

python解析netflow数据到csv的流程详解
描述
python解析netflow数据到csv
本文主要讲解了linux下通过tcpdump抓取netflow数据包,并将其导入到wireshark进行解析,然后通过wireshark导出数据为json文件,再通过python脚本将其解析为csv文件以便做数据分析。
使用linux自带的tcpdump抓包
在linux的shell下使用tcpdump包抓取指定端口下的数据包,netflow流量的端口默认为9996端口。
tcpdump udp port 9996 -w netflow_data.cap
在shell打上该命令linux便会开始抓包,按Ctrl+C则会停止抓取并将数据写入netflow_data.cap文件,由于netflow的数据量特别大,所以如果没有过滤出指定ip的netflow流量,建议不要取太长时间(毫不夸张的说,一个大型企业的netflow流量10分钟的netflow数据往往可以使这个文件达到好几个G,解析成json文件后甚至达到几十G,这已经远远超出了一般程序可以解析处理的范围)。
可以先使用
tcpdump udp port 9996 | grep xxx.xxx.xxx.xxx
测试检查是否可以获取对应的数据,如果长时间没有响应,这表明数据数据包可能没有到达本端,需要检查设备配置或者防火墙策略。
在linux下使用该命令可以查看对应端口下的数据包,通过grep可以过滤出自己的想要查看的ip
将抓好的包导入wireshark
抓取下来的包直接用wireshark打开(windows版和Mac版都可以)。如下图所示:
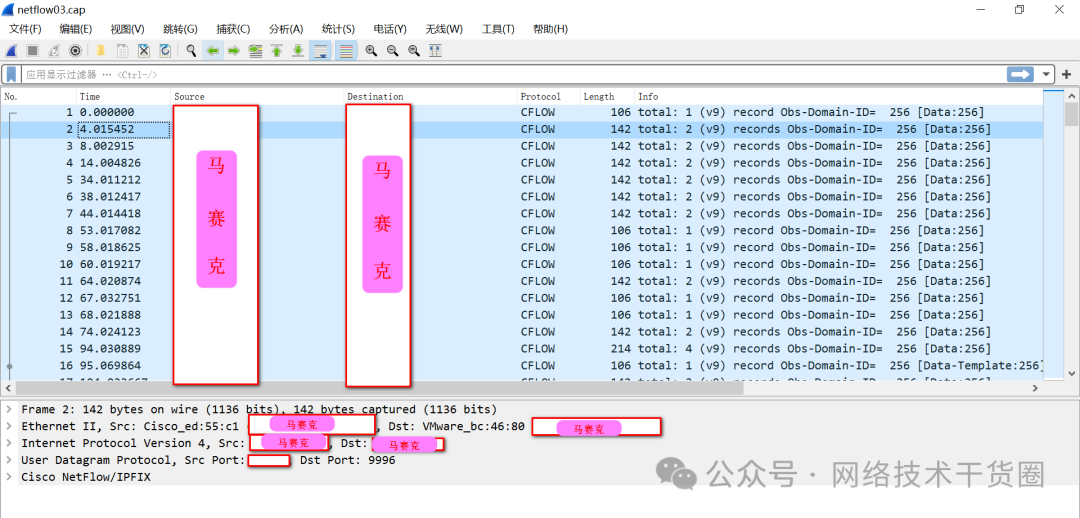
如下图所示,随便点击一个数据包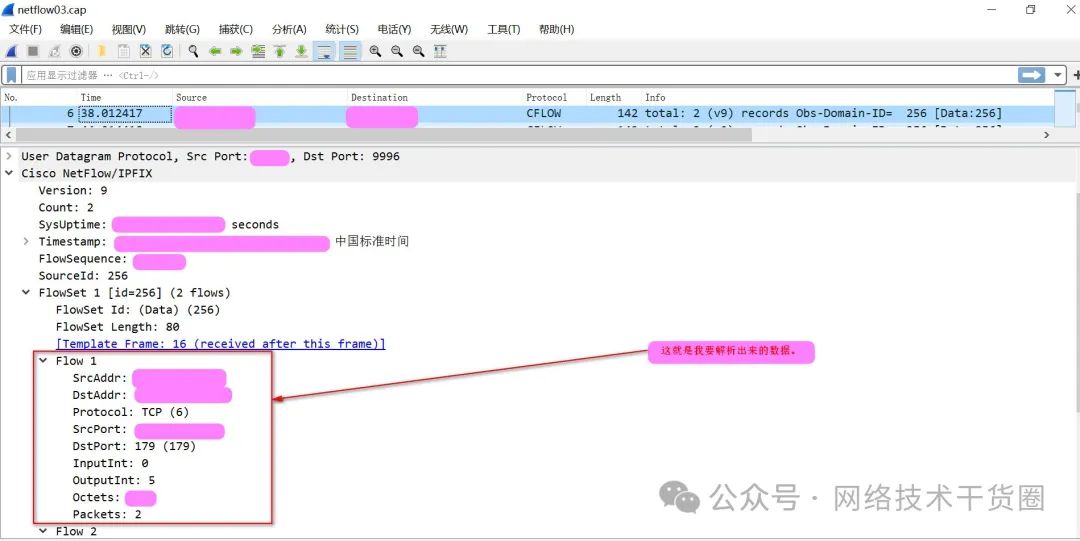
将数据导出为json文件
在wireshark中导出数据到json文件,以便于我们使用python对数据进行解析。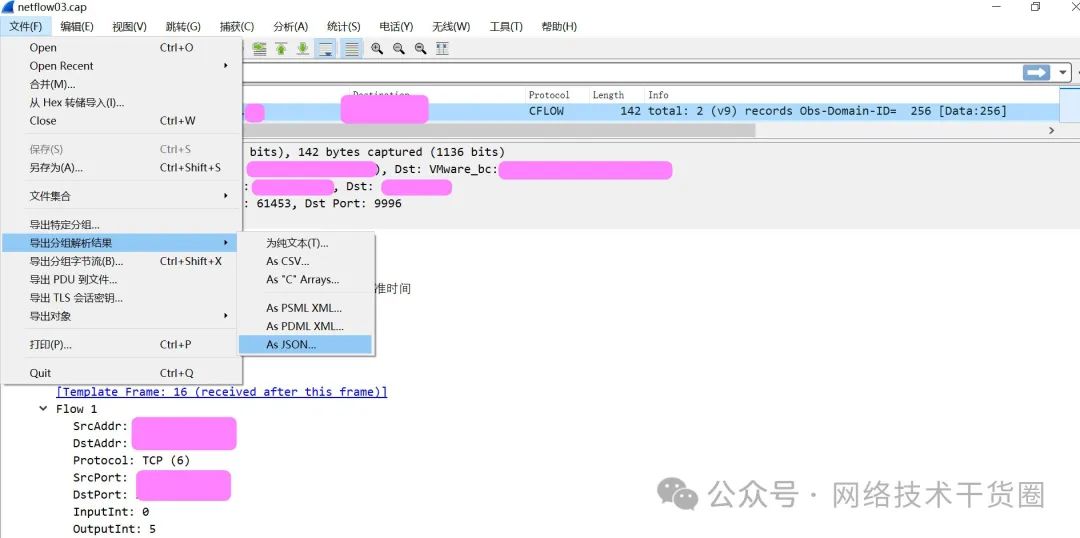
解析数据到csv
将导出好的json文件上传到安装了python环境的终端上(例如Linux或Mac),与如下脚本(脚本名称netflow_to_csv.py)放置在同一目录下
# _*_ coding: utf-8 _*_
import json
data_file = './data.json' # wireshark导出数据
output_file = './netflow.csv' # 解析后文件名
with open(data_file, 'r') as f:
data_list = json.loads(f.read())
def get_the_flow_list(data_item):
'''
["Flow 1": {
"cflow.srcaddr": "xxx.xxx.xxx.xxx",
"cflow.dstaddr": "xxx.xxx.xxx.xxx",
"cflow.protocol": "2",
"cflow.srcport": "0",
"cflow.dstport": "17",
"cflow.inputint": "5",
"cflow.outputint": "0",
"cflow.octets": "36",
"cflow.packets": "1"
},
"Flow 2": {
"cflow.srcaddr": "xxx.xxx.xxx.xxx",
"cflow.dstaddr": "xxx.xxx.xxx.xxx",
"cflow.protocol": "2",
"cflow.srcport": "0",
"cflow.dstport": "17",
"cflow.inputint": "5",
"cflow.outputint": "0",
"cflow.octets": "36",
"cflow.packets": "1"
}
]
'''
cflow = data_item.get('_source').get('layers').get('cflow')
flowSet_k = [k for k,v in cflow.items() if 'FlowSet' in k][0]
flow_data_list = []
# flow_list = [{f:v} for f,v in cflow.get(flowSet_k).items() if 'Flow ' in f]
for k,v in cflow.get(flowSet_k).items():
if 'Flow ' not in k:
continue
srcaddr = v.get("cflow.srcaddr")
dstaddr = v.get("cflow.dstaddr")
protocol = v.get("cflow.protocol")
srcport = v.get("cflow.srcport")
dstport = v.get("cflow.dstport")
inputint = v.get("cflow.inputint")
outputint = v.get("cflow.outputint")
octets = v.get("cflow.octets")
packets = v.get("cflow.packets")
flow_data_list.append((k, srcaddr, dstaddr, protocol, srcport, dstport, inputint, outputint, octets, packets))
return flow_data_list
def domain():
with open(output_file, 'w') as f:
title = 'No,Flow_id,srcaddr,dstaddr,protocol,srcport,dstport,inputint,outputint,octets,packets
'
f.write(title)
i = 0
for data_item in data_list:
i = i + 1
try:
flow_list = get_the_flow_list(data_item)
for flow_item in flow_list:
line = '%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s
' % (i, flow_item[0], flow_item[1], flow_item[2], flow_item[3], flow_item[4], flow_item[5], flow_item[6], flow_item[7], flow_item[8], flow_item[9])
f.write(line)
except Exception as e:
print 'template'
print e
continue
if __name__ == '__main__':
domain()
运行解析脚本
在shell下运行如下命令即可。
python netflow_to_csv.py
解析结果
最终运行结果如下图所示: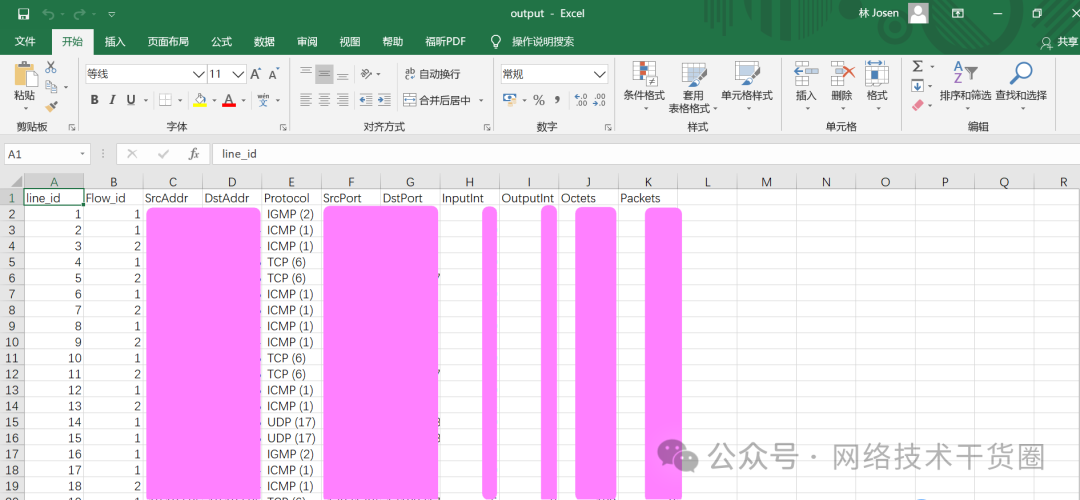
-
Labview采集到的串口数据存储在csv文件中2016-11-28 8470
-
Python存储数据详解2018-03-29 2695
-
csv文件中的数据2018-11-26 2729
-
TensorFlow csv文件读取数据(代码实现)详解2020-07-28 2686
-
有关Python的解析2021-07-29 1492
-
请问CH376S如何读取CSV中的数据,解析出来?2022-10-11 1064
-
完全自学指南Python爬虫BeautifulSoup详解2017-09-07 947
-
Python3如何对CSV进行写入和读写2018-05-11 6169
-
如何通过pandas读取csv文件指定的前几行?2018-09-19 2561
-
python经典实例详解2021-04-26 1140
-
[源代码]Python算法详解2023-06-06 751
-
虹科分享 | NetFlow数据能够为网络故障排除提供什么? | 网络流量监控2023-04-20 1594
-
Python教你用 Rows 快速操作csv文件2023-10-21 1706
-
VVIC 平台商品详情接口高效调用方案:从签名验证到数据解析全流程2025-09-23 879
-
1688 商品详情 API 调用与数据解析 Python 实战2026-02-10 556
全部0条评论

快来发表一下你的评论吧 !
