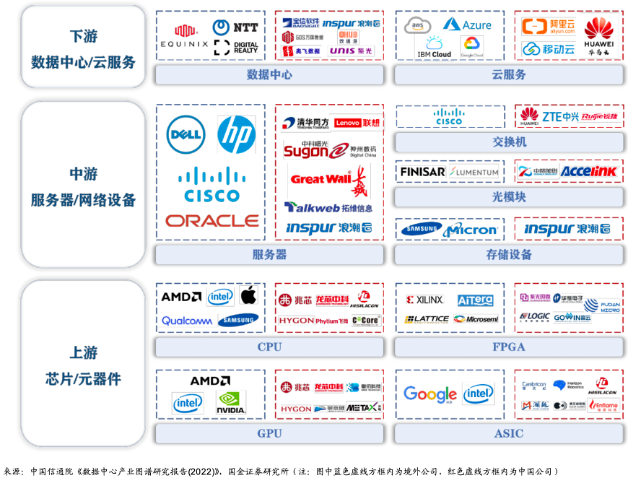
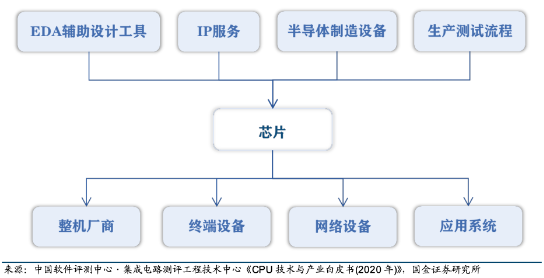
如果站在半导体产业链的角度看,那么芯片属于中游。它的上游包括支撑集成电路设计和制造的 EDA 辅助设计工具和 IP 服务,半导体制造设备、芯片生产测试流程。产业链下游包括各类整机厂商、终端设备、网络设备和应用系统等,其中最重要的是服务器、桌面和嵌入式系统等硬件设备厂商。
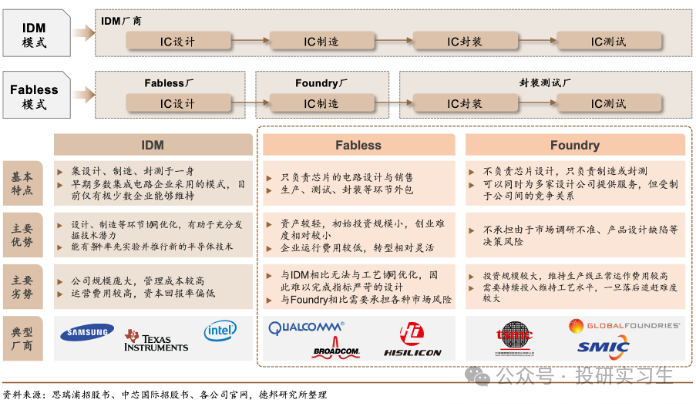
由于全球化的不断深入,半导体产业发生了多次区域转移,分工不断细化。可以将半导体的生产分为四个主要步骤:设计、制造、封装、测试。在传统的垂直整合制造商模式(IDM,即自己完成设计、制造、封装测试等所有环节)基础上诞生了著名的Fabless+Foundry模式,Fabless厂商是以美国为主的负责设计,而Foundry则是以中国台湾为主的负责制造的厂商。两种模式各有利弊,不过这属于半导体产业链范畴的讨论,我们在此不做赘述。
CPU、GPU、ASIC、FPGA
半导体产品可以分为集成电路(芯片)、分立器件、光电器件和传感器,其中芯片进一步分为数字芯片和模拟芯片,数字芯片下还有逻辑芯片、微处理器和存储芯片三类。我们所说到的算力芯片或AI芯片实际上指的都是逻辑芯片,广义上可以是所有采用逻辑门的大规模集成电路,包括以 CPU、GPU 为代表的通用计算芯片、专用芯片(ASIC)和 FPGA,狭义上,AI芯片指针对大量数据进行训练和推理设计的芯片。

CPU
CPU是中央处理器(Central Processing Unit),是计算机的运算核心和控制核心。CPU包括运算器(算术逻辑单元ALU、累加寄存器、 数据缓冲寄存器、状态条件寄存器)、控制器(指令寄存器IR、程序计数器PC、地址寄存器、 指令译码器ID、时序、总线、中断逻辑控制)、高速缓冲存储器(Cache)、内部数据总线 、控制总线、状态总线及输入/输出接口等模块。
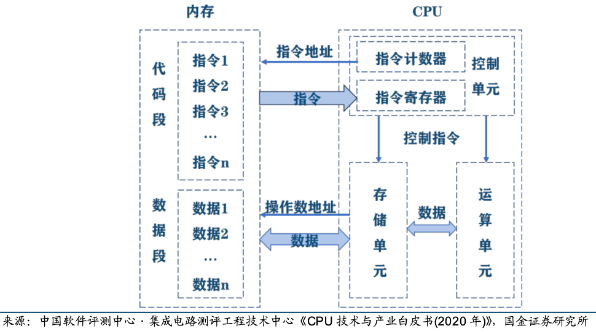
CPU 的主要功能是解释计算机指令以及处理计算机软件中的数据,其运行程序时主要包括一下5个步骤:1)指令寄存器(IR)从存储器或高速缓冲存储器中获取指令;2)指令译码器(ID)对指令进行译码,并将指令分解成一系列简单的微操作;3)译码后的微操作通过控制单元发送给CPU内的运算器执行数学运算和逻辑决策,;4)执行某些指令时需要读取或写入数据到主存储器,地址寄存器用于确定存储器中数据的位置,而数据经过内部总线传输;5)指令执行完成后,结果会被写回到CPU的寄存器或存储器中,供后续指令使用。
我们可以将这个流程类比自己做数学题时的场景,从最开始的读题(获取指令)、审题(指令译码)到一步一步计算答案(执行运算),再将答案写在草稿纸上(存储结果)用于下一小问。对于CPU来说这整个过程是一个连续循环,称为指令周期,包括获取指令、译码、执行、访问存储器和写回结果的步骤。人们用主频来衡量以上一个指令周期被执行的速度(CPU性能),主频是指CPU内部时钟的频率,通常以赫兹(Hz)为单位,1赫兹等于每秒钟一个周期。此外,FLOPS(每秒执行多少浮点运算)也被用于衡量CPU性能。
在CPU的发展历史中,为了进一步提升它的运算能力人们提出了多线程(Multithreading)和多核(Multi-core)的设计方法。多线程指的是程序可以同时执行多个任务,也就是电脑可以同时做不同的事。例如,一个线程可以处理用户输入,同时另一个线程可以执行后台计算,还有一个线程可以处理网络通信。即使一个线程被阻塞,其他线程仍然可以继续工作,从而提高了整体的效率和程序的响应性。多核则是增加CPU内的处理单元,使CPU可以并行处理多个指令流。
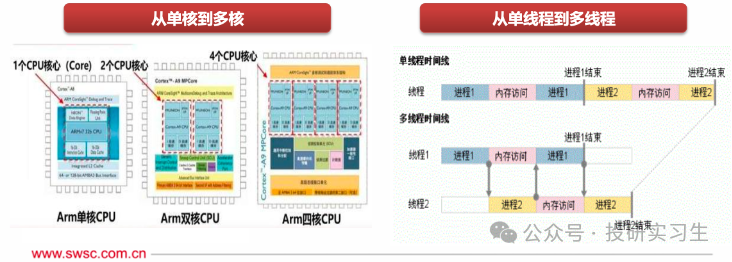
可以按指令集和应用领域对CPU进行分门别类,指令集是 CPU 所执行指令的二进制编码方法,是软件和硬件的接口规范。按照指令集可分为 CISC复杂指令集和 RISC精简指令集两大类,在上一篇文章中做过详细介绍,这里不再赘述。CPU 按照下游应用领域还可分为通用微处理器(MPU, Micro Processor Unit)和微控制器(MCU, Micro Controller Unit),MPU便是我们熟悉的应用于服务器、桌面(台式机/笔记本)、超级计算机等中的CPU。MCU是用于控制类应用的低性能、低功耗CPU。MCU的主频一般低于 100MHz,一般是用在智能制造、工业控制、智能家居、遥控器、汽车电子、机器手臂的控制等。

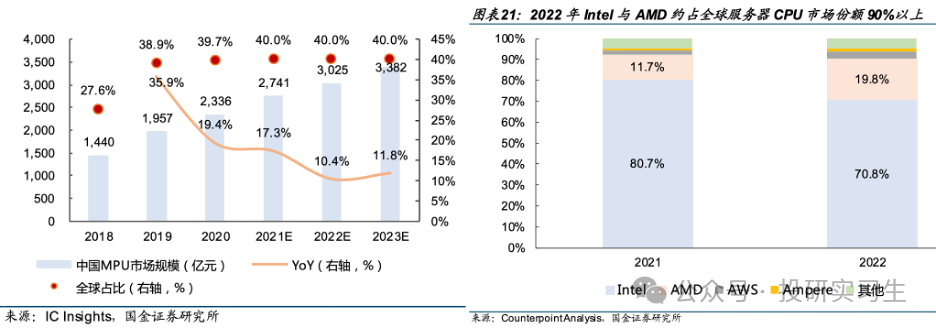
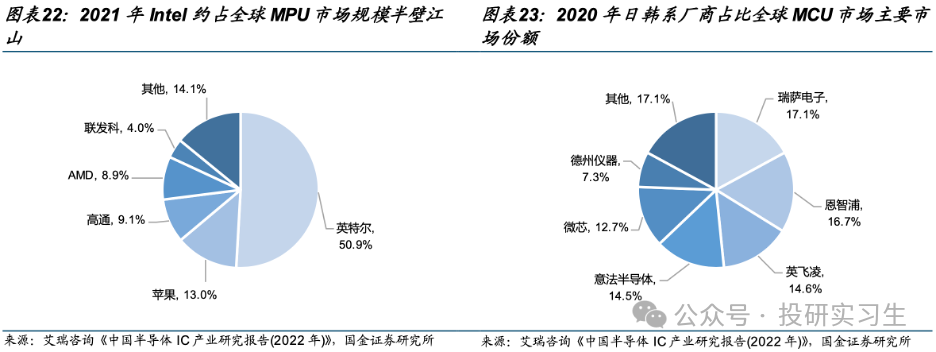
从竞争格局上看,英特尔和AMD占据了大部分市场份额,其中英特尔作为CPU的缔造者拥有绝对主导地位。从服务器CPU角度看,2022年英特尔与AMD合计占到全球90%的市场份额,不过近两年AMD不断抢占英特尔份额。从MPU整体上看,英特尔占据半壁江山,移动设备端苹果和高通分别拥有13%和9%的份额。从MCU上看则是日韩系厂商份额较多。
GPU
作为通用处理器,以前几乎所有的计算任务都由CPU处理,不过到了八十年代末九十年代初,越来越多的图形渲染处理需求催生了GPU的诞生,黄仁勋正是在这一时期创立的英伟达,专注于GPU的研发与制造。
GPU是图形处理器(Graphic Processing Unit),又称为显示芯片(显卡),最初是作为专用处理器来辅助CPU进行图像和图形相关运算工作的。从结构上来说,CPU的设计是低延迟的串行计算模式,拥有少数强大的ALU算数逻辑单元高效的挨个完成每个任务。而GPU侧重于并行计算(Parallel Processing),拥有大量的ALU可以同时处理大规模的简单计算。简单来说,CPU的工作模式好比一位博士单独去解一道复杂的高数题,而GPU则如同一百名高中生一起计算加减、乘除法。
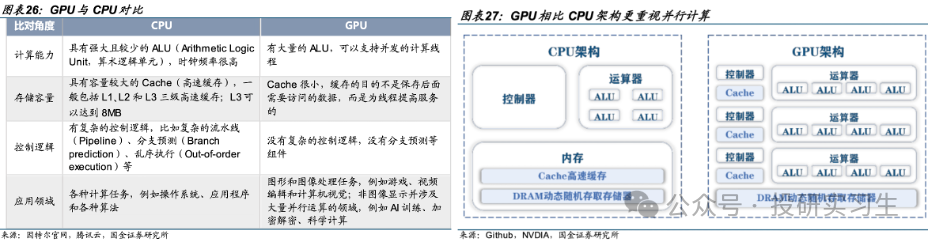
CPU已经如此强大了,为什么还需要GPU呢,或者说为什么在图形处理和如今的人工智能浪潮下为什么GPU这个以前CPU的小弟成为了王者呢?首先在图像处理领域,图片是由一个个像素点组成的,比如一张1080p的图片实际上是由1920x1080= 207万像素点组成,但是每个像素点的计算并不复杂。由CPU加载图片时是一个一个的单独运算每个像素点,而使用GPU的话则是并行计算,由多个ALU同时处理每个像素点,从而实现快速处理全部像素点。

在人工智能大模型中同理,大模型可以有各种不同结构,但其背后的本质都是基于神经网络的深度学习,它的核心运算需求并不高,主要就是累加和累乘的运算,但是由于模型参数巨大、网络层数复杂,因此需要运用大规模并行计算,这也就是为什么GPU如今独领风骚。

由黄仁勋于1993年创立的英伟达可谓是GPU的奠定者和缔造者,1999年英伟达推出了被誉为世界上第一款真正的GPU的GeForce 256,并凭借此产品获得巨大成功。然而,作为专用处理器,传统 GPU 应用局限于图形渲染计算,在面对非图像并涉及大量并行运算的领域,比如 AI、加密解密、科学计算等则更需要通用计算能力。为了提高GPU的通用性,英伟达于2006年推出的CUDA开发环境构造了其强大的生态护城河,自此GPGPU(General Purpose GPU)时代开启。

CUDA(Compute Unified Device Architecture,统一计算设备架构) 可以让开发者能够用类似 C 语言的方式编写程序,让 GPU 来处理计算密集型任务。简单来说,CUDA平台是英伟达提供给开发者的编程工具,包含了一系列工具函数,有各种功能,同时CUDA可以让开发者调用成千上万的 GPU 核心同时工作,进一步提高计算速度。随着时间推移,CUDA被应用在包括物理化学、生物医药、人工智能等众多行业领域,其开发者生态也不断丰富,同时由于CUDA只适用于英伟达的GPU,它成为了英伟达主导GPU的杀手锏。类似于CUDA的还有针对AMD的GPU使用的ATIStream,以及两款开源平台ROCm和OpenCL,这两者可实现不同生态GPU的相互迁移。
在GPU发展历史上,除了CUDA平台外,微架构迭代与芯片制程升级是单卡GPU性能提升的关键途径。GPU 的微架构是用以实现指令执行的硬件电路结构设计,不同的微架构设计会对 GPU 的性能产生决定性的影响。以英伟达为例,从最初 Fermi 架构到现在的Hopper架构和最新的Blackwell架构,英伟达平均买两年更新一次架构,每一阶段都在性能和能效比方面得到提升,同时引入了新技术,如 CUDA、GPU Boost、RT 核心和 Tensor 核心等,作为行业第二的AMD也紧跟英伟达更新其微架构。
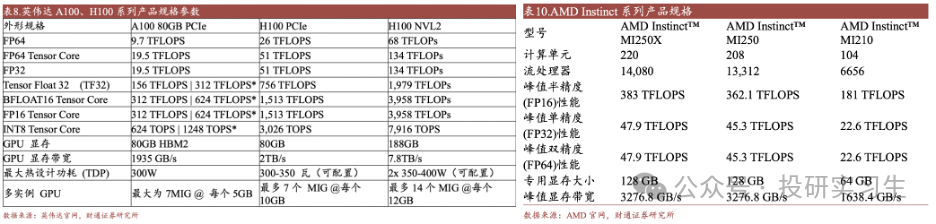
对比当前主流的顶级GPU英伟达H100和AMD的MI250X可以看出,二者在硬件层面上的差距并不大,真正能够使英伟达维持80%市占率达的其实是软件层面的CUDA平台,由于多年以来众多主要开发者都使用基于CUDA的英伟达GPU,其形成的广泛生态和粘性极大的增加了进行更换厂商的总成本,同时这也给远在大洋彼岸的国内厂商追赶英伟达造成更大的挑战。因此英伟达不仅仅是我们印象中的卖芯片的硬件公司,它也是一家强大的软件公司。
ASIC
在GPGPU时代GPU已经具备了类似CPU的通用性,专用处理器中还剩下ASIC和FPGA两款。ASIC (Application Specific Integrated Circuit,专用集成电路)是为了某种特定需求而专门定制的芯片。ASIC 的计算能力和计算效率都可以根据算法需要进行定制,因此与通用芯片相比具有体积小、功耗低、计算性能高等优势。但是缺点也很明显,ASIC只能针对特定的几个应用场景,算法和流程变更可能导致 ASIC 无法满足业务需求。
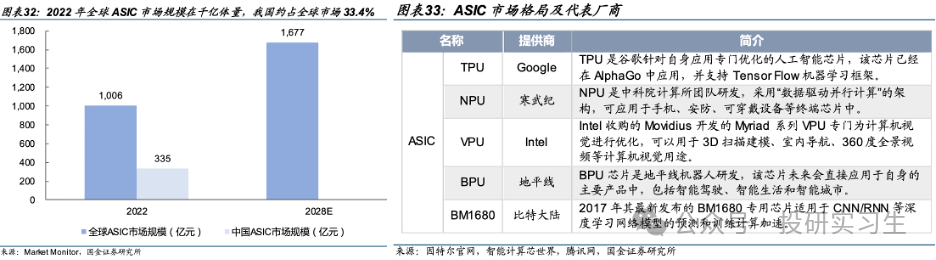
由于目前对于芯片的需求爆发主要还是来自AI领域,针对AI计算场景设计的ASIC从性能、能效、成本均极大的超越了通用芯片,是GPU的潜在竞争对手。目前全球 ASIC 市场并未形成明显的头部厂商,由于 ASIC 需要定制且开发周期长,大多为云计算/互联网等大厂有资金与实力进行研发,且仅当其定制化应用场景市场空间足够大时量产ASIC才能实现丰厚利润。目前市场上主流 ASIC 有 TPU 芯片、NPU 芯片、VPU 芯片以及 BPU 芯片,它们分别是由谷歌、寒武纪、英特尔以及地平线公司设计生产,预计未来将有更多诸如微软、亚马逊、百度、阿里等云计算巨头加入定制自家的ASIC。
FPGA
除了ASIC外,FPGA (Field-Programmable Gate Array,现场可编程门阵列)也是一种专用芯片,其最大特点是现场可编程性。CPU、GPU以及各类 ASIC 芯片在制造完成后,其芯片的功能就已被固定,而 FPGA 芯片在制造完成后,用户可以根据自己的实际需要,将自己设计的电路通过 FPGA 芯片公司提供的专用 EDA 软件对 FPGA 芯片进行功能配置,从而将空白的 FPGA 芯片转化为具有特定功能的集成电路芯片。FPGA 芯片由可编程的逻辑单元(Logic Cell,LC)、输入输出单元(Input Output Block,IO)和开关连线阵列(Switch Box,SB)三个部分构成。
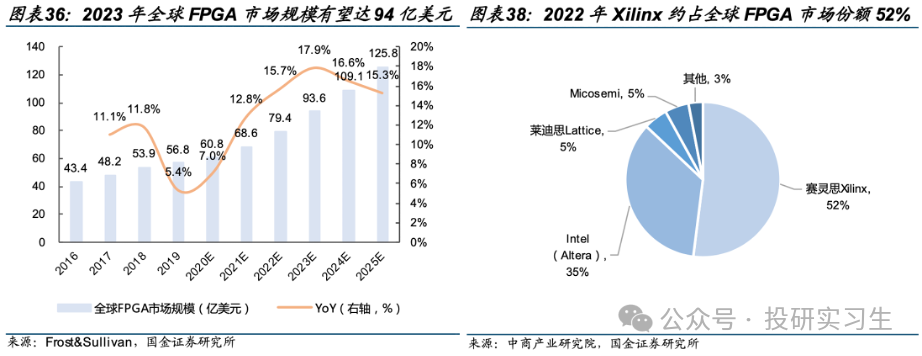
2023 年全球 FPGA 市场规模有望达 94 亿美元,且保持15%左右的增速。从竞争格局上看,被AMD收购的赛灵思Xilinx 约占全球 FPGA 市场份额 52%,Intel 旗下 Altera 约占 35%。
中美情况对比
前面详细介绍了主要四种处理器芯片的功能、市场空间和竞争格局,接下来进一步说说中国和美国在AI芯片上的差距。首先,无论是站在国家安全、自主可控的角度还是受美国卡脖子技术禁令影响的角度,国产自研替代虽然艰难但一定是未来最可靠甚至是唯一的出路。
从算力、算法和应用层出发,中国厂商和美国同行相比都有一定差距。在算力端存在芯片性能及生态差距,在芯片的生产端核心环节如芯片的设计、流片等也均由海外主导;在算法端,海外在基础研究方面较为领先,如谷歌发布底层架构 Transformer ;应用端,海外头部应用多已成为行业标准,拥有较为良好的用户基础,有助于 LLM+产品的快速落地,如办公领域的微软 Office 产品。
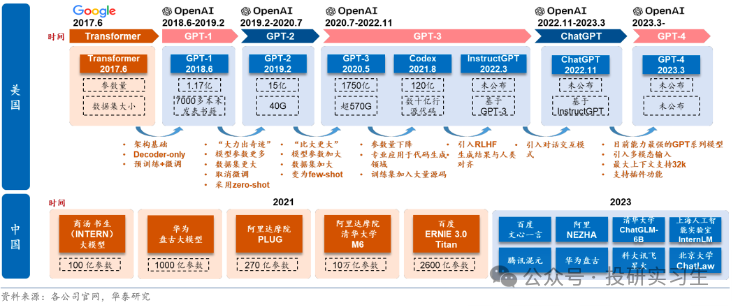
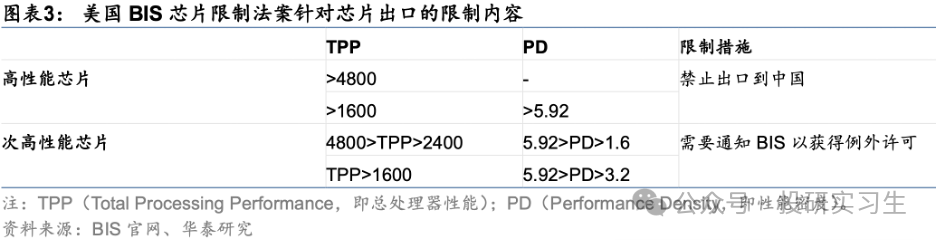
不过算法和应用端的差距不大,而算力层面的差距是最关键的。一方面算力端的核心环节均受海外主导,很难绕开,而且海外头部算力厂商围绕自身产品形成了包含应用、算法的生态壁垒,更加难以突破。另一方面,算力处于基础支撑地位,直接影响模型的落地和应用的推广进度。美国政府为了限制中国AI的发展更是出台政策禁止了美国企业将高端芯片卖给国内企业,自2022年以来美国已多次出台出口限制法案,限制力度逐步提升。去年10月的最新法案中以总处理性能 TPP(Total Processing Performance,即计算速度*字节长度)和性能密度 PD(Performance Density,即每平方毫米的 TPP)为要求,TPP>4800 的芯片、TPP>1600 且 PD>5.92 的芯片属于高性能芯片,不再被允许出口。
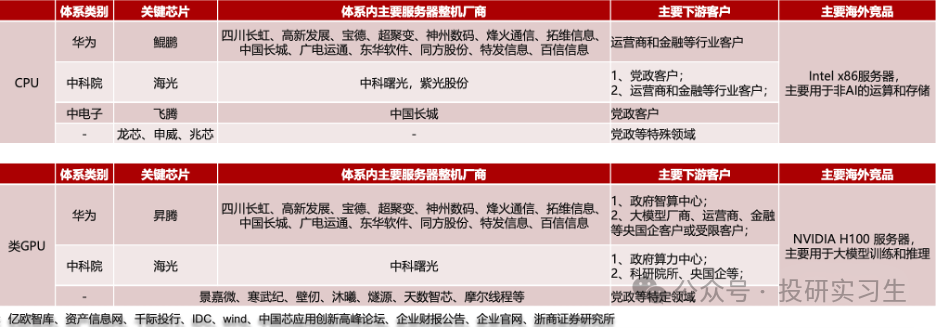
在这个背景下,我们来对比下中美主要AI芯片发展进度。国内的算力产业整体上可分为三大体系:以鲲鹏+昇腾为核心芯片的Arm服务器华为系,以海光为核心芯片、中科曙光为整机厂的x86服务器中科院系,以飞腾为核心芯片、中国长城为整机厂的Arm服务器中电子系。
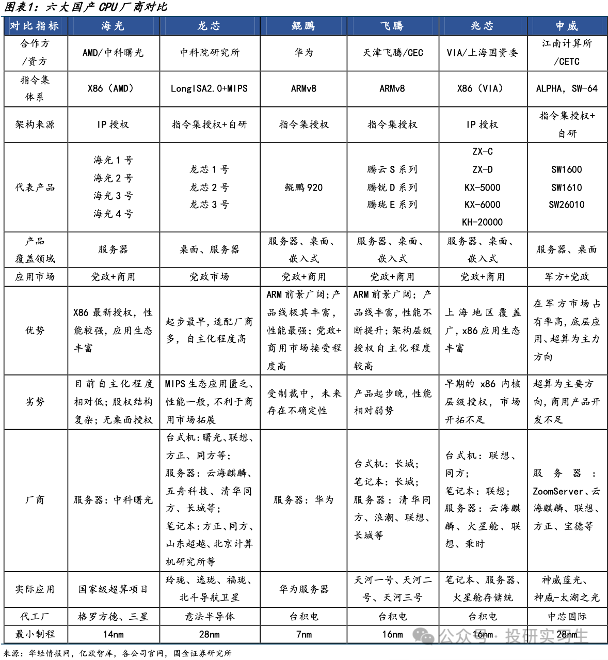
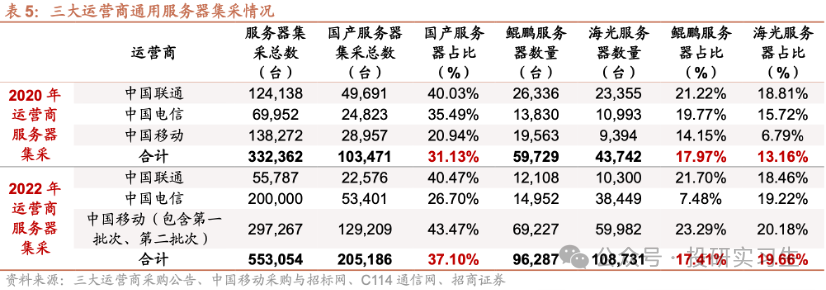
在CPU领域,国内企业经过多年发展与积累形成了海光信息、龙芯中科、华为、飞腾、兆芯和申威六大厂商齐头并进的局面,其中华为和海光性能最好,可对标英特尔与AMD的顶级CPU产品,飞腾和申威的芯片则主要应用于国家超算中心如天河、神威。从三大运营商的采购情况也可以看出,2022年采购中国产CPU服务器占比达到37%,其中海光占比19.66%,华为鲲鹏占比17.41%。
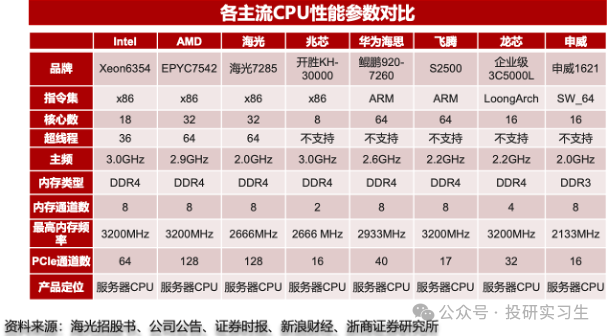
GPU方面,由于GPU领域英伟达占据绝对领导地位,国内厂商目前在硬件和生态上都有较大差距。国内GPU最强的是华为,昇腾310为推理芯片,昇腾910为训练芯片。昇腾 910 芯片采用7nm制程,FP16 算力达到 320TFLOPS、INT8 算力达到 640TOPS,与 NVIDIA A100 80GB 版本旗鼓相当,组网集群上限达到18000张(英伟达A100为16000,H100为50000)。不过与英伟达H100和今年刚刚发布的B100相比存在1-2代差距。
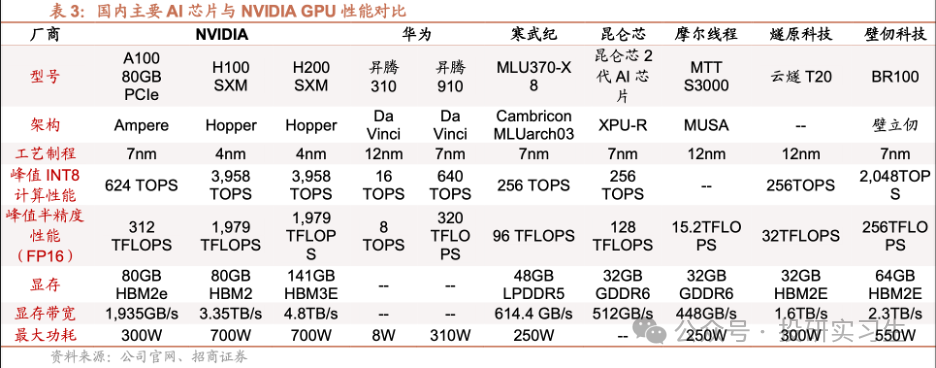
此外,海光信息基于GPGPU架构推出DCU深算产品,软件生态完善兼容通用的“类 CUDA”环境,旗下产品DCUZ100 的关键性能指标实现FP6410.8TFlops,显存32GB HBM2,也可对标英伟达A100和AMD的MI100单卡性能。

发展趋势
最后来说说AI芯片的发展趋势有哪些,由于未来应用于大模型推理的需求将远超过训练需求,AI芯片也朝着更高性能、更低功耗和更靠近边缘和端侧发展。在性能提升方面,单个处理器层面的提升主要来自过去几十年都遵循的摩尔定律,也就是芯片制程的提升,以及设计层面的微架构迭代。然而当晶体管大小接近 1nm 左右时,与 0.1nm 的原子直径尺寸量级接近,量子隧穿引起的晶体管漏电效应将愈发明显,以至于影响芯片正常工作。微架构方面,英伟达于今年三月GTC大会上最新推出的Blackwell架构也展现出架构更新放缓的趋势。
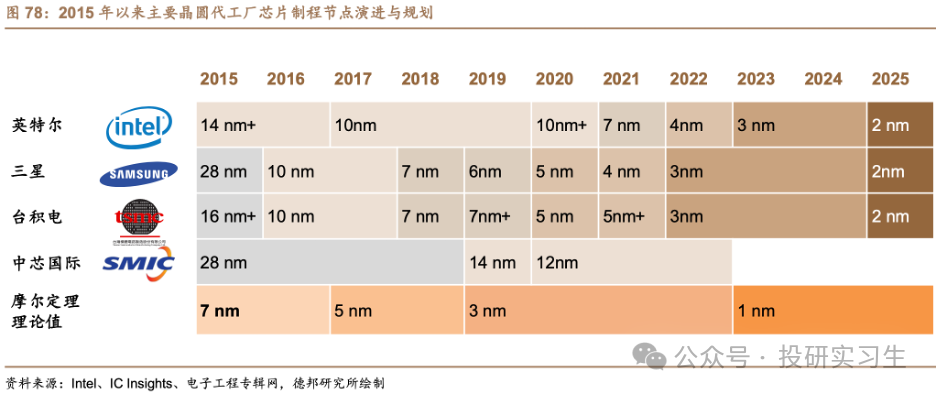
在这个背景下,单张GPU的性能已接近瓶颈,因此未来的发展必然聚焦于多张卡的联合上。在芯片封装层面,通过Chiplet和CoWos等先进封装技术将多颗芯片与内存等模块封装在一起。在系统层面,通过卡间互联、服务器间互联以及数据中心集群间互联等方式集合更多的GPU。
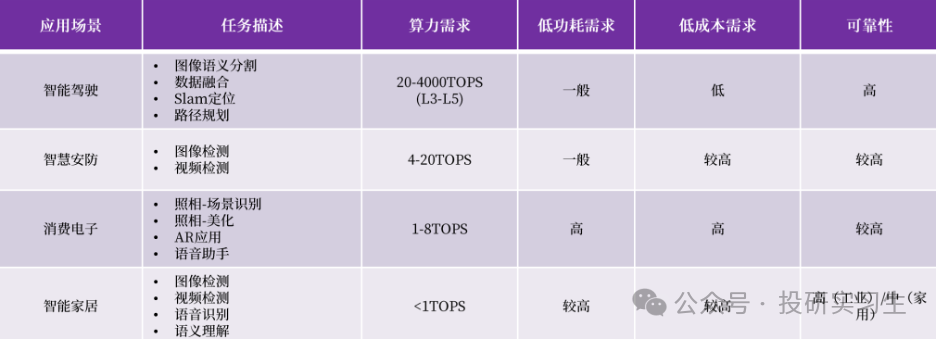
此外,随着越来越多的推理需求出现,AI芯片也将越来越多的从云端转移到边缘和端侧,也会出现更多低功耗的端侧芯片,比如现在的自动驾驶、AI PC和AI手机等概念,都需要将算力直接部署到汽车、电脑或手机上。
-
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值2026-03-10 957
-
什么是AI算力模组?2025-09-19 1269
-
一文看懂AI算力集群2025-07-23 2180
-
摩尔线程与AI算力平台AutoDL达成深度合作2025-05-23 2265
-
大算力芯片的生态突围与算力革命2025-04-13 3732
-
浅谈为AI大算力而生的存算-体芯片2023-12-06 1003
-
ai芯片和算力芯片的区别2023-08-09 10498
-
ChatGPT背后的算力芯片2023-05-21 5093
-
ChatGPT供应算力的核心基建——AI芯片2023-02-15 2180
-
昆仑芯AI芯片以AI算力服务实体经济 筑底算力经济新基建2022-10-19 4024
-
亿铸科技发布基于ReRAM的全数字化存算一体AI大算力芯片技术2022-09-01 4146
-
存算一体大算力AI芯片将逐渐走向落地应用2022-05-31 6794
-
深度解析AI算力的现状和趋势2018-08-01 9938
全部0条评论

快来发表一下你的评论吧 !
