

算能携手瑞莎计算机(Radxa)推出全球首款SG2300X微型智算盒子
描述
在以 ChatGPT 为代表的大模型应用的出现,加速了智能计算风暴的到来。随着 AI 发展的浪潮,在终端本地运行大模型推理成为下一个热点。在此背景下,算能发布支持运行大模型的终端处理器SG2300X,开启边缘大模型新时代!算能携手瑞莎计算机(Radxa) 推出全球首款 SG2300X 微型智算盒子——瑞莎 Fogwise AirBox。
SG2300X:令人惊喜的端侧生成式AI处理能力
| 产品规格 | SG2300X |
| 处理器 | ARM A53 8核 2.3GHz |
| 内存 | LPDDR4x 4.266 Gbps 128bit 68.256 GB/s;最大容量支持16GB |
| 智能算力 | 24 TOPS INT8;12 TFLOPS FP16/BF16;2 TFLOPS FP32;支持混合精度计算 |
| 视频解码 | H.264 & H.265: 32路 1080P @25fps;最大分辨率支持7680 * 4320 |
| 视频编码 | H.264 & H.265: 12路 1080P @25fps;最大分辨率支持7680 * 4320 |
| 图片编解码 | JPEG: 解码750张/秒 @1080P;编码250张/秒 @1080P;最大分辨率支持 32768 * 32768 |
| 视频后处理 |
支持图像的CSC(RGB/YUV/HSV),resize(1/128~128),crop 支持padding,border,font,contrast and brightness adjustment 最大分辨率支持8192 * 8192,分辨率超过的图片支持切割处理后拼接 支持8bits输入格式:Y only,YUV420/YUV422/YUV444 Planar,NV12/NV21/NV16/NV61 Semi-planar,RGB planar and packed,YUV444 packed,YUV422 packed 支持8/16/32bits输出格式:YUV444/RGB planar 支持8bits输出格式:Y only planar,YUV420/I420 planar,NV12/NV21 semi planar,RGBY/BGRY planar,RGB/BGR packed |
| 高速接口 |
PCIe Gen3 X16 EP,可配置成 X8 RC + X8 EP,支持级联 2个以太网RGMII接口,支持速率10/100/1000Mbps;1个SD/SDIO controller;1个eMMC 5.1,总线位宽4-bit |
| 低速接口 | 1个SPI Flash接口;3个UART接口,3个I2C接口;2个PWM接口,2个风扇转速检测接口;32个通用IO |
| 安全性 | 支持AES/DES/SM4/SHA/RSA/ECC 加速;支持真随机数产生;支持安全密钥存储机制,支持安全启动,支持Trustzone |
| 典型功耗 | 20W |
| 工作温度 | - 40℃ ~ + 105℃ |
| 工具链 | 支持TensorFlow / Pytorch / Paddle / Caffe / MxNet / DarkNet / ONNX;支持TensorFlow / Pytorch / Paddle / TensorRT 以及客户定制的INT8、FP16、BF16量化算法 |
SG2300X处理器拥有24T的算力,能够流畅运行像LLAMA-2 7B这样的生成式AI。
SG2300X惊人的算力使其可以在更短的时间内处理更多的数据,实现更快的响应速度,为用户带来更加流畅和智能的体验。

瑞莎 AirBox:国产化边缘智算设备

瑞莎 Fogwise AirBox是瑞莎计算机团队研发的搭载SG2300X的边缘智算盒子,算力高达 24TOPS@INT8,支持多精度(INT8、FP16/BF16、FP32),支持私有 GPT、文本到图像等主流智能模型部署,配备铝合金外壳,可在恶劣环境中部署。
AirBox 的核心元器件皆采用国产元器件,且瑞莎计算机拥有AirBox的完全知识产权,无惧“卡脖子”。
| Radxa Fogwise AirBox | |
| 形态尺寸 | 104mm x 84mm x 52mm |
| 处理器 | SOPHON SG2300X SoC,八核 Arm Cortex-A53(ARMv8)@ 2.3GHz |
| TPU |
张量处理单元,计算能力:最高达24TOPS(INT8),12TFLOPS(FP16/BF16)和2TFLOPS(FP32) 支持领先的深度学习框架,包括 TensorFlow、Caffe、PyTorch、Paddle、ONNX、MXNet、Tengine 和 DarkNet |
| 内存 | 16GB LPDDR4X |
| 存储 |
工业级 64GB eMMC 16MB SPI 闪存 提供高速SD卡的SD卡插槽 |
| 多媒体 |
支持解码32路H.265/H.264 1080p@25fps视频 完全处理32路高清1080P@25fps视频,涉及解码和AI分析 支持编码12路H.265/H.264 1080p@25fps视频 JPEG:1080P@600fps,支持最大32768 x 32768 支持视频后处理,包括图像CSC、调整大小、裁剪、填充、边框、字体、对比度和亮度调整。 |
| 连接 |
2x 千兆以太网端口(RJ45) 1x M.2 M Key(2230/2242)用于NVMe SSD 1x M.2 E Key用于WI-FI/BT |
| 工作温度 | 0°C 到 45°C |
| 外壳 | 耐腐蚀的铝合金外壳 |
| 散热器 | PWM调速风扇与定制散热片 |
极致性价比,让每个人都拥有端侧智能设备
对比目前主流的端侧算力产品,AirBox本地运行生成式AI的效率如何呢?
以Nvidia Jetson 系列多款支持生成式AI的设备为例。
AGX Orin 通过 MLC 加速之后 Llama-7B 47tokens/s,Llama-2-13B 25 tokens/s:airbox 上 Llama2-7B 性能是 12 tokens/s, Llama2-13B 性能是 6 tokens/s,可以支持int4、int8、fp16精度,llama2 及其各种变种模型性能相似;单芯最大可以跑20B-int4的模型。
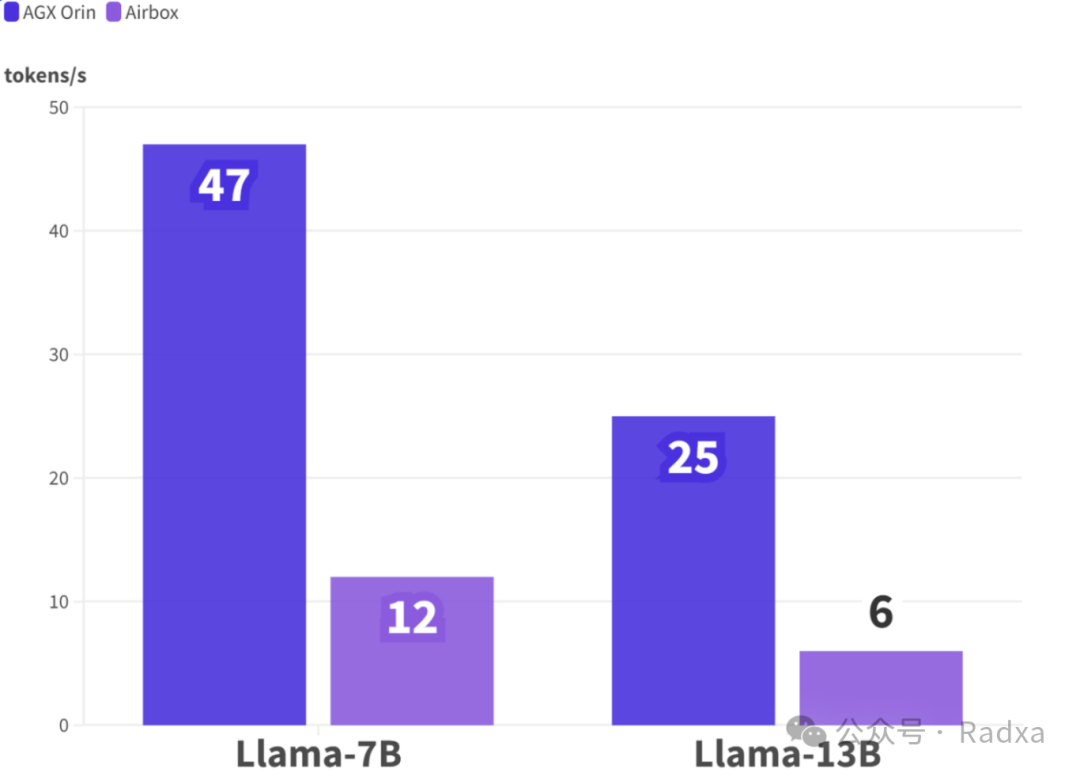
(注:Orin数据来源英伟达官网;此处数据越高越好)
经测试发现:AGX Orin和AirBox的每人民币(产品售价)可获得的每秒token数(实际性能),AirBox有着显著的优势。
Llama-7B:
AGX Orin(64G)≈0.00301 每秒token数/每人民币
AirBox≈0.00445 每秒token数/每人民币
Llama-13B:
AGX Orin(32G)≈0.00160 每秒token数/每人民币
AirBox≈0.00222 每秒token数/每人民币
AGX Orin上 Stable Diffusion 每张图耗时 2.2s,SDXL 耗时 23.1s;Airbox使用LCM加速之后,SD1.5 耗时 1.1s,SDXL耗时 7.4s。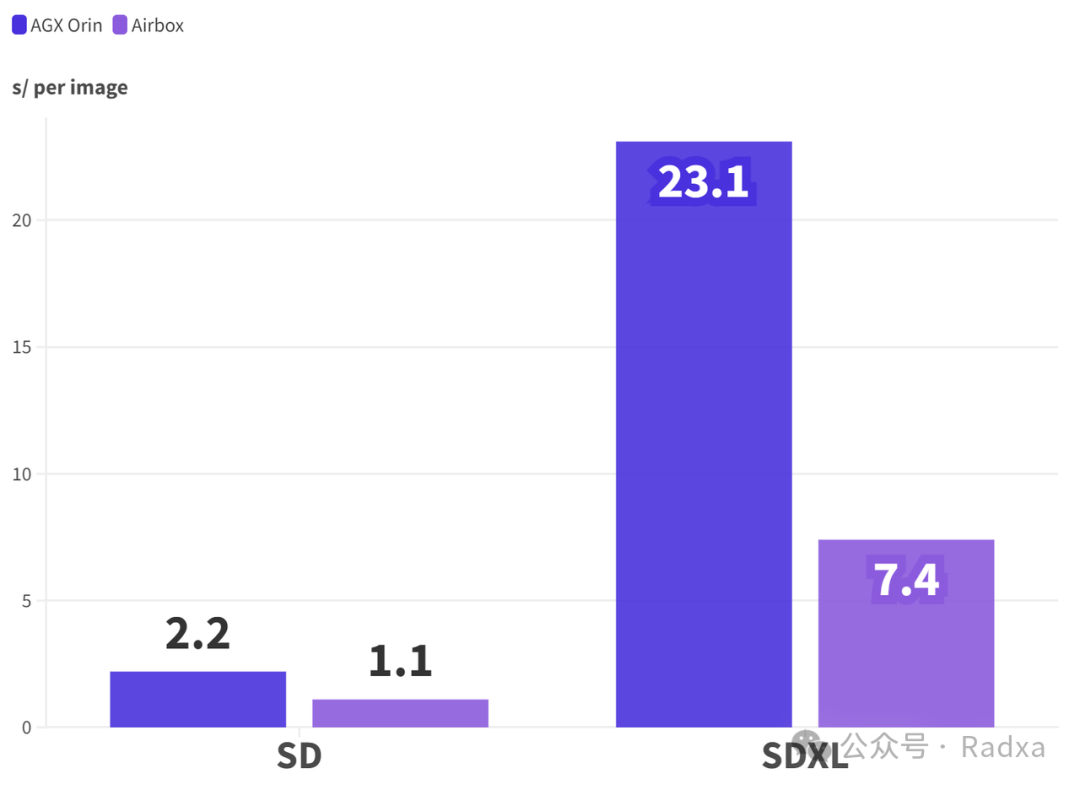
(注:Orin数据来源英伟达官网;Orin未标明步数,此处假设都是20步;此处数据越低越好)
丰富的生态应用
瑞莎 Fogwise AirBox 可提供卓越的智能性能,满足您对强大计算能力的需求。这款小巧但功能强大的设备可与 Tensorflow、Pytorch 和 Caffe 等领先的深度学习框架无缝兼容,为用户提供便携、高效的智能体验。无论您是制造商、智算爱好者、业余爱好者还是专业人士,Fogwise AirBox都是您的最佳选择。

AICore SG2300X:助力企业轻松获得高性能智算产品能力
Radxa AICore SG2300X 是一款配备先进 SOPHON智算处理器 SG2300X 的计算模块,可提供强大的性能来释放您的全部潜力。配备16GB内存,和64GB eMMC存储。Radxa AICore SG2300x 拥有令人印象深刻的24TOPS INT8计算能力,在各种任务中表现出色,并全面支持主流深度学习框架,集成核心电路及元件,可大幅加速产品研发速度,是企业快速开发高性能 AI 产品的首选。
审核编辑:刘清
-
瑞莎推出基于全志A733处理器的单板计算机Cubie A7A2025-08-20 3021
-
算力系列基础篇——算力与计算机性能:解锁超能力的神秘力量!2024-07-11 104
-
瑞莎科技近日推出Radxa Rock 5C/Rock 5C Lite开发板2024-04-09 3393
-
【算能RADXA微服务器试用体验】Radxa Fogwise 1684X Mini 规格2024-02-28 2433
-
Imaginatin携手算能,助力打造基于RISC-V的桌面级处理器2023-11-21 1657
-
算能重磅发布行业首款服务器级RISC-V CPU算丰SG2042,助力RISC-V迈向高性能计算2023-03-03 2382
-
超级计算机“算天、算地、算人”把算力转化为生产力2022-10-19 3787
-
瑞芯微和英伟达的边缘计算盒子方案,你会选哪一家的?2022-09-29 2917
-
微型计算机原理及应用2021-09-10 2546
-
制作微型计算机所需的元件有哪些2021-07-27 2565
-
什么是微型计算机的组成原理2021-07-16 1673
-
全球首款RISC-V AI单板计算机问世2021-01-14 3989
-
微型计算机原理2009-10-10 1341
全部0条评论

快来发表一下你的评论吧 !
