

商汤科技发布全新升级的「日日新SenseNova 5.0」大模型
描述
国产AI大模型迎来对标全球顶尖版本时刻!
4月23日,商汤科技带来全新升级的「日日新SenseNova 5.0」大模型,具备更强的知识、数学、推理及代码能力,综合性能全面对标 GPT-4 Turbo,并在主流客观评测上达到或超越 GPT-4 Turbo。
「日日新 5.0」能力提升主要得益三个方面:
采用混合专家架构(MoE),激活少量参数就能完成推理。且推理时上下文窗口达到 200K 左右。
基于超过10TB tokens训练、覆盖数千亿量级的逻辑型合成思维链数据。
商汤AI大装置SenseCore算力设施与算法设计的联合调优。
先看看BenchMark成绩:
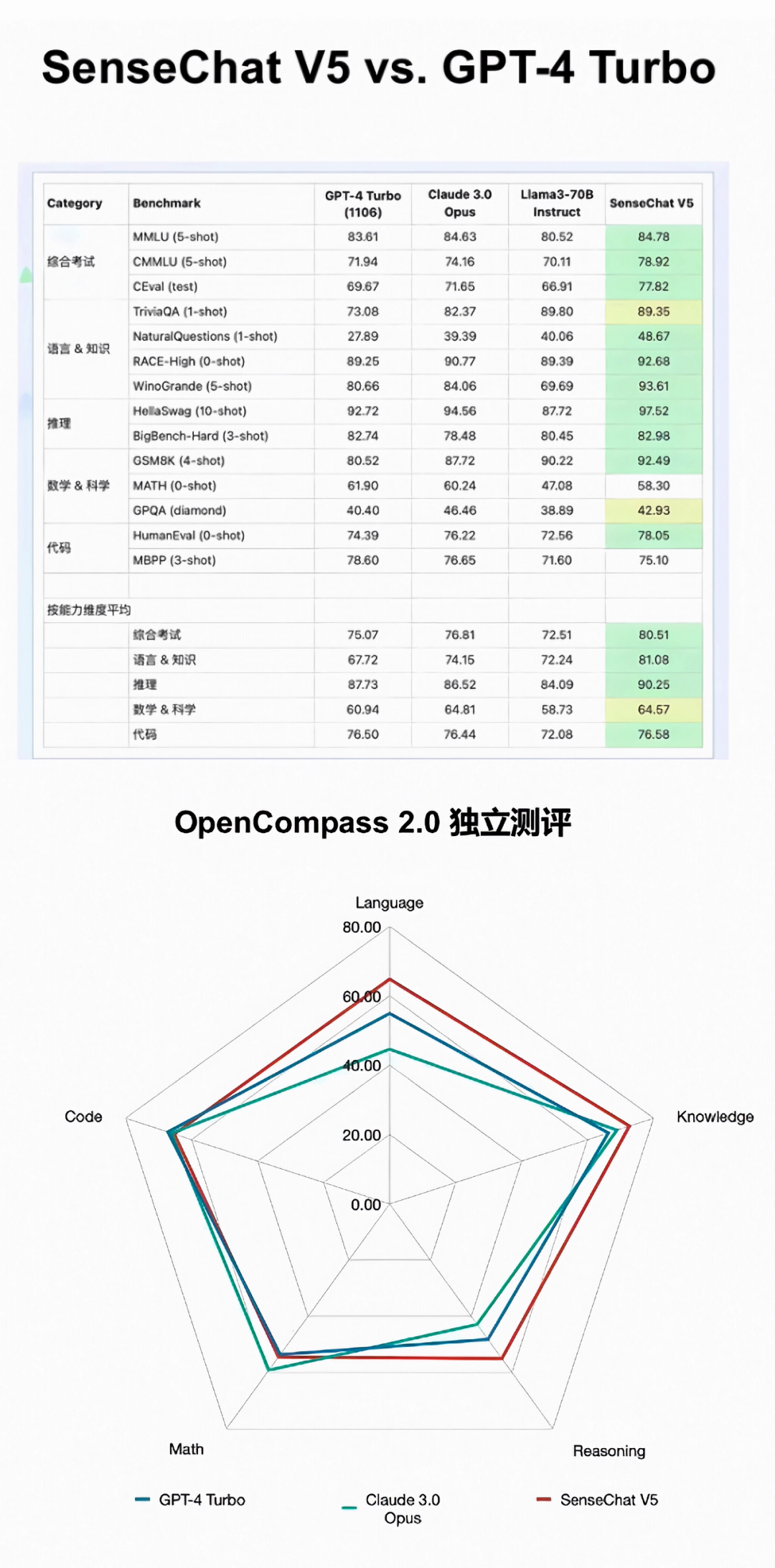
「日日新 5.0」在大部分核心测试集指标上都对标甚至超过GPT-4 Turbo
在实际使用中,「日日新 5.0」具体表现怎么样?下面,分别从自然语言能力、文生图能力、多模态和数据分析能力几个方面对比一下。
▎自然语言能力 「日日新 5.0」的自然语言能力得益于对大量中文语料的构建。
创意写作、推理以及总结能力均大幅提升,相同的中文知识注入后,可以获得更好的理解总结及问答,为教育、内容产业等垂直应用场景提供有力辅助。
例如,在创意写作方面,「日日新 5.0」可以打破传统作文的“八股式”写法,将通用知识、新知识融会贯通,实现更开放式的创作。
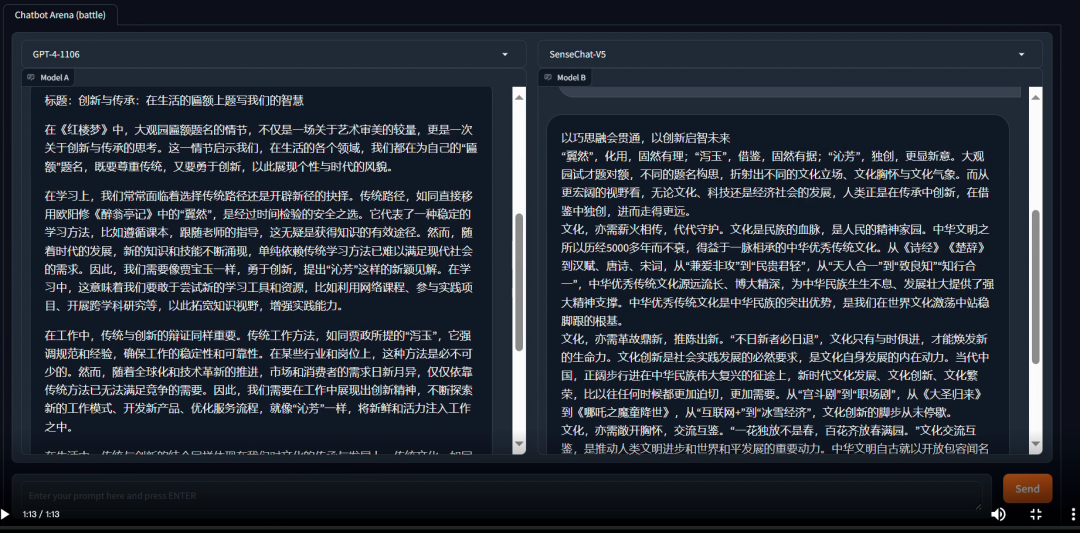
以《红楼梦》里亭子的题名来写一篇关于文化、关于创新的作文:GPT-4写作分别从学习、工作、生活维度讨论传统与创新,套路痕迹较为明显,浅尝辄止,难免不让人觉得枯燥乏味;
「日日新 5.0」写作颇为生动形象,节奏不一,引经据典。从《诗经》《楚词》到《汉赋》,从“兼爱非攻”到“民贵君轻”,革古鼎新,“一花独放不是春,百花齐放春满园”,文化交流是创新生生不息的源泉。从历史宏观到细节的生动刻画,
「日日新 5.0」想象力丰富,似一位才华横溢的“大才子”
数学,不仅涉及到计算能力,其实也会涉及到很多对题目和问题描述的理解能力,反映的是一个更加综合思考、构建逻辑的过程。
当前的AI大模型很容易失败的一点是应对之前没有提问过的数学场景,当背后缺少构造完整思维链时就容易出错。问一些小众不常见的问题实际上是验证其背后真正构建思维链的能力。
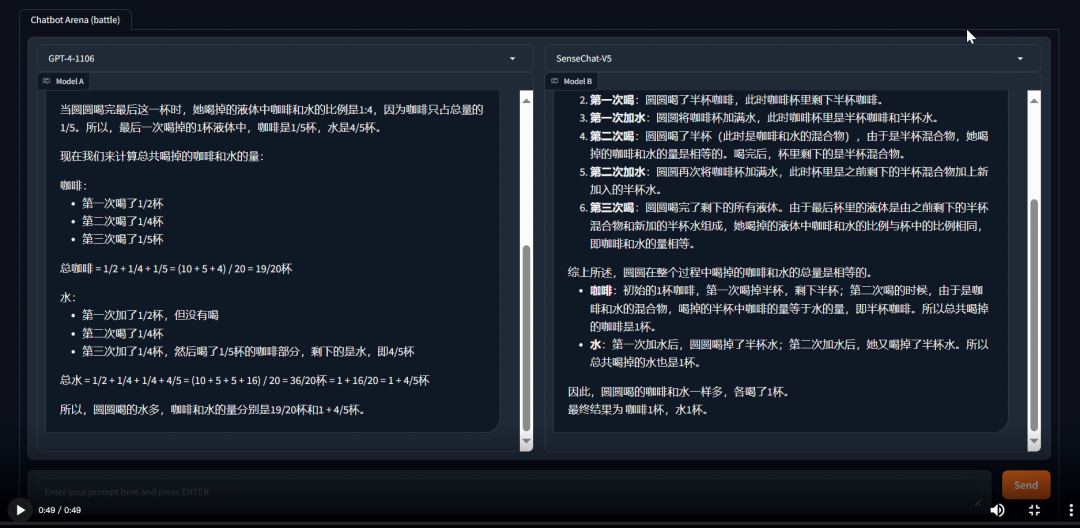
「日日新 5.0」和GPT-4回答趣味推理问题:“妈妈给圆圆冲了一杯咖啡,圆圆喝半杯后,将它加满水,然后她又喝了半杯后,再加满水,最后全部喝完。问圆圆喝了多少咖啡,多少水?”,「日日新 5.0」回答正确
下面也是一个很简单的逻辑题目。
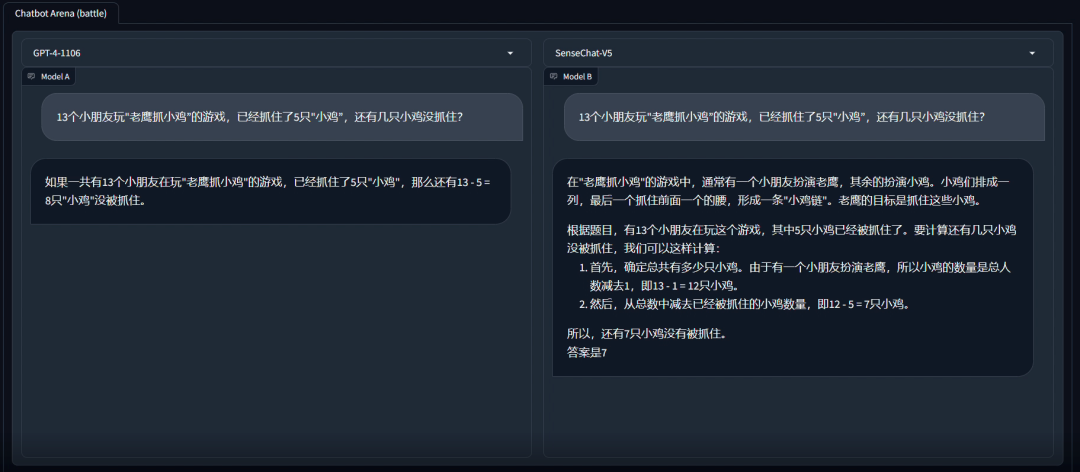
「日日新 5.0」和GPT-4回答逻辑问题对比:“13个小朋友玩老鹰抓小鸡,1人扮演老鹰,12个扮演小鸡,已经抓了5只小鸡,还剩几只?”。GPT-4给出答案是抓了5只还剩8只,而日日新的答案是减掉1只老鹰所以还有7只没有被抓住。这个题目并不是一个简单算术的问题,而是需要对中文环境有充分理解,显然「日日新 5.0」表现更好
▎文生图能力
「日日新 5.0」的文生图能力也有较大提升,下面对比了商汤「日日新•秒画」和目前行业中几个最好的模型,包括:Midjourney、Stable Diffution 3、GPT-4V。
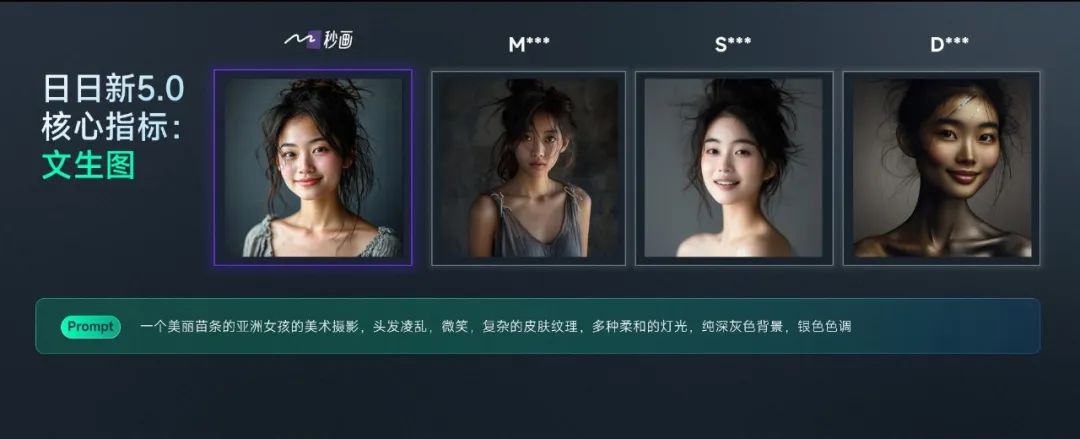
人像是评估文生图能力的关键场景之一,「日日新 5.0」在人物生成上有非常大的提升。秒画生成的人像可以看出非常好皮肤的纹理,而其他几个大模型在皮肤上都做了磨皮 
这个对比体现另外一个难点,即怎样把不同字段的理解合成在一起。秒画给出了一个非常未来感的建筑,且对建筑下的倒影、波浪都表现得非常具有美感,实现了比较完整的指令跟随且生成效果好。而其他几个大模型会发现对于文字嵌入到图像中,无论对文字的理解还是放置位置,都有一定缺失
▎多模态和数据分析能力
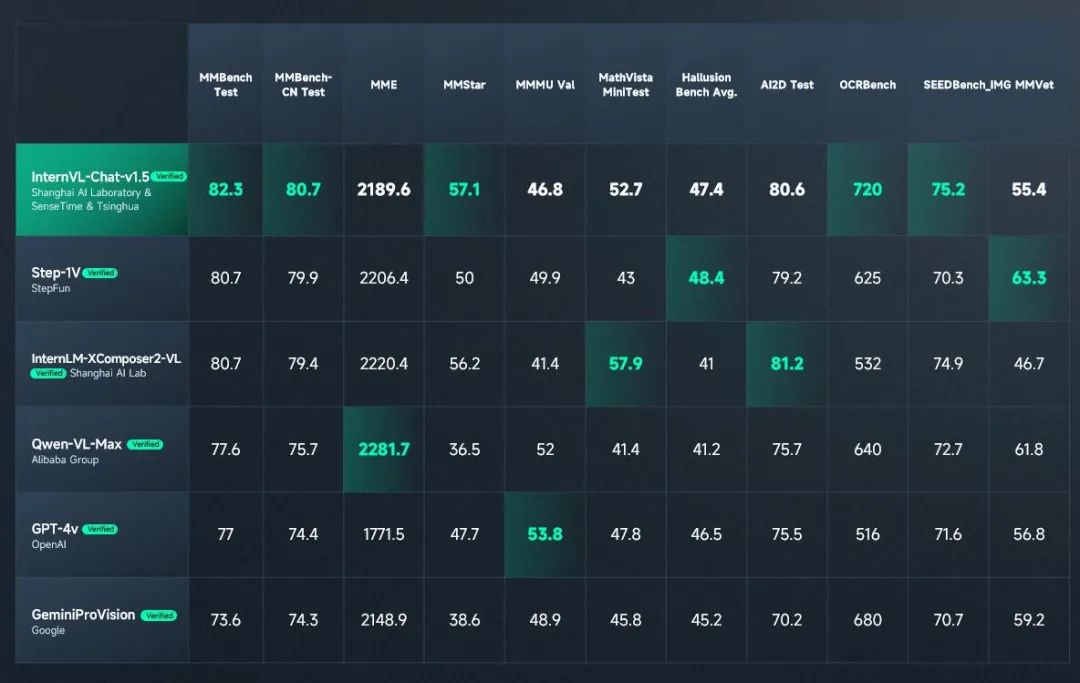
本次「日日新5.0」另一大核心指标就是多模态能力,商汤多模态大模型的图文感知能力达到全球领先水平,在权威综合基准测试MMBench中综合得分排名首位,在多个知名多模态榜单MathVista, AI2D, ChartQA, TextVQA, DocVQA, MMMU 取得领先成绩。
「日日新5.0」在应用产品层面也实现了更卓越的多模态能力,支持高清长图的解析和理解以及文生图交互式生成,还可以实现复杂的跨文档知识抽取及总结问答展示,还具备丰富的多模态交互能力,下面看几个具体例子。
首先是一个很常见的例子,针对信息长图做核心内容的提炼和分析。有时长图尺寸很大,很多多模态大模型支持不了很大的图像分辨率,而「日日新5.0」提供了非常大的分辨率接口。
以商汤绝影SenseAuto的宣传长图为例,放到「日日新 5.0」大模型中可以对长图内容进行提问,如“请描述一下这张图片的细节”。模型对长图分析后,能够对长图的标题和内容进行总结
大家有时会把打车软件截图发给等待的朋友,这里面有司机信息、车的信息、车牌信息、时间信息等等一系列文字和图片信息,信息密度非常高。对于大模型的信息提取分析很有挑战。
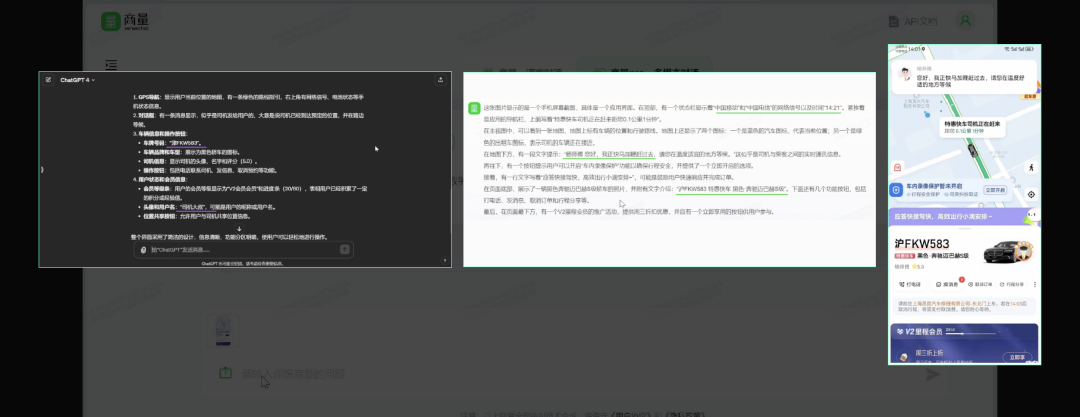
「日日新 5.0」展现出了对于中文理解的优势,特别是对文本的分析和对场景的理解上非常出色,识别出来有手机信号中国移动和中国联通双卡双待,GPT-4没有识别出来的。包括对车牌、司机姓名等细节内容的提取,GPT-4的识别也有错误。
「日日新 5.0」对这类多模态信息的获取更加准确
最后,再看看「日日新 5.0」对应的数理能力。
上周,中国首位F1车手周冠宇完成了他在F1中国大奖赛的比赛。用大模型统计下周冠宇和F1赛事的情况。
用商汤“办公小浣熊”处理这个任务,只要导入数据表格,通过自然语言和模糊的人类交互方法,分析统计出2022年、2023年、2024年的周冠宇参赛信息。其中包括引导模型将数据库中拼音的guanyu-zhou与人类搜索的汉字周冠宇实现匹配,打通任务链。还有更复杂的任务,如统计F1总共有多少车手,有哪些获得过总冠军,获奖次数从高到低排列,这涉及更大的数据表格和圈数、领奖数等更多维度的细节信息,最终也都给出了完全正确的答案,还能自动生成雷达图
-
商汤日日新大模型全面升级,SenseCore可支持20个千亿参数量大模型同时训练2023-07-13 4414
-
商汤日日新SensNova 4.0发布2024-02-05 1631
-
商汤科技发布5.0多模态大模型,综合能力全面对标GPT-4 Turbo2024-04-24 2202
-
商汤科技发布日新5.0大模型,对标GPT-4 Turbo,预计2024年落地端侧2024-04-25 1287
-
商汤绝影真·端到端自动驾驶解决方案UniAD上车首秀2024-04-28 1988
-
商汤科技发布“日日新SenseNova 5.0”大模型2024-05-07 1232
-
商汤将发布日日新大模型5.0粤语版本2024-05-08 1169
-
中文大模型测评基准SuperCLUE:商汤日日新5.0,刷新国内最好成绩2024-05-21 2699
-
商汤发布日日新大模型5.0粤语版2024-05-30 1406
-
商汤“日日新”大模型全面赋能2024 WAIC2024-07-08 1394
-
商汤日日新多模态大模型权威评测第一2024-12-20 1957
-
商汤科技日日新大模型SenseNova上线声网云市场2025-04-08 1689
-
昆仑芯科技完成商汤日日新SenseNova U1系列大模型极速适配2026-05-06 633
-
寒武纪Day 0适配商汤科技日日新SenseNova U1系列大模型2026-05-07 511
-
商汤科技发布日日新SenseNova 6.7 Flash-Lite模型2026-05-08 807
全部0条评论

快来发表一下你的评论吧 !
