

面向边缘AI应用的全新RZ/V2H
描述
一款新的64位MPU RZ/V2H,为瑞萨电子的RZ/V系列带来了针对边缘AI的重大升级。边缘AI是指在连接网络的边缘进行的AI处理。优势在于嵌入式和本地处理系统,如安全设备、家用机器人和家用电器;相比之下,云AI处理是在中央服务器群中进行的。
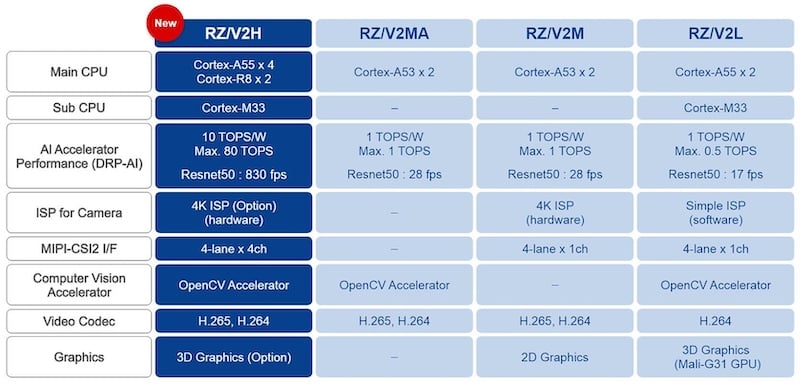
瑞萨电子的RZ/V系列微处理器均采用多核技术,并针对本地机器视觉处理进行了优化。新的RZ/V2 H通过额外的处理器内核、更快的处理速度和更低的功耗大大提高了赌注,在Resnet 50(一种50层深度卷积神经网络架构)上提供高达80 tera/s的操作(TOP)。
瑞萨64位RZ/V视觉AL MPU产品线
它还包括AI分类模型,效率高达每瓦10个TOP。相比之下,该系列中之前的MPU在Resnet50上的最高速度为1 TOP和28 fps。
多达10个处理核心
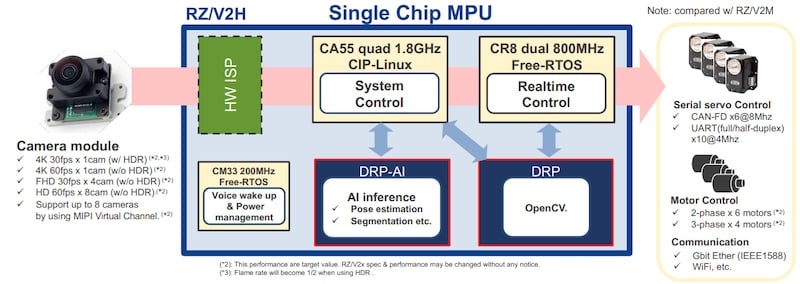
RZ/V2 H配备了四核Cortex-A55,双核Cortex-R8,Cortex-M33,Renesas DRP,Renesas DRP-AI以及可选的硬件图像信号处理器(ISP)。A55通常运行Linux进行整体系统控制和处理。四核使MPU能够以高达830 fps的速度同时支持四个4K分辨率摄像头。实时操作,如电机控制和通信,可以卸载到R8。200 MHz M33处理后台任务,如电源管理和唤醒任务。
RZ/V2 H应用示意图
硬件ISP是从相机获取图像数据的第一站。由于有些相机有自己的ISP,瑞萨电子提供的RZ/V2 H有或没有硬件ISP部分。最后,DRP和DRP-AI提供OpenCV兼容性,并执行大部分AI处理。这为智能家居和办公设备、工业安全产品和基础设施设备提供了强大的处理器选项。它允许设备执行AI操作,如图像识别,识别和决策,而无需调用服务器进行任何操作,但最复杂的AI操作。更多信息可以在RZ/V2 H手册中找到。
更高的计算性能,更低的电力消耗
当小封装决定了低热量和低功耗预算时,仅仅增加内核或提高时钟速度来提高性能是不够的。在这方面,RZ/V2 H没有让人失望。它具有核心和时钟速度,但它也使用了精心的优化来增加功能,同时降低功耗。
瑞萨电子专有的动态可重编程处理器(DRP)是一种可重新配置的处理引擎,可以适应不同的任务。它足够灵活,可以根据需要随每个时钟周期进行更改。在RZ/V2H中,DRP系统卸载了预处理和后处理。 DRP处理OpenCV兼容性,而针对AI数学优化的DRP—AI执行最繁重的AI计算。 瑞萨表示,V3的能效是V2的10倍。
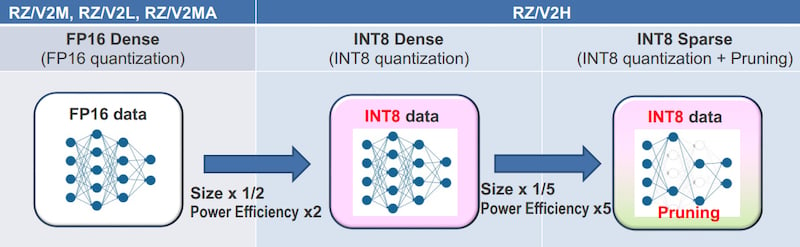
矩阵计算现在使用INT 8数据量化,而不是DRP-AI V2中使用的FP 16。从浮点数降为整数似乎是一个很大的妥协,但在这个应用程序中,它不是。MPU使用Resnet 50模型,该模型使用INT 8数据保持高精度。迁移到INT 8可以将数学性能提高14倍。与此同时,它将数据密度减半,从而使功率效率比FP 16高出2倍。
DRP中的非结构化剪枝
一个称为非结构化修剪的过程带来了进一步的性能提升和功耗降低。AI模型会查看加权值,较大的值具有更大的意义,并且导致匹配的可能性更大。修剪将所有接近零的权重设置为零。
FP 16在早期MPU版本中没有修剪(左),而INT 8在RZ/V2 H中具有稀疏修剪(右)。nbsp;
由于结果将为零,没有值朝向最终结果,DRP—AI引擎跳过任何权重等于零的操作。保留零权重被称为密集修剪,而跳过它们被称为稀疏修剪。这使得AI模型更小,更快,更高效,在从FP16切换到INT 8获得的2倍功率效率的基础上,功率效率提高了约5倍。
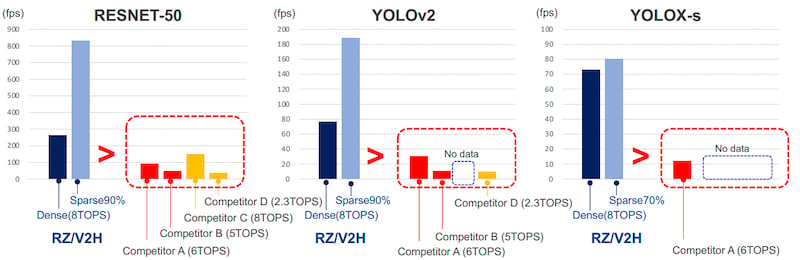
根据瑞萨电子的基准测试,INT8和稀疏修剪的结合显著提高了常见竞争产品的性能。
竞争性基准测试说明RZ/V2H的性能优势
密集修剪提供了两倍的性能,而稀疏修剪使AI性能进一步提高了约3倍。在一个典型的应用中,设备必须处理视频,识别对象,并根据观察结果做出决策,处理器中的AI计算速度直接转化为设备操作的速度。机器人可以更快地移动,警报可以更快地触发,任何必要的响应都可以更快地启动。
无需风扇
与竞争对手的基于GPU的嵌入式AI相比,DRP和DRP-AI提高了性能并显著降低了功耗。在机器人真空用例中,RZ/V2 H以低于4 W的功率为AI同步定位和地图绘制(SLAM)提供13 fps的帧率,从而在大多数应用中无需冷却风扇。这意味着更安静的操作和更长的电池寿命。RZ/V2 H现在可以作为组件和开发板从标准瑞萨分销渠道购买。
-
RZ/V2H Group芯片:功能、特性与设计要点解析2026-04-01 1105
-
拆解百元级工业核心板:明远智睿V2H如何实现“算力自由”?2025-07-29 1456
-
Banana Pi 最新边缘 AI 系统模块 BPI-AI2N 采用瑞萨电子 RZ/V2N2025-06-25 2325
-
瑞萨RZ/V2H平台支持部署离线版DeepSeek -R1大语言模型2025-05-13 2113
-
瑞萨新款RZ/V2N视觉AI MPU产品介绍2025-03-27 2146
-
AI MPU# 瑞萨RZ/V2H 四核视觉 ,采用 DRP-AI3 加速器和高性能实时处理器2025-03-15 7340
-
瑞萨推出集成DRP-AI加速器的RZ/V2N,扩展中端AI处理器阵容,助力未来智能工厂与智慧城市发展2025-03-11 1581
-
面向视觉 AI 应用的全新 MPU 平台:瑞萨RZ/V2H MPU2024-11-22 2841
-
瑞萨电子RZ/V2H MPU提升机器人与自主应用中的AI性能和实时控制2024-07-15 1670
-
基于瑞萨RZ/V2H AI微处理器的解决方案:高性能视觉AI系统2024-07-02 1905
-
瑞萨电子推出面向高性能机器人应用的RZ/V2H微处理器2024-03-08 2309
-
RZ/V2H组用户手册2024-02-25 626
-
贸泽开售面向AI视觉IoT应用的Renesas RZ/V2L高精度MPU2022-07-05 1716
-
瑞萨电子推出支持入门级AI应用设计的全新RZ/V2L MPU2021-05-24 3383
全部0条评论

快来发表一下你的评论吧 !
