

如何利用一些小技巧实现SVM的增量式训练
人工智能
描述
老树发新芽SVM的增量式训练
大家是不是以为我们的SVM篇就这样结束了?nonono,对于这样一位资深的老前辈来说,寥寥几篇怎能叙说尽,换句话来说,历经几十年的历练,还能屹立于ML之巅,必定拥有卓越的技术实力和深厚的专业底蕴。
不过,大家在用SVM时一定也注意到过SVM本身只支持单次训练,要怎么解释呢?意思就是说我们在训练一个SVM模型前,要事先指定好想要识别的类别或是任务,这样训练好之后,模型就只能针对所指定的任务了。如果想要再添加新的需求,那不好意思了,需要再重新制定任务,并且这个任务必须包含老任务,不然SVM就会喜新厌旧了,只能完成新任务。
这样一来是不是有点麻烦?有伙伴要问了,我们CNN就能支持增量学习,你这SVM看起来还是不太行啊。那么为了给我们的SVM大佬正名,今天小编就给大家带来一篇番外,利用一些小技巧实现SVM的增量式训练。直接上代码!!
继续使用我们的鸢尾花数据集,不过这次我们做点特殊的。我们将其作为一个单分类的数据集来使用,具体怎么做呢?让我们一步步来看:
鸢尾花数据集一共有150组样本,我们先选取前50组出来,训练一个单分类模型,目的是让其只能够识别一种样本,代码片段:
|
from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.svm import OneClassSVM from sklearn.metrics import accuracy_score import numpy as np # 加载数据集 iris = datasets.load_iris() X = iris.data y = iris.target data_each = 50 X0 = X[:data_each] y0 = y[:data_each] # 构建支持向量机分类器 svm = OneClassSVM(kernel='rbf', nu=0.1) # 在训练集上训练模型,选取前30组作为训练样本 svm.fit(X_train[:30]) # 在测试集上进行预测,选取后20组数据作为测试集 y_pred = svm.predict(X_train[30:]) print("ACC: ", (y_pred == 1).sum() / len(y_pred)) |
测试结果打印:
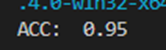
好的,接下来就是至关重要的一步了,我们知道SVM全称是支持向量机,那么其原理就是在训练样本重抽取一部分当作支持向量,即挑选出能够代表全体数据的灵魂数据。换句话说,这些支持向量本身就能代表当前类别的所有数据,通过和支持向量间的对比即可认定新数据是否属于同一类别。那么好,我们要做的就是将这些支持向量提取出来,并将其与新数据拼接在一起作为新的训练数据:
|
support_vector = svm.support_vectors_ # 拼接数据,将前一类别的支持向量与新数据结合 new_train_x = np.vstack([support_vector, X[data_each:2*data_each][:30]]) |
这里提前看一下支持向量,针对于第一个类别,支持向量有4个:
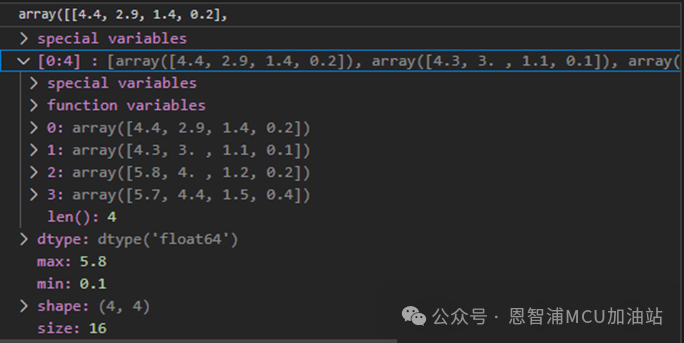
继续训练,并测试:
|
# 构建支持向量机分类器 svm = OneClassSVM(kernel='rbf', nu=0.1) svm.fit(new_train_x) # 在测试集上进行预测,拼接之前的数据集 y_pred = svm.predict(np.vstack([X0[30:], X[data_each:2*data_each][30:]])) print("ACC: ", (y_pred == 1).sum() / len(y_pred)) |
测试结果:
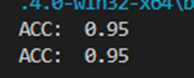
再来看下新的支持向量:
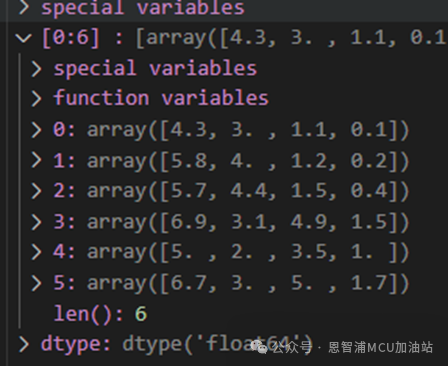
可以看到,在第一次支持向量的基础上,又增加了针对第二个类别的。同时根据测试精度,可以看出,通过添加第一次训练多得到的支持向量,而非将全体数据进行二次训练,能够达到同样的效果。也验证了我们的猜测:支持向量本身其实就是数据集的代表,只将其作为训练样本,完全能够替代全部数据。并以此为基础实现SVM模型的增量式训练。
审核编辑:黄飞
-
如何在stm32上实现svm实时训练与分类?2021-11-19 3031
-
使用NodeMCU开发一些小项目2021-11-01 1609
-
在STM32如何去实现增量式PID算法2021-09-13 2092
-
利用Arduino与增量式光电编码器测量速度2021-09-03 2791
-
在stm32上实现svm实时训练与分类2021-08-17 3015
-
一个基本的SVM2020-06-11 1438
-
TFT液晶的一些小图标怎么触发2019-03-22 2727
-
基于Hadoop的数据驱动的并行增量算法2017-12-09 930
-
单片机的一些小项目资料2015-11-18 712
-
关于半导体的一些小常识2010-03-01 1119
-
一些小型按钮开关2009-09-19 3019
-
一些小型有机实芯电位器2009-08-21 831
-
关于ISA 数据交换的一些小例子2009-05-14 722
-
一种基于凸壳算法的SVM集成方法2009-04-16 790
全部0条评论

快来发表一下你的评论吧 !
